-
-

Who is us
-

Concept
-

Goal
-
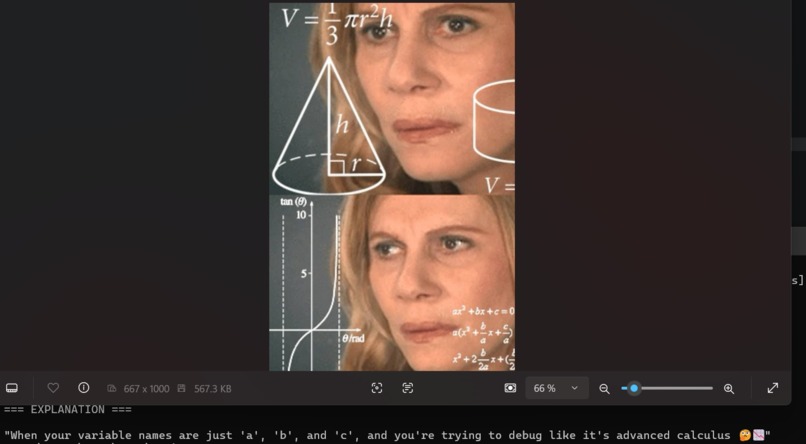
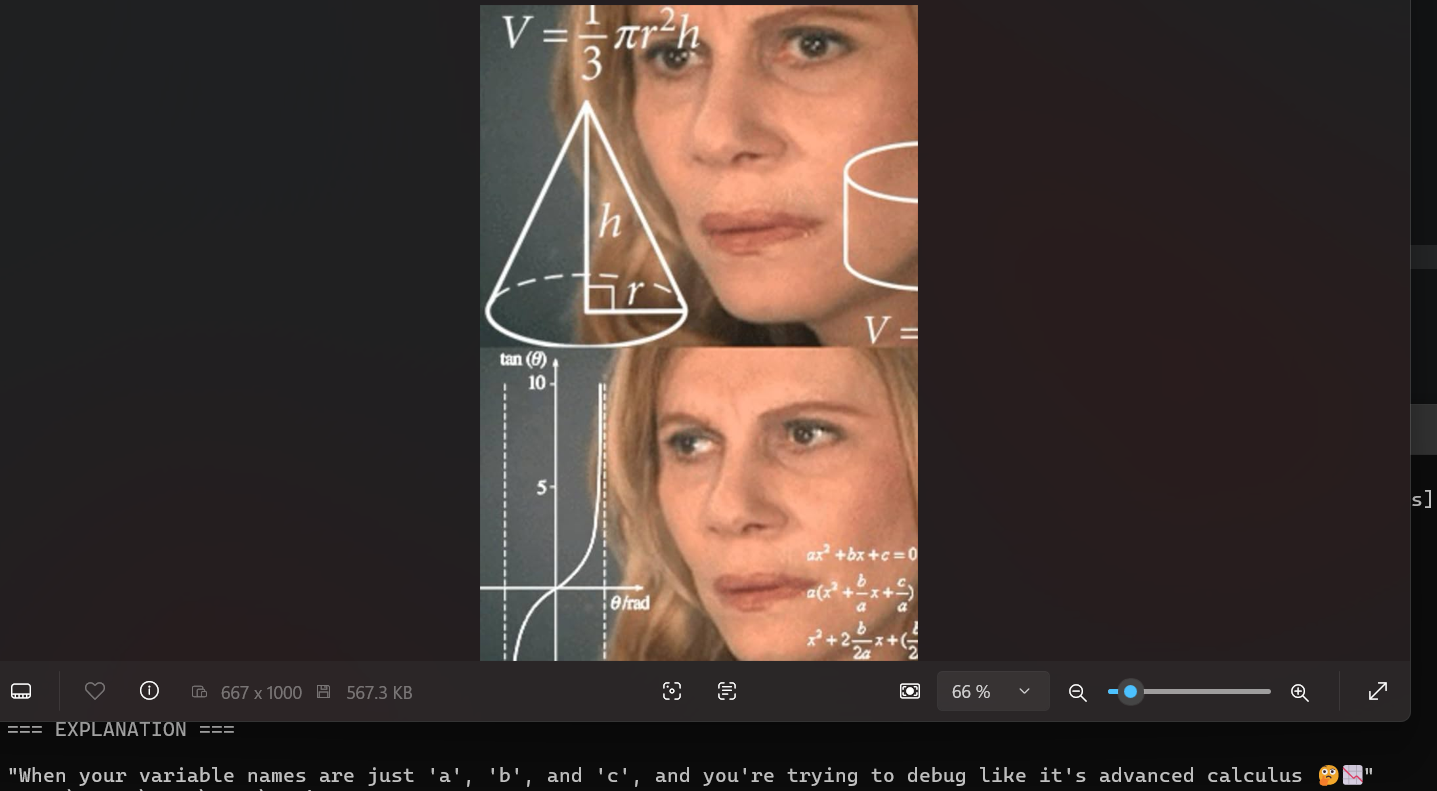
Name your variables!!!

