-
-
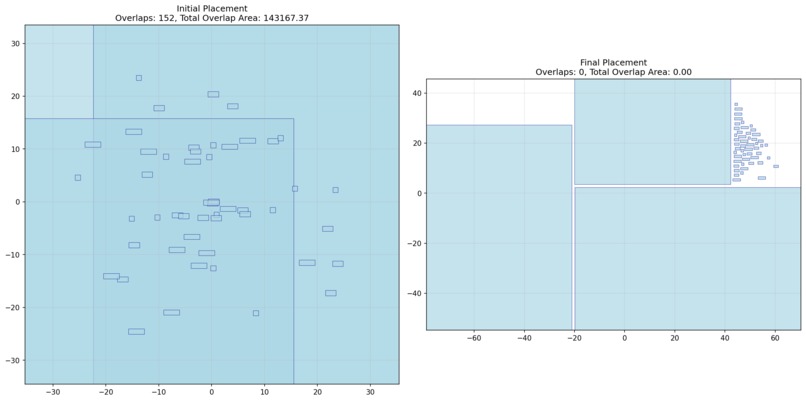
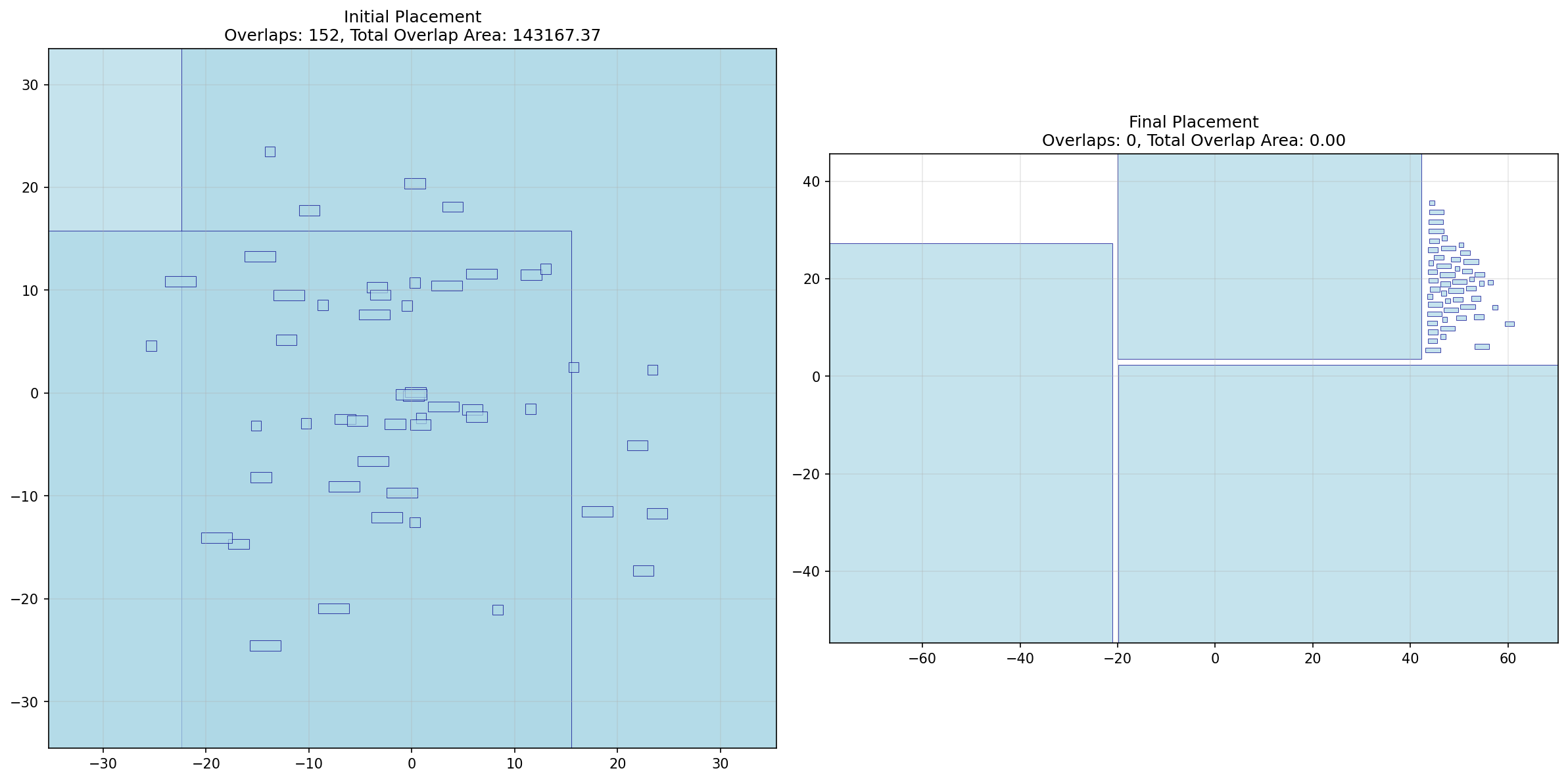
Initial vs final placement showing the model eliminating all overlaps, reducing total overlap area using gradient based optimization.
Inspiration
I went into this project with zero background in VLSI. No chip design classes, no placement algorithms memorized, no intuition for macros or routing congestion. That was the point. I have always been drawn to problems where the surface looks intimidating but the core question is simple if you strip it down enough. Cell placement is one of those problems. At its heart, it asks how to arrange objects in space so they do not collide and so the connections between them stay short. That is a systems problem. It has geometry, constraints, tradeoffs, and scale. Those are the exact environments where machine learning systems become interesting, not as black box predictors, but as optimization engines that learn from feedback. Instead of starting by memorizing classical placement heuristics, I wanted to approach the problem from first principles. If a human can reason about overlaps and wiring cost, could I encode that reasoning into loss functions and let a machine iteratively improve the layout on its own? That curiosity became the foundation of this project.
What it does
This project is a machine learning driven system that learns how to place VLSI cells using gradients instead of rules. Given a randomly generated chip layout with overlapping cells and long interconnects, the system optimizes cell positions to produce a legal placement with zero overlaps and reduced wirelength. It does not rely on handcrafted placement rules or search heuristics. Instead, it treats placement as a continuous optimization problem. The system takes in a netlist represented as tensors, defines differentiable objectives that reflect physical constraints, and uses gradient based optimization to iteratively improve the layout. The result is both quantitative metrics that match test suite criteria and visual evidence showing the layout becoming cleaner over time. This turns placement from a static algorithm into a learning driven system.
How we built it
I built this like a full machine learning system, except instead of training a classifier, I’m training positions on a chip. Everything starts with a synthetic netlist generator, because I wanted full control over the problem distribution. In generate_placement_input, I create a mix of macro cells and standard cells, compute width and height from area, and assign a realistic pin count per cell. Then I generate pins inside each cell using relative coordinates. That detail matters because in real placement, pins move when the cell moves, so the model needs to reason about geometry, not just a graph. Finally I create edge_list, which is a random pin connectivity graph that represents the wiring the optimizer will later try to shorten. All of this is stored as PyTorch