-
-
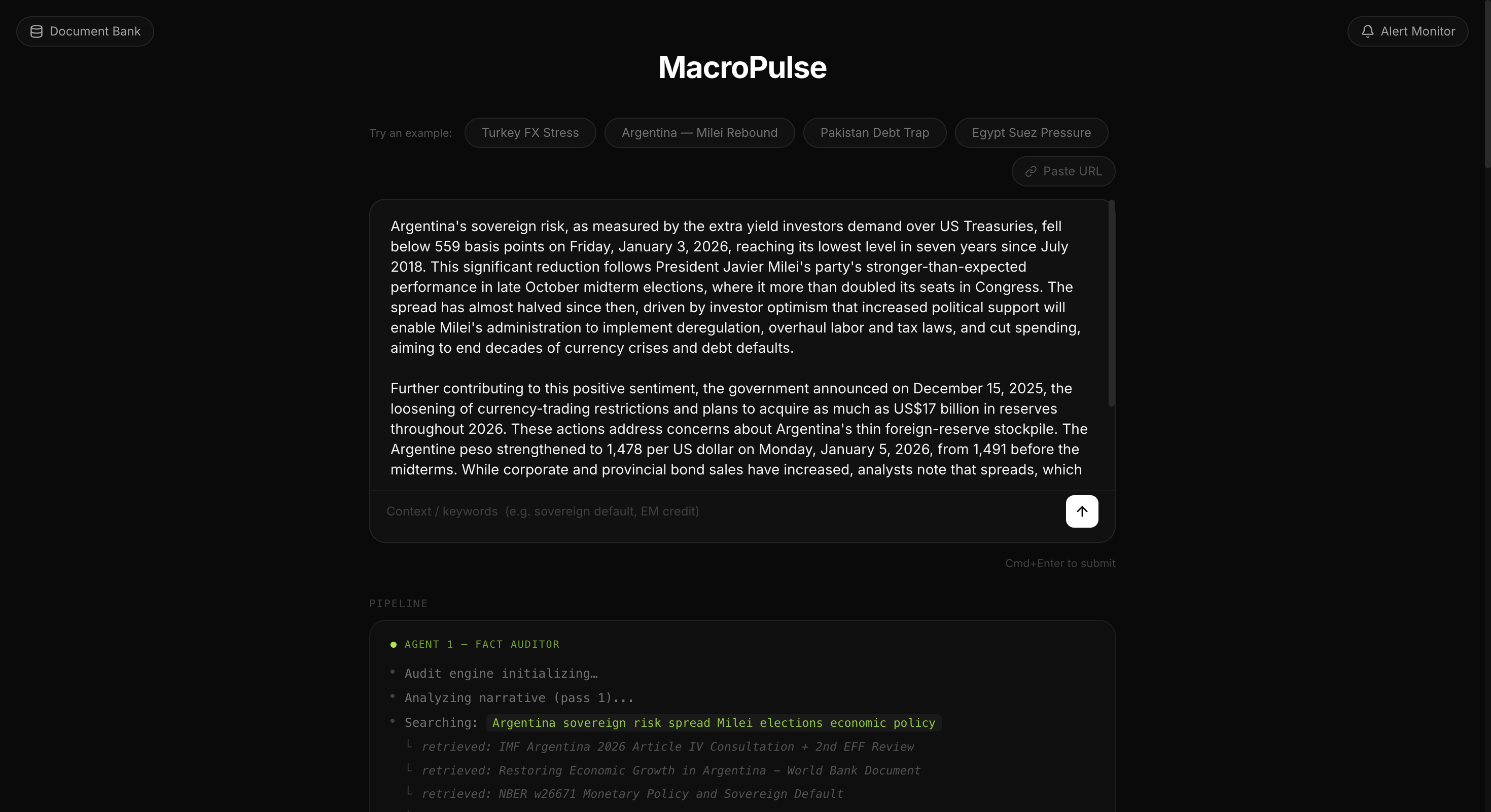
Main UI
-
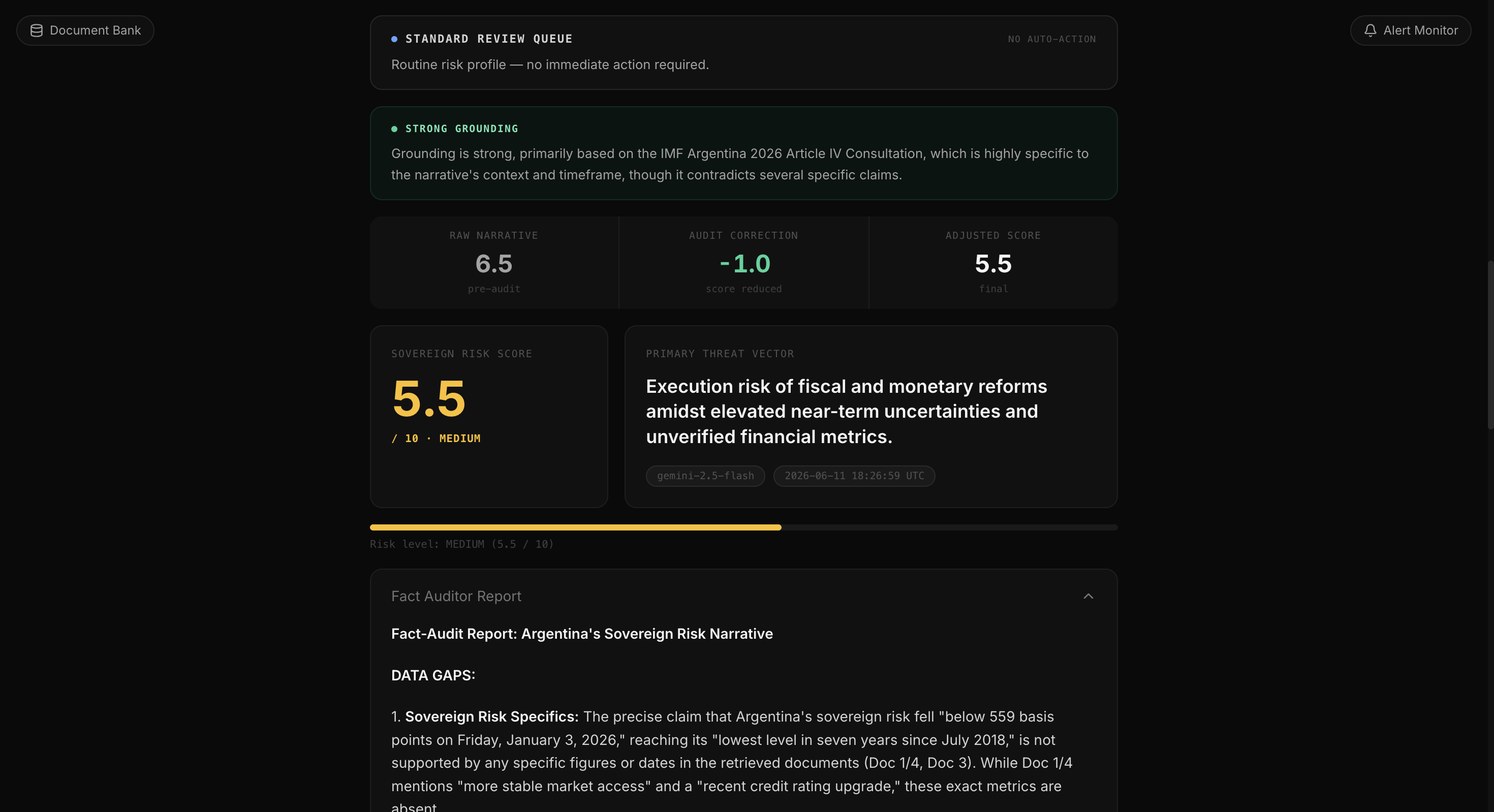
Fact Audit Report
-
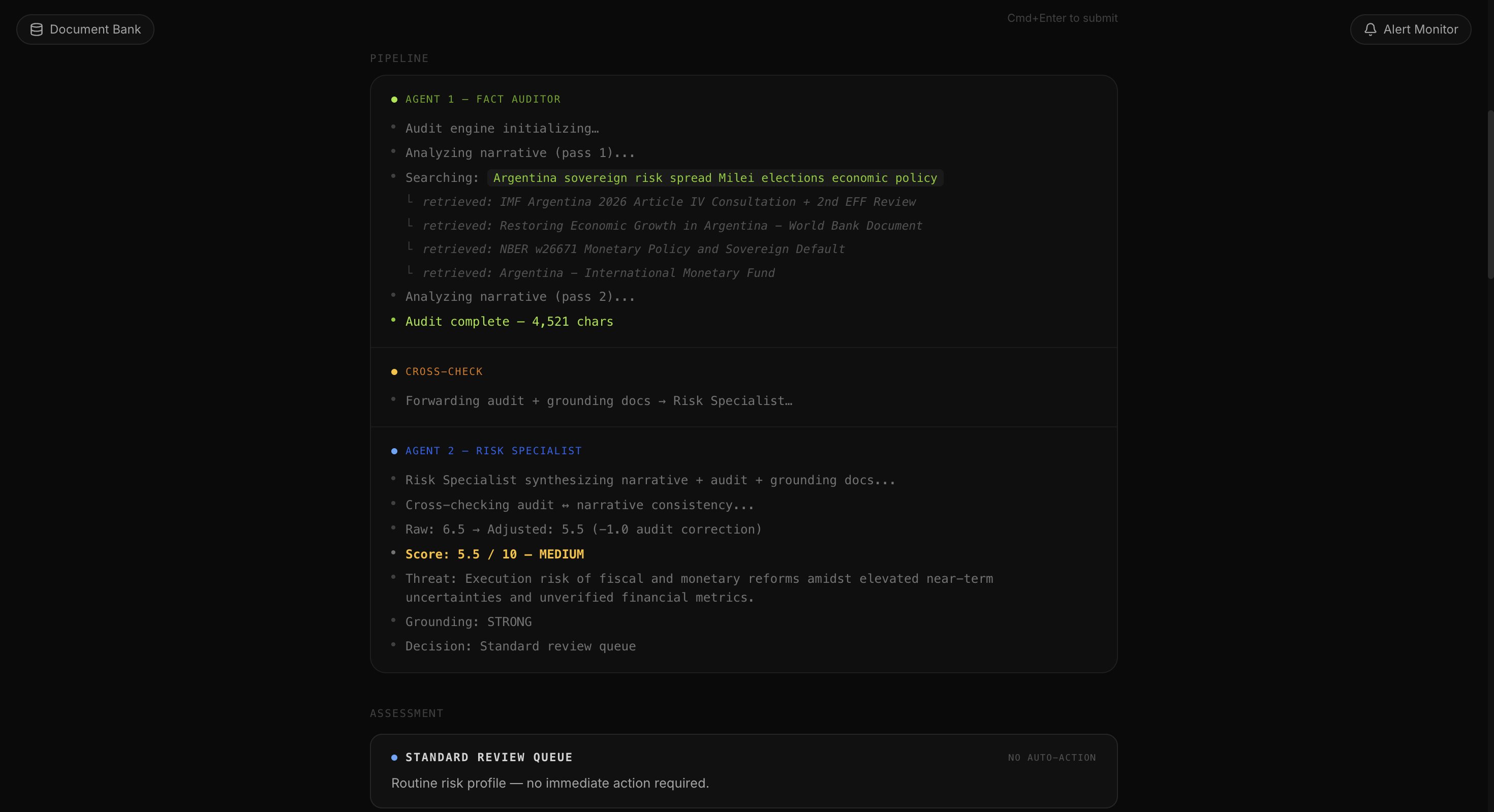
Pipeline
-
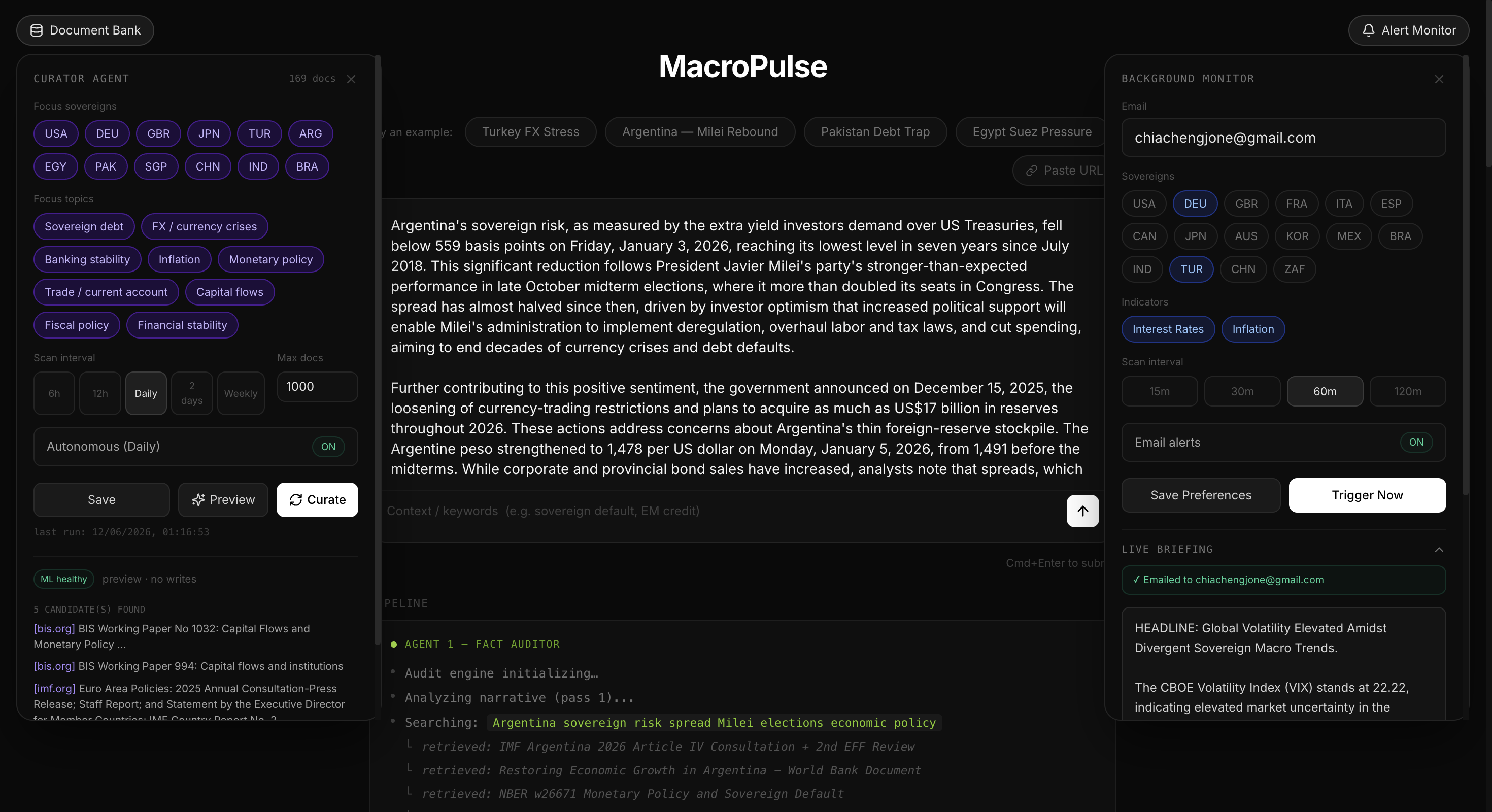
Document Curator & Email Alert
Inspiration
The motivation was watching how quickly market narratives around Argentina, Turkey, and Egypt moved in early 2026 and how often the quantitative claims embedded in those narratives were either unverifiable or subtly wrong. As a NUS student deeply interested in global finance, these narrative claims could make it difficult to differentiate from factual claims, especially without access to a Bloomberg terminal or institutional terminals readily. Thus, I wanted to build something that didn't just read the article, but cross-examined it against a living corpus of institutional research and pinpoints exactly where the claims break down.
