-
-

MaidReal Head
-

Bald MaidReal Head
-

CAD Renger
-
CAD Image
-
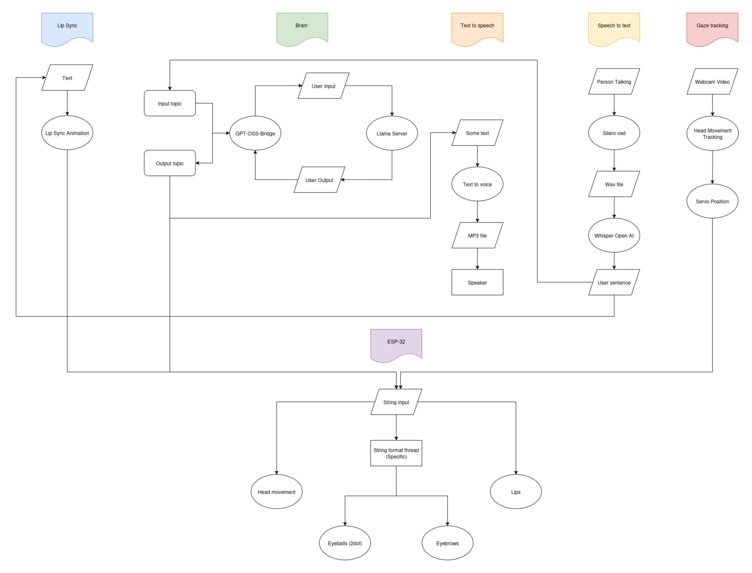
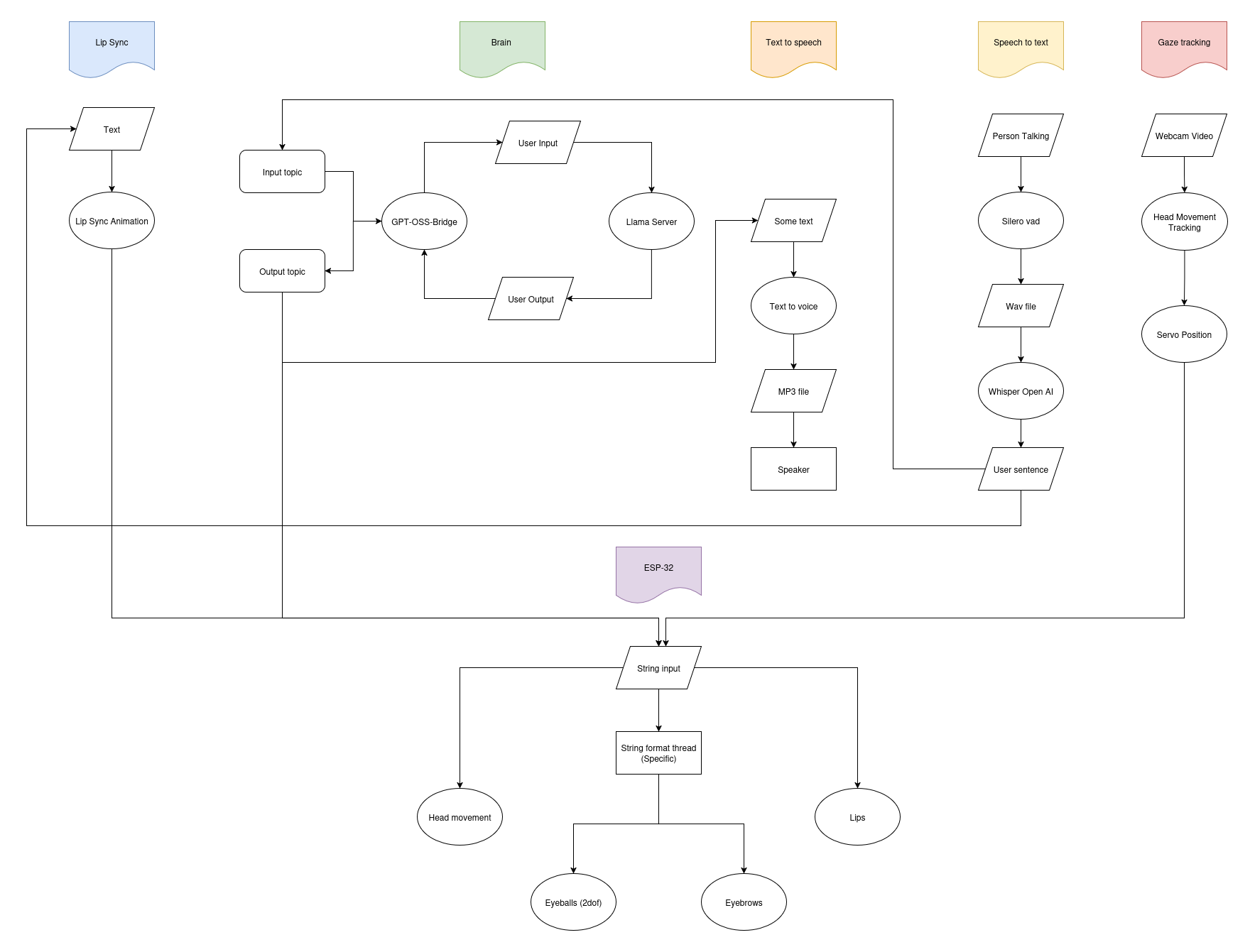
Software flowchart



