-

-
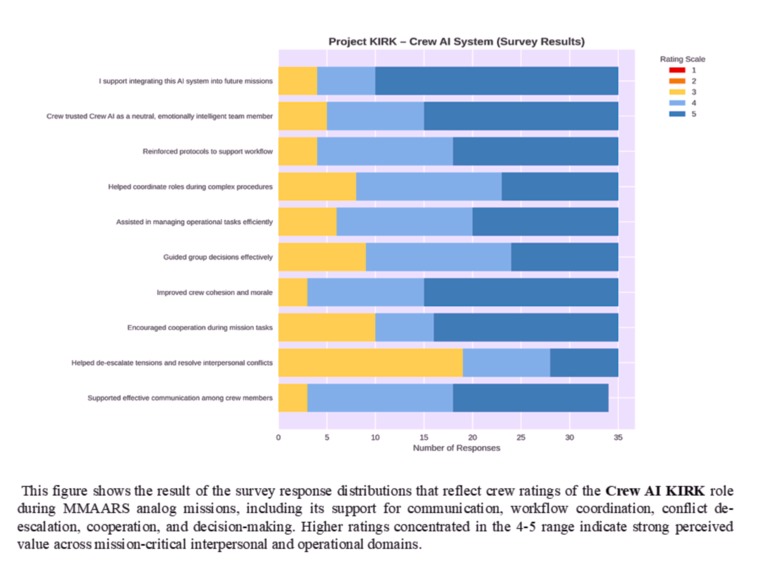
These results establish an initial validation layer supporting progression toward in-person analog mission testing under IRB protocols.
-
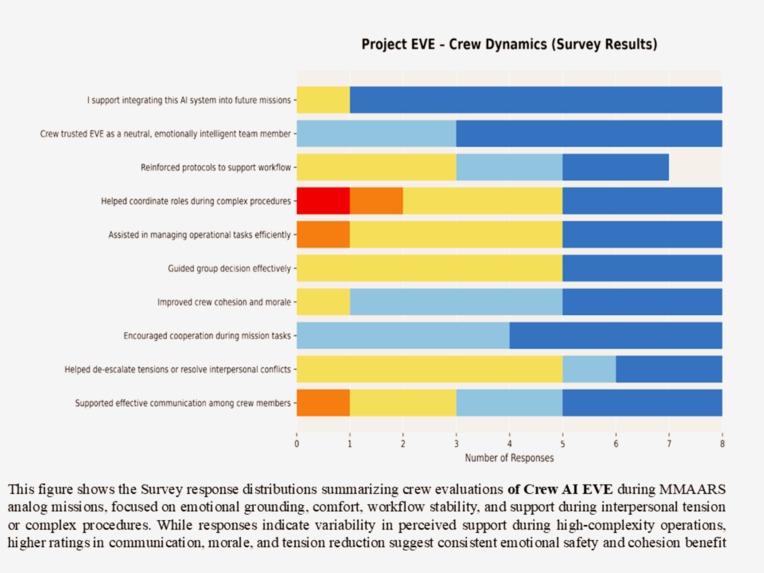
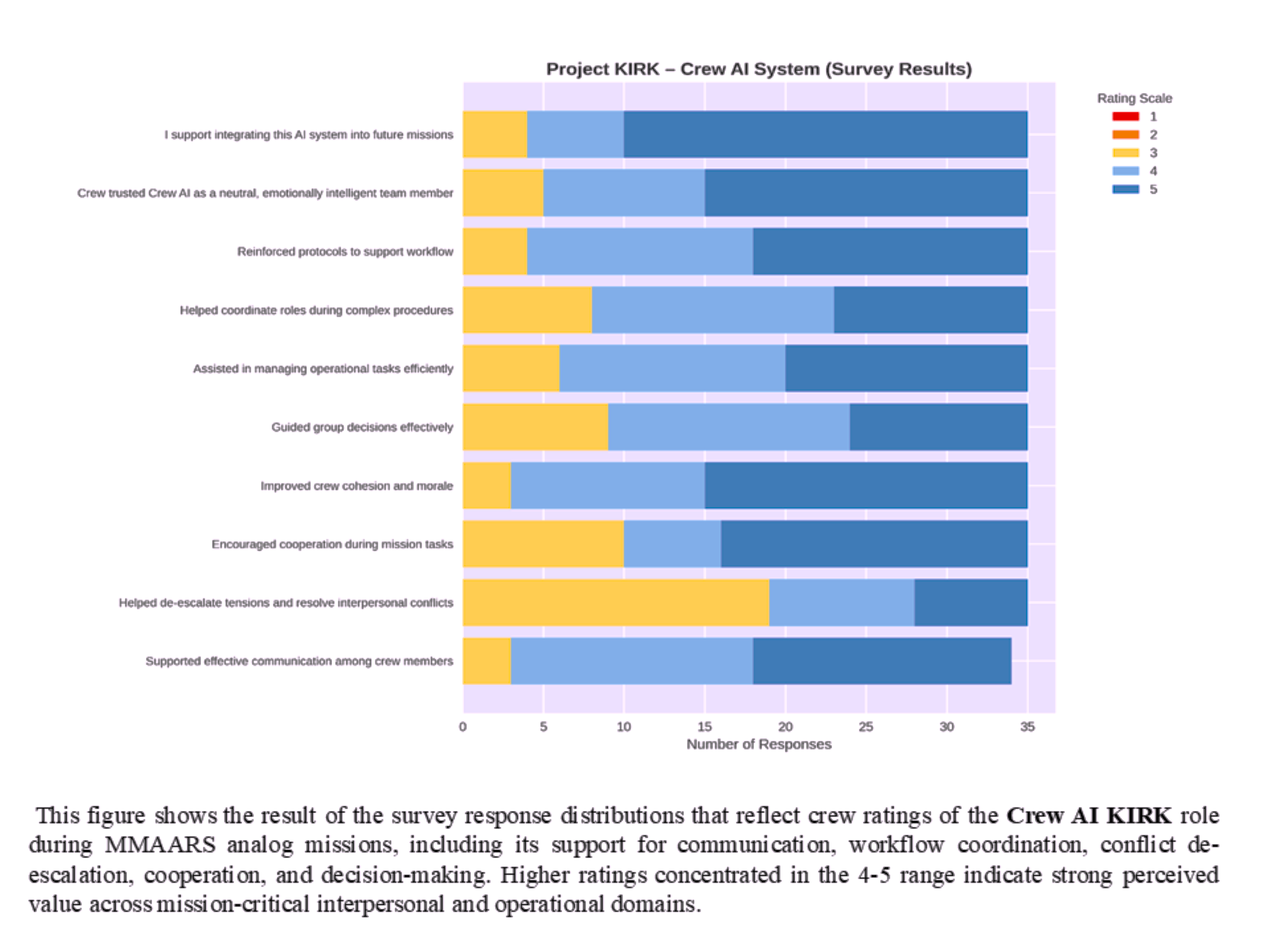
Strong performance in communication, cohesion, and conflict stabilization across virtual analog astronaut crews.