What it does
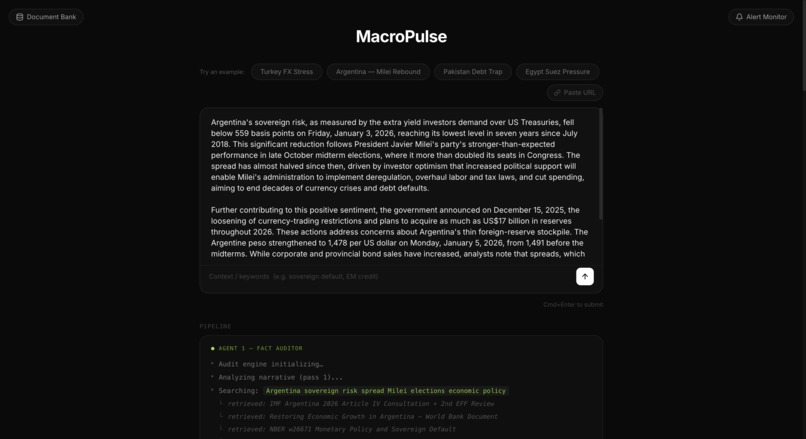
MacroPulse is a two-agent sovereign risk evaluation platform. The user pastes a financial narrative such as a news excerpt, a research summary, a macro brief and a Fact Auditor agent retrieves grounding documents from a curated Elasticsearch knowledge base via hybrid RRF search, then produces a structured audit identifying data gaps, inflated claims, and factual contradictions. A Sovereign Risk Specialist agent then synthesises the audit and the evidence into a scored assessment.
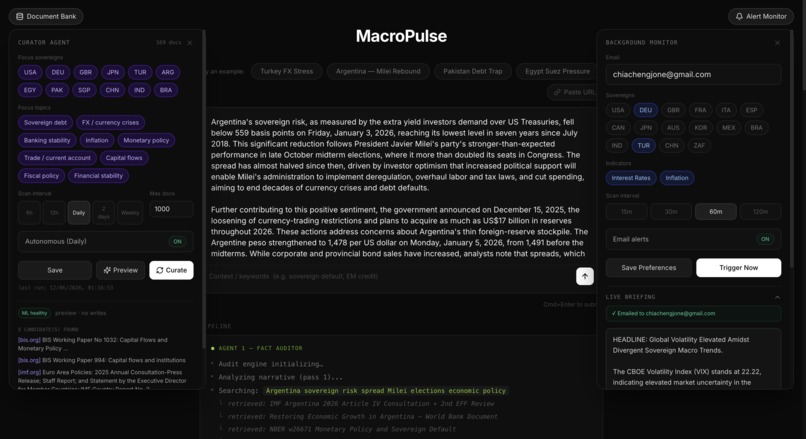
On top of the core pipeline, MacroPulse runs a background alert monitor that pulls live FRED macroeconomic indicators for up to 16 sovereigns, generates a Gemini briefing, and emails it on a configurable interval. A self-curating document bank uses Tavily to discover and ingest new institutional research daily from whitelisted sources — IMF, World Bank, BIS, central bank publications — keeping the knowledge base fresh without manual curation.
How we built it
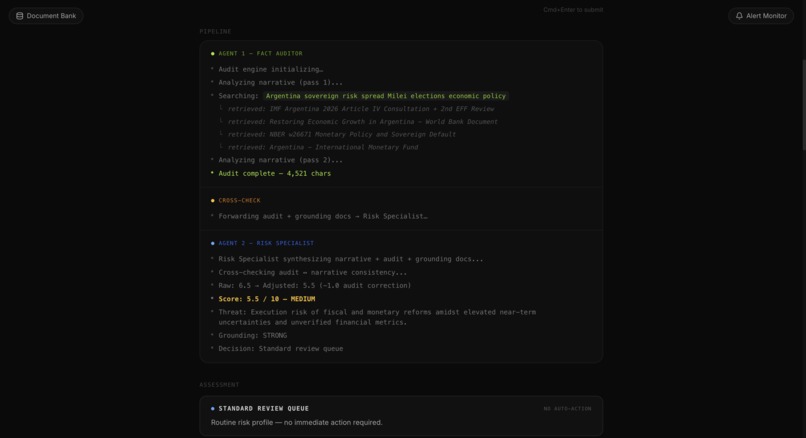
Backend is a FastAPI service on Google Cloud Run, orchestrating two Gemini 2.5 Flash agents via the Vertex AI SDK. Agent 1 operates in a tool-calling loop, invoking an Elasticsearch search tool exposed through the official Elastic MCP server. The retrieval strategy is Reciprocal Rank Fusion combining BM25 multi_match with kNN using the .multilingual-e5-small model. Agent 2 receives the audit findings and grounding documents and produces structured JSON output via constrained decoding.
