-
-
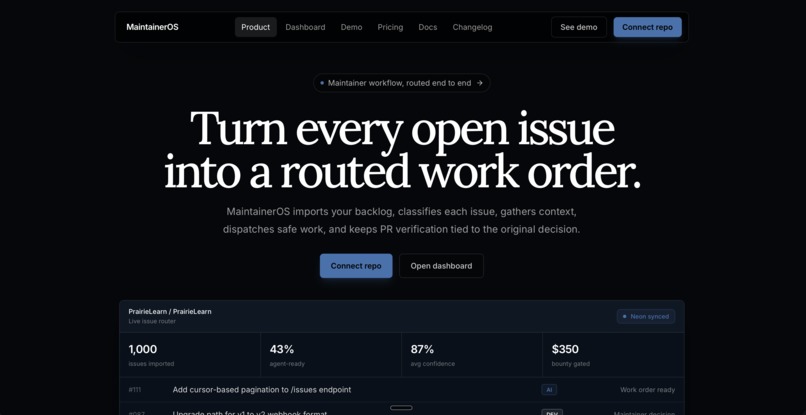
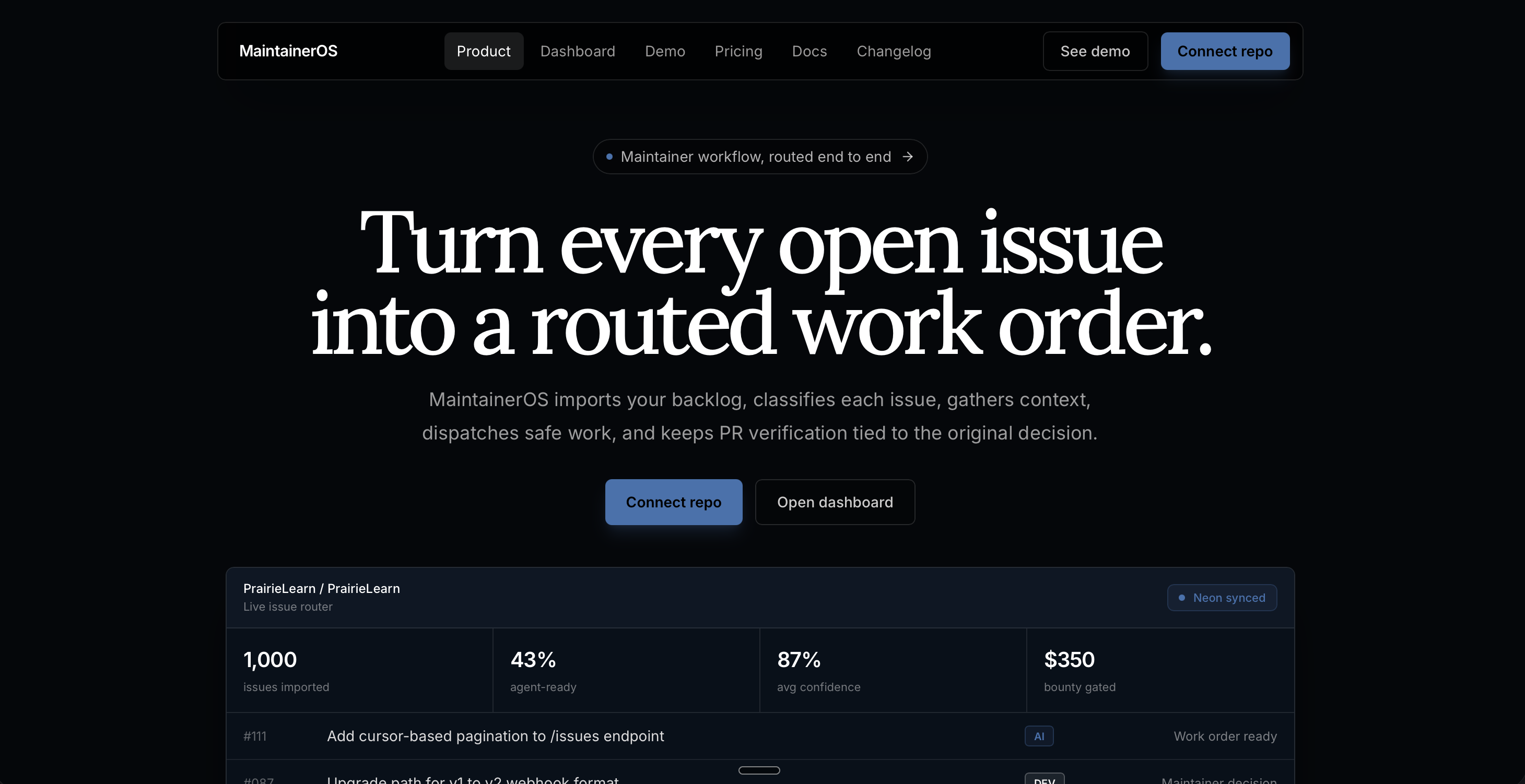
LandingPage
-
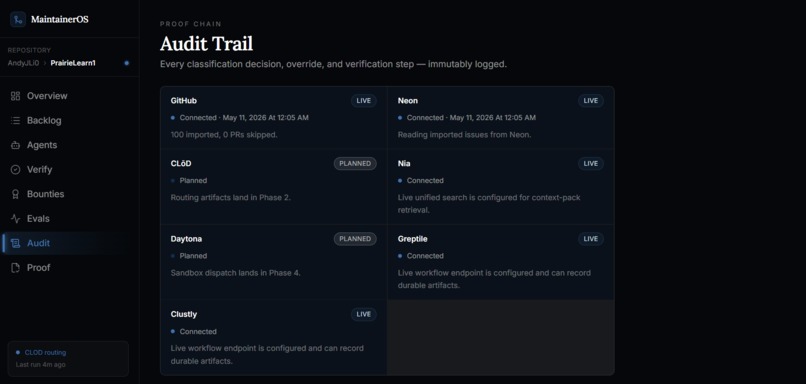
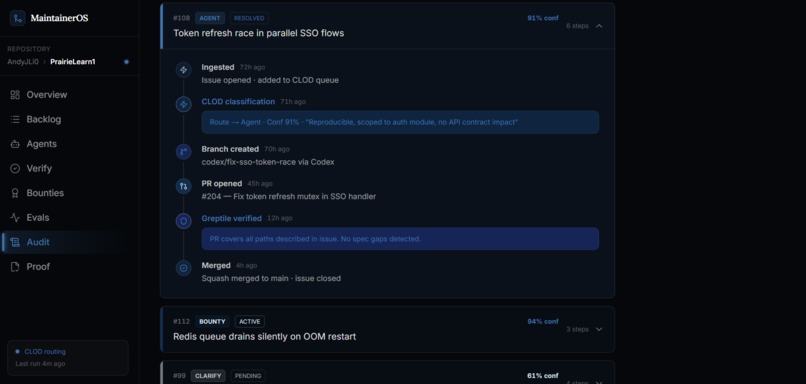
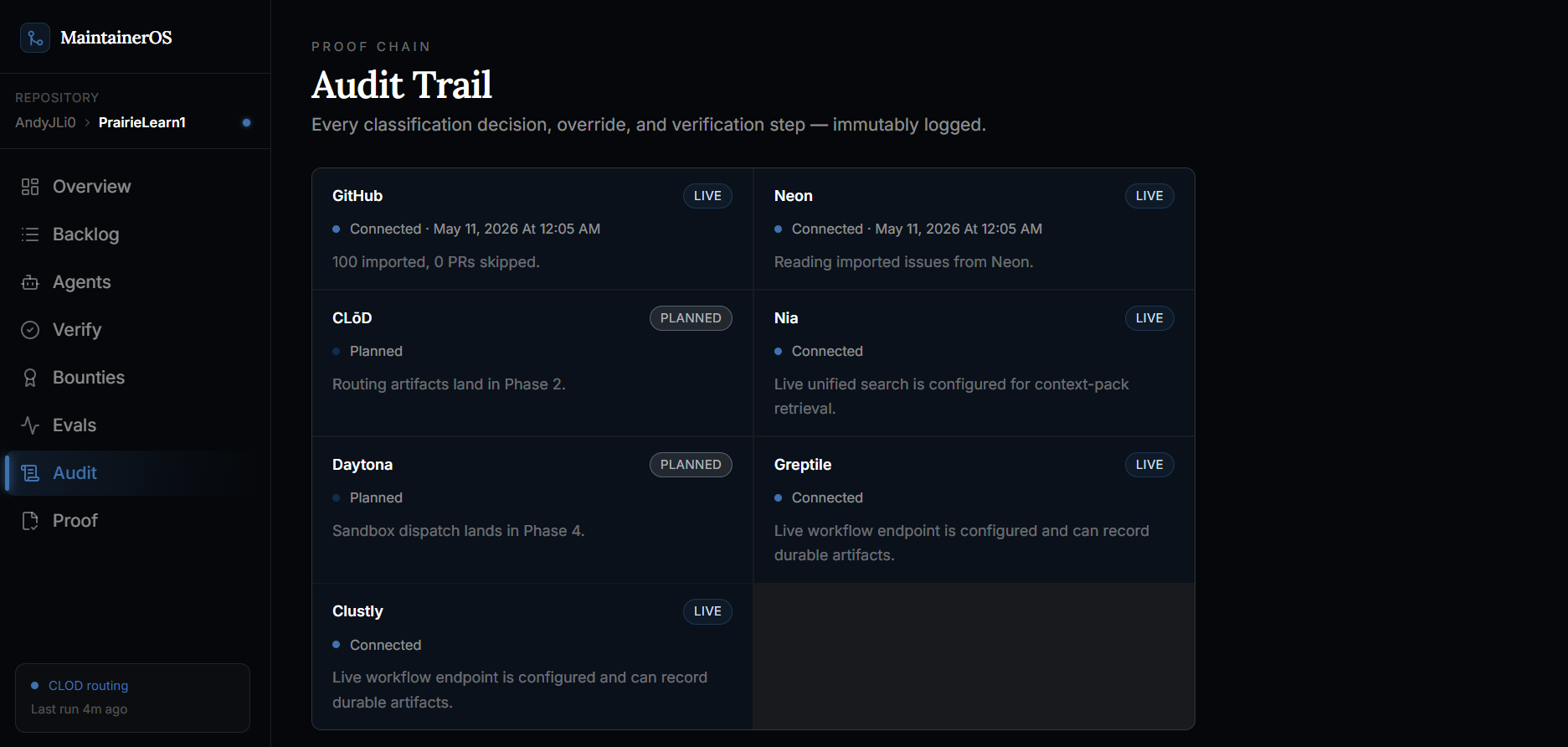
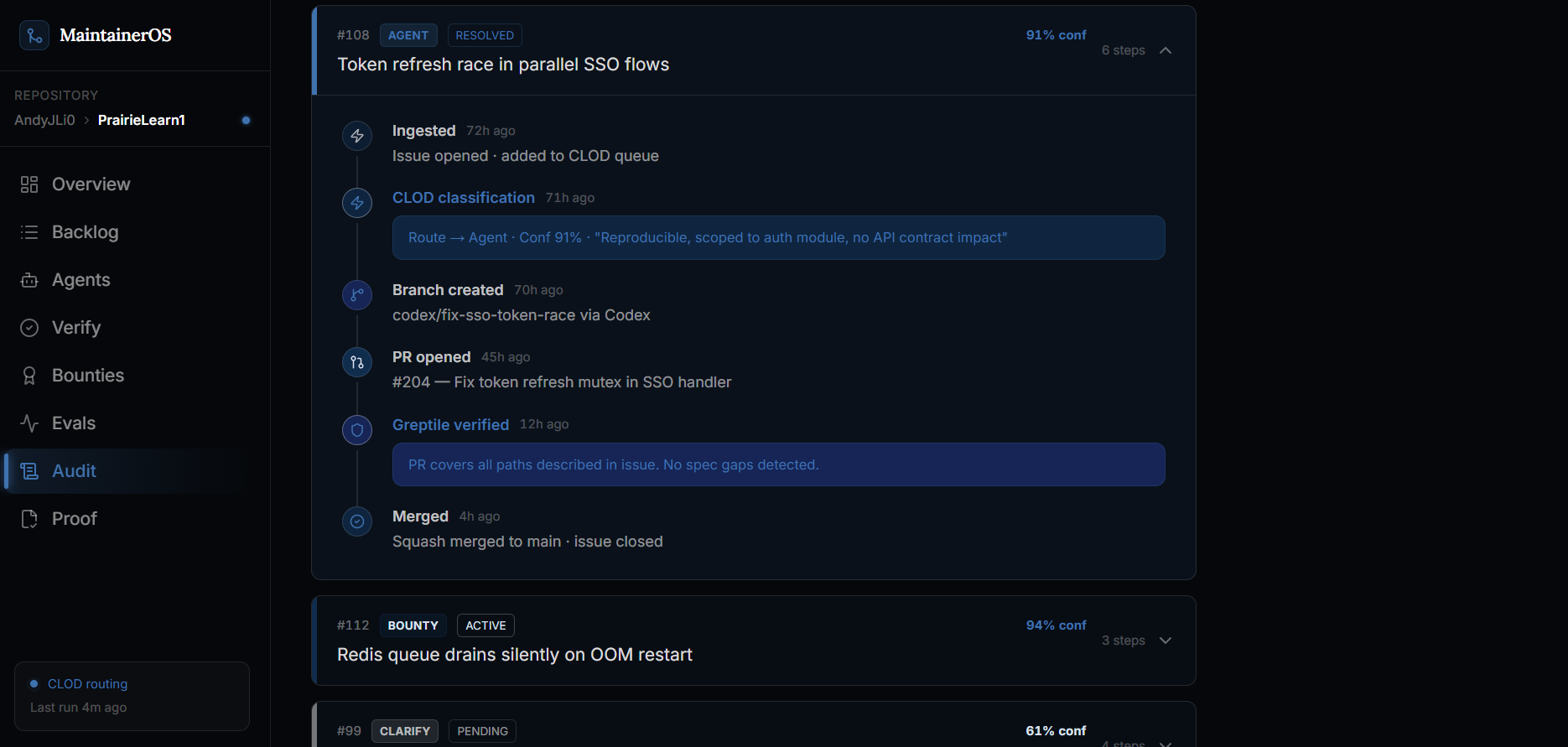
