-
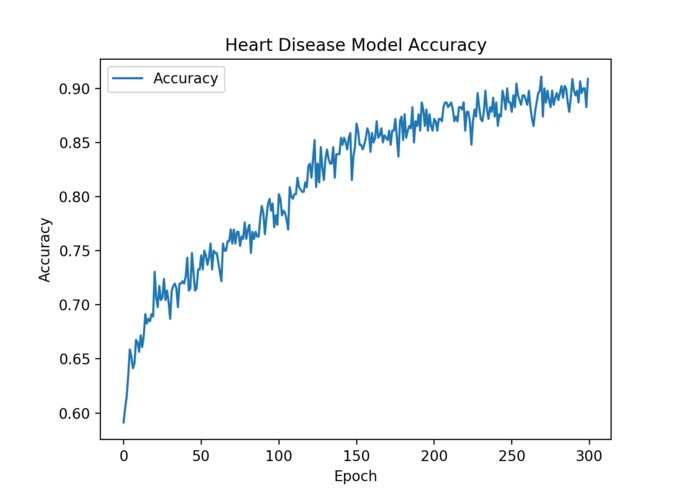
Graph of machine learning model accuracy over 300 epochs
Inspiration
To improve detection of heart disease using machine learning
What it does
It predicts the chance of a person having heart disease given 13 pieces of data about the person. These variables are age, sex, resting blood pressure, serum cholesterol levels, fasting blood sugar, resting electrocardiographic results, presence of chest pain, maximum heart rate, ST depression induced by exercise relative to rest, number of major vessels colored by fluoroscopy, presence of exercise induced angina, slope of peak exercise, and the presence of reversible or fixed defects.
How we built it
We leveraged Python, Keras, and TensorFlow to predict the relationship between these 13 variables and the presence of heart disease. We trained multiple multilayered models using different optimizers and loss functions. Our best results were obtained with a binary cross-entropy loss function, yielding over 90% accuracy in predicting heart disease and a high F1 score. We used datasets compiled by UC Irvine.
Challenges we ran into
Accomplishments that we're proud of
What we learned
We practiced adapting neural networks, adjusting algorithms to prevent overfitting, and plotting in PyPlot.
What's next for Machine Learning Algorithms to Predict Heart Disease
Built With
- keras
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.