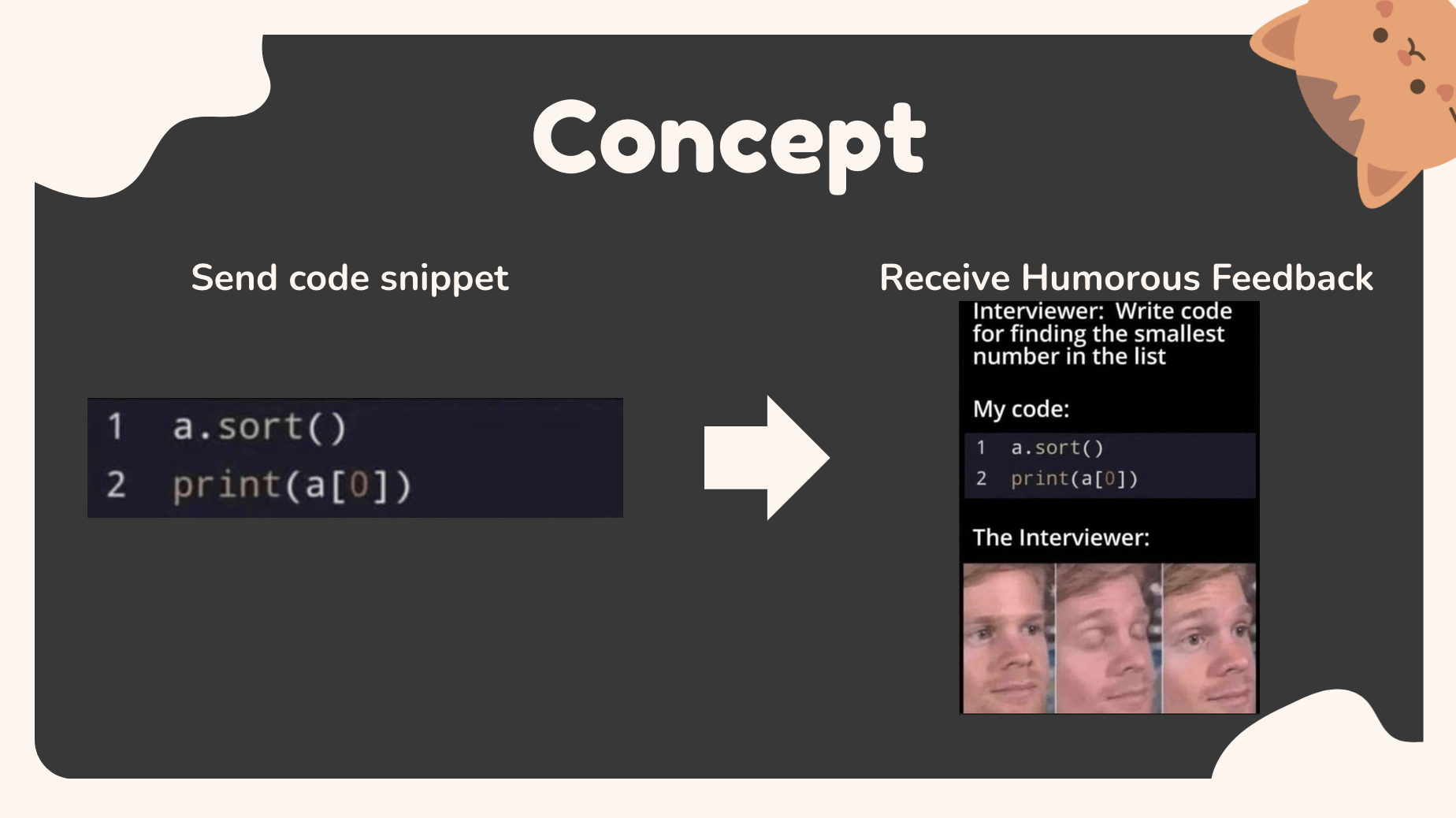

Playful Code Review System
We’ve built a first version of a playful and engaging way to learn programming by turning code reviews into something closer to meme culture.
Given a Python code snippet, our system detects common errors, anti-patterns, and coding malpractices, and transforms them into contextual feedback paired with a meme and a generated message. The result is a “roast-meets-education” experience designed to make learning from mistakes more memorable and less intimidating.
The tool is currently focused on Python, but the architecture is language-extensible.
Idea
Instead of just receiving a grade, we reimagine feedback as something social, funny, and shareable:
- Professors can use it to give students structured yet entertaining feedback for smaller code submissions or exercises
- Students can use it peer-to-peer to highlight issues in code in a lighthearted way
- Feedback can be customized by tone (funny, educational, sarcastic, etc.)
How it works (high level)
1. Dataset creation (offline layer)
We built a curated dataset of coding malpractices by combining:
- Ruff linter rules
- Python anti-pattern repositories from GitHub
- Bad-practice datasets and code examples
This process also involved web scraping and HTML parsing due to inconsistent formats across sources.
On top of that, we added custom “fun” rules to make the system more relatable (e.g., discouraging meaningless print statements like "here", overuse of emojis in formal code, or confusing variable reuse).