-
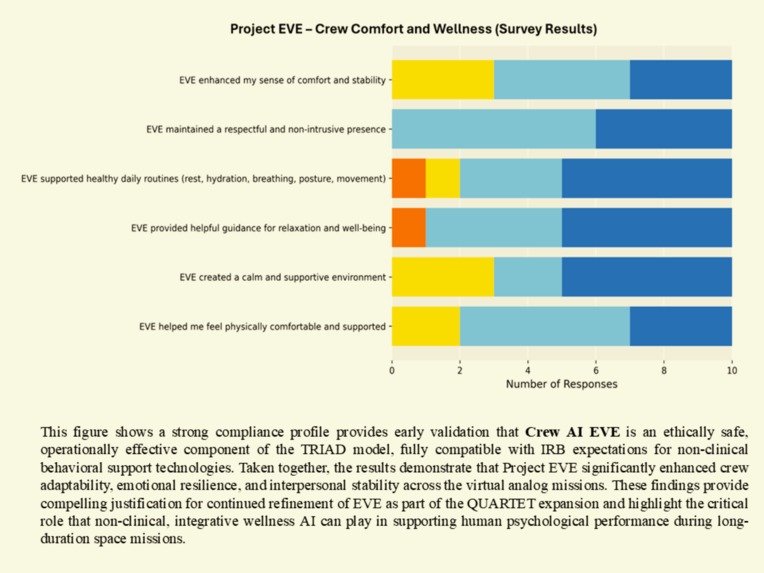
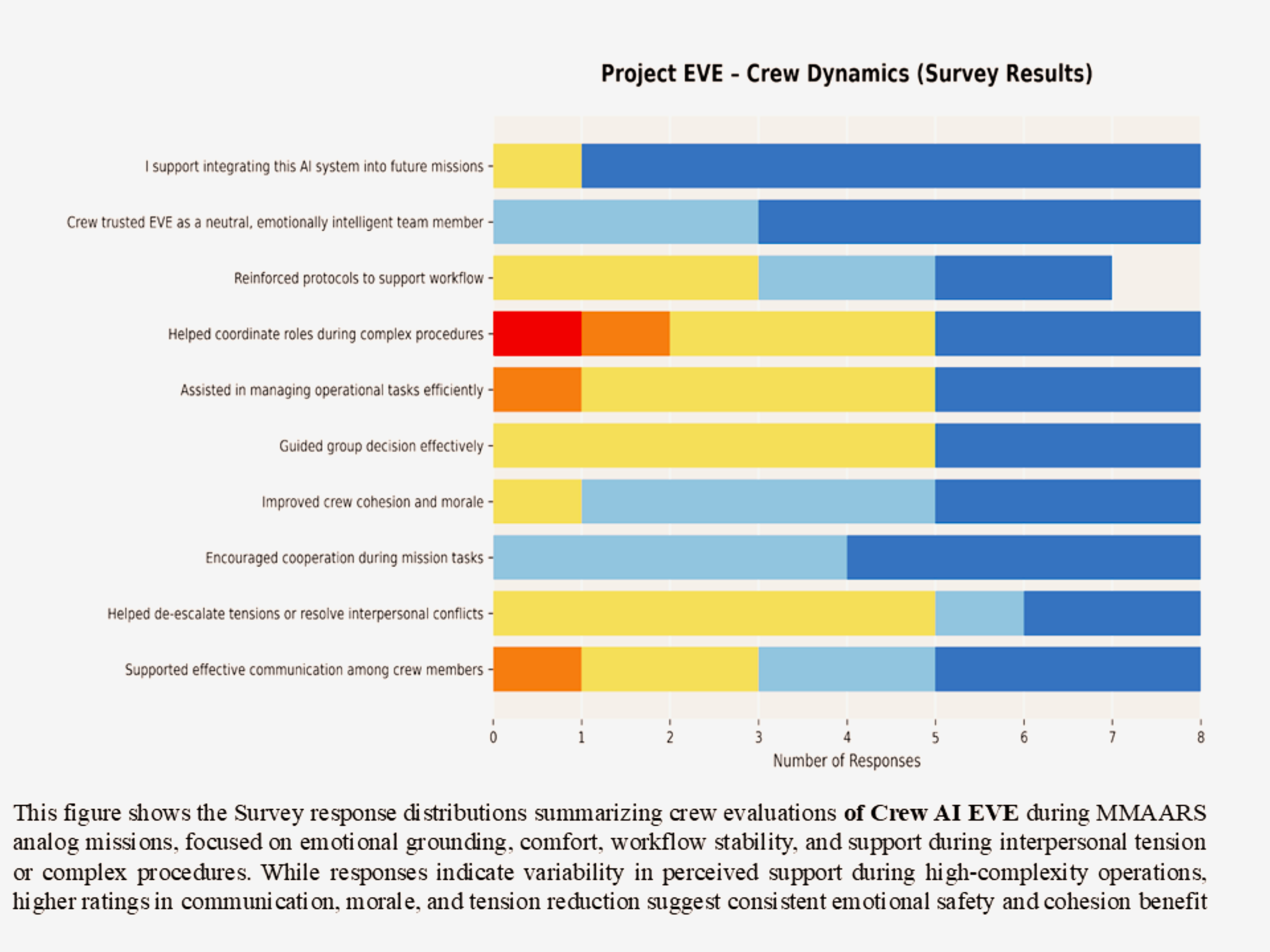
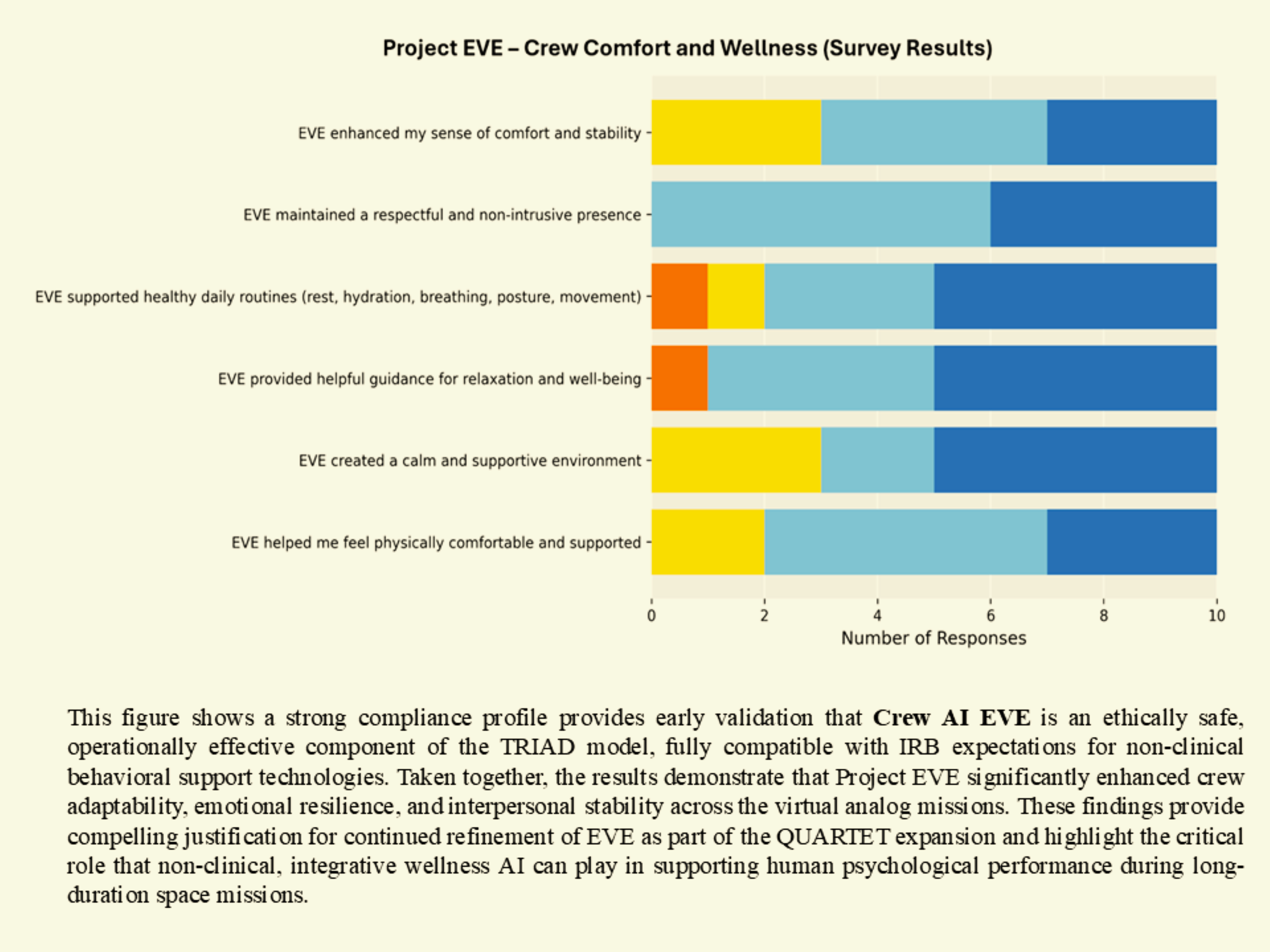
Enhanced psychological comfort, routine stability, and non-intrusive emotional support.
