-
-
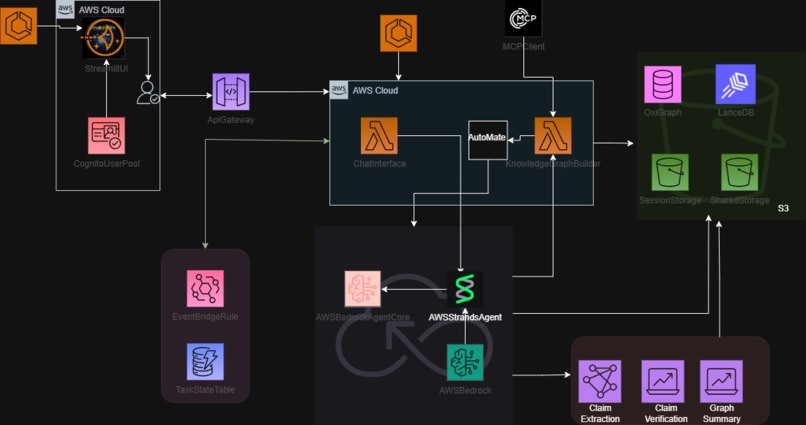
Architectural Diagram 1
-
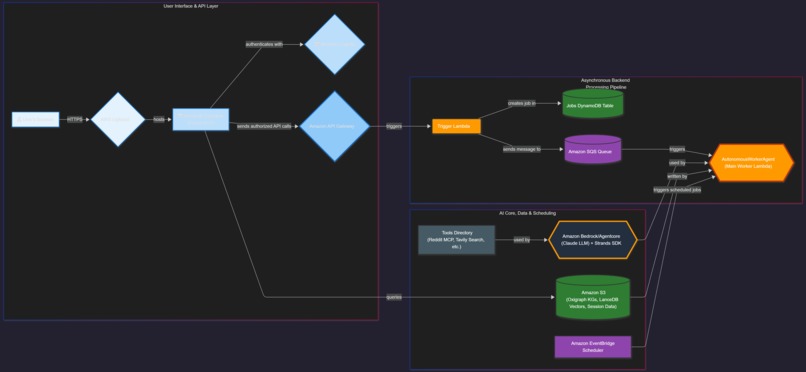
Architectural Diagram Mermaid
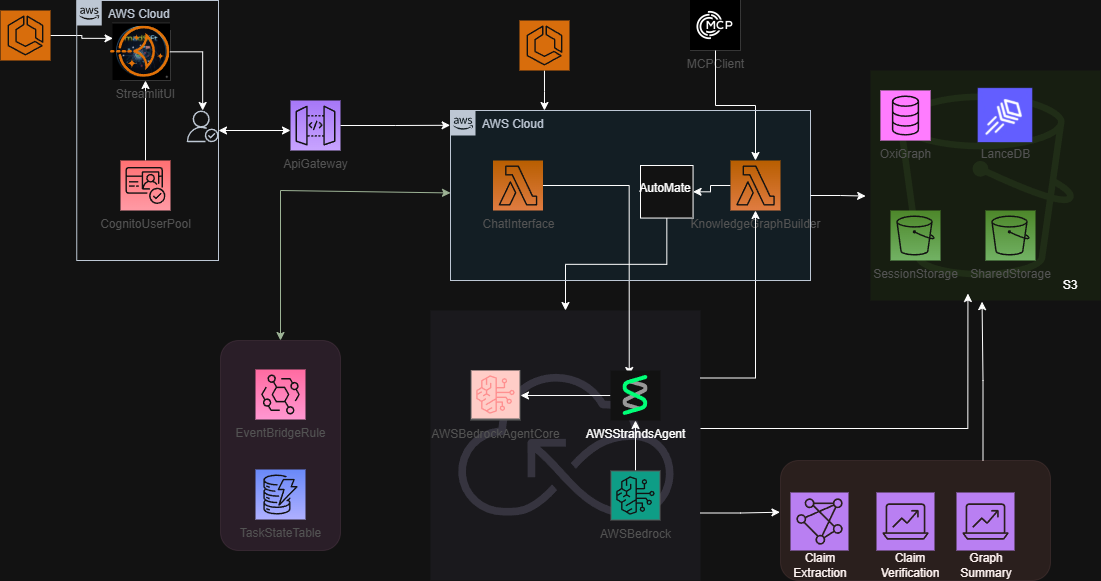
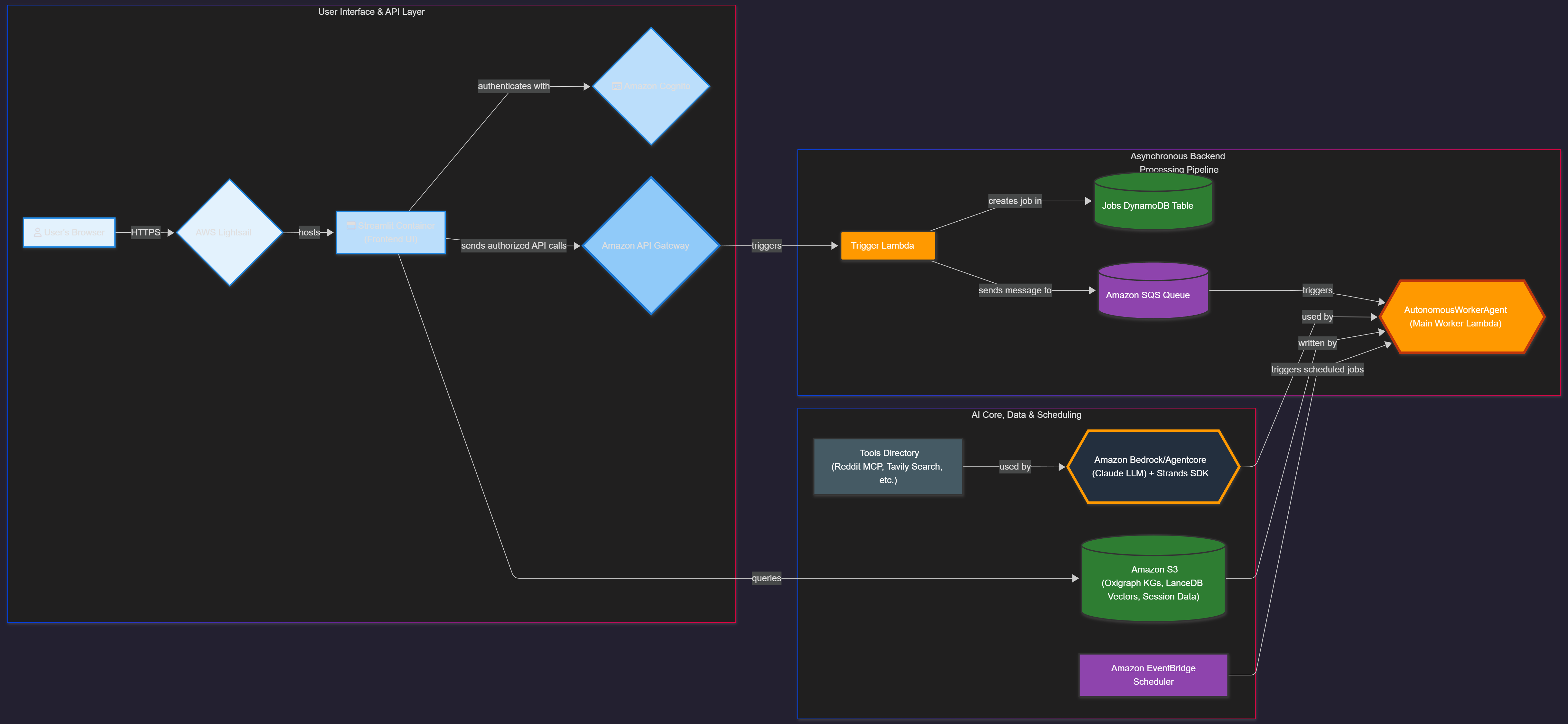
MadSift: Misinformation Detection & Analysis Framework
1. Vision & Overview
Project: MadSift, an autonomous AI agent framework built on AWS to combat the "infodemic" by proactively identifying, analyzing, and verifying emerging rumours from social media.
This framework is not just a verification tool; it is a comprehensive intelligence platform designed to serve a wide range of users who are on the front lines of the information war. For these users, MadSift acts as a powerful force multiplier:
- For Journalists & Fact-Checkers: In a world where every second counts, MadSift provides a near-real-time verification capability, drastically reducing the hours spent manually tracking sources and allowing journalists to publish timely, evidence-based clarifications.
