Inspiration
Every student has been there, you search YouTube for a calculus tutorial, find something too advanced or too basic, get confused, and give up. The content exists thousands of hours of high-quality educational material but there's no intelligent layer connecting a student's specific knowledge gaps to the right material at the right time.
The deeper frustration is that quality tutoring is unevenly distributed. A student at a well-funded university has office hours, tutoring centers, and TAs. A first-generation college student taking calculus online while working 30 hours a week has YouTube and hope. That gap isn't a content problem. It's a guidance problem.
We built LusiLearn to close that gap to give every learner access to the kind of adaptive, personalized tutoring that used to require a human expert and a lot of money.
What it does
LusiLearn is a multi-agent AI tutoring platform that adapts to each learner in real time. A student can say "I need to learn derivatives for my exam in two weeks," or upload a photo of a recent test or notes, and receive a personalized two-week learning path complete with sequenced YouTube videos, adaptive practice problems, and real-time voice Q&A.
The platform covers the full learning loop:
- Personalized onboarding AI-generated profile questions assess knowledge level, learning style, and goals
- Multimodal assessment learners upload handwritten work; the system reads it, identifies misconceptions, and diagnoses exactly where reasoning breaks down
- Adaptive learning paths content curated from YouTube, ranked by semantic similarity to the learner's specific gaps, sequenced by prerequisite and difficulty