Audit trail
-
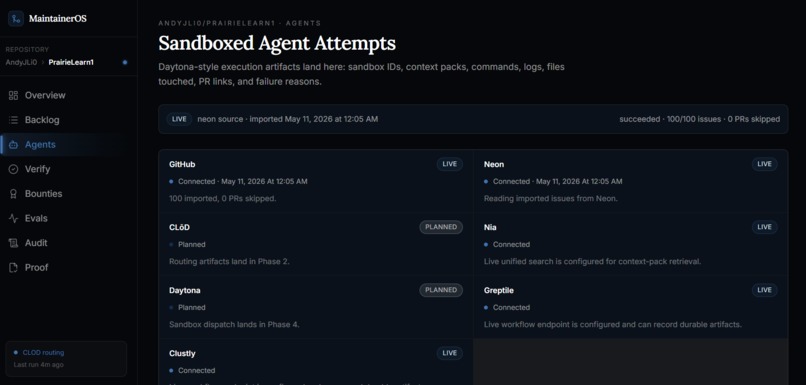
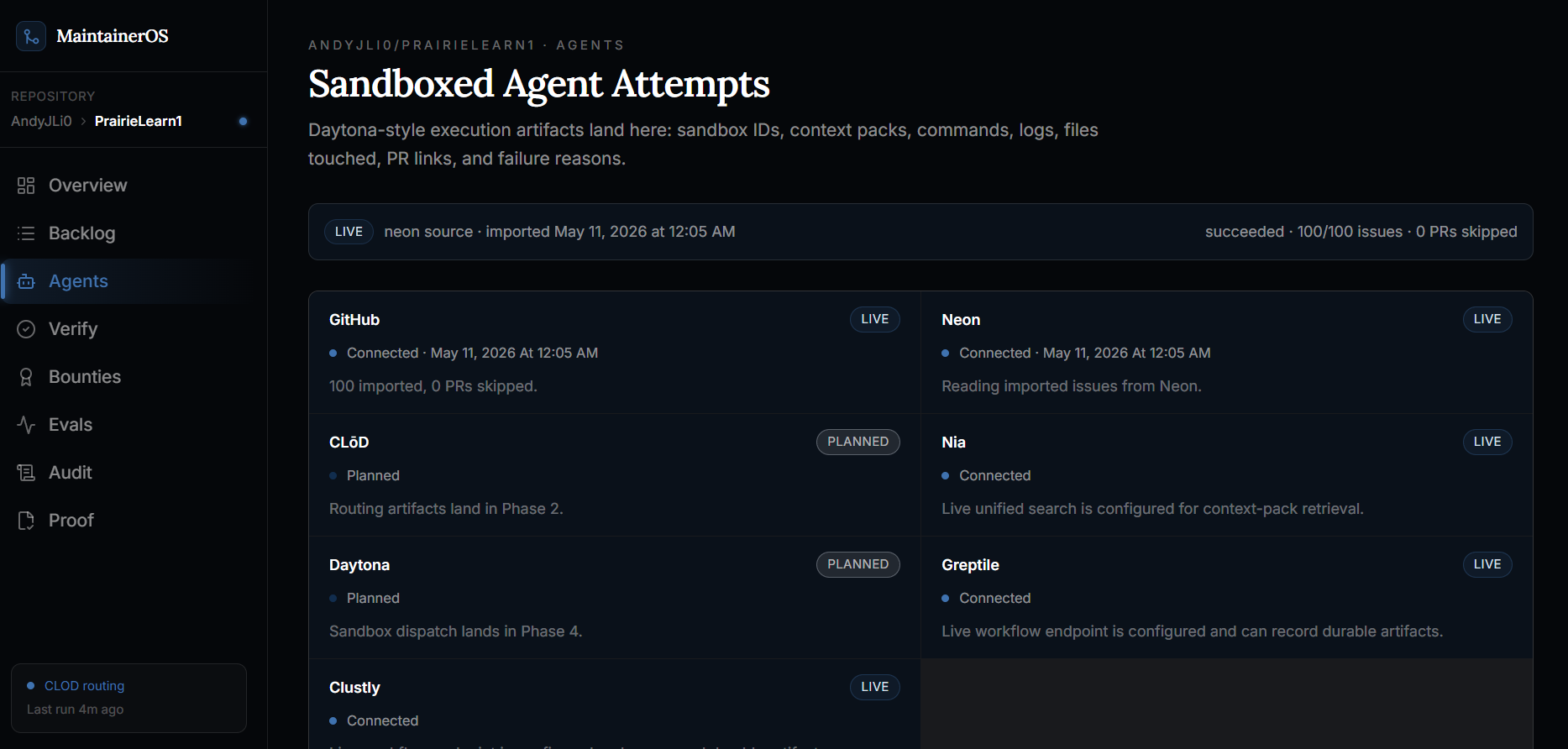
Sandboxed agent attempt history
-
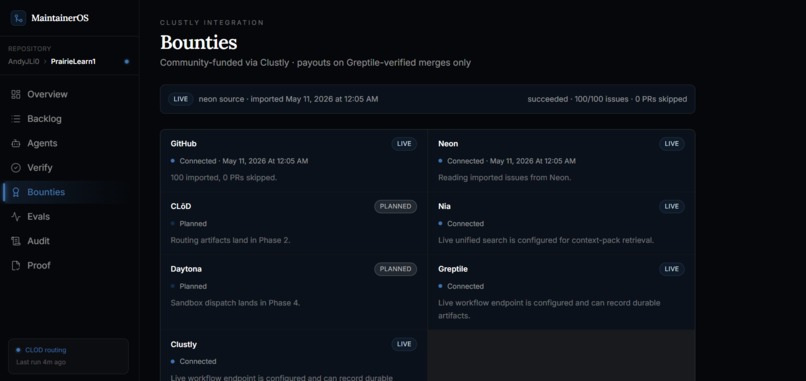
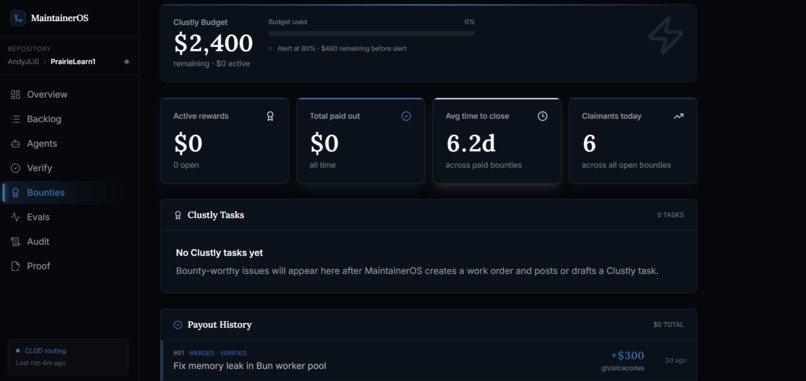
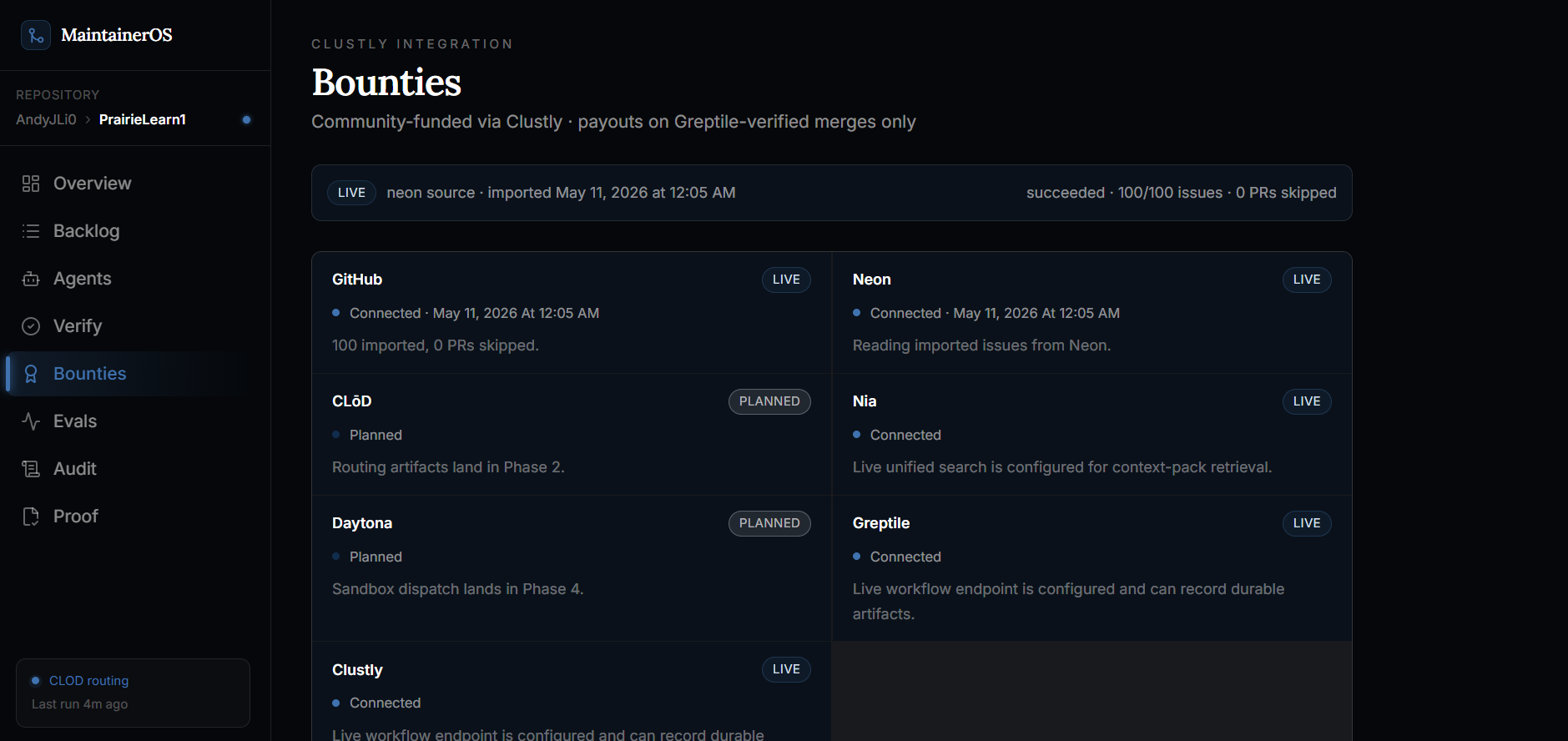