tensors so gradients can flow cleanly. Once the “dataset” exists, I treat placement as an optimization problem. The state the model learns is just the 2D position of every cell. Sizes and connectivity stay fixed. In train_placement, I clone the initial tensors, then create cell_positions as the only learnable parameter with requires_grad=True. That design choice keeps the system stable and makes the whole training loop feel like a clean ML pipeline. Then I define two differentiable objectives. Wirelength_attraction_loss is the “bring connected things closer” force. Pins are stored relative to their parent cell, so every forward pass recomputes absolute pin coordinates by adding the current cell position plus the pin offset. For each edge in edge_list, I compute a smooth Manhattan style distance using logsumexp so the loss stays differentiable and gradients do not become jagged. I normalize by the number of edges so the scale stays comparable across different designs. Overlap_repulsion_loss is the real core. Overlap is not something you can ignore in placement, so I convert it into a differentiable penalty. I compute pairwise distances between all cells and compare them to the minimum separation required to avoid overlap. Instead of hard thresholds, I use softplus to create a smooth overlap barrier. As training progresses, I anneal the sharpness so the model transitions from a soft “hint” early on to a strict “no collisions allowed” later. On top of that, I add a small Coulomb style repulsion field that helps prevent early clustering. It spreads cells out when gradients are messy, then relaxes as the model starts finding legal placements. The training loop is standard ML discipline applied to geometry. I use Adam, schedule the learning rate, anneal the overlap weight, and clip gradients to prevent unstable jumps. Every 100 epochs, I save a visualization so you can literally watch the layout go from chaotic overlaps to a clean placement. To make sure this is not just “the loss went down,” I built a separate evaluation layer that is intentionally non differentiable. calculate_cells_with_overlaps checks legality by counting how many unique cells are still involved in any overlap, because that matches how placement is judged. calculate_normalized_metrics reports two headline scores: overlap ratio and normalized wirelength, where wirelength is normalized by nets so designs of different sizes can be compared fairly. Finally, test.py is the system level proof. It runs the optimizer across 10 designs from small to massive, with fixed seeds, and reports overlap ratio, normalized wirelength, and runtime. In other words, it is not just a demo. It is a mini benchmark harness that checks whether the approach generalizes beyond a single cherry picked example. If I had to summarize the build in one sentence: I turned chip placement into a learnable ML optimization loop, then wrapped it with real metrics and a test harness so I can prove it works.
