-
-

Intact Challenge
-
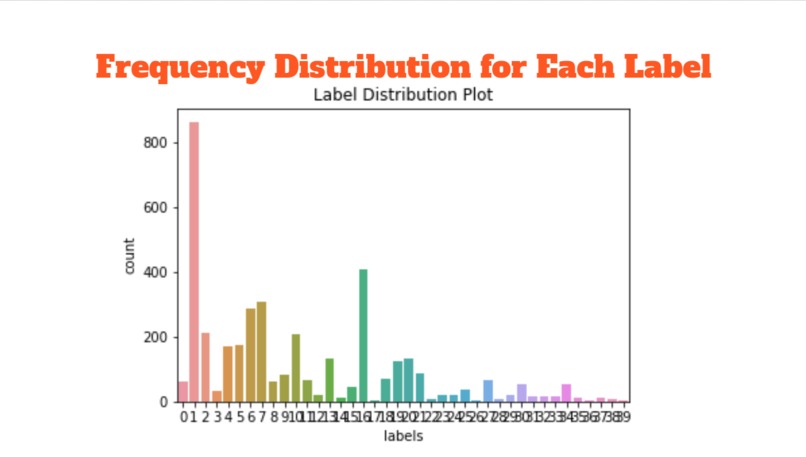
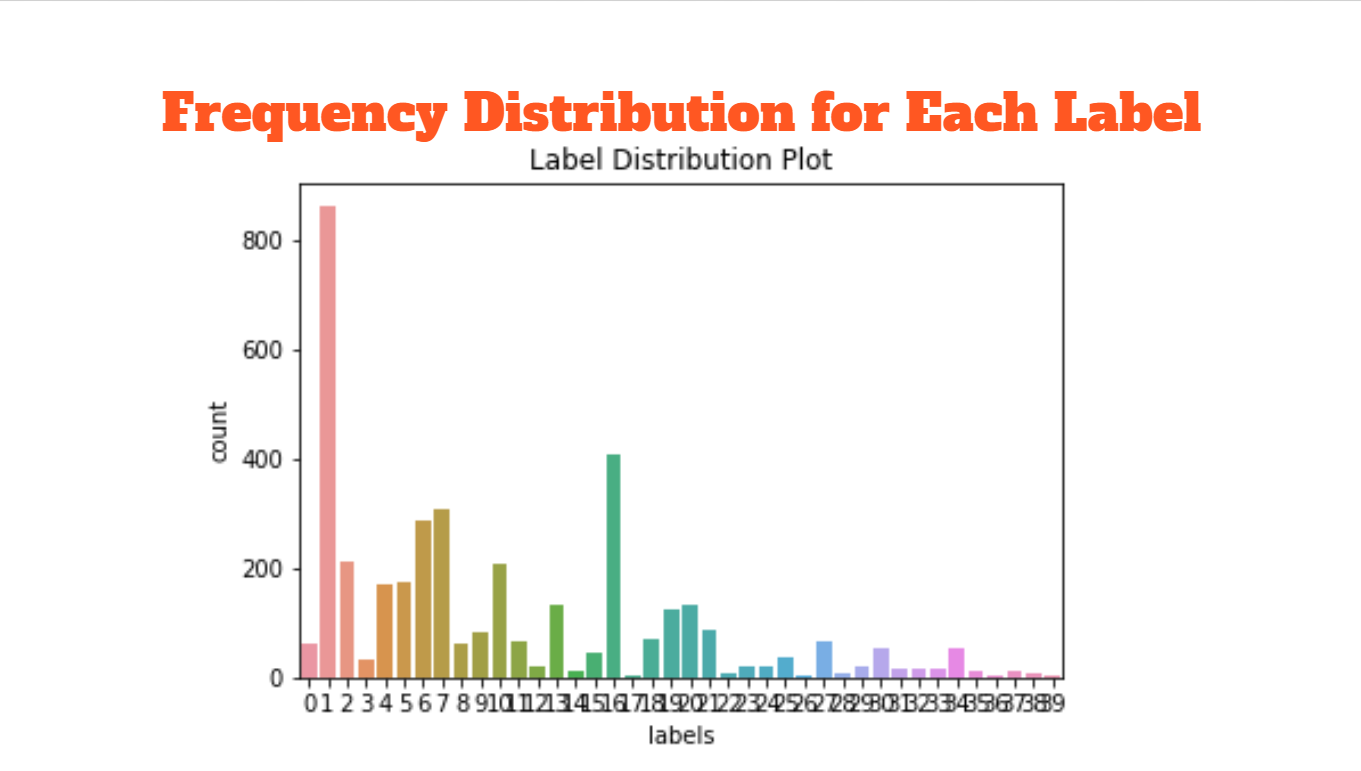
Frequency Distribution Plot
-

