-
-

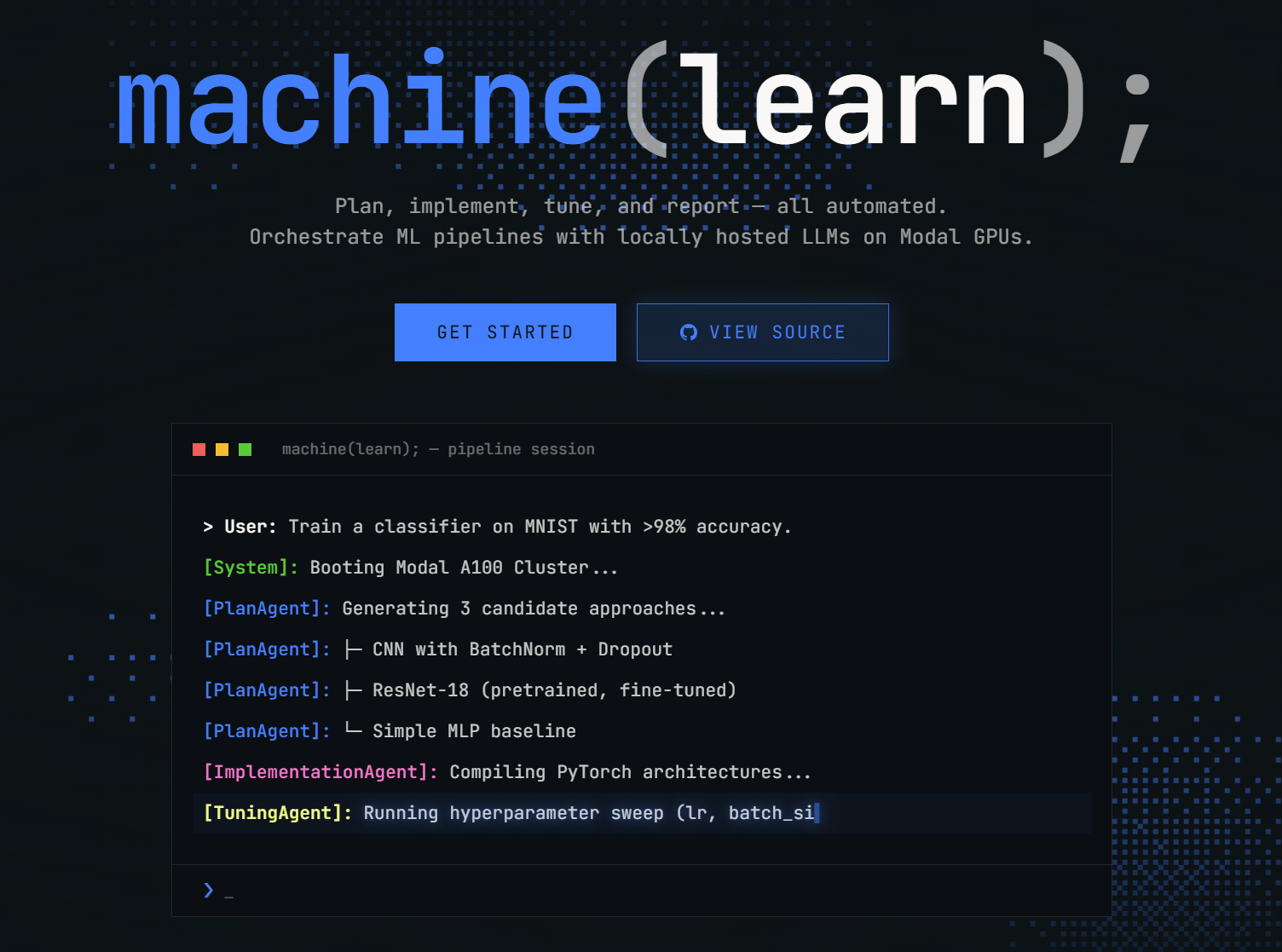
The landing page and mock terminal showcasing our 4-phase ML agent swarm in action.
Inspiration
Training a custom ML model feels like wrestling with infrastructure. Between PyTorch boilerplate, CUDA OOM errors, and babysitting tuning loops, the friction is massive. We realized the hardest part of ML isn't the calculus but the plumbing. We wanted to make training a state-of-the-art model as frictionless as typing: "Classify this dataset with >98% accuracy."
What it does
machine(learn); is an autonomous AI pipeline for ML experimentation. Users upload a dataset to our Next.js dashboard and provide a plain-English prompt. Our multi-agent swarm takes over:
- PlanAgent: Proposes 3-5 distinct ML approaches.
- ImplementationAgents: Generates PyTorch training code and spins up parallel, serverless GPUs to execute them.
- TuningAgents: Adjusts hyperparameters to autonomously optimize the objective function across iterations.
- ReportAgent: Aggregates the best model, packages the code, and streams final metrics.
How we built it
- Backend (Compute): Python and
asynciofor orchestration. We deployed locally hosted LLMs viavLLMdirectly onto Modal's serverless GPUs. - State Management: Supabase (Postgres) with Realtime subscriptions acts as our message broker. Agents push structured JSON payloads as they hit milestones.
- Frontend: A Next.js 14 dashboard with a brutalist, terminal-IDE aesthetic and a live flowchart of the swarm's execution using Framer Motion.
Challenges we ran into
- VRAM Cold Starts: Initially, our LLM server deployed alongside our run pipelines, causing massive cold starts as models loaded into VRAM for every execution. We solved this by decoupling the LLM server into a dedicated, persistent Modal service (
ml-agent-llm-service), keeping the container warm and slashing latency. - True Parallel Execution: We needed to guarantee the agent swarm actually ran in parallel, with each agent receiving its own dedicated GPU and inference capabilities. We achieved this by leveraging Modal's serverless architecture combined with Python's
asyncio.gather(). Each agent spawns in an isolated container, scaling horizontally while concurrently querying the shared LLM service.
What we learned
Heavy agent frameworks like LangChain are often overkill. By using pure Python asyncio and strictly typing our outputs, we built a faster, more deterministic swarm. We also learned the power of separating UI state from heavy compute using Postgres.
What's next for machine(learn);
"One-Click Deploy." Once the ReportAgent selects the best model, we want the system to automatically containerize the weights and expose them as a scalable FastAPI endpoint.
Built With
- asyncio
- css
- fastapi
- framer-motion-(state-driven-ui-animations)
- modal
- next.js
- postgresql
- pydantic
- python
- pytorch
- qwen
- react
- supabase
- tailwind
- tailwind-css
- three.js
- typescript
- vllm

Log in or sign up for Devpost to join the conversation.