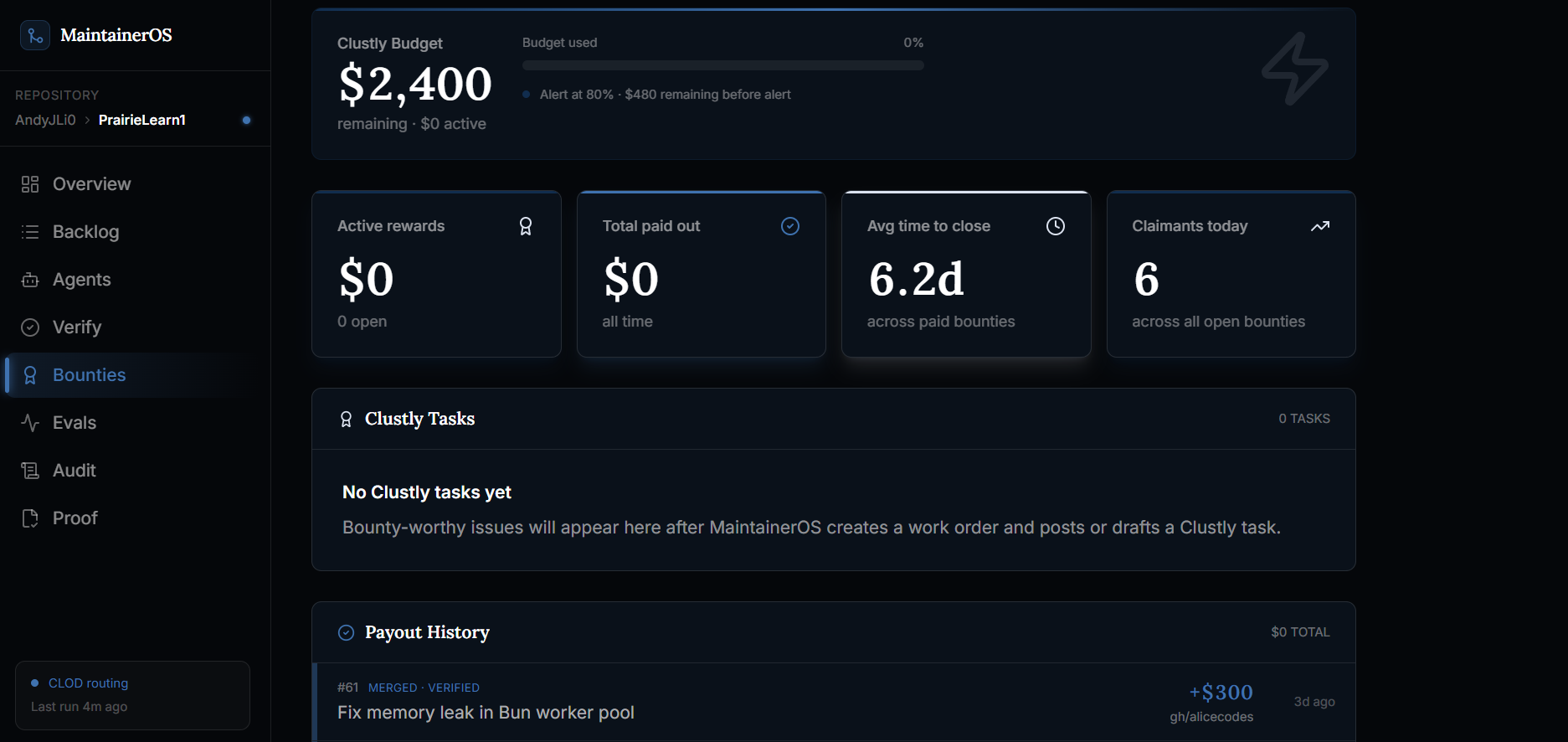
Bounties
-
-
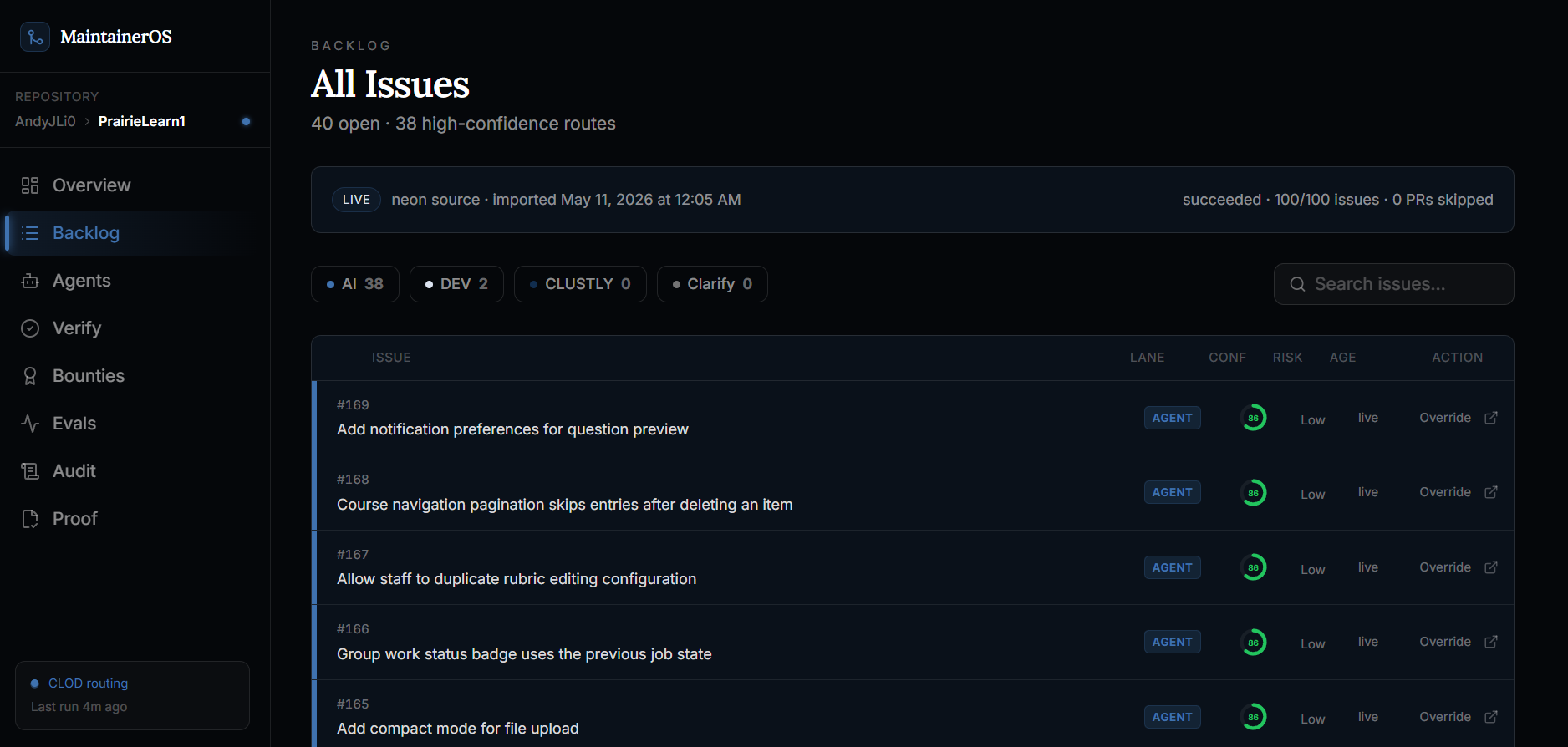
All issues
-
Bounties details
-
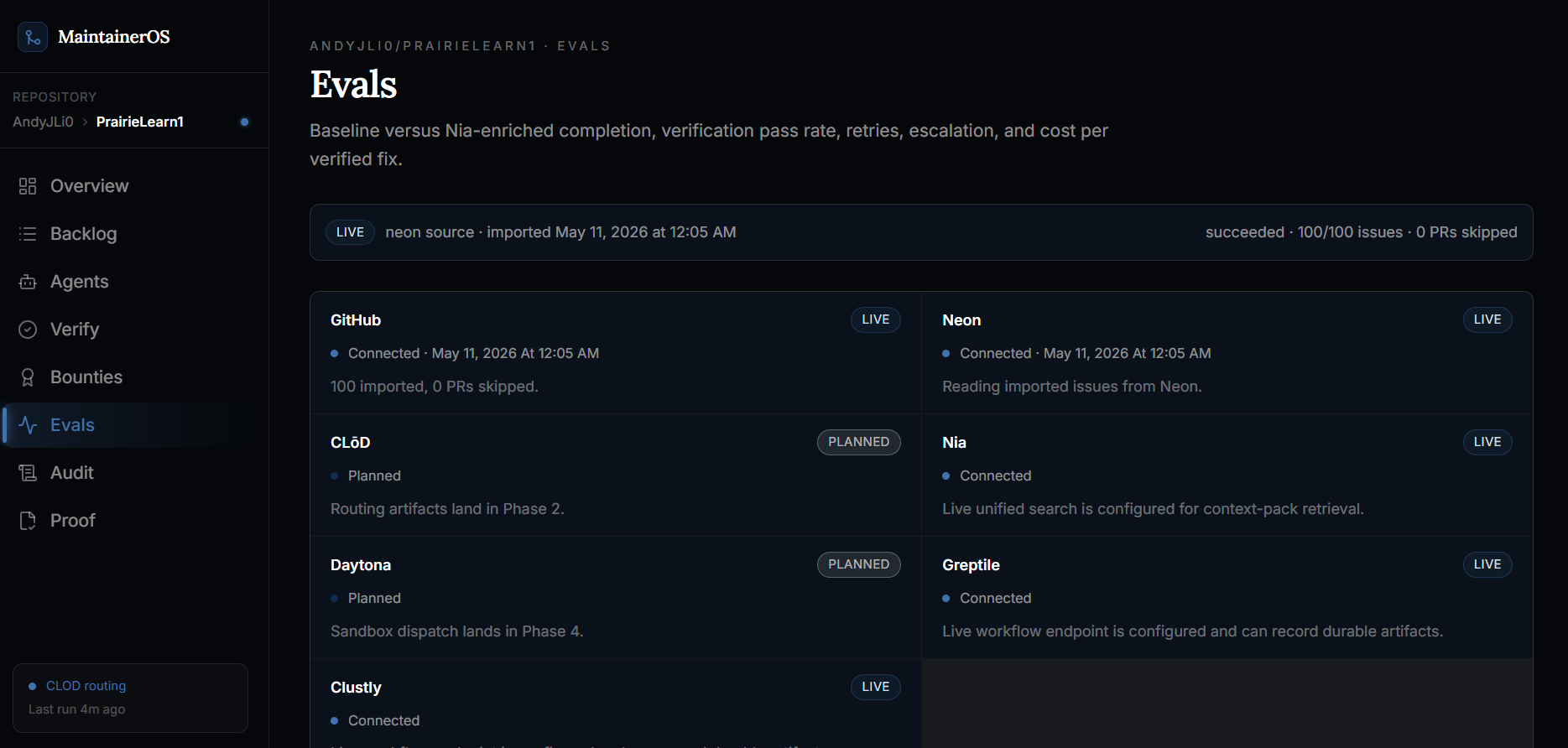
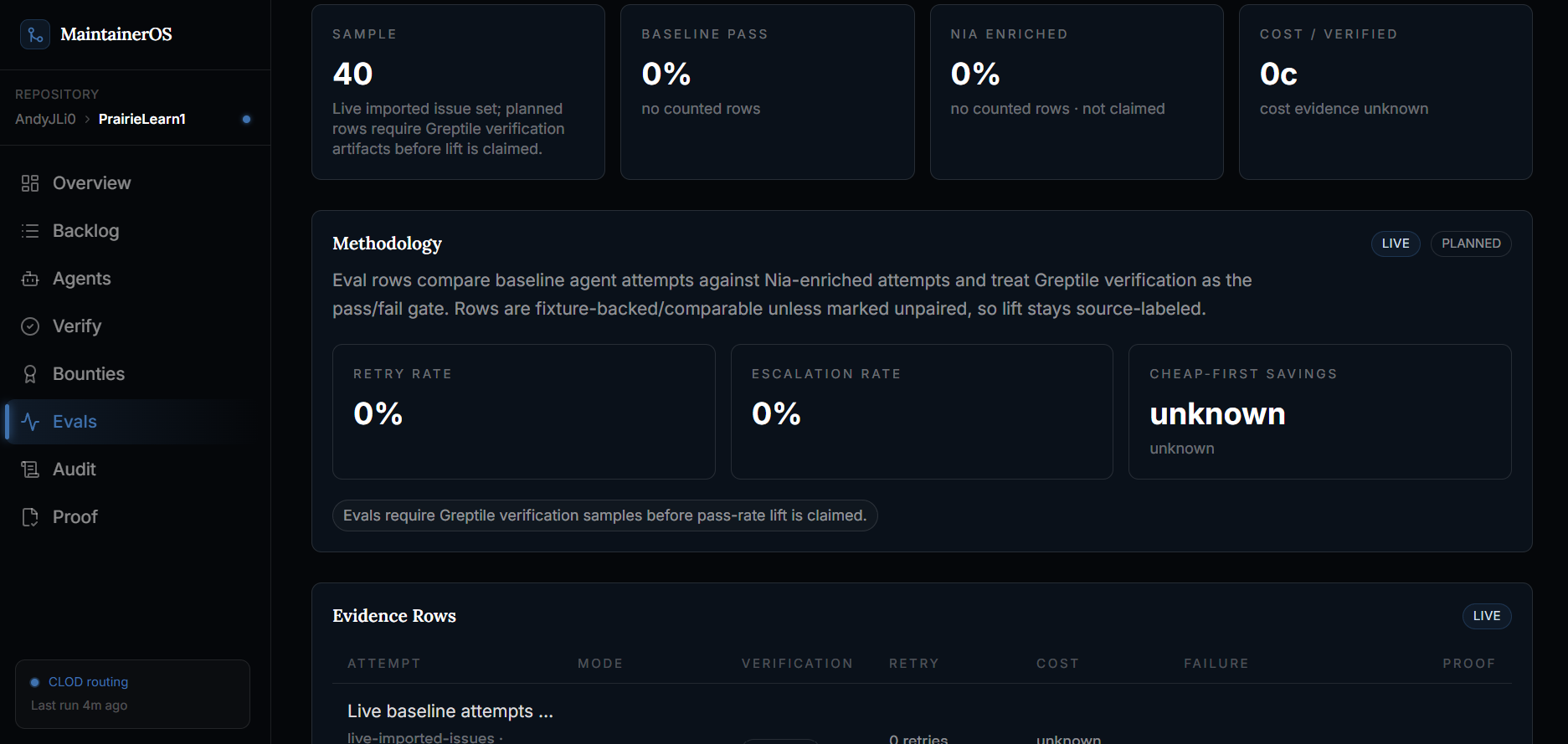
Evals
-
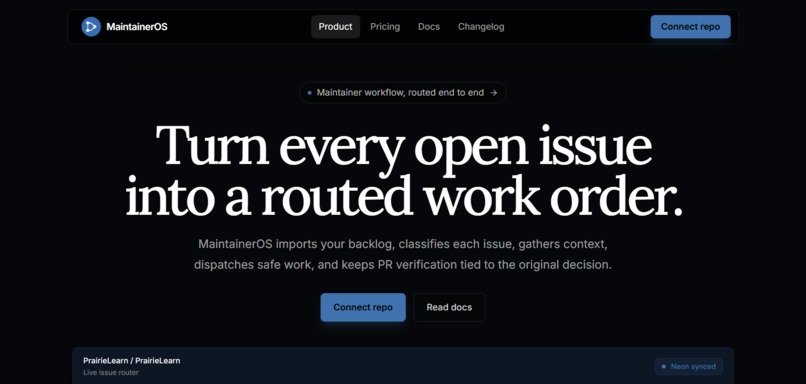