Challenges we ran into
The biggest challenge was translating physical intuition into smooth mathematics. Early versions of the overlap loss either failed to fully eliminate overlaps or caused unstable gradients that made optimization explode. Hard penalties do not work well with gradient based methods. Everything had to be softened, annealed, and carefully scaled. Another challenge was evaluation. A loss decreasing does not mean a placement is legal. I needed a completely separate, non differentiable evaluation layer that computes exact overlap geometry and reports metrics that actually matter. Designing metrics that were fair across different design sizes required careful normalization. Finally, scaling exposed tradeoffs. Pairwise overlap is inherently quadratic. For a challenge setting this is acceptable, but it forced me to think about how real systems would accelerate or approximate this computation.
Accomplishments that we're proud of
I am proud that this system consistently produces placements with zero overlapping cells across randomized test cases of varying sizes. I am proud that the optimizer learns purely from loss signals without any placement heuristics baked in. I am proud that the project is not just a model but a full system. It includes data generation, optimization, evaluation, and visualization, all designed to work together. Most of all, I am proud that I took a domain I did not understand and built something meaningful by reasoning from first principles.
What we learned
This project reinforced that machine learning systems are about designing the right feedback loops. The hardest part was not writing code. It was deciding what signals the optimizer should see and when. I learned how annealing shapes learning dynamics, how smooth approximations enable optimization, and how evaluation metrics can subtly change incentives. I also learned that machine learning becomes most powerful when it is used as a tool for reasoning. I was one-dimensional for thinking only about the prediction angle.
What's next for Machine Learning Systems Design for VLSI Cell Placement
The next milestone is pushing normalized wirelength closer to zero while maintaining strict legality. With more time, this could be achieved by adding congestion aware density penalties, introducing hierarchical placement stages, and learning better pin embeddings instead of using fixed offsets. Incorporating real benchmark netlists would also allow comparison against classical tools. Longer term, this approach could evolve into a hybrid system where traditional EDA constraints define feasibility and machine learning handles optimization under real world complexity. At its core, this project is about teaching a system not just to learn from data, but to learn how to design. It would require me to review and implement more ideas from other sophisticated research papers.

Log in or sign up for Devpost to join the conversation.