- For Academic & Market Researchers: The system's unique autonomous monitoring feature is a game-changer, enabling the study of how misinformation evolves and propagates over time by creating invaluable longitudinal datasets.
- For Social Media Platforms & Content Moderators: MadSift acts as an early-warning system, autonomously flagging emerging, high-velocity narratives that may be part of coordinated campaigns, allowing teams to prioritize their resources and intervene more effectively.
Problem Statement: In our digital ecosystem, misinformation flows like a torrent, spreading faster than facts can catch up. The sheer volume and velocity of online content make manual verification an impossible task, while the sophisticated nature of these narratives requires a deep, contextual understanding that simple keyword-based tools lack. To truly combat this challenge, it's not enough to just debunk a single post; we must understand the entire rumour ecosystem—how claims connect, how narratives form, and how they propagate through online communities.
MadSift addresses this critical need head-on. The system combines neuro-symbolic reasoning with knowledge graph construction to automatically discover, analyze, and verify claims from social media platforms, providing users with evidence-based insights through an interactive chat interface. It is a proactive intelligence platform designed to bring clarity and structure to the chaos of online information.
Core Solution & Key Innovations: MadSift implements a novel, hybrid Graph-RAG (Retrieval-Augmented Generation) architecture, leveraging a suite of powerful AWS services. Its key innovations are:
- Autonomous Scheduled Monitoring: The system can be tasked to monitor a topic for a set duration, automatically fetching data, building incremental Knowledge Graphs, and summarizing trends at set intervals—all without human intervention.
- Optimized, Serverless Graph Architecture: MadSift uses a powerful combination of Oxigraph for RDF graph processing and LanceDB for vector storage, with both data artifacts persisted directly in Amazon S3. This serverless-native approach is a deliberate and superior architectural choice for this problem.
- High-Performance Batch Processing: A state-of-the-art pipeline for claim extraction and embedding generation that processes hundreds of posts in seconds, achieving a Significant speedup and Very high cost reduction compared to sequential methods.
- Multi-Dimensional Summarization: A sophisticated summarization engine that transforms dense graphs into journalist-friendly intelligence briefings by synthesizing insights from multiple analytical dimensions: graph structure, semantic similarity, verification status, and source analysis.
2. Architectural Philosophy & Justification
- Serverless First & Asynchronous by Default: The entire backend is built on a serverless, event-driven paradigm (API Gateway -> SQS -> Lambda). This eliminates idle costs, provides infinite scalability on demand, and removes the burden of infrastructure management.
- The Right Tool for the Job: An Optimized Graph Strategy
- The Challenge: Rumour verification involves creating many small-to-medium-sized, ephemeral Knowledge Graphs in rapid bursts. An always-on, cluster-based graph database like Amazon Neptune is designed for massive, persistent enterprise graphs and would be both architecturally inappropriate and prohibitively expensive for this burst-y, on-demand workload.
- The Superior Solution: MadSift employs a highly optimized, serverless-native strategy. The Oxigraph RDF library (written in Rust for incredible performance) is run directly within the Lambda function's memory to build the graph. The final graph, along with its LanceDB vector store, is then persisted as a simple file in Amazon S3.
- The Benefits: This approach is dramatically more cost-effective (paying only for milliseconds of compute and cents for storage, vs. thousands for an idle Neptune cluster) and perfectly matches the ephemeral, burst-driven nature of the task.
- Future-Proof Scalability: This choice does not sacrifice future growth. Because both Oxigraph and Neptune use the standard SPARQL query language and RDF data model, the system can be seamlessly migrated to Amazon Neptune and Neptune Analytics if a future use case requires a massive, persistent, multi-billion-triple graph.
- Managed Agent Runtime with Amazon Bedrock AgentCore: We are not just running Python code; we are leveraging Amazon Bedrock AgentCore, a containerized, production-ready runtime system for AI agents. By building our
AutonomousWorkerAgenton top of AgentCore, AWS manages the complex, undifferentiated heavy lifting of the agent's execution environment. This allows us to focus entirely on defining sophisticated, high-level agentic patterns—like our multi-step reasoning, tool use, and autonomous monitoring. - Tool Integration & The Model Context Protocol (MCP): A key architectural innovation is the use of the Model Context Protocol (MCP) for social media data acquisition. Instead of a simple
fetch(posts)command, our agent uses an MCP client to engage in a more sophisticated, conversational data retrieval process. This stateful connection allows for more efficient data streaming and makes the agent's data-gathering capabilities highly modular and future-proof.
