-
Home page
-
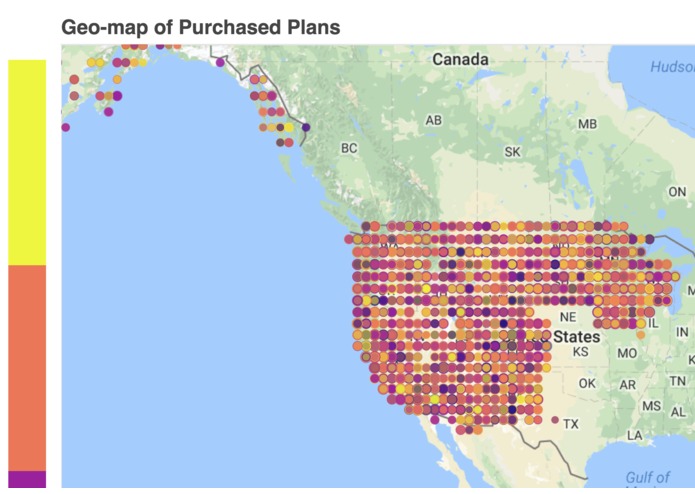
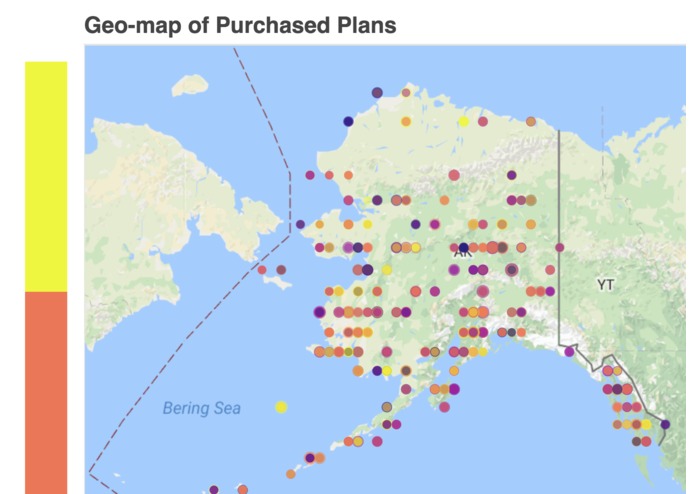
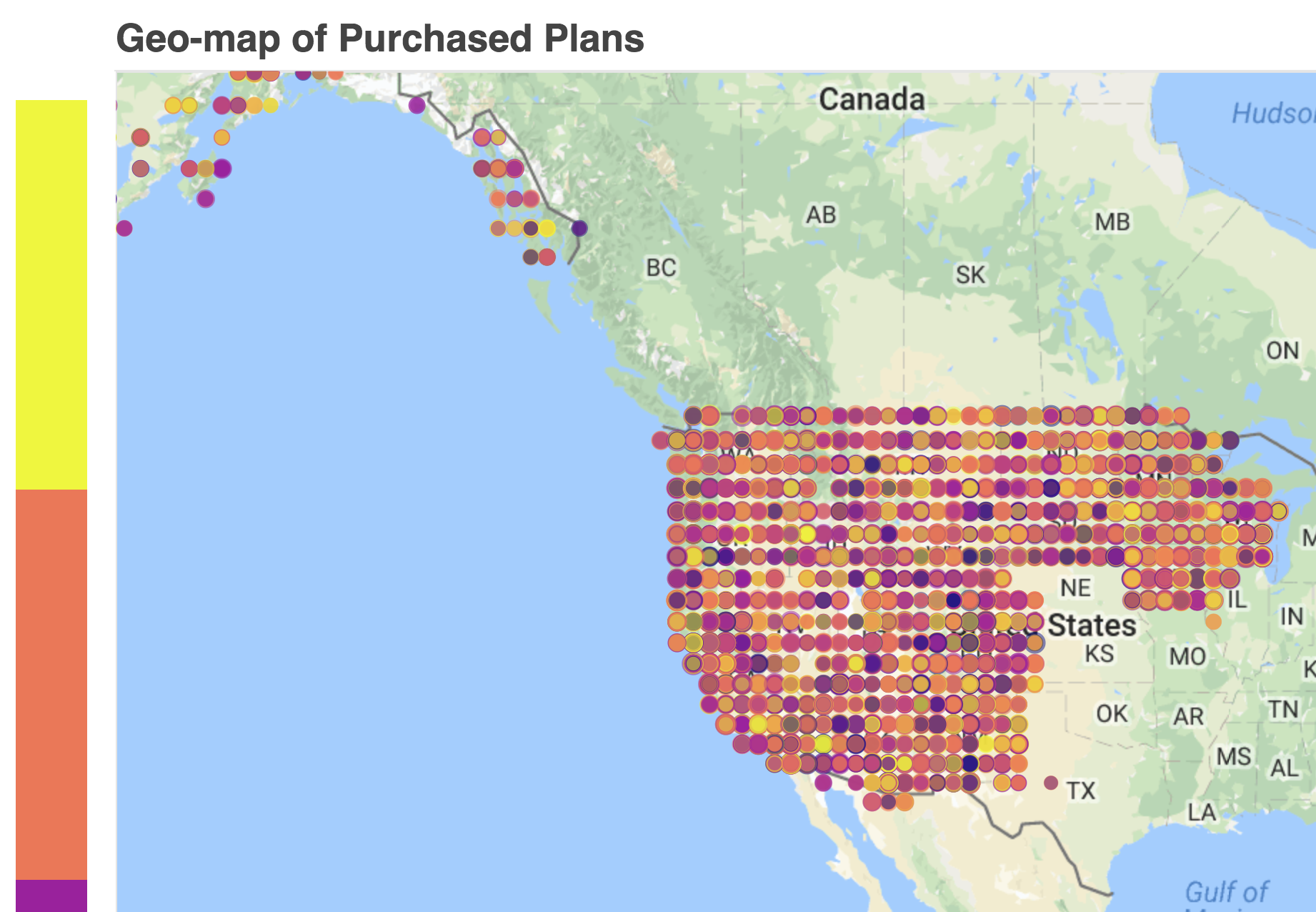
GeoMap for Frequency for type of plan purchased
-
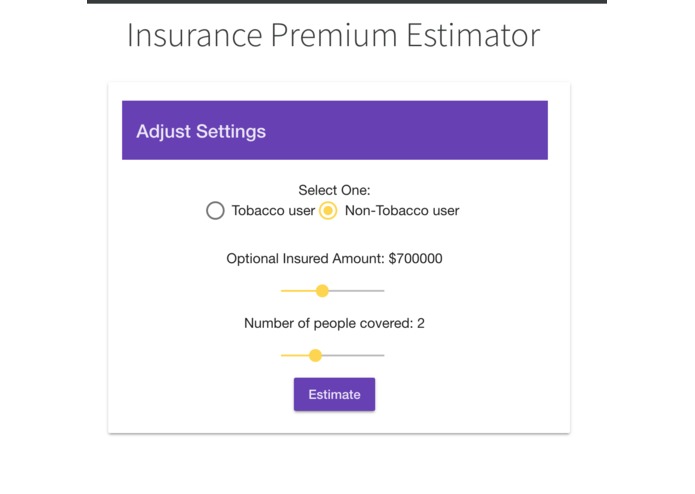
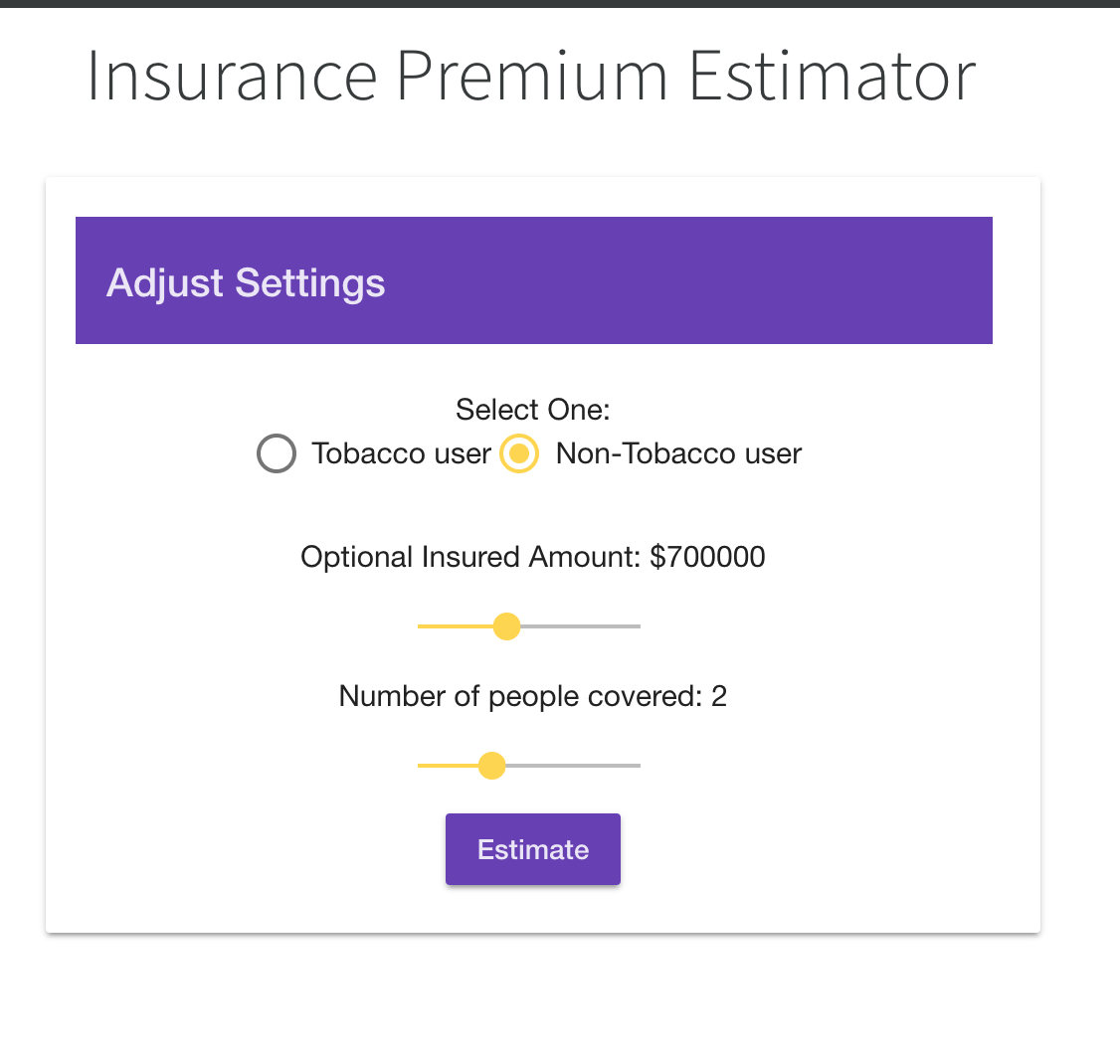
Insurance Premium Estimator
-
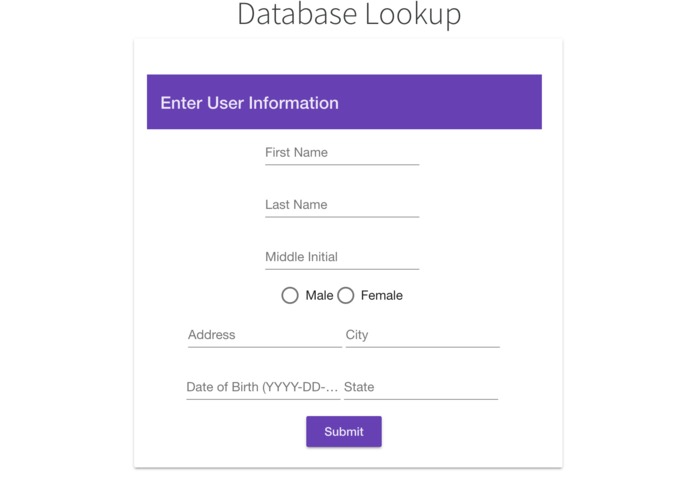
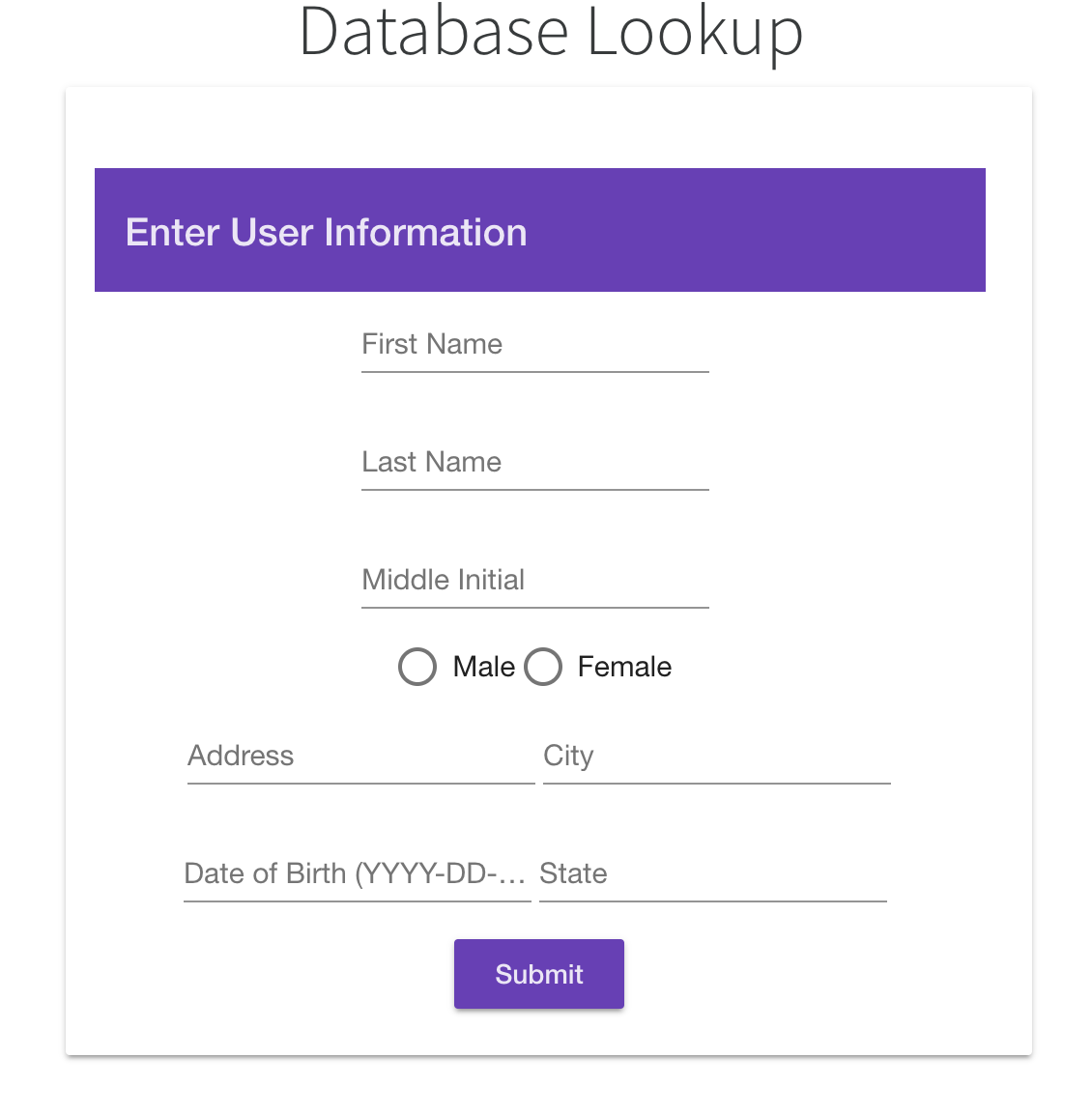
Database Search
-
-
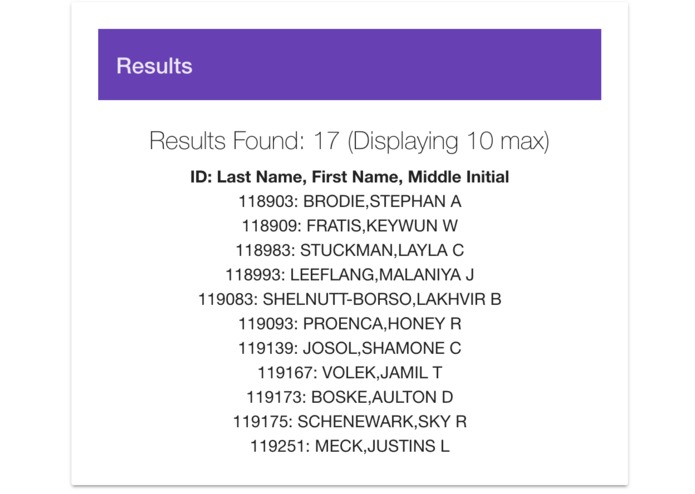
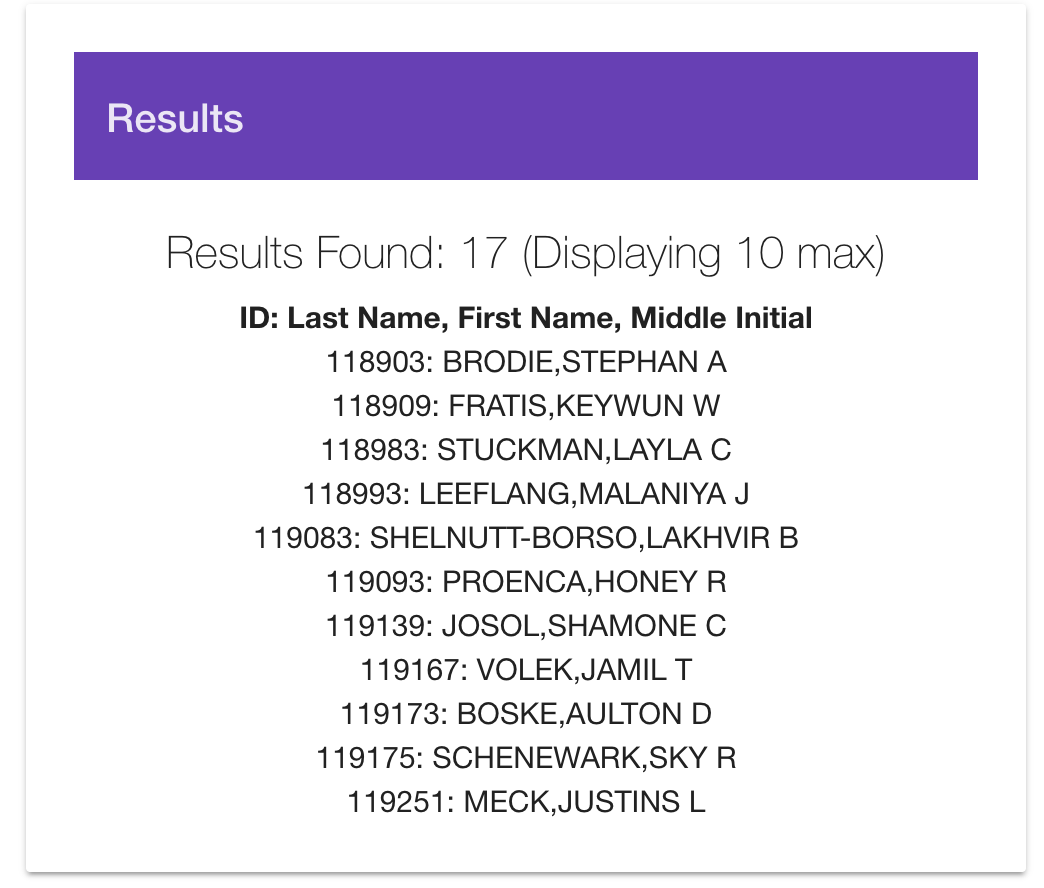
Results for Database search
-
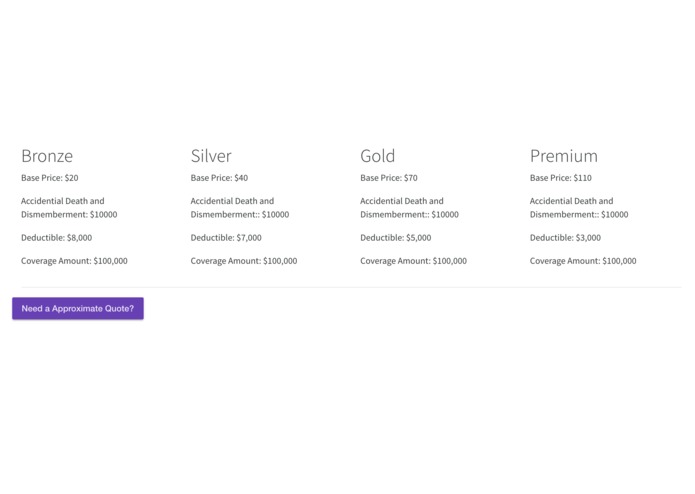
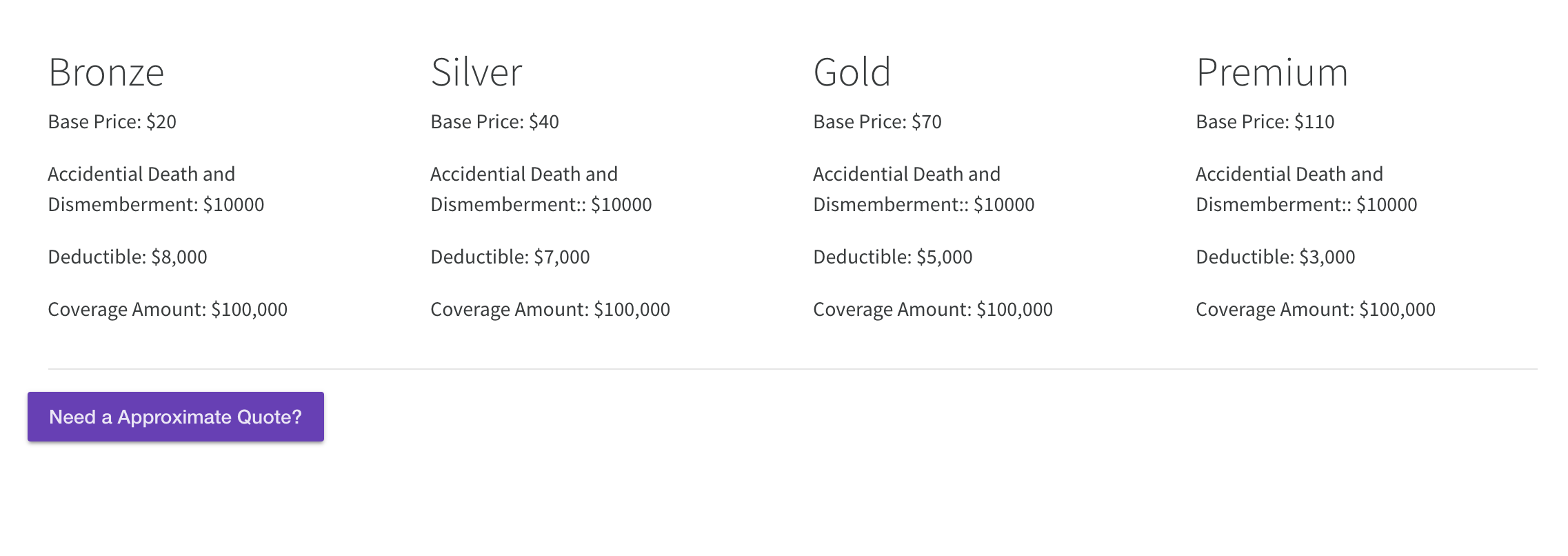
Information about plan
MAGIC CLIENT MANAGER