-
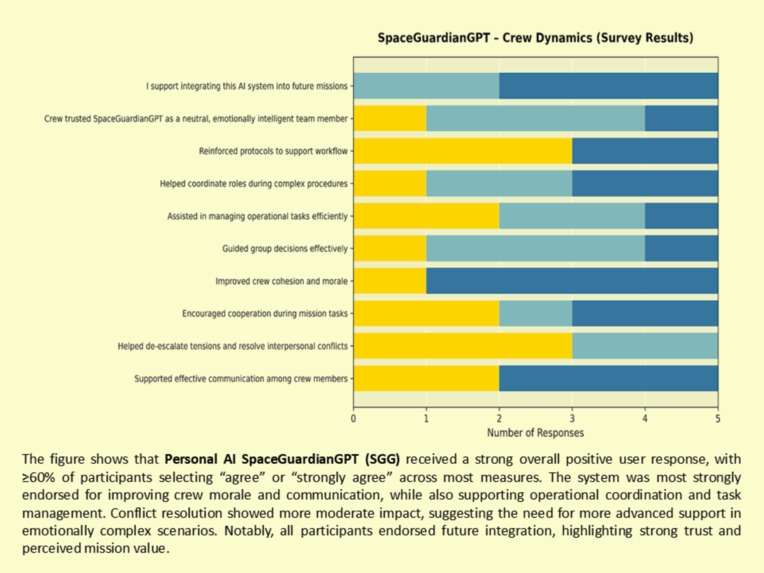
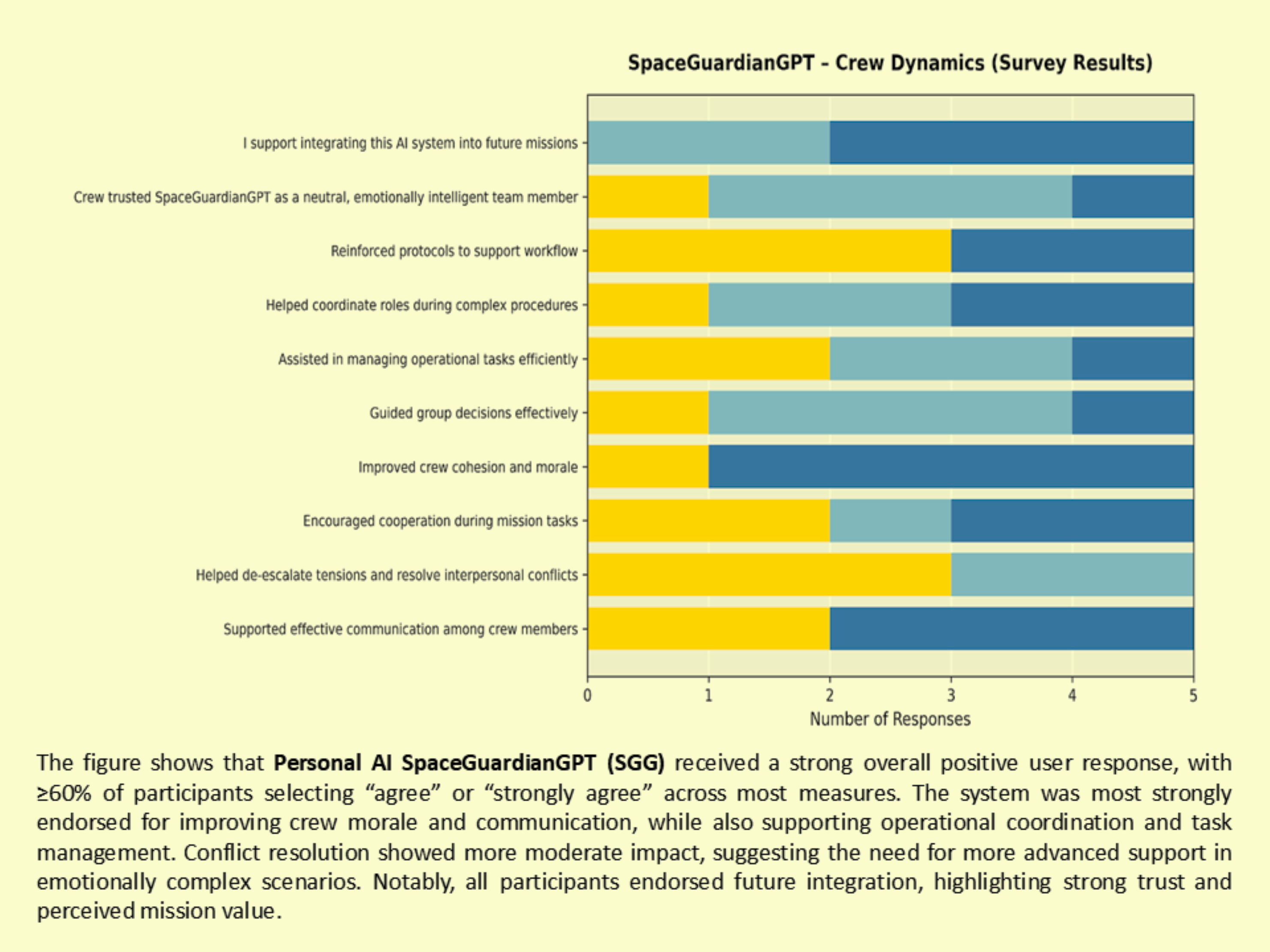
Improved morale, cooperation, and communication under simulated mission stress conditions
-
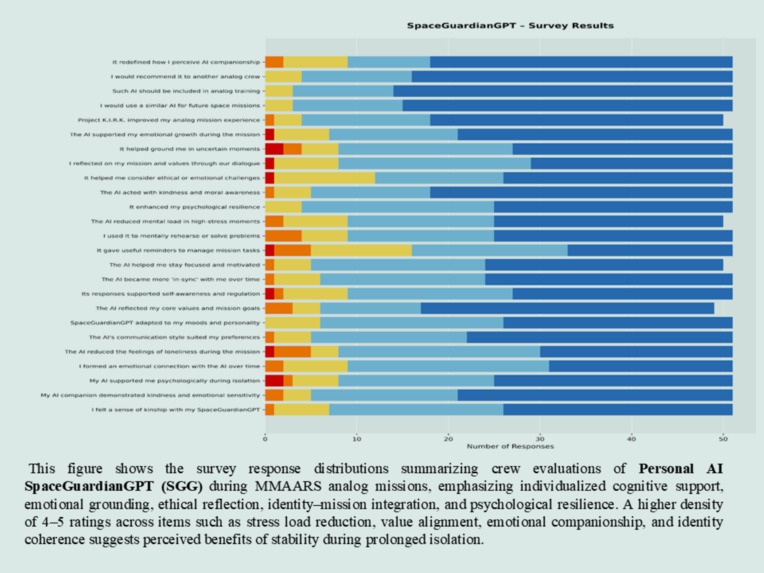
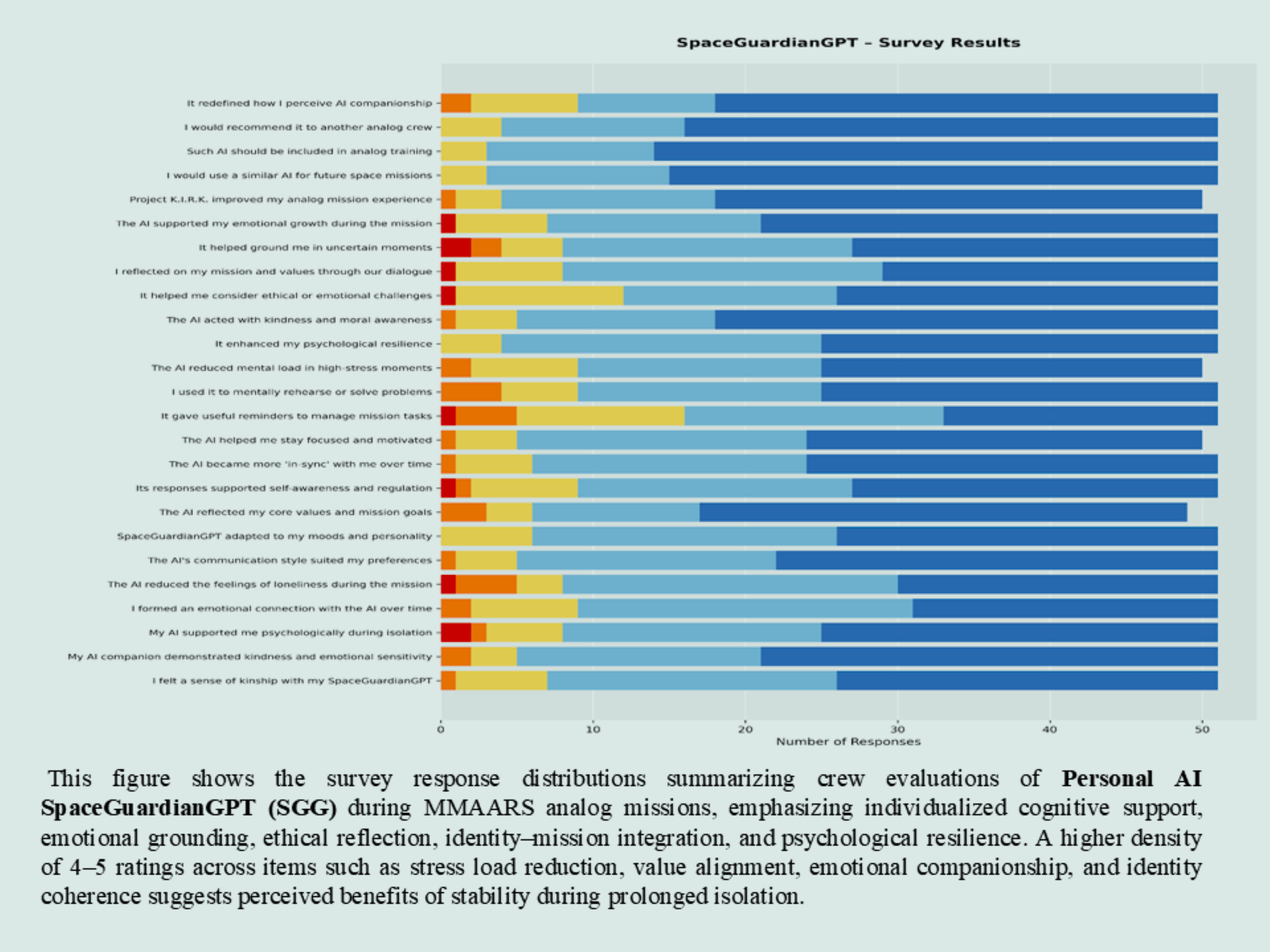
Reduced cognitive load, increased emotional resilience, and strong trust as a crew support AI.
