Inspiration
Every developer knows the feeling. You open a legacy codebase, see 3,000-line God classes, methods named doEverything(), and think "I should really clean this up." Then you check the clock, realize it's already 4pm, and close the file. Repeat tomorrow.
We've all been there. Technical debt isn't a mystery, we know how to fix it. The problem is it takes forever, it's boring, and there's always something more urgent. Meanwhile, that debt compounds. Companies are bleeding $2.41 trillion annually on this stuff. Engineers spend 13+ hours a week just working around bad code.
So we asked: what if you could point an AI at a messy codebase, go to bed, and wake up to cleaner code? Not a one-shot refactoring tool that breaks everything. A marathon agent that actually understands the codebase, runs tests, rolls back mistakes, and just keeps going.
What it does
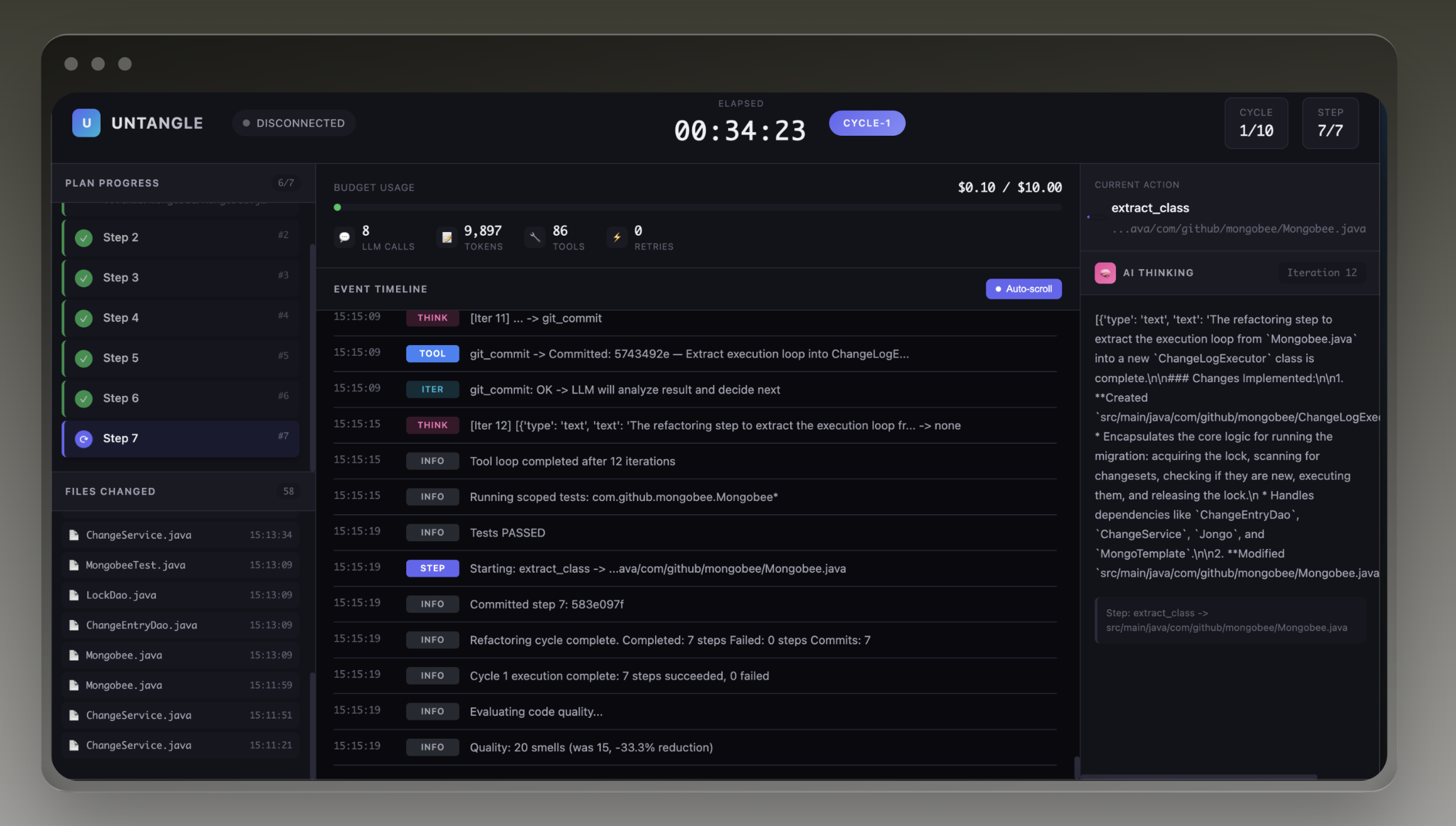
UNTANGLE is an autonomous AI agent that refactors legacy codebases over extended periods—hours to days; without babysitting.
