-
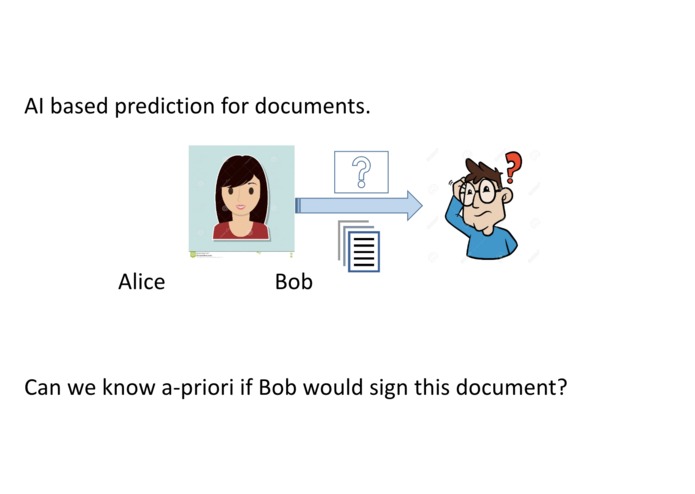
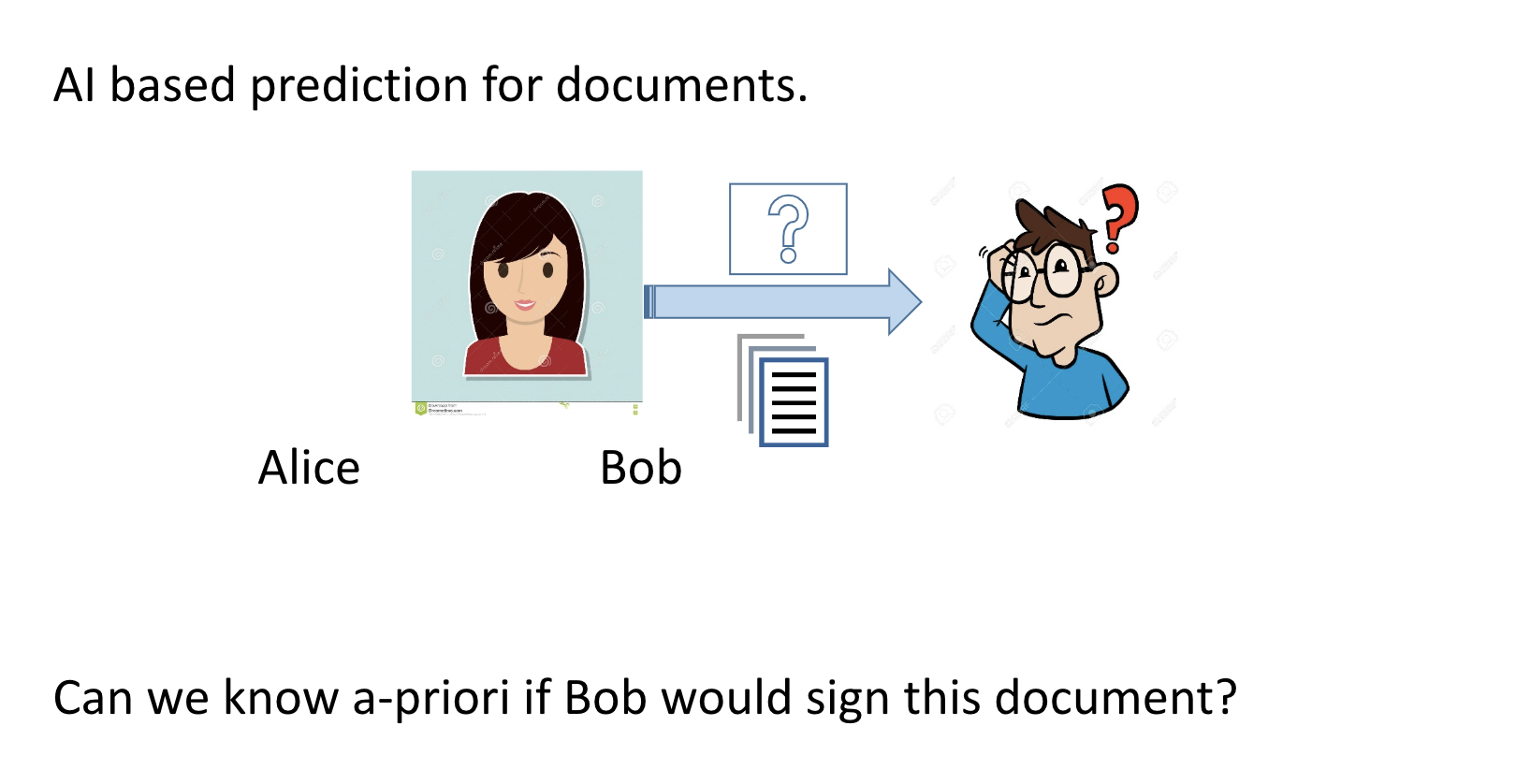