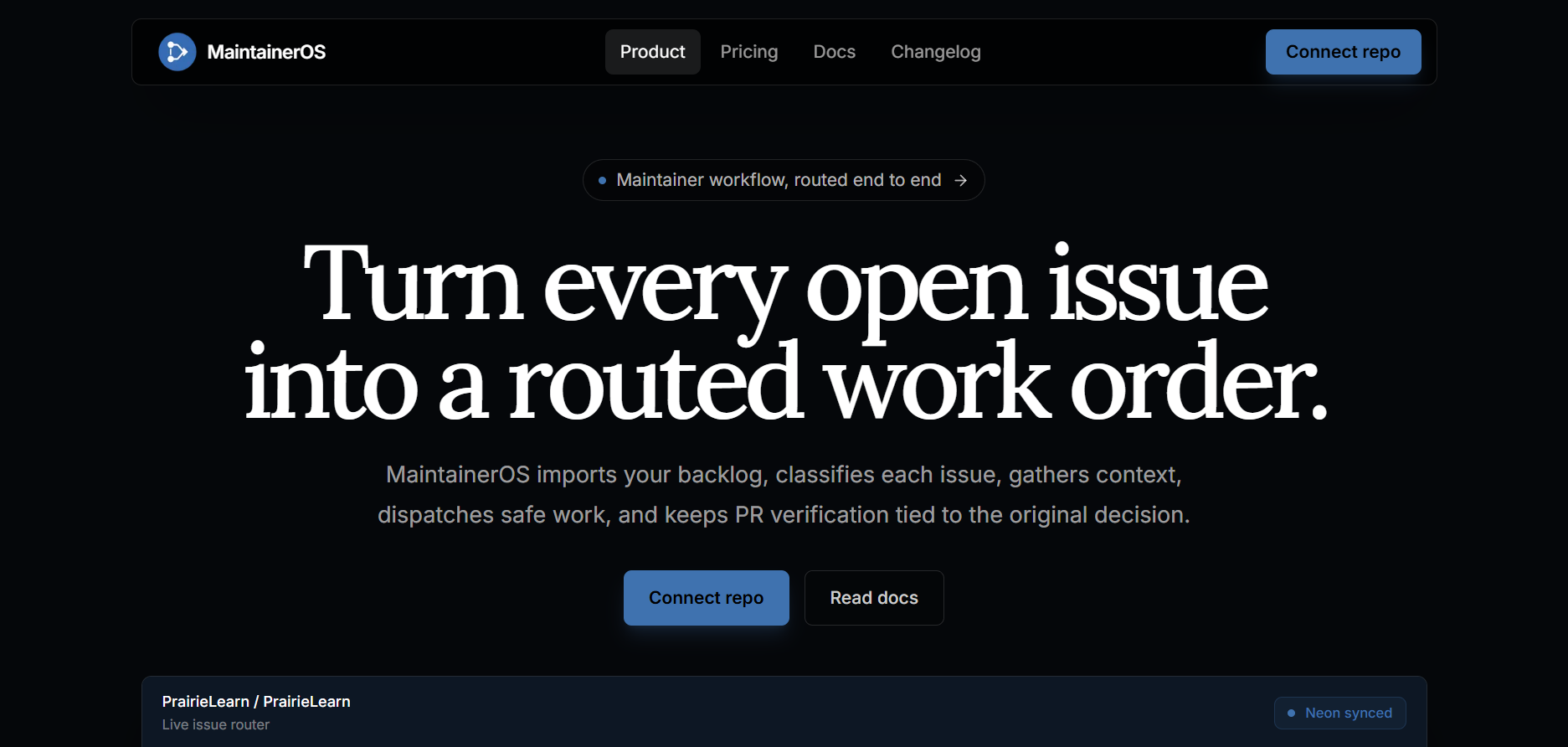
Landing page
-
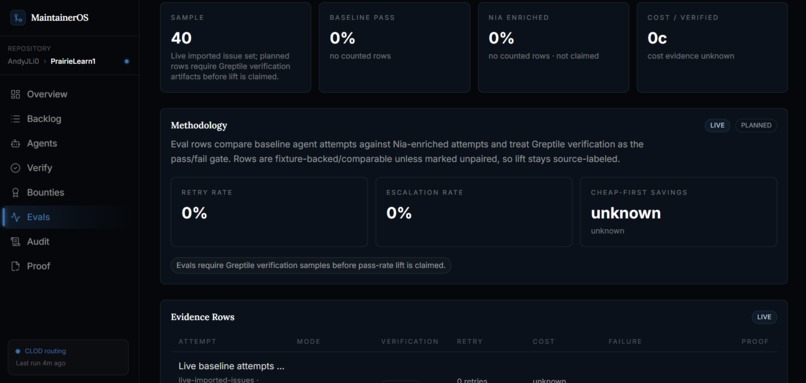
-
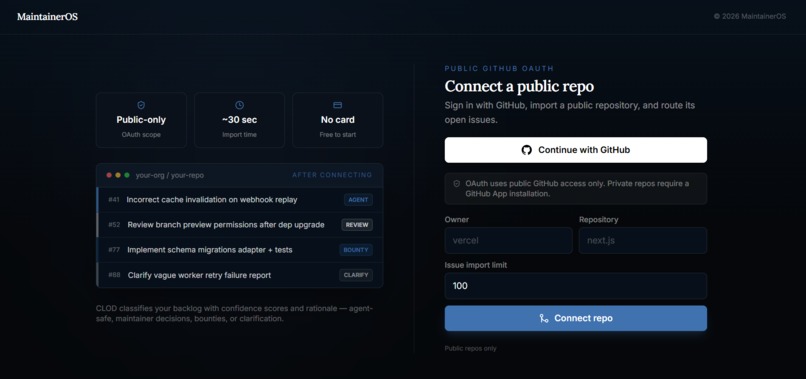
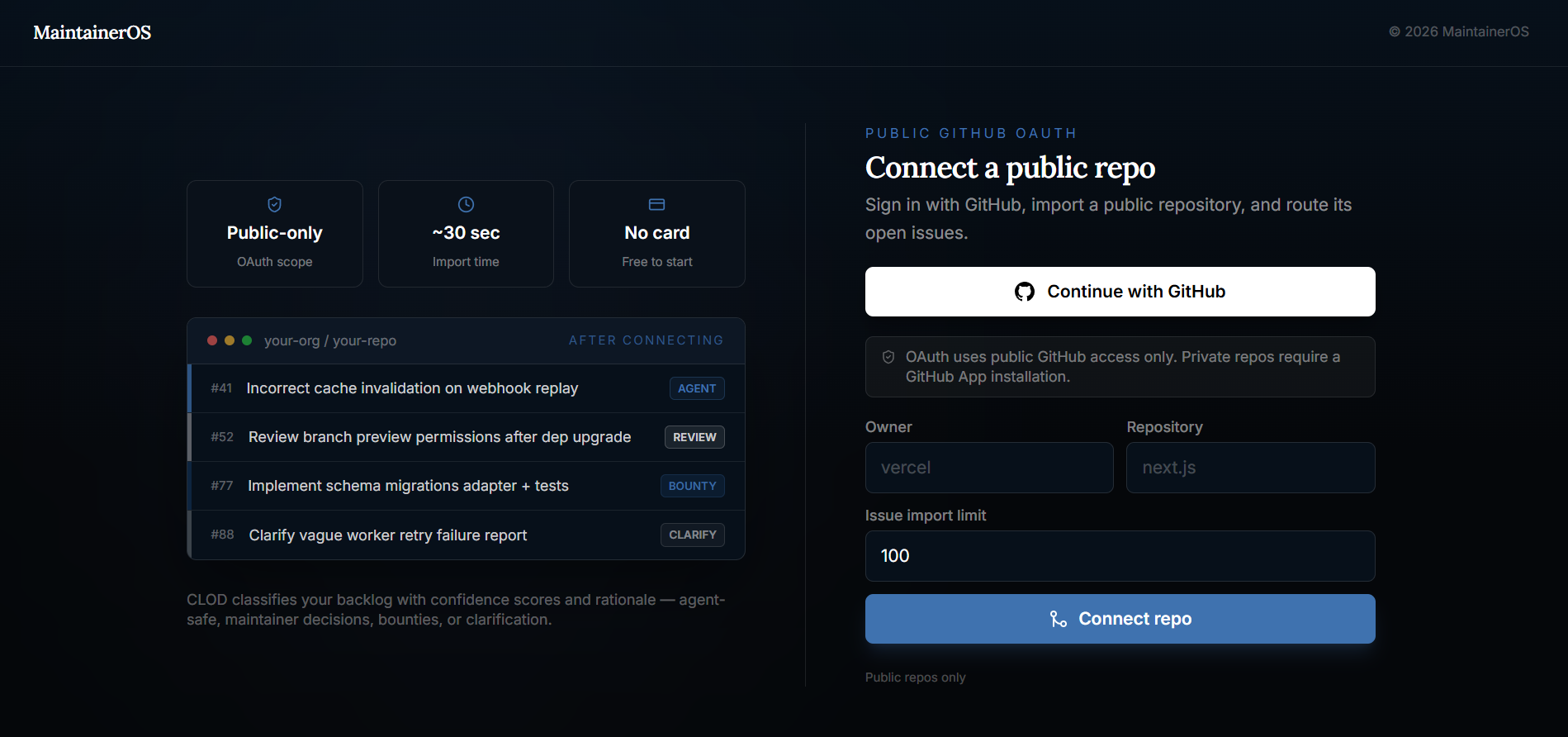
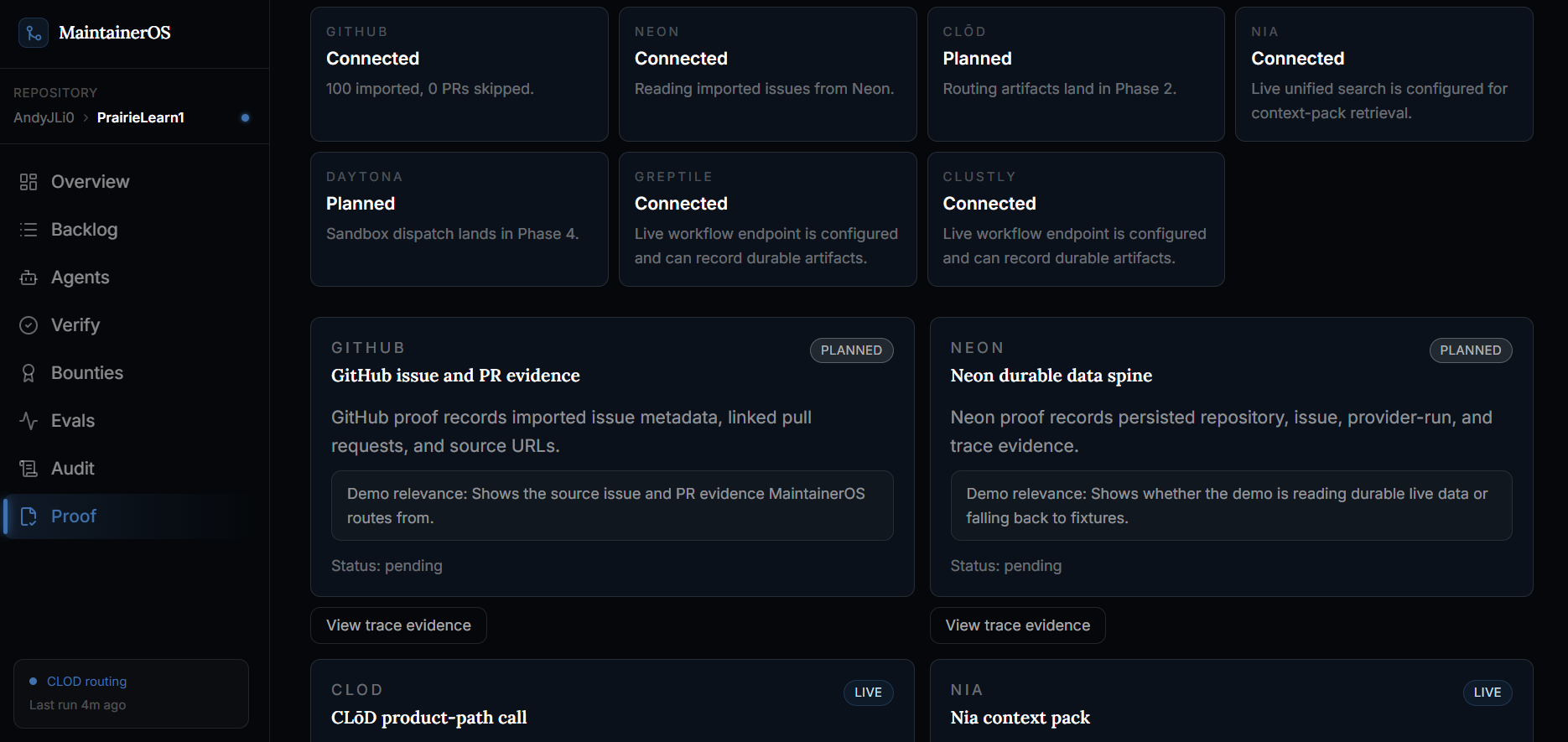
Connection page