2. Two-layer detection system
We experimented with multiple approaches:
Static + rule-based analysis
Using tools like Ruff and structured analyzers to detect standard issues.LLM-based reasoning model
A prompt-tuned LLM trained on our curated malpractice dataset. This approach proved more robust and flexible.
Overall, the LLM-based detector achieved stronger coverage and better generalization.
3. Meme retrieval system (semantic matching)
Once issues are detected, we map them to memes using:
- FAISS vector search index
- Sentence Transformers (Hugging Face embeddings, specifically
all-MiniLM-L6-v2)
Each meme is encoded as a vector, and the detected issue acts as a query. A KNN-style retrieval is performed to select the most appropriate meme for the situation.
Mathematically, retrieval can be expressed as:
$$ \text{meme}^* = \arg\min_{m \in M} \; d\big(f(\text{issue}), f(m)\big) $$
where:
- f is the embedding function
- dis a distance metric (cosine distance)
- M is the meme dataset
4. Meme + humor generation layer
Finally, we feed:
- the detected issue
- the selected meme
- user-selected tone (funny / educational / sarcastic / etc.)
into an LLM that generates a contextual joke or explanation.
A small randomness factor ensures variety and avoids repetitive outputs.
Why it matters
This project turns code feedback into something:
- more engaging for learners
- more expressive for teachers
- more social and shareable for peers
Instead of just saying:
“this is wrong” we say it in a way that sticks.

Log in or sign up for Devpost to join the conversation.