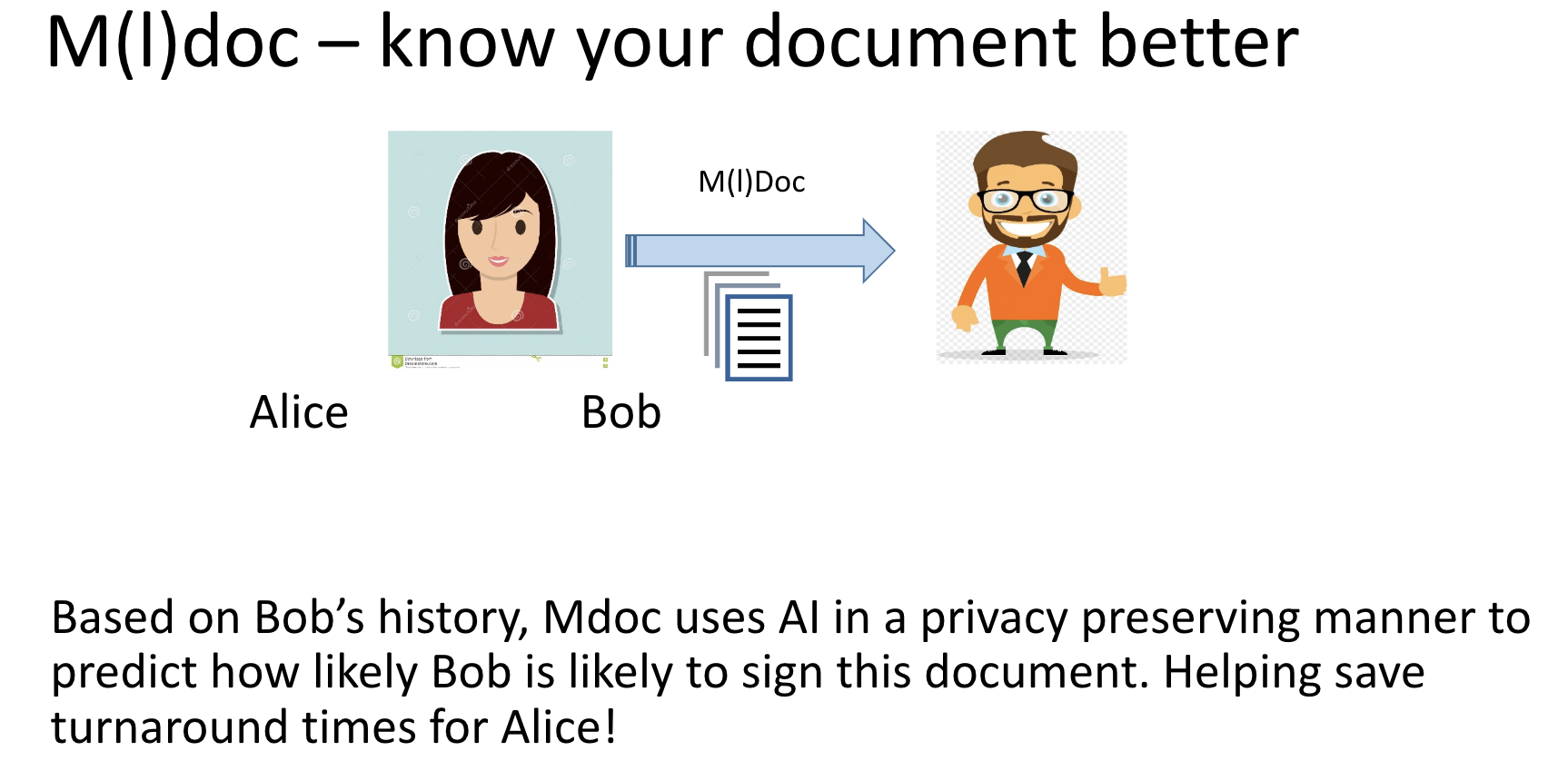
Will Bob sign this document?