-
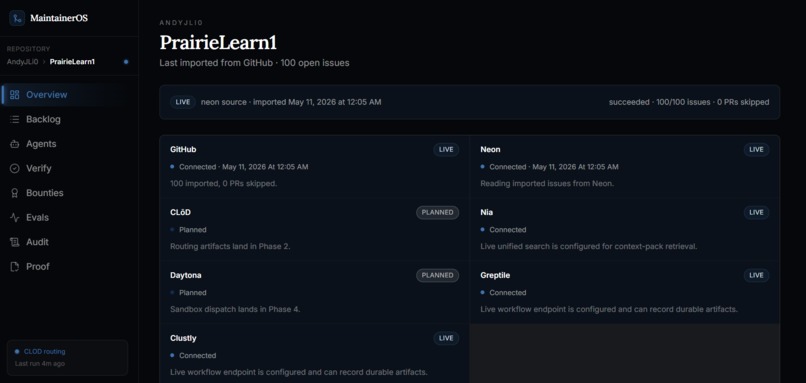
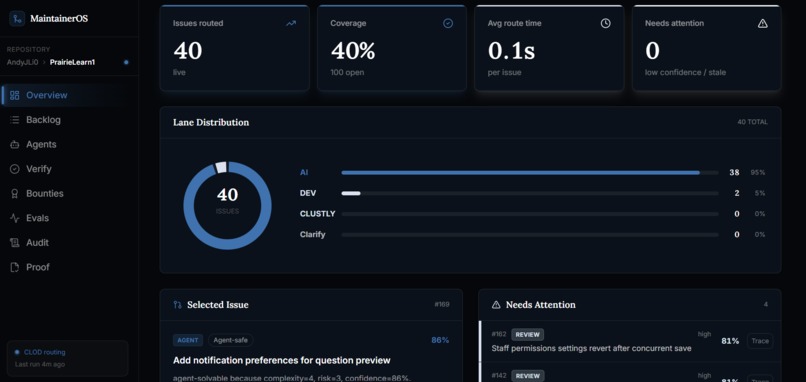
Overview page
-
-
-
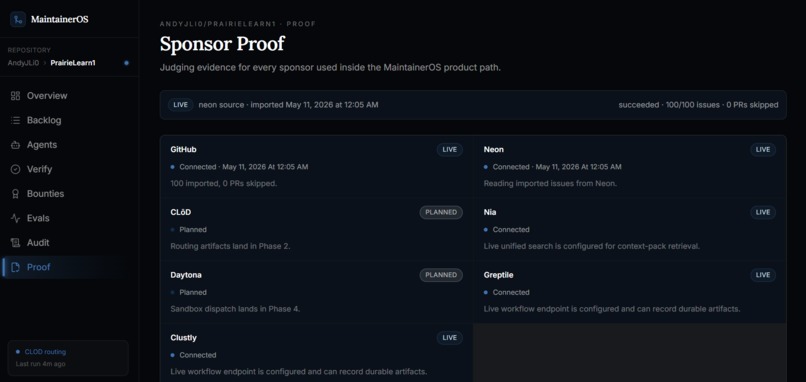
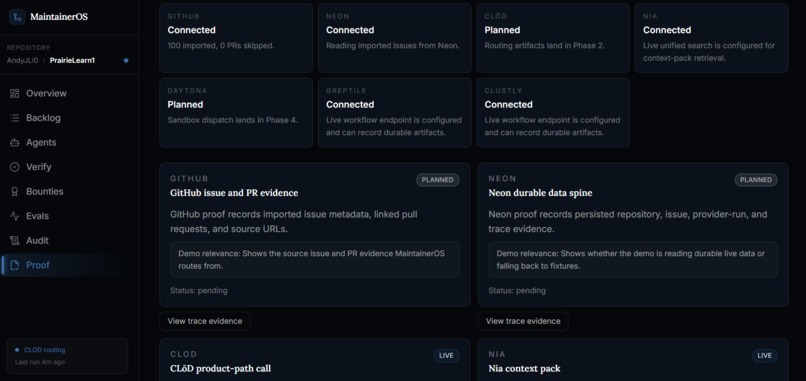
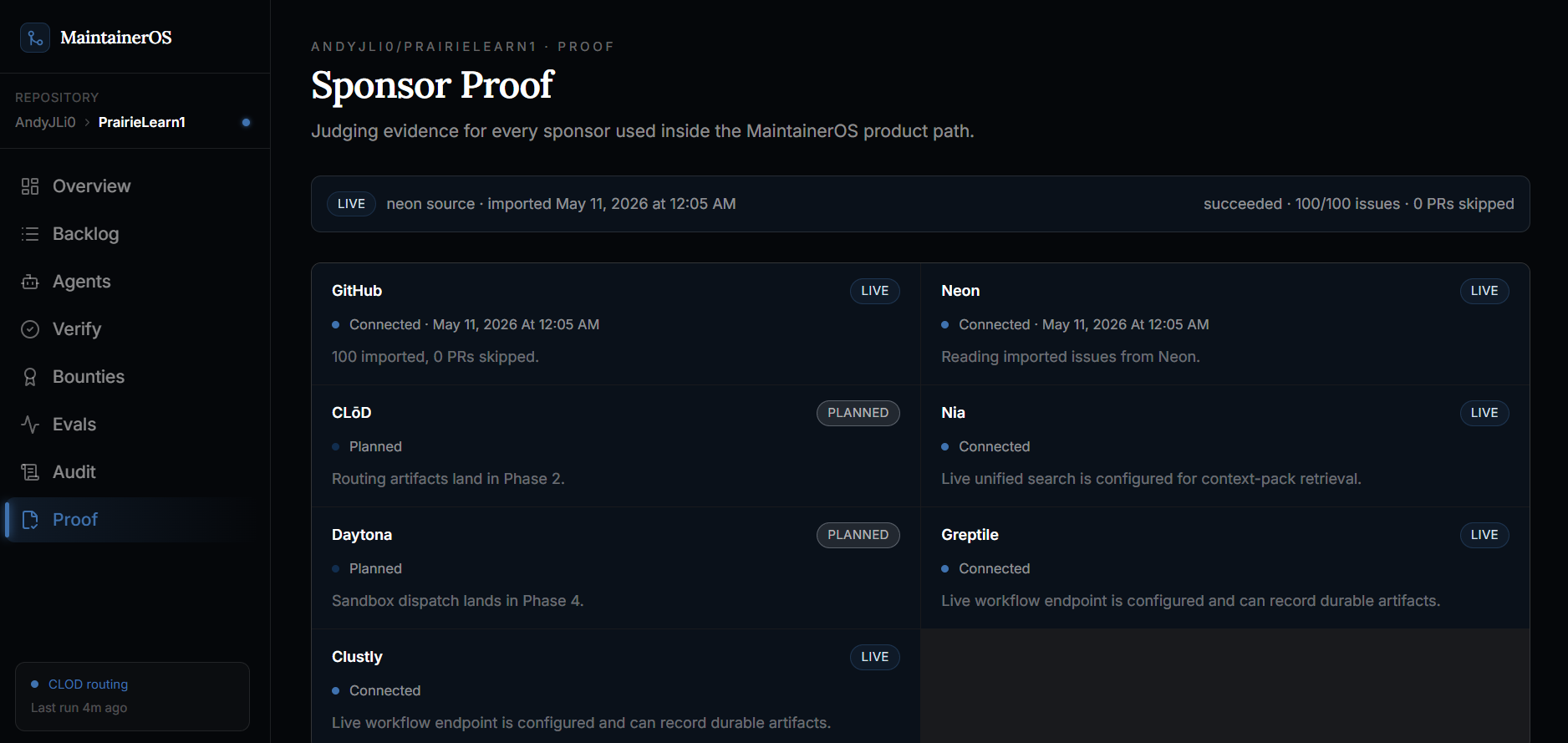
Proof of sponsor utilization