3. High-Level Architecture
The architecture decouples the user interface (hosted on AWS Lightsail) from the heavy asynchronous backend processing.

4. Data Model & Schema Management
- Knowledge Graph Store (S3): Final KGs are stored as RDF/Turtle
.ttlfiles. Oxigraph is used for in-memory graph construction due to its high performance, which is critical in a serverless Lambda environment. - Vector Store (S3): Key KG nodes are converted into rich semantic documents, embedded using Cohere Embed v4, and stored in a LanceDB vector database directly in S3.
- Job Tracking (DynamoDB): A
Jobstable tracks the real-time status (QUEUED,PROCESSING,COMPLETED,FAILED) of each asynchronous verification task.
5. Agent & Component Specifications
5.1 Ingestion & Orchestration Components
- Streamlit UI on Lightsail: The user-facing application, containerized and deployed on AWS Lightsail for predictable pricing and simple management.
- API Gateway & Trigger Lambda: The synchronous entry point that receives a request, creates a job record in DynamoDB, places a message on an SQS queue, and returns a job ID for status polling.
- SQS Queue: Decouples the API from the heavy processing, ensuring scalability and fault tolerance for long-running AI tasks.
5.2 AutonomousWorkerAgent (The Core Engine)
- Role: The main "brain" of the system. A long-running, containerized Amazon Bedrock AgentCore application that handles on-demand jobs and scheduled monitoring ticks.
- Implementation: A Strands Supervisor Agent orchestrating a multi-step, autonomous workflow.
- A) The Knowledge Synthesis Pipeline: This is the core workflow executed for each job or monitoring tick.
- Fetch Data: Uses the
RedditMCPToolto pull raw conversation data. - Extract Claims (Batch): Processes texts in batches of 96, using a
ClaimsExtractionAgentto extract structured claims in a single, efficient LLM call. - Synthesize Knowledge Graph: Uses a
KGBuilderAgentto construct a high-performanceOxigraphKnowledge Graph in memory. - High-Performance Verification & Enrichment: This step is a highly efficient, cluster-based process:
- Claims from the in-memory graph are grouped into clusters.
- Each cluster is summarized by an LLM to create a coherent search context.
- This context is used to perform a single, powerful search with the Tavily Search API. Tavily's AI-native design provides clean, ad-free, RAG-optimized content, which is perfect for our agent. Advanced parameters like
search_depthand date filters give our agent the precision of a skilled researcher. - The retrieved evidence and the cluster of claims are sent to Amazon Bedrock in a single batch call for parallel reasoning, where
SUPPORTED,REFUTED, orUNCERTAINlabels are assigned. - The results are added as new triples back into the in-memory Oxigraph graph.
- Create Embeddings (Batch & Parallel): Generates embeddings using Cohere Embed v4 and stores them in a LanceDB database.
- Persist Artifacts & Update Status: Saves the final, fully enriched KG
.ttlfile and LanceDB database to S3 and updates the job's status in DynamoDB.
- Fetch Data: Uses the
- B) The Autonomous Monitoring Process: This describes how the synthesis pipeline is used for proactive monitoring, now including an intelligent, stateful summarization process.
- A user creates a monitoring job via the UI (topic, duration, interval).
- An EventBridge Scheduler is created.
- At each interval, the scheduler triggers this
AutonomousWorkerAgent. - The agent executes the full Knowledge Synthesis Pipeline on any new data discovered since the last tick, creating an incremental KG for that time window.
- Aggregated Summarization: This is where the agent transforms raw, cumulative data into a high-level intelligence briefing.
- Merge KGs: The agent first finds all previous KGs in S3 associated with this specific monitoring job. It merges the new, incremental KG with all the previous ones to create a single, up-to-date graph representing the entire event timeline.
- Generate Intelligent, Multi-Dimensional Summary: It then runs its sophisticated
SummarizationToolon this merged graph. This is not a simple text summary; it is a deep analytical process that synthesizes insights across multiple dimensions:- Query-Aware Focusing: The summarization process is intelligently focused from the start. It uses the original monitoring job's query (e.g., "vaccine misinformation") to semantically filter the merged graph, ensuring the entire analysis is targeted only at the most relevant claims, entities, and relationships, thus eliminating noise.