Bert Parameter Settings
-
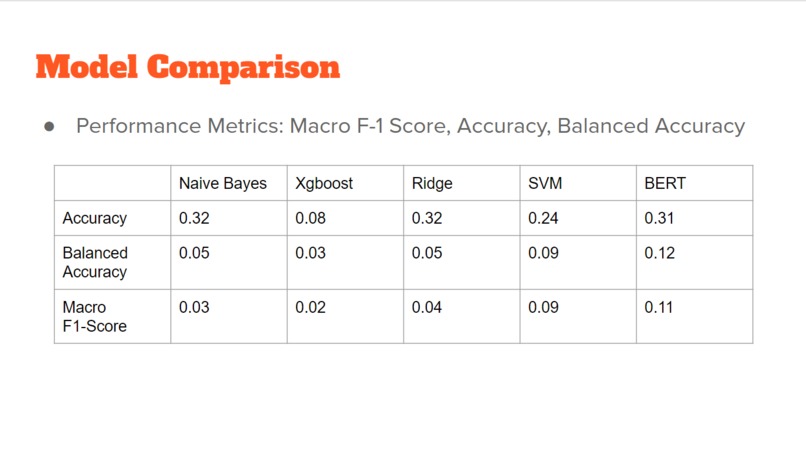
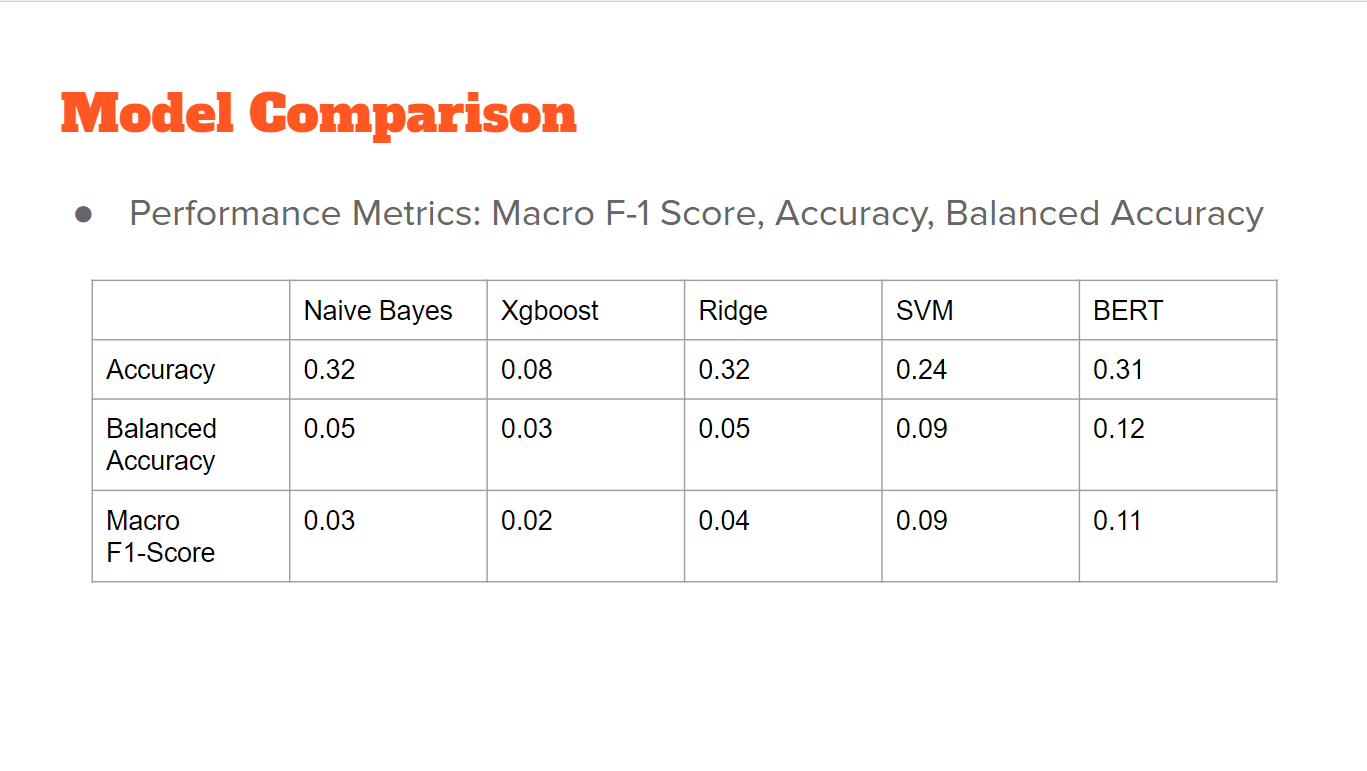
Model Comparison


Inspiration
The project motivated us to explore different techniques and tools used in data science
What it does
Intact's claims department receives thousands of documents every day. Among these are medical documents, as Intact provides compensation to those who have sustained injuries in automobile accidents. Due to the volume of data received on a daily basis, it is difficult to keep every document neatly organized for easy retrieval. Thus, it would be helpful to have a system that automatically makes sense of the content of the document and can classify it into one of a set number of categories.
Our group classifies each medical transcription into a medical specialty
The evaluation is based on F1-score with macro averaging on the test set
How we built it
Data Exploration
- Plots for showing basic information in text words
Data Preprocessing
- Preprocess the text words for better analysis
Data Modeling
- Split train/test sets for model comparison
- Normal Classification Models (Xgboost, SVM, Rigid Classifier)
- Pre-trained Model - BERT
Challenges we ran into
The BERT model needs large RAM to run and GPU to utilize the model. This makes us difficult to tune the parameters.
Accomplishments that we're proud of
We trained the best model with a great macro F-1 score and accuracy.
What we learned
Python, Natural Language Preprocessing, Language Models, Machine Learning
What's next for M3 biubiubiu - Intact
Keep improving our skllsets
Built With
- language-models
- machine-learning
- natural-language-processing
- python


 Shan")
 Shan")
Log in or sign up for Devpost to join the conversation.