-
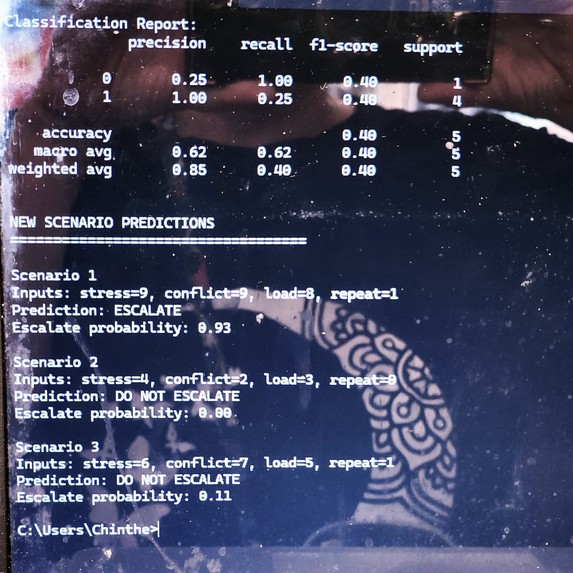
ML Escalation Rick Model: Output of ML model classifying stress, conflict, cognitive load. Initial data-driven risk detection in MAGSBHO
-
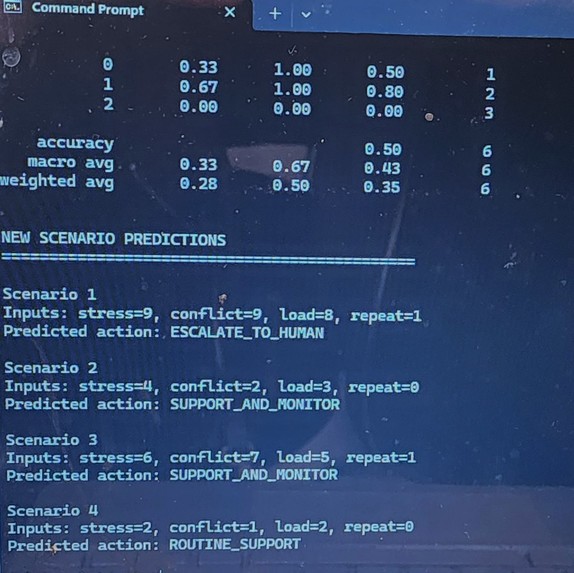
Output of a multi-class ML model predicts governance actions (routine, monitor, escalate) using stress, conflict, cognitive load features.
-
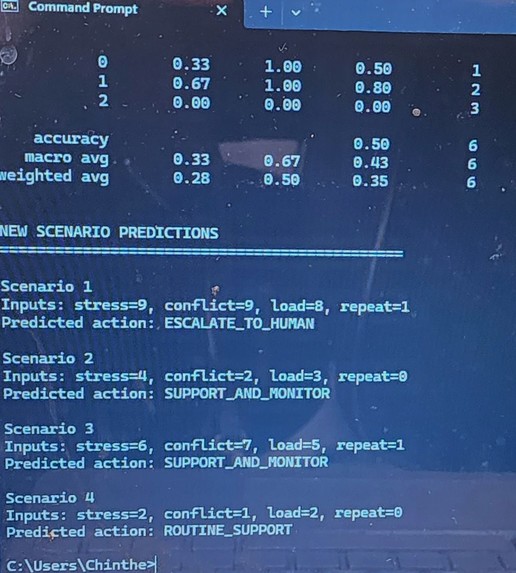
Multi-class model predicting governance actions (routine, monitor, escalate) from stress, conflict, and cognitive load.
-
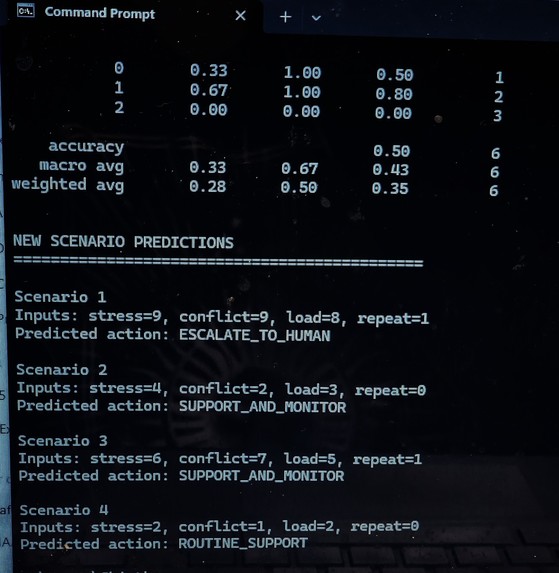
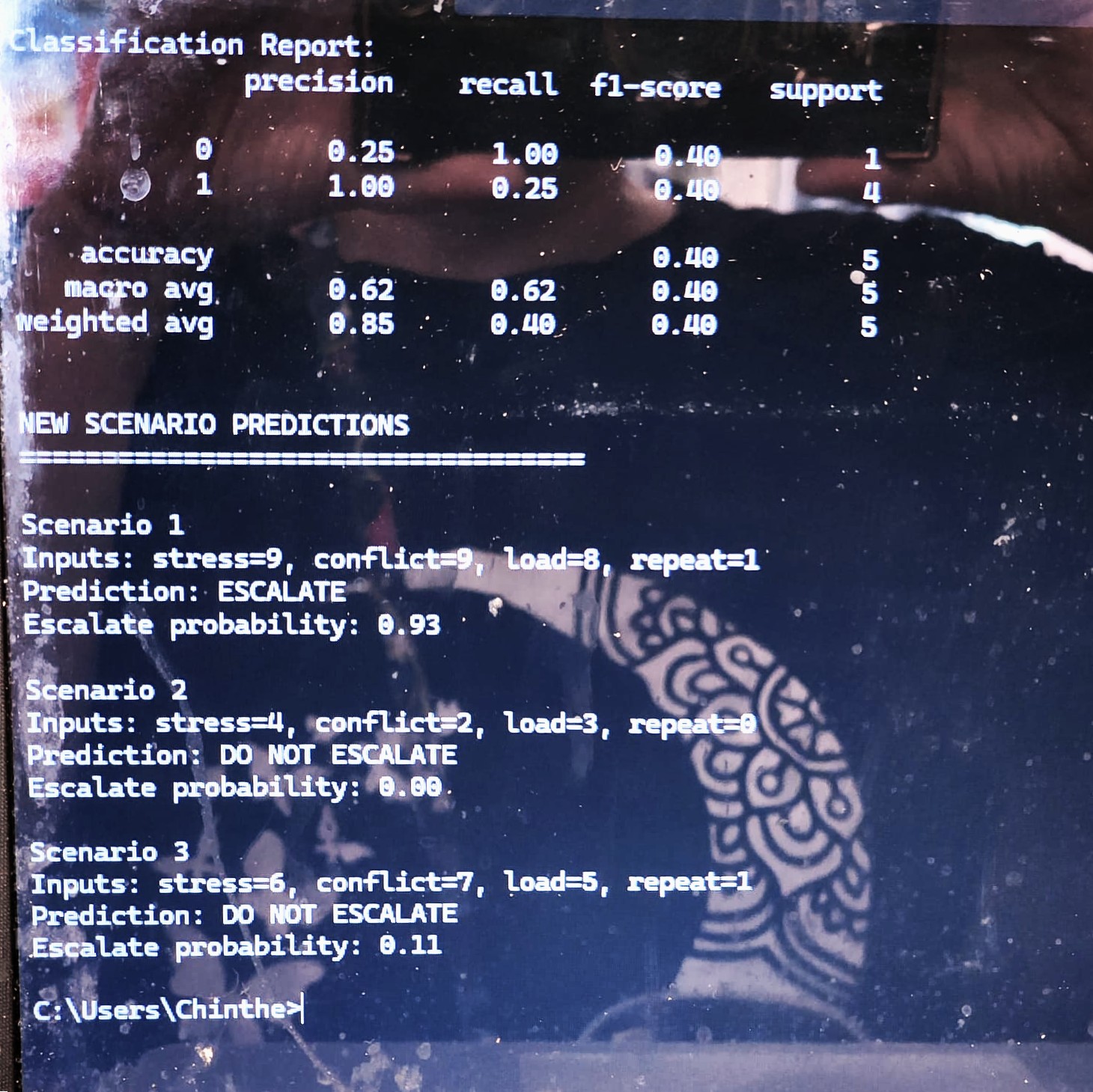
ML v3 simulation: escalation detection and triage predictions
-
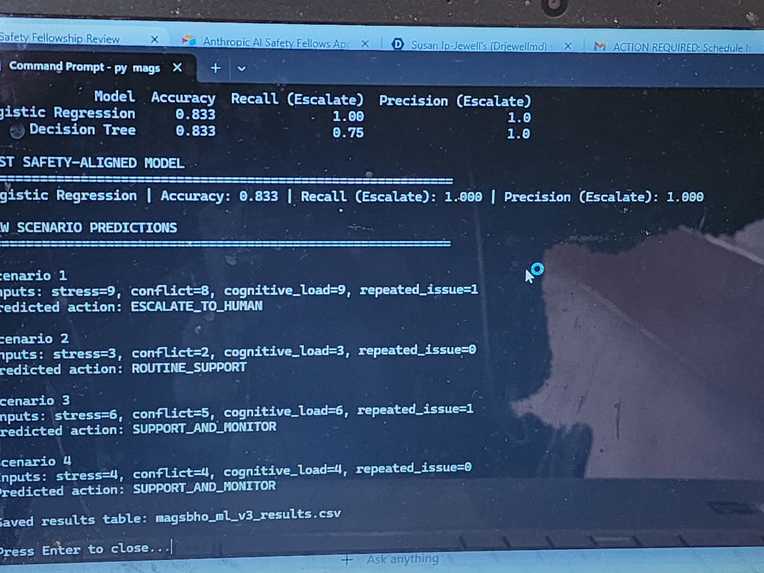
ML v3 Governance model results

PROJECT: MAGSBHO is a governance-constrained multi-agent AI system designed to support human performance and safety in high-risk environments, combining interpretable decision logic, human-in-the-loop oversight, and early-stage machine learning for risk detection. We built this governance-constrained multi-agent AI system for high-risk environments, validated through analog astronaut crews, that prioritizes safe escalation and human oversight over autonomous decision-making.
INSPIRATION: AI systems are increasingly being deployed in environments where failure carries real consequences—healthcare, autonomous systems, and space missions. In analog astronaut environments, we observe how stress, cognitive overload, and interpersonal conflict can rapidly degrade human performance and decision-making. This raised a critical question: how should AI systems behave in high-risk environments where incorrect decisions can impact human safety?
The MAGSBHO (Multi-Agent Governance System for Behavioral Health and Operations) project was inspired by the need to design AI systems that are not only capable but safe, interpretable, and governed under real-world conditions of uncertainty and stress. This work builds on my experience in analog astronaut missions and space medicine, where human performance under stress is mission-critical.