The frontend is a Next.js dashboard on Cloud Run consuming a Server-Sent Events stream, rendering each agent step in real time. The document bank curator runs on Cloud Scheduler, discovers new PDFs via Tavily Search restricted to 69 whitelisted official domains. Every assessment is persisted to a searchable macro-pulse-audit Elasticsearch index, forming a full governance trail.
Challenges we ran into
The Elasticsearch trial ML tier was the hardest constraint. The .multilingual-e5-small deployment scales to zero between requests, causing the first kNN search in any session to hang for up to 30 seconds waiting for the node to warm. I added ML preflighting before every ingest, automatic fallback to keyword search on timeout, and pinned the ML node configuration to prevent scale-to-zero.
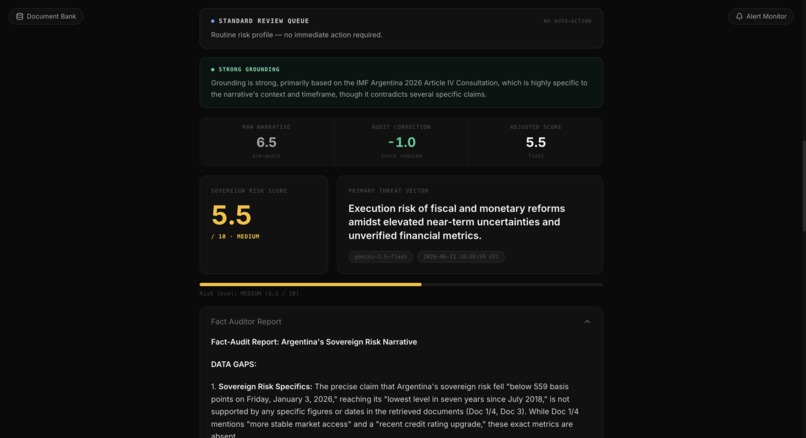
Calibrating the two-score system took significant iteration. The raw_narrative_score is supposed to reflect the narrative as written, but a positive Argentina article would score 2.5 even though Argentina's sovereign risk is objectively elevated. I added an explicit instruction in the specialist persona that for sovereigns with documented default history or active IMF programs, the raw score cannot fall below 4.5. The adjusted score then moves independently based on what the audit actually found, giving a meaningful signal rather than just two numbers that track each other.
Accomplishments that we're proud of
The audit quality exceeded our expectations. The fact auditor consistently identified specific discrepancies, citing the exact IMF document section that contradicted a claim, or flagging a precise figure that appeared nowhere in the retrieved corpus. On the Argentina test case, it caught that the narrative framed a $17 billion reserve target as a positive signal while the retrieved IMF Article IV reported a missed net reserve target through end-2025. This contradiction detection, grounded in retrieved evidence would not be possible in a single-pass LLM call.
What we learned
I learnt that multi-agent pipelines fail in production in ways that are qualitatively different from single-model failures. The semaphore design which ensures that scheduled alert sweeps and bank curation don't block user-facing pipeline requests took multiple iterations to get right. The main risk is not just rate limits on individual calls but rather the interaction between background tasks and interactive latency.
Hybrid retrieval with RRF is meaningfully better than keyword search for this domain, but it is also significantly more fragile in a trial environment. The gap between the quality of results when the ML node is warm versus cold is large enough to affect downstream scoring. This reinforced a general lesson that in agentic systems, the quality of retrieval is not a secondary concern but yet the primary determinant of output quality, and infrastructure reliability around the retrieval layer deserves as much attention as the model.
What's next for MacroPulse
The most important next step is expanding the document bank beyond the current 169 documents to full coverage of the IMF's Article IV consultation archive, World Bank country assessments, and BIS working papers, structured as a continuously updated corpus rather than a static knowledge base. With broader coverage, the grounding strength would shift from PARTIAL to STRONG for most G20 sovereigns, and the audit findings would be substantively richer.
On the infrastructure side, I want to move the autonomy gate from a binary grounding-strength classifier to a continuous grounding score derived from the semantic similarity between retrieved documents and the narrative being audited. This would make the autonomy threshold a modifiable parameter that a risk desk could calibrate to their own tolerance.
Built With
- elastic-mcp
- elasticsearch
- fastapi
- fred
- gemini
- google-cloud
- mcp
- next.js
- python
- resend
- tailwind
- tavily
- typescript
- vertex

Log in or sign up for Devpost to join the conversation.