-
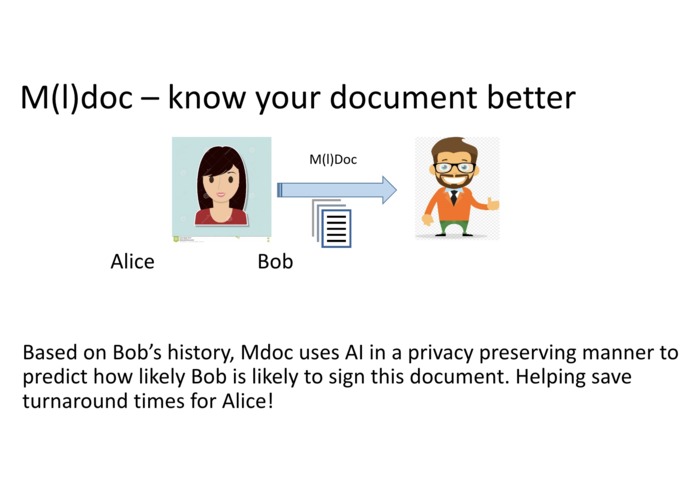
We predict before you send the document to Bob!
-
M(l)Doc Workflow
Inspiration
HR's spend a lot of time sending documents back-and-forth and in-turn increase the risk of losing out on quality candidates. For example, an HR wanting to get an offer letter signed from a prospective employee needs to shoot back and forth multiple emails during the negotiation phase. We believe this can be significantly reduced if we predict the response of the receiver to any document you send out to sign. thus, minimizing the unnecessary time and man-power spent in finding the perfect middle ground.
What it does
Imagine Alice is an HR in a top Silicon-Valley start-up (Go Bears!). Alice wants Bob to (Docu)Sign an offer letter. We Propose M(l)Doc. M(l)doc uses AI in a privacy-preserving manner to predict how likely Bob will sign the document in its current form. Hence, Alice can short-circuit multiple to and fro communications just by using M(l)Doc, helping save time for Alice!
How we built it
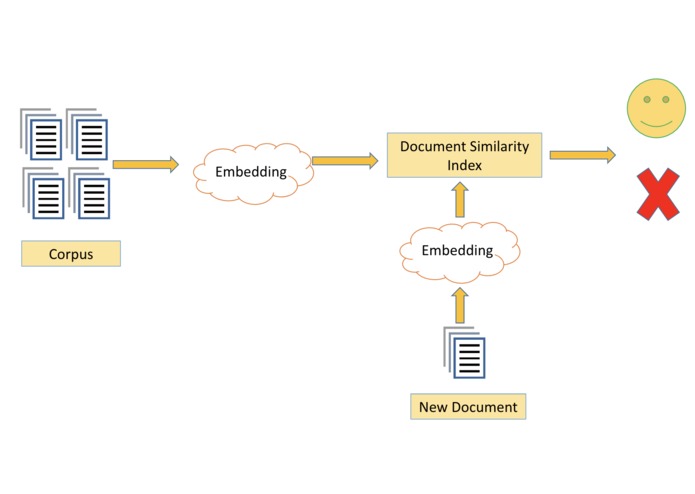