-
-
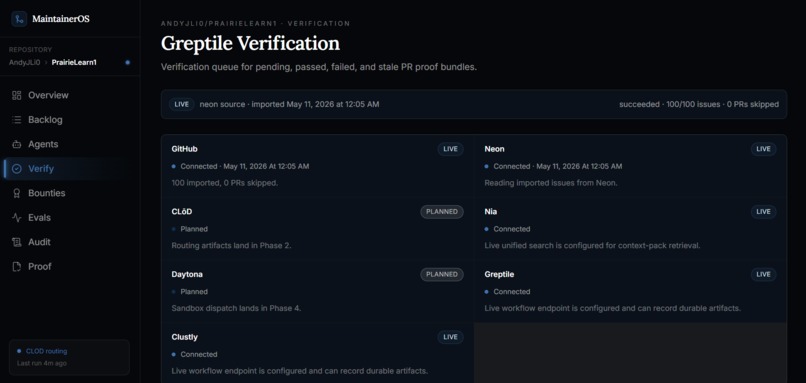
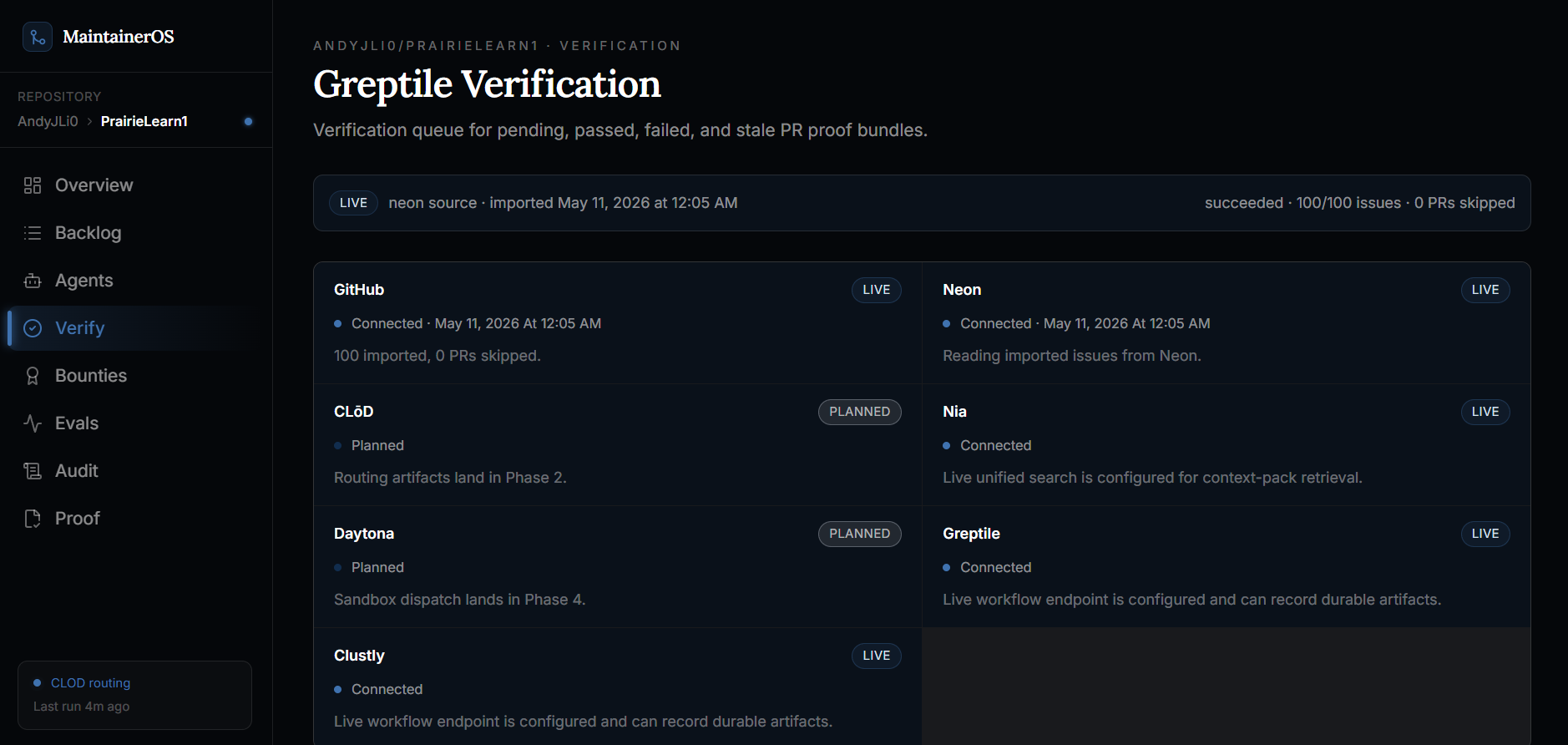
Greptile verification history
MaintainerOS Devpost Submission
Inspiration
Open-source maintainers do not just have a backlog problem. They have a trust problem.