- Structural Analysis: It calculates graph centrality metrics to identify the most influential nodes (key claims or users that are central to the conversation) and the critical "bridge" nodes that connect disparate narrative clusters.
- Verification and Source Analysis: It infers the verification status of claims directly from the graph's metadata, calculating statistics on how many claims are
SUPPORTEDorREFUTED. It also analyzes the distribution of sources to spot potential echo chambers and assess the credibility of the information ecosystem. - Temporal Analysis: It extracts timestamps from the graph to understand the velocity of information spread and identify peak activity windows.
- LLM-Powered Synthesis: Finally, all of these rich, multi-dimensional findings are synthesized by a powerful Amazon Bedrock model into a structured, journalist-friendly intelligence briefing that explains the current state of the narrative.
- Store Summary: This new, aggregated summary is saved to S3, timestamped, overwriting the previous summary for that job.
- The agent can be configured to periodically inform the user of trends by sending this new, aggregated summary.
- The agent self-terminates the schedule upon completion of the total duration.
5.3 InteractiveChatAgent
- Role: The agent that powers the chat interface in the Streamlit app.
- Core Logic (Graph-RAG & Summarization): When a user selects a completed job, this agent loads the corresponding Oxigraph KG and LanceDB files from S3. It intelligently routes the user's query to either the
GraphQueryAgentTool(for SPARQL queries) or theVectorSearchAgentTool(for semantic search) to synthesize an evidence-based response. Additionally, it is equipped with an on-demandSummarizationToolthat synthesizes structural, semantic, and verification data from the graph into a concise, narrative intelligence briefing.
6. Our Development Journey with Kiro: An AI-Powered Co-Developer
From the outset, we embraced an agentic philosophy not just in our final product, but in our development process. We partnered with Kiro, an AI agentic IDE for developers, which acted as an invaluable co-developer and on-demand AWS expert.
One of the most insightful shifts came from Kiro's spec-driven development model. We learned to describe high-level goals, and Kiro would generate the foundational code and AWS SAM templates. It was instrumental in scaffolding our project, demystifying complex IAM roles, and even prototyping the Streamlit UI.
This partnership also taught us valuable lessons in human-AI collaboration. Kiro's eagerness to find a solution was a double-edged sword; it could sometimes over-engineer a simple bug fix or confidently lead us down a path to work around a buggy starter kit we later realized should have been abandoned. The key was learning to leverage its incredible ability to generate and explain, while maintaining human oversight to guide its powerful reasoning. This partnership between human intuition and AI acceleration was a core part of our hackathon journey.
7. Future Work & Vision
This project lays the foundation for a comprehensive intelligence platform. The modular, agentic architecture allows for straightforward extension:
- Multilingual & Multimodal Support: Our top priorities for future work. The infrastructure is ready. We will focus on the complexities of multilingual graph construction and integrate multimodal LLMs and vector stores to analyze images and detect deepfakes.
- Real-Time Alerting (
AlertingAgent): Implement a new, high-frequency agent that constantly queries the KGs for user-defined threat patterns (e.g., a new, unverified claim about a company with over 100 mentions in the last hour) and fires immediate notifications. - Advanced Analytics & Verification: Integrate more sophisticated analytical tools to perform echo chamber detection, analyze propagation networks, and implement custom verification metrics (FS, ECS, BAS) to provide a deeper, more nuanced "truth score."
- Leveraging Bedrock AgentCore Knowledge Base: For the alerting system, we envision a future integration with AgentCore's built-in Knowledge Base. An analyst could define a monitoring query in natural language ("Alert me if posts similar to 'election fraud' mention my brand"), which would configure a managed RAG pipeline for highly efficient, semantic threat detection.
8. About Me
I have been a data scientist/ML researcher (for the past decade) where work is largely experimental. This hackathon has given me the opportunity to transition into production grade projects.
Thank you
Saket Kunwar
Built With
- agentcore
- amazon-web-services
- bedrock
- claude
- cohere
- kiro
- lightsail
- s3
- strands
- streamlit

Log in or sign up for Devpost to join the conversation.