About the Project
We wanted to push large language models beyond text and into physical expression. Human communication isn’t just words — it’s tone, gaze, and subtle body language. Our goal was to let an AI “express itself” the same way, by giving it a robot head that can move with intention and emotion.
What It Does
- Tracks gaze and head position in real time.
- Speaks naturally with lip-sync and emotional intonation.
- Moves eyes, mouth, and head servos based on the AI’s reasoning.
- Runs fully locally — no cloud dependence, everything on one machine.
- Uses llama.cpp in a ROS2 node, so the LLM doesn’t just generate text — it also decides how to move. For example, the AI might tilt its head curiously, nod while speaking, or glance away as if thinking.
What Inspired Us
We were inspired by the idea of humanizing AI — not in a gimmicky way, but as a step toward robots that feel more alive and approachable. From companion robots to educational assistants, adding nonverbal communication makes AI far more engaging, relatable, and trustworthy. We wanted to prove that AI can be more than just a voice in a box.
How We Built It
Core AI Node: llama.cpp running GPT-OSS models, bridged into ROS2.
Audio Stack: Silero VAD for voice activity detection, Whisper for speech-to-text, and Zonos for low-latency text-to-speech.
Motion Control: Servos driven by ROS2 topics, with a custom motor reasoning layer mapping LLM outputs into expressive physical motions.
Face Behaviors: Lip-sync tied to waveform analysis, gaze tracking with OpenCV, and servo primitives for nodding, tilting, and expressive gestures.
Local Integration: All components containerized and optimized for GPU acceleration in WSL2/Ubuntu, functional on a laptop.
What We Learned
- How to make LLMs interact with real-time hardware, not just generate words.
- The importance of timing and synchronization between speech, lip-sync, and servo motion.
- Techniques for squeezing maximum performance out of limited hardware (VRAM, CPU/GPU).
- That running speech + vision + LLM reasoning fully locally is possible with careful optimization.
- First-hand experience with CAD design and rapid prototyping, combining Blender and Fusion for both organic mesh modelling and parasolid editing for servo joints.
- Using freeRTOS to allow multiple tasks to run simultaneously
Challenges We Faced
Servo expressiveness: Designing motion mappings that “feel” human instead of robotic.
CAD and prototyping: Iterating mechanical designs — first time modeling in Blender, then refining in Fusion.
Latency: Keeping STT → LLM → TTS → servo response under conversational speeds.
Model performance: Balancing speed, accuracy, and expressiveness on limited laptop hardware.
VRAM allocation: Deciding which models and tools could coexist while maximizing tokens-per-second.
System optimization: Debugging audio in WSL, juggling ROS2 nodes, and squeezing efficiency from every component.
What's next for MaidReal Head
More expressions: Eyelid blinking & tilting, lip shaping, eyebrow movement, and subtle facial gestures.
Hardware upgrades: Swap MG90s servos for stronger 25kg-class servos, move from ESP32 to a more powerful MCU.
Customization: Allow users to choose voices, personalities, and even facial designs.
Improved aesthetics: Better face shell design, custom colors, and smoother 3D-printed parts.
Expanded embodiment: Add arms, shoulders, and body language for richer communication.
Contextual expressions: Link servo motions more tightly to conversation context
Adaptive learning: Let the AI refine its motion style over time, personalizing its expressiveness to the user.
Multi-agent interaction: Imagine multiple heads/robots talking to each other with gestures and expressions, not just words.



Log in or sign up for Devpost to join the conversation.