Every healthy repository has issues that look simple from the outside but carry hidden risk: missing context, stale code, unclear ownership, half-finished attempts, and fixes that are cheap to generate but expensive to review. The result is a painful tradeoff. Maintainers either move slowly, or they let automation touch their project without enough evidence, control, or accountability.
MaintainerOS was inspired by one question:
What if an open-source backlog could route itself into the right kind of work?
Some issues are safe for agents. Some need maintainer judgment. Some are valuable enough to become paid bounty work. Some should be clarified or closed before anyone spends time on them.
We built MaintainerOS to make that routing explicit, auditable, and useful.
What It Does
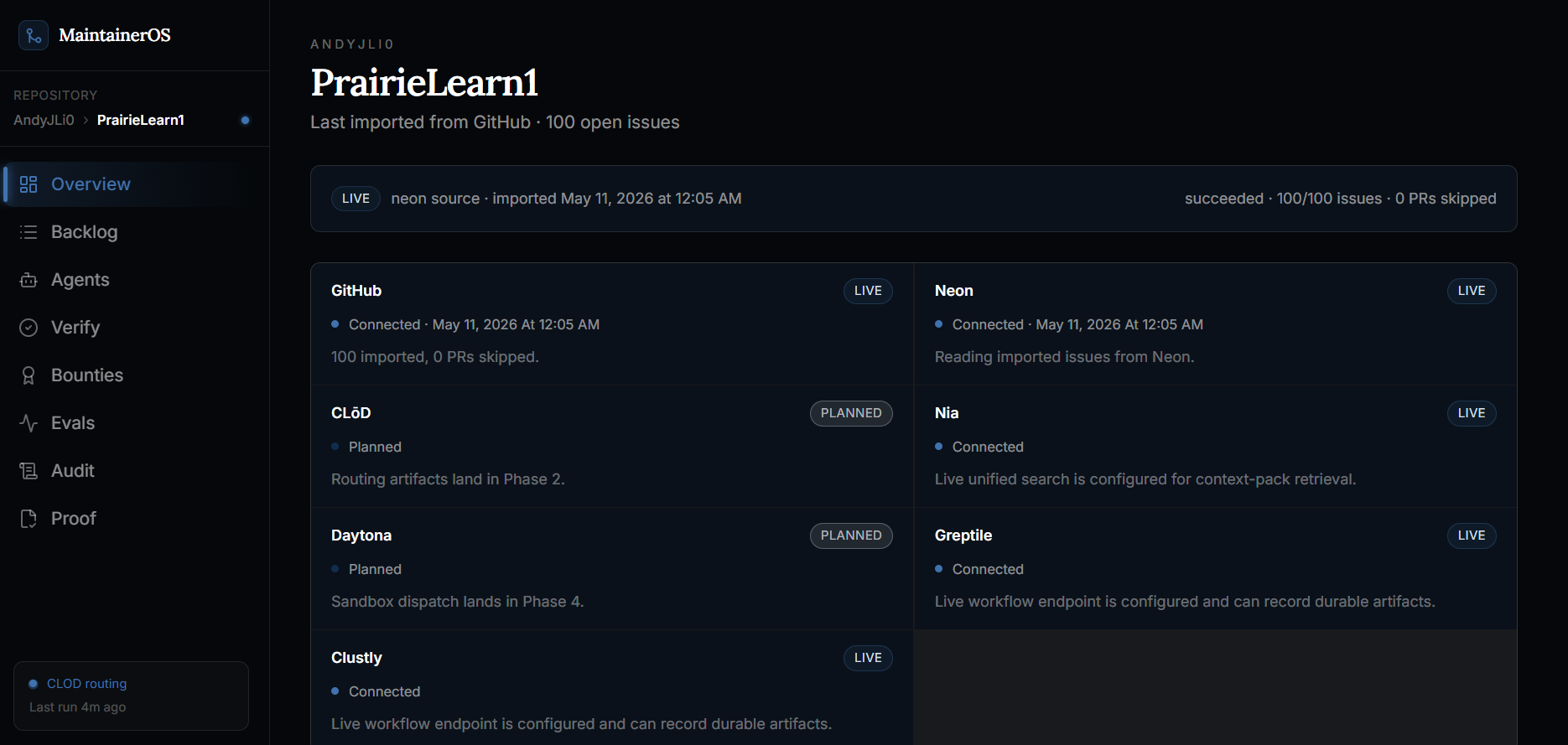
MaintainerOS turns a GitHub issue backlog into an operating system for maintainers.
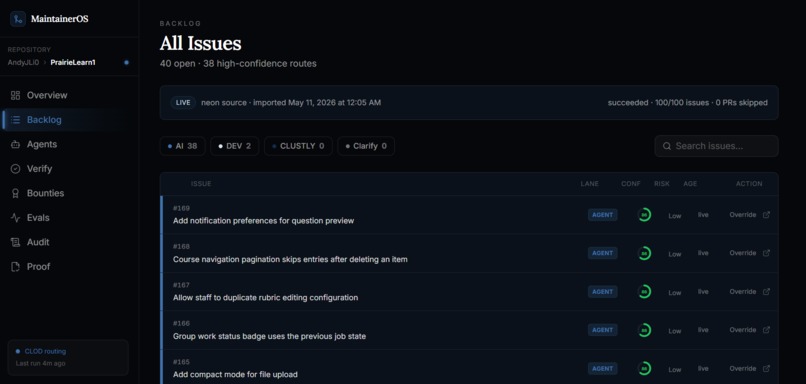
It imports real GitHub issues, analyzes them, and routes each one into a clear lane:
- Agent-safe: low-risk issues that can be attempted by an automated coding agent.
- Maintainer review: higher-risk issues that need human judgment before work starts.
- Bounty-worthy: issues that can become paid Clustly tasks with payout artifacts.
- Clarify or close: issues that need more information before anyone invests time.
The core idea is that automation should not be trusted just because it produced a pull request. MaintainerOS tracks the full lifecycle from issue import to final release decision:
issue import -> route decision -> context pack -> sandbox attempt -> PR -> verification -> maintainer acceptance -> payout eligibility
For bounty work, payout release is gated by explicit checks:
release = bounty + funded + linkedPR + freshVerification + maintainerAcceptance
If anything is missing, MaintainerOS explains exactly why release is blocked. It does not hide failures behind vague statuses.
The result is a maintainer control plane: agents can move fast on safe work, humans keep authority over judgment calls, and contributors can earn through verified, auditable workflows.
How The Flow Works
MaintainerOS is built around one principle: every issue should move to the right next step, not the fastest next step.
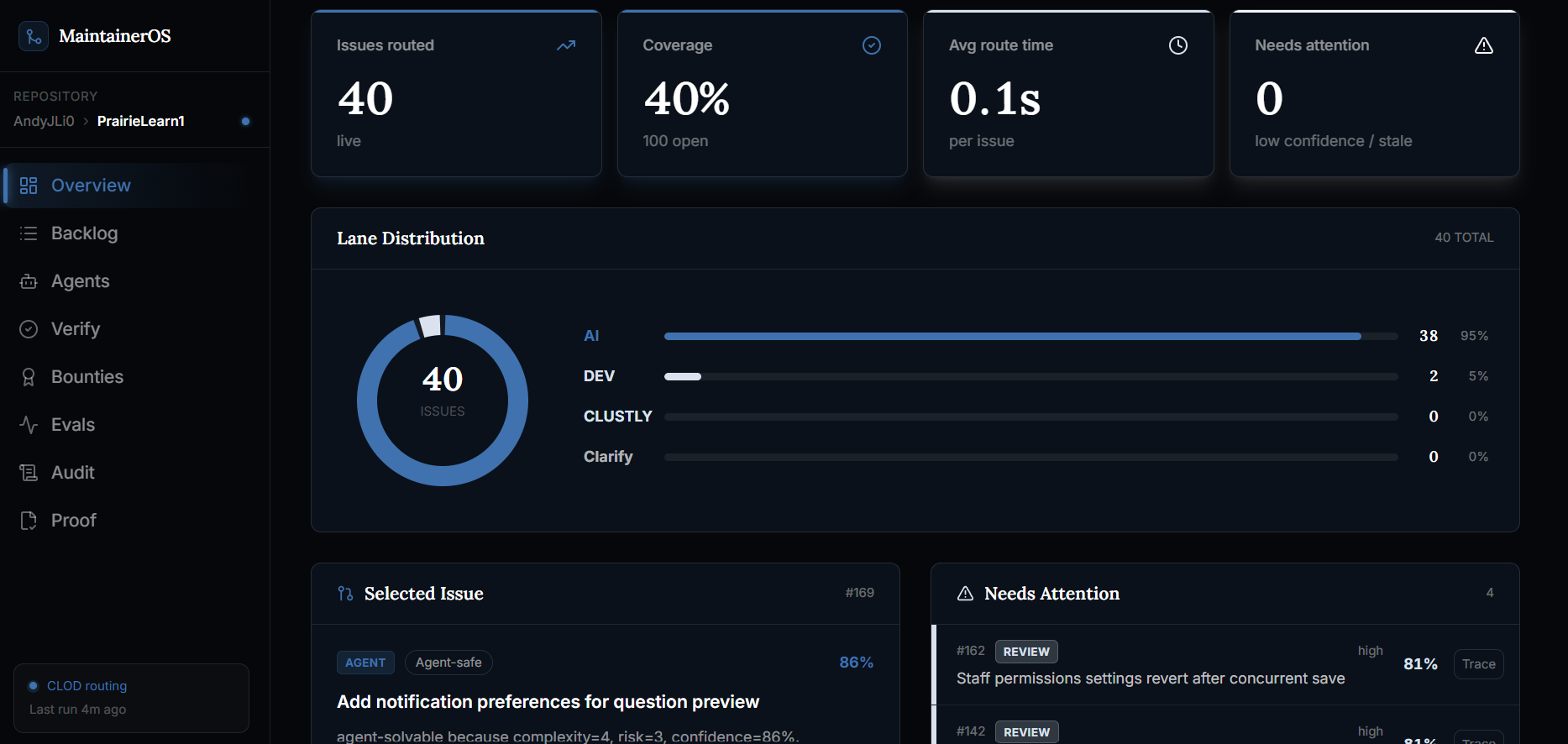
The flow starts when MaintainerOS imports a GitHub backlog and normalizes each issue into structured signals: title, body, labels, repository context, risk indicators, suggested files, prior attempts, and policy constraints. From there, CLOD performs the first routing pass. It classifies the issue by asking whether the work is low-risk and executable, ambiguous and blocked, risky enough for maintainer review, or valuable enough to become paid contributor work.