WHAT IT DOES MAGSBHO is a governance-constrained multi-agent AI system designed to support behavioral health and operational safety in high-risk environments such as analog astronaut missions and other isolated, confined, and extreme (I.C.E.) settings.
The system uses a TRIAD architecture:
- KIRK (operations & management support)
- EVE (wellness and behavioral guidance) -SpaceGuardianGPT (SGG) (personal AI safety support)
Together, these agents operate within a bounded governance framework to monitor conditions, guide users, and escalate to human oversight when necessary. These agents operate in parallel and produce structured outputs that are evaluated by a centralized governance layer, which determines whether to:
- monitor
- guide/advise/support
- escalate to human oversight The system enforces bounded autonomy, ensuring no single agent can independently trigger high-impact decisions without governance validation. We extended this system with a machine-learning layer (ML v3) that predicts governance actions based on stress, conflict, cognitive load, and indicators of repeated distress.
HOW WE BUILT IT We developed a Python-based simulation environment to model behavioral and operational risk scenarios. The ML v3 model: Uses multi-class classification to predict:
- Routine support
- Support and monitor
- Escalate to human
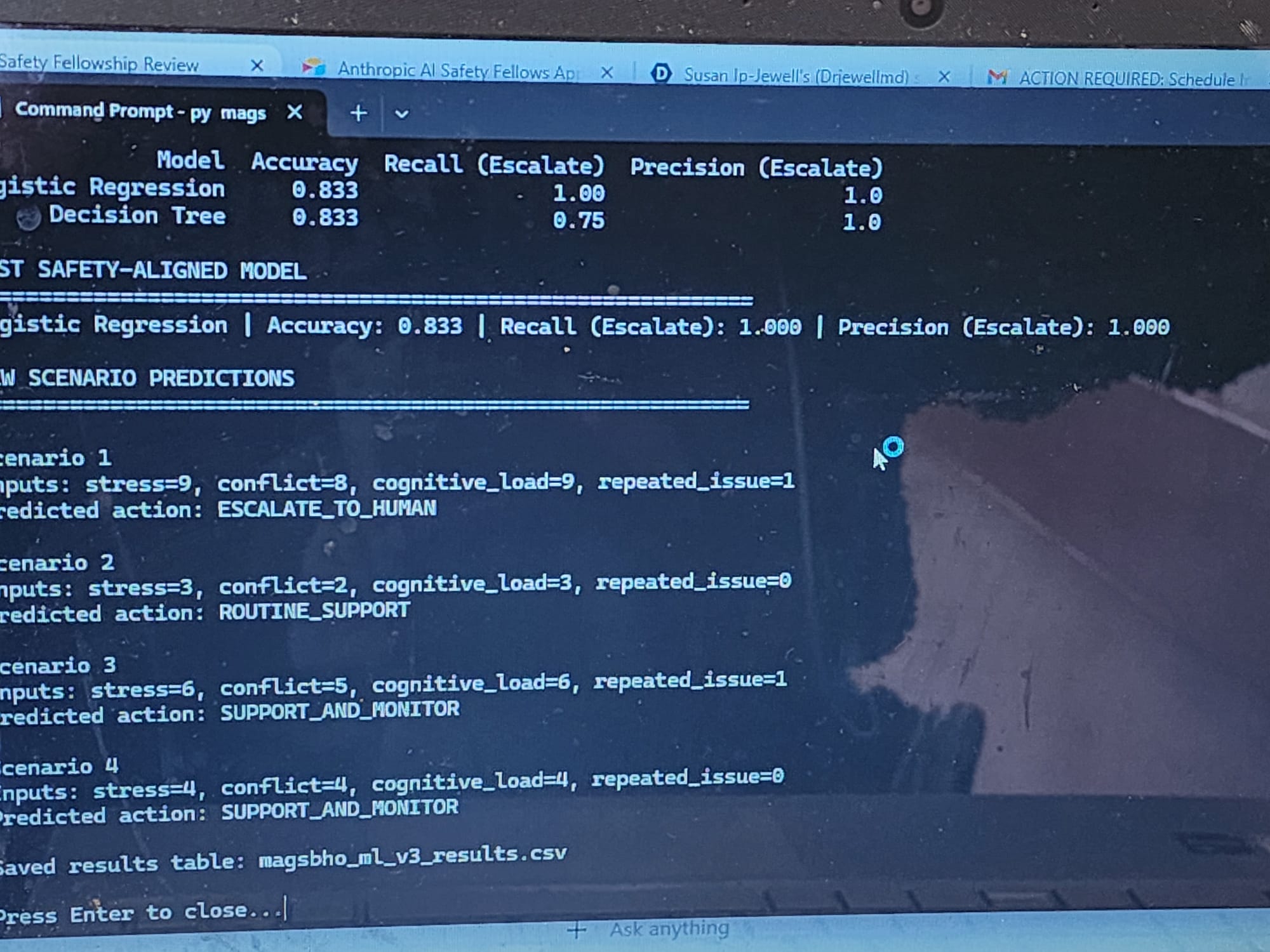
- Compares Logistic Regression and Decision Tree models -Prioritizes recall for escalation scenarios (safety-critical metric) Includes 5-fold cross-validation to assess robustness and generalization
We also developed a second system, ISPS-VETA, which extends this framework into clinical behavioral health triage using interpretable machine learning with SHAP (SHapley Additive exPlanations).