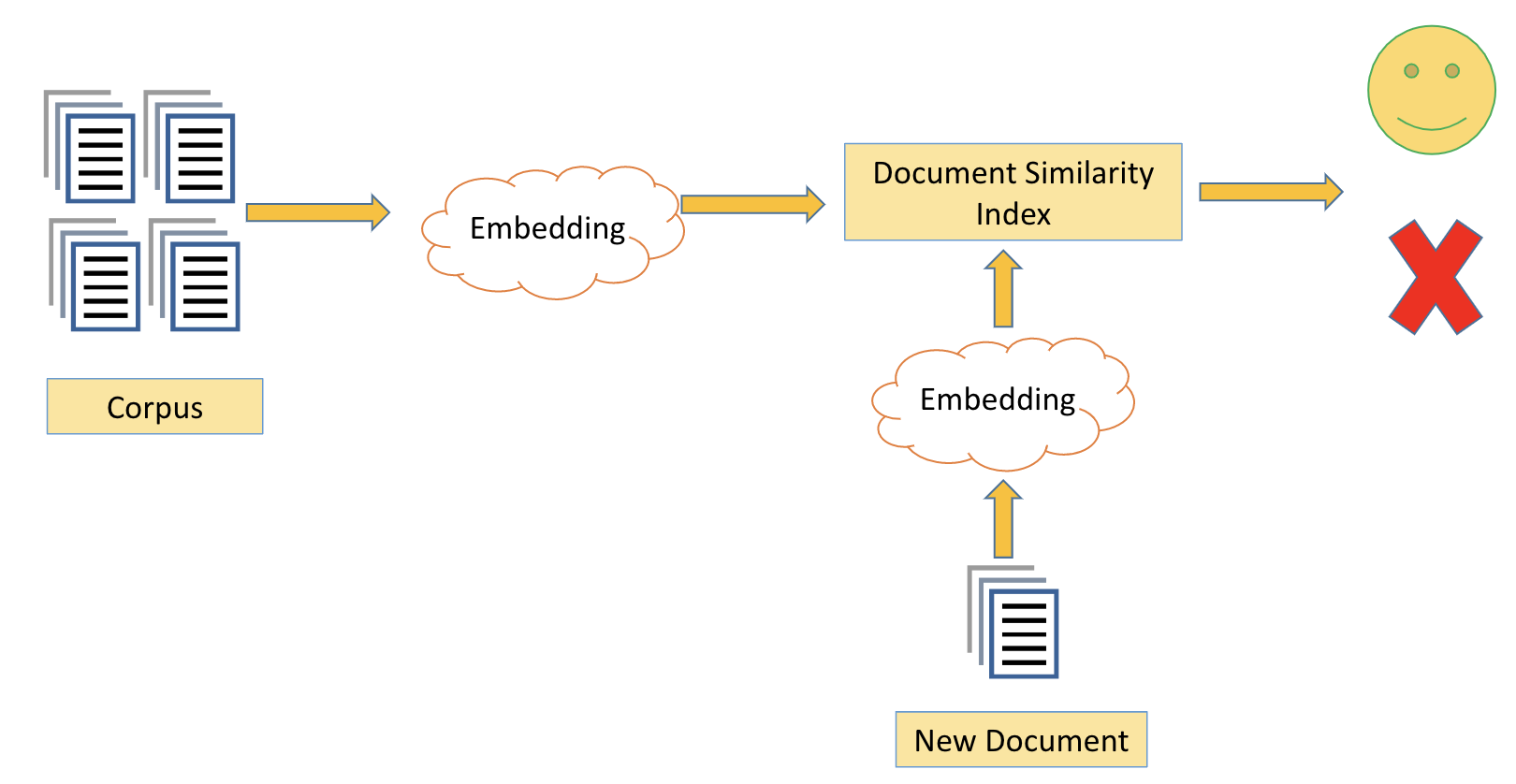
M(l)Doc initially relies on the previous corpus and a word-embedding model. Each document (from Alice) is mapped into this word embedding and is compared to the corpus. If there is a high positive match, then we predict that the document is likely to be signed (by Bob).
Challenges we ran into
Converting the data into a standardized form to be able to run our modeling algorithms(ML) and extract relevant information from the documents and bucketize them into similar categories based on the text.
Accomplishments that we're proud of
We are able to successfully find the cosine similarity of different documents and mark a precise percentage of similarity/dissimilarity between them.
What we learned
What's next for M(l)-Doc
The current edition of M(l)Doc involves a single embedding per user. We foresee a system where each document is conditioned not just on the sender (Alice), but also on the receiver (Bob).
Built With
- docusign
- envelopedocumentfields
- gensim
- numpy
- oauth
- python
- scikit-learn




Log in or sign up for Devpost to join the conversation.