CLOD does not get unchecked authority. Its classification is wrapped by deterministic routing policy. Hard-block labels like security or decision-needed force maintainer review. Low confidence routes away from automation. Missing requirements send an issue to clarify-or-close. Only issues that pass the safety policy become agent-safe.
The main routes are:
- Agent-safe: clear, low-risk work that can be attempted automatically.
- Maintainer review: risky work, architecture decisions, security concerns, or anything requiring human judgment.
- Bounty-worthy: valuable work that should become a paid contributor task instead of an automated attempt.
- Clarify or close: issues that are too vague, stale, incomplete, or not actionable yet.
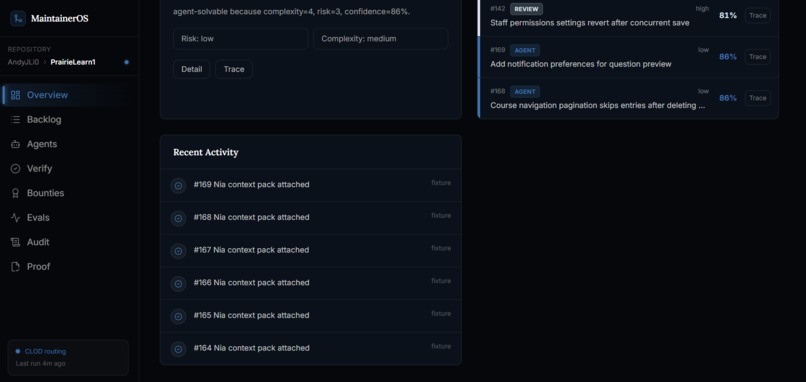
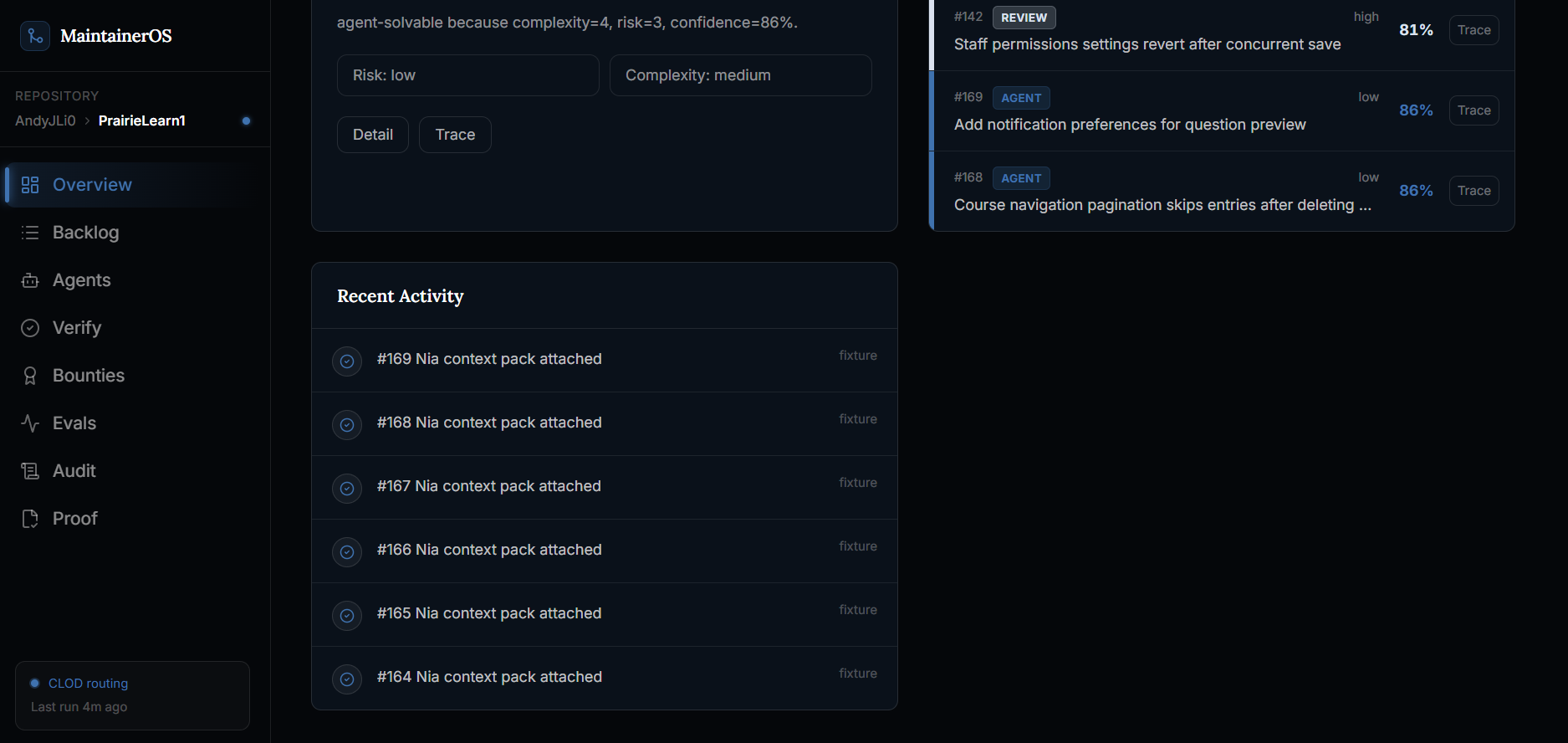
Once an issue is routed, MaintainerOS creates an evidence trail. It records the route decision, why that route was chosen, what policy gates passed or blocked, and what artifact should happen next.
Agent Execution And Daytona Isolation
For agent-safe issues, MaintainerOS does not let an agent work directly against the maintainer's repository.
The agent attempt is isolated through a Daytona-style sandbox flow. Each attempt gets its own environment, branch, command plan, context mode, logs, files touched, exit status, failure reason, and PR handoff. That matters because maintainers need to review what happened, not just see that a bot opened a pull request.
The sandbox record answers the questions maintainers actually care about:
- What commands did the agent run?
- Which files did it touch?
- Did the attempt pass, fail, or stop early?
- Was it using baseline context or an enriched context pack?
- Did it open a PR?
- If it failed, is the failed attempt preserved for review?
If the cheap or first-pass attempt fails, MaintainerOS escalates instead of pretending the system succeeded. The issue can move to a deeper retry, maintainer review, or bounty routing depending on the failure reason and route policy.
Escalation Model
Escalation is one of the core product ideas.
MaintainerOS assumes that automation will sometimes be wrong, incomplete, stale, or too uncertain. The system is designed to preserve those failures and route them intelligently.
Examples:
- If an issue has security, auth, data-loss, or decision-heavy signals, it escalates to maintainer review before any agent execution.
- If CLOD confidence is too low, automation is blocked and the issue goes to maintainer review or clarification.
- If an agent attempt fails in Daytona isolation, the failed attempt remains visible with logs, commands, files touched, and failure reason.
- If a PR is opened but verification fails, the work is not considered complete.
- If verification passed against an old SHA, it becomes stale and blocks merge readiness.
- If bounty payout gates are missing, release is blocked with explicit reasons.
The goal is not to automate everything. The goal is to make every handoff obvious: agent, maintainer, contributor, verification, or close.
Verification And Trust Gates
MaintainerOS treats verification as a trust boundary.
A generated PR is not accepted just because it exists. It has to pass verification, and that verification has to be fresh. If the PR changes after verification, the old result no longer counts.
That gives the system a simple rule:
trustedPR = linkedPR + passedVerification + currentHeadSHA
For bounty work, payout release has an even stricter gate:
release = bounty + funded + linkedPR + freshVerification + maintainerAcceptance
If any part is missing, MaintainerOS blocks release and explains why. This keeps payment, merge readiness, and automation completion tied to evidence instead of status labels.
How We Built It
We built MaintainerOS as a Next.js and TypeScript application with a provider-oriented architecture.
The system starts with a GitHub import layer that reads issue backlogs and stores live or demo-ready workflow state. From there, CLOD routes issues using a mix of model judgment and deterministic policy gates. Nia-style context packs provide repository-aware evidence so contributors and agents understand relevant files, citations, and suggested commands before work begins.
For execution, we modeled Daytona-isolated sandbox attempts as durable artifacts. MaintainerOS captures commands run, files touched, logs, PR URLs, duration, status, context mode, and failure reasons. This makes agent work inspectable instead of magical.
For verification, MaintainerOS tracks PR links, verification status, inspected files, blocking findings, current PR SHA, and verified SHA. Stale verification cannot unlock completion, merge readiness, or payout release.
For bounty workflows, MaintainerOS separates bounty lifecycle from payout readiness. A bounty can be funded, claimed, submitted, or approved, but release-ready is derived from gates, not manually stored as a status.
We also built a trace ledger so maintainers can see why the system made each decision. The demo includes controls for happy paths, failed cheap attempts, stale verification, blocked bounty release, and successful release.
Challenges We Faced
The hardest part was keeping the product honest.
It is easy to build a demo where every integration looks successful. It is much harder to build one where failures, stale checks, missing approvals, fixture data, and blocked releases are clearly labeled. We spent a lot of time making sure the system could explain not only what happened, but why something was not allowed to proceed.
Another challenge was treating verification as a real gate. A PR can change after verification, so we made SHA freshness part of the core logic. If the verified SHA does not match the current PR head SHA, the verification is stale and blocks completion, merge readiness, and payout release.
We also had to separate bounty lifecycle state from payout readiness. A bounty can be funded, claimed, submitted, or approved, but "release-ready" should be derived from evidence gates. That made the system more reliable and easier to reason about.
What We Learned
We learned that maintainers need more than automation. They need auditability.
The useful product is not "AI fixes your issues." The useful product is a workflow where every decision has evidence, every artifact has a source, and every risky action has a gate.
LLMs can help with routing, context, and execution, but deterministic checks need to own the final safety boundaries. Maintainers should never have to guess why a PR was trusted, why a bounty was blocked, or why an issue was routed to a human.
We also learned that demo reliability is product reliability. Reset, replay, and scenario controls are not just presentation features. They make the system testable, explainable, and easier to trust.
What's Next
Next, we want to deepen the live provider integrations, especially real Daytona sandbox execution, live Clustly funding and claim flows, and stronger GitHub workflow automation.
We also want to expand the evaluation suite, improve repository-specific policy controls, and give maintainers more direct authority over approval, rerouting, and release decisions.
Our long-term goal is for MaintainerOS to become the control plane for open-source maintenance: agents do the safe work, humans keep authority over judgment calls, and contributors can earn through verified, auditable bounty workflows.





Log in or sign up for Devpost to join the conversation.