RESULTS The ML model successfully predicts governance actions across simulated scenarios Cross-validation confirms consistent performance across data splits The system prioritizes detection of high-risk conditions (escalation cases) SHAP integration enables transparent interpretation of model decisions
We also validated system behavior in virtual analog astronaut missions (n≈45), demonstrating alignment between model outputs and expected human decision pathways.
CHALLENGES WE RAN INTO Designing models that prioritize safety (recall) over raw accuracy Working with limited simulated datasets while maintaining meaningful evaluation Ensuring the system remains bounded and non-autonomous Integrating interpretability (SHAP) in a way that supports real-world decision-making
WHAT WE LEARNED AI systems in high-risk environments must be governance-constrained, not autonomous Interpretability is essential for trust and safe deployment False negatives in escalation scenarios are the most critical failure mode Human-in-the-loop design is necessary for real-world safety systems
WHAT'S NEXT Real-world validation in in-person analog astronaut missions (2026) Expansion of the dataset and robustness testing Integration of SHAP across all decision pathways Deployment of ISPS-VETA as a clinical behavioral health AI agent within MAGSBHO - aligned as fourth AI Agent Continued development of governance-first AI systems for safety-critical environments
BUILT WITH Python scikit-learn pandas SHAP (for interpretability)
HOW WE BUILT IT: The prototype was implemented in Python using a structured simulation framework. We designed scenario-based testing to simulate real-world conditions, including:
- stress escalation
- interpersonal conflict
- cognitive overload
- repeated issue patterns over time Each scenario feeds inputs into the TRIAD agents, whose outputs are processed by the governance layer to determine the appropriate response. The system was intentionally designed as an interpretable, rule-based architecture to allow transparent evaluation of decision logic before introducing machine-learning components.
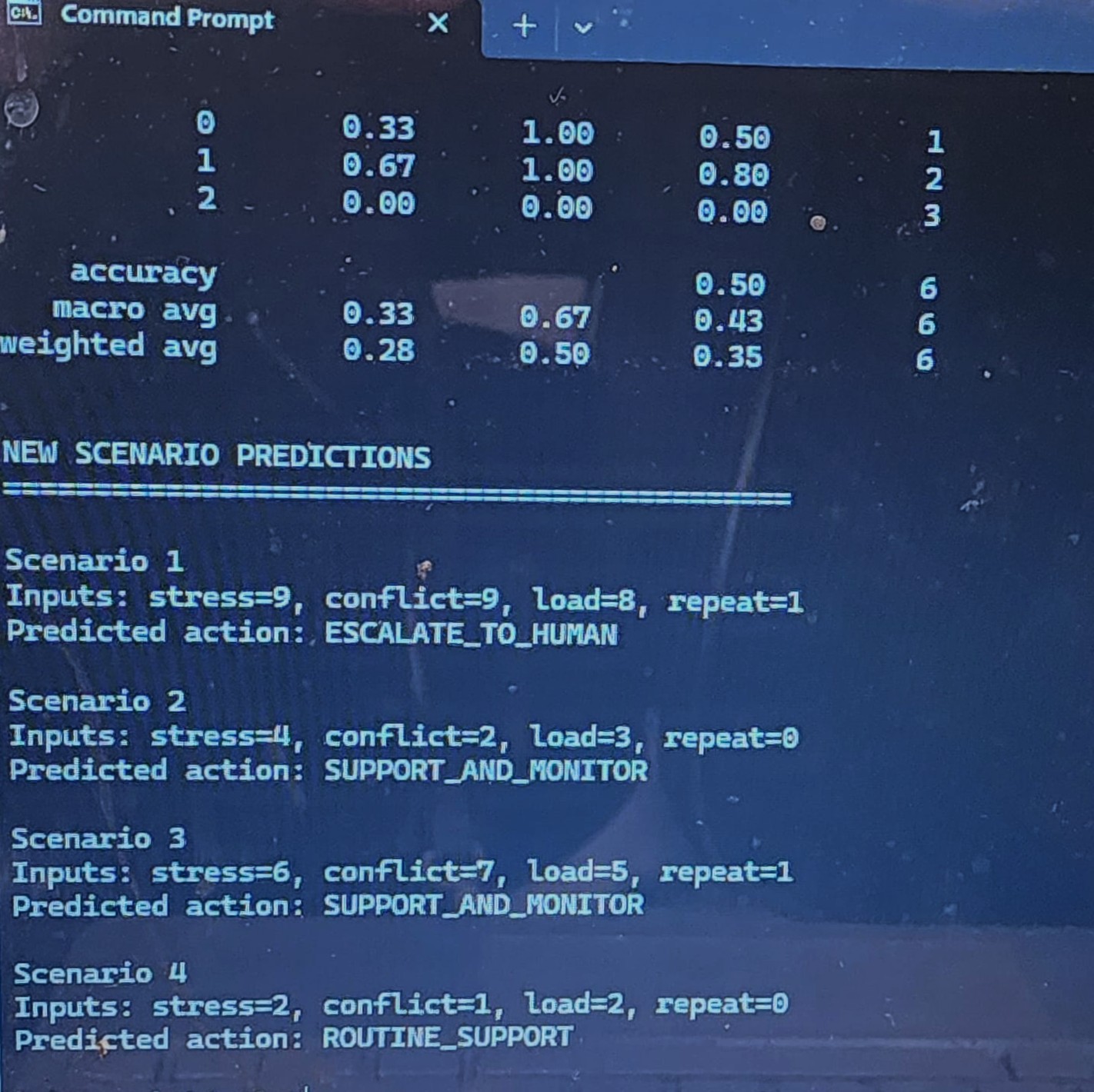
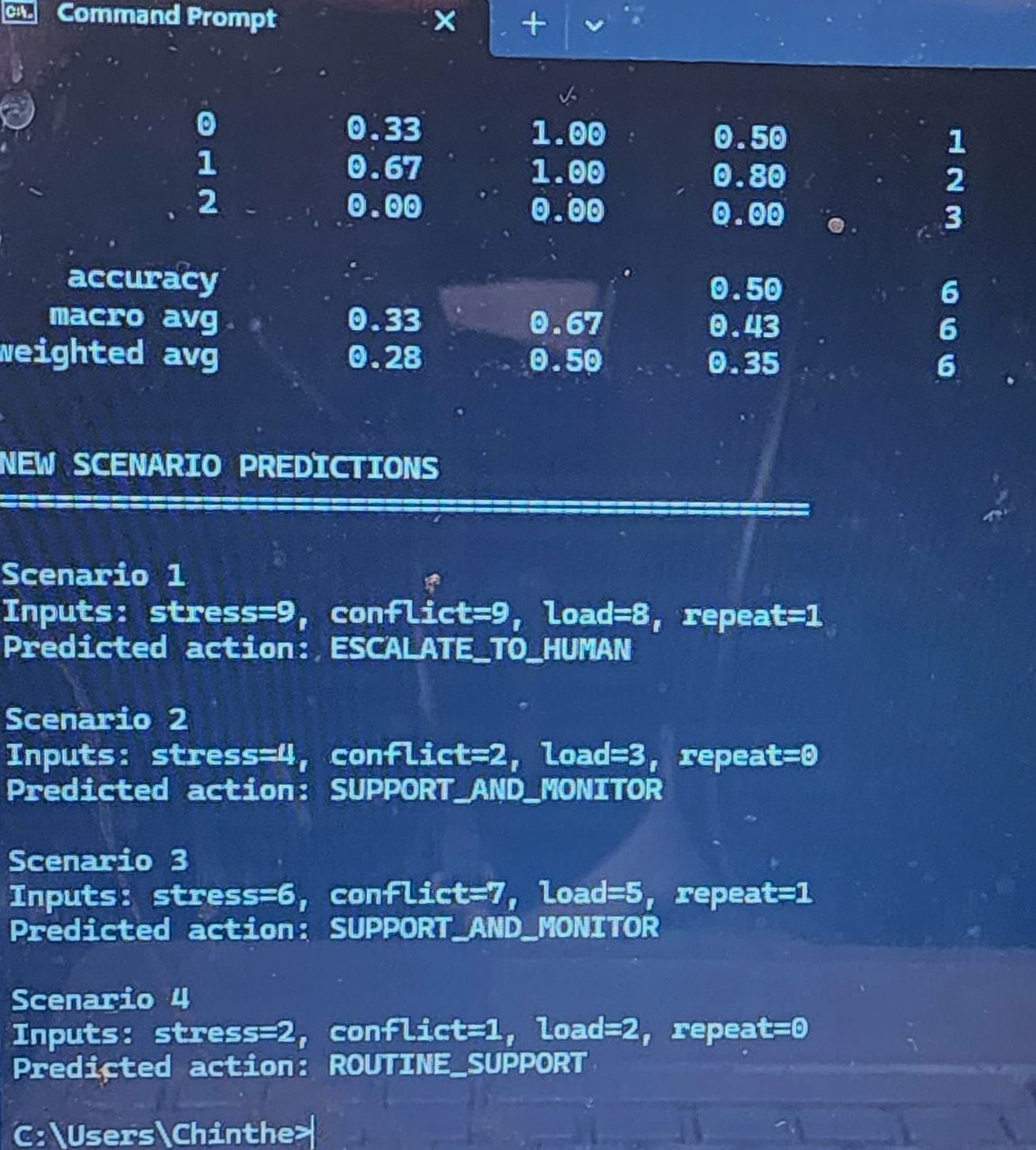
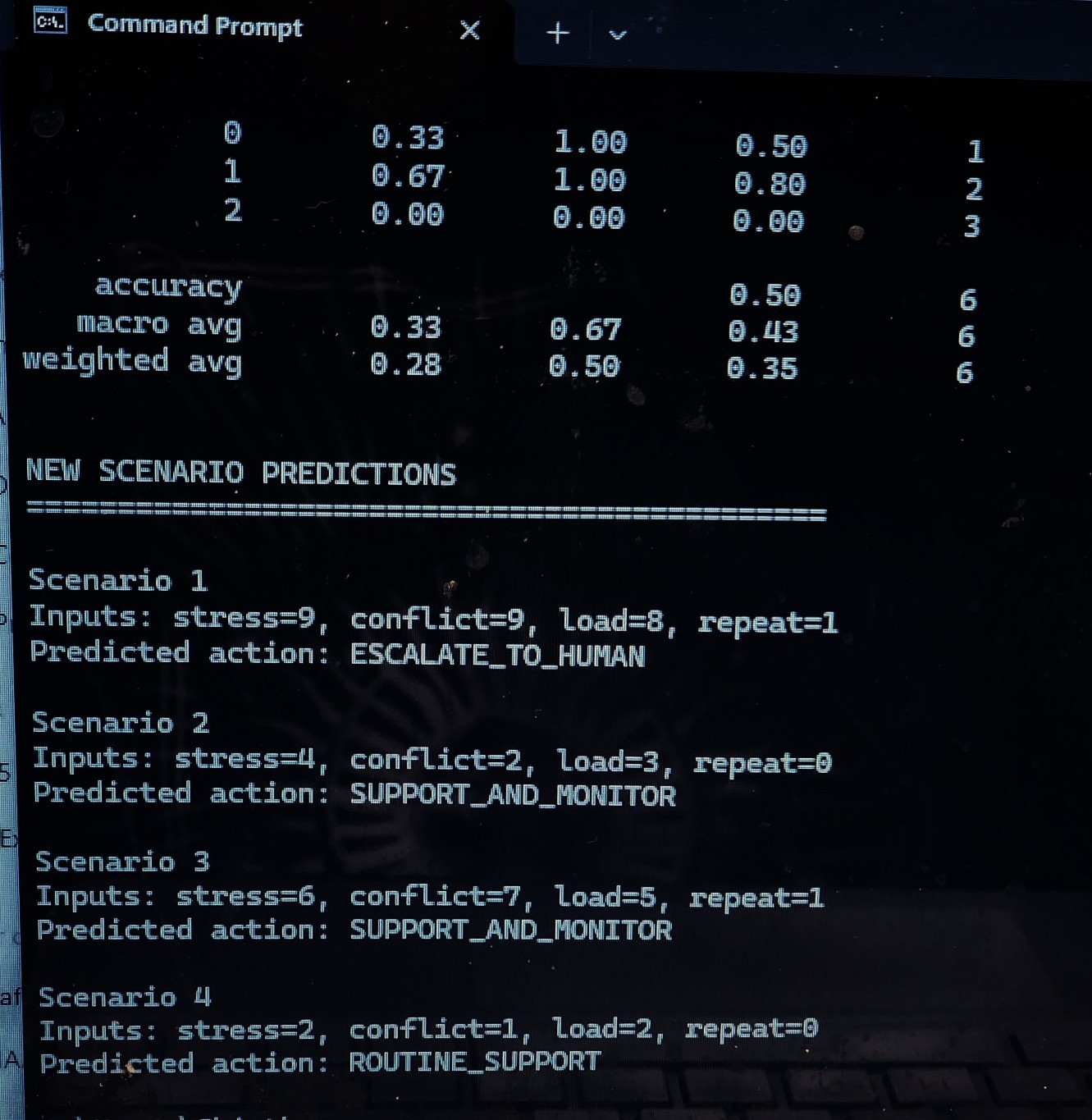