User-friendly web app uses data analytics and machine learning to dig up demographics and predict insurance premiums
Inspiration
While our interest originally stemmed from the desire to pick up basic machine learning and data analysis techniques, we loved the interdisciplinary aspect of the ViTech insurance hack, which emphasized both creating a user interface and analyzing the data itself and presenting it successfully on the UI.
It really challenged us to work with linking our application to backend since the challenge was so reliant on dynamically provided data.
The web app is simple and user-friendly because we want to help you! Whether "you" are a company executive or a prospective client, we want you to clearly understand and visualize data. Our application is minimalistic and has massive potential for growth.
What It Does
Magic Client Manager is an online tool designed with the user experience in mind. We took the dataset provided by Vitech and analyzed it using various techniques, including but not limited to regressions and dimensionality reduction.
Clients can filter through and find users in the database by name, address, city, state, and/or several other fields who meet those parameters. We created a multi-linear model in R which we implemented in Angular as an interactive Insurance Premium Predictor. We have also integrated beautiful visualizations of data analytics to paint a comprehensive big picture overview of 1.4 million data points.
How We Built It
The user interface was constructed using Angular4 with Firebase acting as our backend. We used R to create the predictive models used in our UI to estimate premium rates. Python and Matlab were used to analyze the Vitech dataset and libraries were imported into Python in order to create the visualizations.
Challenges
- This was one of our first times successfully connecting Angular4 to Firebase.