You point it at a repo. It analyzes the code, builds a knowledge graph of entities and dependencies, detects smells (God classes, long methods, feature envy, etc.), creates a prioritized plan, then starts fixing things. Each change gets tested in a Docker sandbox. If tests pass, it commits. If they fail, it retries or rolls back. It creates git savepoints so you can always revert.
The key thing: it persists. It remembers what it learned. It can research patterns it doesn't know. It tracks its budget so it doesn't blow through API costs. And you can watch the whole thing happen in real-time.
### How we built it
LangGraph for orchestrating the multi-step workflows (analyze → plan → refactor → verify → repeat). Gemini 3 pro preview, Tree-sitter for parsing ASTs without needing a full compiler toolchain.
The architecture has three main graphs that feed into each other:
- Analysis Graph: Parses code, detects smells, builds the knowledge graph
- Planning Graph: Prioritizes refactoring opportunities, generates step-by-step plans
- Refactoring Graph: Actually writes code, runs tests, handles retries and rollbacks
Everything runs in Docker for safety. We auto-detect what services the codebase needs (MongoDB, Redis, Postgres, etc.) by scanning the pom.xml and spin up the right containers automatically.
State gets checkpointed constantly so the marathon can resume it it crashes. There's a full audit trail in JSONL format for every decision the agent makes.
### Challenges we ran into
Getting reliable test execution was brutal. Legacy Java projects have opinions about their build environment. One repo needs Java 8, another needs 17, this one only works with a specific Maven version. We ended up building an auto-detection system that picks the right Docker image based on what's in the pom.xml.
The retry loop for failed refactorings was trickier than expected. The agent would sometimes get stuck in a loop trying the same fix. We had to add explicit "learnings" to the knowledge graph—"tried X on this method, failed because Y"—so it wouldn't repeat mistakes.
WebSocket real-time updates kept disconnecting. Turns out when you're streaming hundreds of events per second from LLM calls, you need to be more careful about batching and backpressure than we initially were.
### Accomplishments that we're proud of
The whole thing works end-to-end. You can clone a real open-source Java project, run untangle run --autonomous --web, and watch it methodically clean up the codebase over hours. Commits stack up. Tests stay green (mostly). The knowledge graph grows.
The web observatory dashboard turned out really nice. Seeing the AI's thinking process in real-time, watching it read files, consider options, write code, run tests; it makes the black box feel transparent.
The auto-infrastructure provisioning is a small thing but it's satisfying. The agent figures out "oh, this project uses MongoDB" and just starts a Mongo container. No config needed.
What we learned
Resilience matters more than speed for long-running agents. We spent way more time on checkpointing, rollback, and graceful degradation than on making the LLM calls faster.
The knowledge graph was a game-changer. Early versions had the agent re-discovering the same information over and over. Once we added persistent storage for entities, decisions, and learnings, the agent got noticeably smarter across cycles.
Budget tracking isn't optional. Autonomous agents can burn through API credits fast. Having hard limits and visibility into cost-per-operation kept us from any unpleasant surprises.
### What's next for UNTANGLE
Python and TypeScript support are the obvious next steps; Java was just the starting point because legacy Java codebases are everywhere and painful.
We want to add automatic PR creation, so UNTANGLE can open pull requests with before/after metrics and let humans review at their own pace.
A VS Code extension would make this way more accessible. Click a button, pick your cost budget, let it run in the background while you work on other things.
And eventually, GitHub Actions integration—run UNTANGLE on a schedule against your worst repos, get weekly PRs that chip away at tech debt.
The dream is a world where refactoring is just... something that happens. Like garbage collection, but for code quality.


Log in or sign up for Devpost to join the conversation.