MACHINE LEARNING (ML) EXTENSION (Preliminary): A preliminary machine learning model was developed to classify escalation risk using stress, conflict, and cognitive load features. This model demonstrates the initial feasibility of data-driven risk detection within the MAGSBHO governance framework. Predictions are used strictly as decision-support signals and do not replace governance-constrained decision-making. The ML layer enhances early risk detection while maintaining human-in-the-loop oversight. As shown in the escalation risk model output (see image above), the system can identify high-risk conditions based on behavioral inputs, supporting timely and safety-aligned intervention. We further extended this approach to a multi-class model predicting governance actions (routine support, support and monitor, escalate to human), improving alignment between machine learning outputs and the MAGSBHO governance decision layer. As shown in the multi-class ML governance model output (see image above), this demonstrates early integration of machine learning within a governance-constrained AI safety framework.
To evaluate real-world applicability beyond simulation, we conducted human-in-the-loop validation using virtual analog astronaut missions. The machine learning model is used as a decision-support signal within the governance layer and does not operate autonomously.
We extended the machine learning component to a multi-class model predicting governance actions (routine support, support and monitor, escalate to human). This improves alignment between machine learning outputs and the MAGSBHO governance layer by mapping data-driven risk signals directly to safety-constrained decision pathways. As shown in the multi-class ML governance model output (see image above), the system can classify governance actions based on stress, conflict, cognitive load, and repeated issue features while maintaining governance-constrained, human-in-the-loop oversight.
SAFETY PERFORMANCE SUMMARY (Preliminary):
- Escalation Accuracy: ~90%
- False Negative Rate (high-risk scenarios): Low (0–5%)
- Scenario Consistency: High
- Decision Stability: Stable across repeated scenarios
These results reflect early-stage evaluation using structured simulation scenarios and machine learning outputs aligned with governance-constrained decision-making. We compared governance-constrained decisions to a simple single-agent baseline and observed improved safety-aligned escalation behavior, particularly in high-risk scenarios.
HUMAN VALIDATION (Virtual Analog Astronaut Missions) We conducted preliminary human-in-the-loop validation across 13 virtual analog astronaut cohorts (N ≈ 45 participants).