- Dealing with outdated versions of Angular and the various modules I worked with since the community is so dynamic.
- Acquiring the data from SOLR was really difficult. The wifi was really slow and it took several minutes to load 10 rows into the Jupyter notebook.
Under unfortunate circumstances, one of our teammates arrived 12 hours late.
The majority of us had practically no experience with data analysis and machine learning. It was hard though we learned a lot!
Everyone was proficient in a different programming language, so we have an odd selection of programs and trying to sync up was a little difficult.
Accomplishments We're Proud Of
- Learning Angular4 and Firebase!
- We learned a lot and we had relatively accurate predictions regarding the data we were able to query from SOLR.
- Our app works pretty well!
- Tapped into multiple fields (interdisciplinary!)
What We Learned
- Brushing up on Angular4 and dealing with dependencies errors between Angular4, Materials2, and Firebase 5.0 proved to be a fairly difficult challenge.
- Working with big data was especially difficult, especially because the wifi was slow during peak times of the Hackathon, making data updating almost impossible.
- How to use SOLR, Firebase, and interesting and useful Python libraries
- A variety of machine learning techniques; there are so many and all of them have different pros and cons.
- Cleaning up and working with massive data
- For two of us, it was our second hackathon - so we're finally learning how to submit a hack, which we accidentally failed to submit the first time haha
- For a majority of us, it was our first time working with someone we had never met before.
What's Next
- Integrate more advanced machine learning and prediction models.
- Feeding in more data into Firebase.
- Smooth out any corner cases that we might've missed

Log in or sign up for Devpost to join the conversation.