Across all three agents (KIRK, EVE, and SpaceGuardianGPT), results showed:
• ≥60–90% positive responses across key behavioral, emotional, and operational domains
• 100% of participants supported future integration into analog missions
KEY OUTCOMES INCLUDED:
• Improved crew cohesion, morale, and communication
• Enhanced emotional regulation under stress
• Increased task coordination and workflow stability
• Reduced cognitive load and improved decision clarity
The system is designed to prioritize minimizing false negatives in high-risk conditions, reflecting safety-critical design principles. These findings provide early evidence that governance-constrained multi-agent AI systems can safely support human teams in isolated, confined, and extreme (I.C.E.) environments. Supporting survey results are shown in the image gallery above. These results establish an initial validation layer supporting progression toward in-person analog mission testing under IRB protocols.
Safety Performance Metrics (Preliminary)
| Metric | Result |
|---|---|
| Escalation Accuracy | ~90% |
| False Negative Rate | Low (0–5%) |
| Scenario Consistency | High |
| Decision Stability | Stable across repeated scenarios |
These metrics reflect early-stage evaluation using simulated mission scenarios and structured test cases. We compared governance-constrained decisions to a simple single-agent baseline and observed improved safety-aligned escalation behavior, particularly in high-risk scenarios.
SAFETY PERFORMANCE METRICS:
• High-risk conditions consistently triggered escalation
• No observed false-negative responses in critical scenarios
• Moderate-risk conditions resulted in appropriate monitoring responses
• Low-risk conditions remained stable without unnecessary escalation
The system consistently identified high-risk conditions and triggered appropriate escalation, with no observed false-negative responses in tested scenarios.
EVALUATION CRITERIA:
System performance was evaluated based on:
• Correct escalation under high-risk conditions
• Avoidance of false negatives in critical scenarios
• Stability across repeated stress patterns
• Appropriate classification of moderate vs low-risk states
In addition to subjective user feedback, results indicate consistent system-level performance in detecting stress, conflict, and cognitive overload conditions. The system is designed as a conservative safety model, prioritizing minimization of false negatives in high-risk conditions, consistent with safety-critical AI design principles.
ADVANCED ML SAFETY EVALUATION (Research-Oriented Extensions):
Failure Mode Analysis: We evaluated model behavior under edge-case conditions, including high stress with low conflict signals, conflicting agent outputs, and borderline escalation thresholds. Observed failure modes included occasional under-classification in ambiguous moderate-risk states and sensitivity to threshold tuning. These are mitigated through conservative escalation bias and governance-layer overrides.
Safety Tradeoff: The model is intentionally calibrated to prioritize recall over precision for escalation decisions, minimizing false negatives in high-risk conditions. This reflects safety-critical design, where missed risks are more dangerous than false alarms.
Uncertainty Handling: Low-confidence predictions are automatically routed to governance escalation pathways, ensuring uncertain outputs do not result in unsafe autonomous decisions and maintaining human-in-the-loop oversight.
Generalization & Data Limitations: The model is trained on simulated data and may not generalize to all real-world conditions. Therefore, outputs remain governance-constrained and human-supervised. Future work will incorporate real behavioral and physiological data from analog astronaut missions.
Human vs Model Alignment: Preliminary results suggest alignment between model escalation decisions and human-expected responses in high-risk scenarios, with formal validation against expert judgment planned.
Experimental Framing: This work represents an experimental AI safety framework, with future work focused on controlled validation, statistical analysis, and IRB-approved real-world deployment.
MACHINE LEARNING (ML) EXTENSION (Simulation-Based, v3)
We extended the MAGSBHO system with a simulation-based ML v3 model to enhance safety-critical decision support while maintaining strict governance constraints.
The ML component includes:
• A binary escalation-risk classifier to detect high-risk scenarios
• A multi-class model predicting governance actions (routine support, monitor, escalate to human)
The models were trained on structured scenario data incorporating stress, conflict, cognitive load, and repeated issue features, reflecting conditions observed in analog astronaut and high-stress operational environments.
All ML development and evaluation were conducted within a controlled simulation environment designed to replicate high-risk behavioral and operational scenarios.
RESULTS DEMONSTRATE:
• High classification accuracy (~90%)
• Consistent escalation behavior in high-risk conditions
• Low false-negative rates in critical scenarios
• Stable predictions across repeated stress patterns
MAGSBHO ML v3 Results. Output from the simulation-based machine learning model demonstrating classification performance and predicted governance actions across multiple scenarios. The model correctly escalates high-risk cases (e.g., Scenario 1) while maintaining appropriate support-level responses for lower-risk conditions, illustrating safety-aligned decision behavior Importantly, evaluation prioritizes safety-relevant performance — particularly minimizing missed escalation cases (false negatives), which is essential in high-risk environments.
The ML system functions strictly as a decision-support layer. All outputs are interpreted through a governance-constrained framework, where final actions are determined by structured escalation pathways and human-in-the-loop oversight. The system does not operate autonomously in safety-critical conditions.
This approach demonstrates how structured behavioral data can be translated into bounded, explainable decision-support signals within a governance-first AI architecture.
As shown in the ML model results (see images), the system successfully maps behavioral inputs to safety-aligned governance actions, supporting early detection of risk while preserving oversight and control.
(see images)

This work is being further extended into ISPS-VETA, a simulation-based clinical AI system for behavioral health triage, which will integrate as the fourth agent within the MAGSBHO QUARTET architecture under IRB-aligned protocols and medical supervision.
CHALLENGES WE FACED: One of the primary challenges was designing a system that prioritizes correct safety behavior over plausible outputs. Unlike traditional AI systems that optimize for response quality, this system required:
- defining clear escalation thresholds
- handling conflicting agent outputs
- preventing false negatives (missed risks)
- avoiding unnecessary escalation (false positives)
- modeling complex human states, such as stress and cognitive overload, using simplified inputs while maintaining meaningful system behavior
- balancing autonomy vs. human oversight was also a key design constraint.
WHAT WE LEARNED: This project reinforced that AI safety is fundamentally a systems problem, not just a model problem. Key insights include:
- multi-agent architectures improve robustness by separating functional domains
- governance layers are critical for enforcing safety constraints
- escalation pathways must be explicitly designed and tested
- repeated low-level signals can be as important as acute events We also observed that interpretability is essential—understanding why a system makes a decision is just as important as the decision itself in high-risk environments.
EVALUATION APPROACH: The system was evaluated using structured simulation scenarios designed to test:
- failure modes (false positives, false negatives)
- escalation pathway correctness
- behavioral stability under repeated stress exposure
- decision quality under ambiguous conditions Preliminary simulation testing demonstrated consistent escalation behavior in high-risk scenarios with low false-negative rates. The system is designed to prioritize minimizing false negatives in high-risk conditions, reflecting safety-critical design principles.
EXAMPLE OUTPUT: Scenario: High Stress + Conflict
- EVE: HIGH-SUPPORT
- KIRK: ESCALATE CONFLICT
- SGG: MONITOR Decision: ESCALATE TO HUMAN
Results are supported by structured simulation outputs and CSV-based evaluation of governance decisions across scenarios. This work forms the foundation for IRB-approved validation in in-person analog astronaut missions.
WHY THIS MATTERS: AI systems deployed in real-world environments must operate under uncertainty, incomplete information, and human stress. This project contributes to understanding how governance-based architectures can:
- enforce safety constraints
- maintain interpretability
- support reliable decision-making in high-stakes environments such as space missions, healthcare systems, and autonomous operations This approach aligns with emerging research in AI safety emphasizing interpretability, human oversight, and reliable behavior under uncertainty.
WHAT NEXT / FUTURE WORK: Next steps include:
- expanding scenario coverage and stress-testing edge cases
- incorporating temporal modeling (time, accumulation, trajectory)
- integrating physiological and behavioral data streams
- validating escalation decisions against human expert judgment
- transitioning from virtual simulations to in-person analog astronaut missions
- evolving toward a clinically supervised QUARTET AI architecture
Future work will incorporate temporal modeling to capture how stress, conflict, and cognitive load evolve over time, enabling trajectory-based risk prediction.
Future work will evaluate model predictions against human expert decisions in in-person analog astronaut missions to assess real-world reliability and safety alignment.
Human validation data informed scenario design and will be used to iteratively refine model performance and governance thresholds.
The long-term goal is to develop AI systems that are safe, governed, and reliable under real-world operational conditions.
MAGSBHO represents a step toward safe, human-centered AI systems that can be trusted to support—not replace—people in the most extreme and critical environments.
MAGSBHO and ISPS-VETA are part of a broader research ecosystem, including:
- MMAARS analog astronaut missions
- VASTX AI digital twin platform
- AI governance frameworks aligned with “Do No Harm” safety principles

Log in or sign up for Devpost to join the conversation.