- Real-time tutoring text and voice Q&A with responses tailored to the learner's known misconceptions, under 3 seconds for text and 2 seconds for voice
- Progress tracking mastery levels per concept, spaced repetition scheduling, and intervention alerts when engagement drops
How we built it
The core insight was treating this as an orchestration problem, not a single-model problem. Effective tutoring requires multiple specialized skills happening simultaneously curation, tutoring, analysis, assessment, and no single AI model does all of them well.
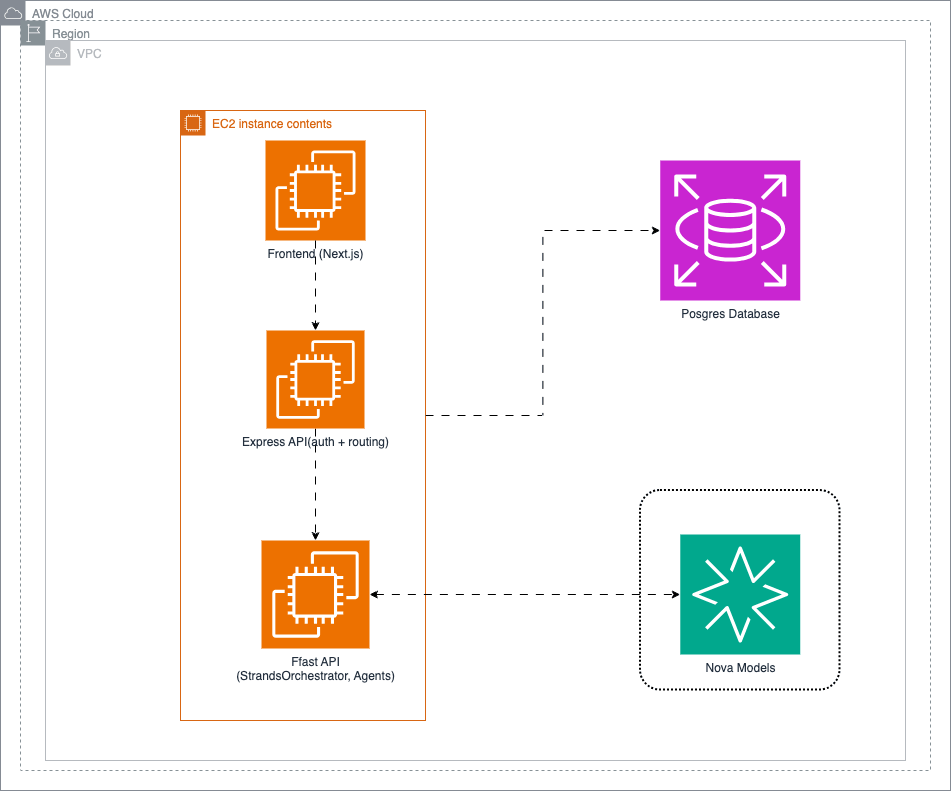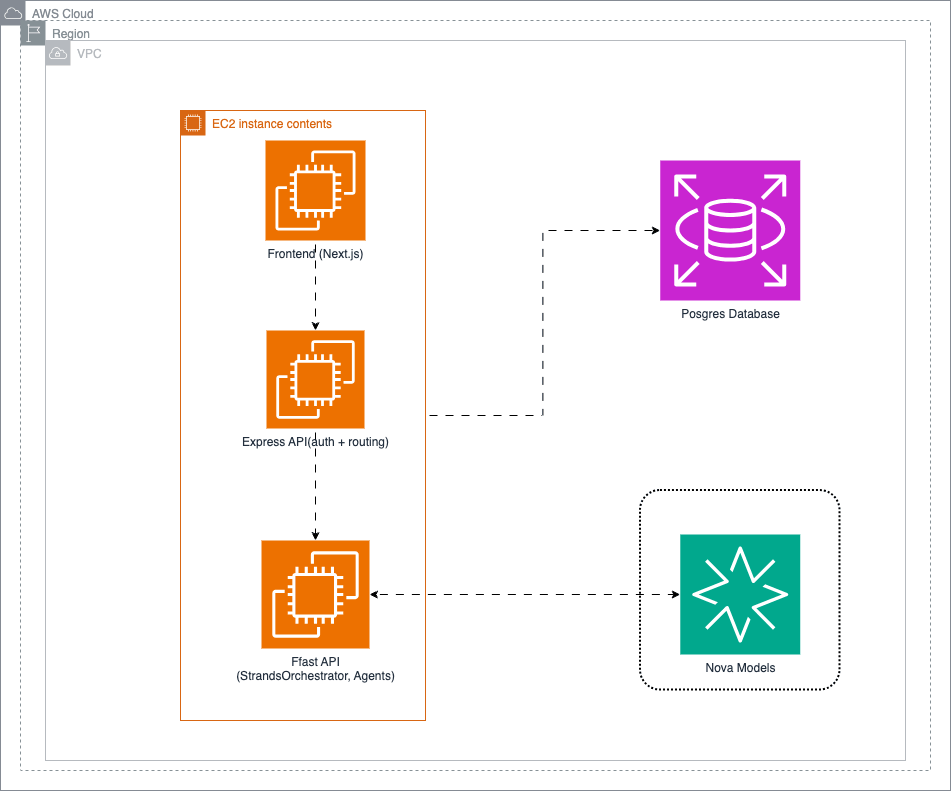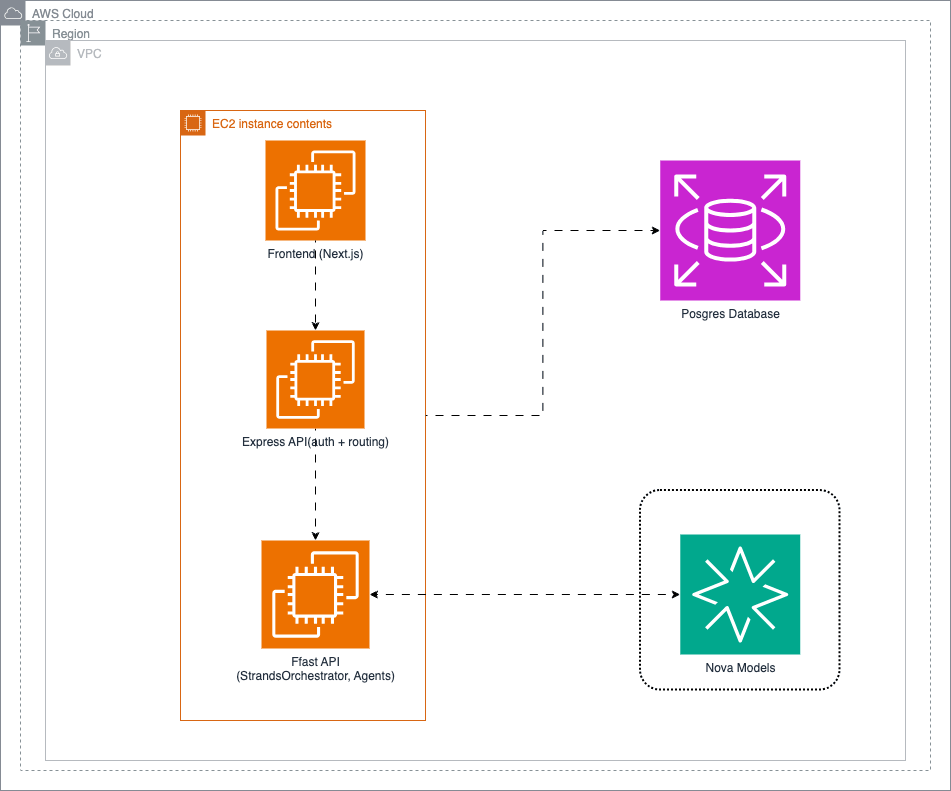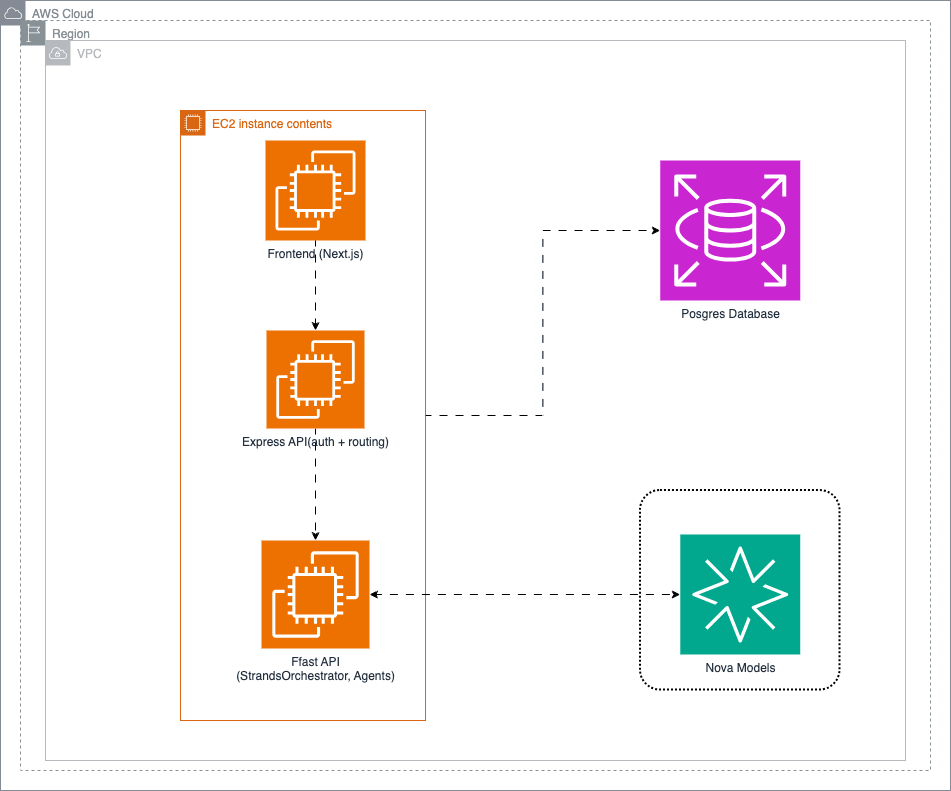
We built four specialized agents coordinated by a central orchestrator using AWS Strands Agents and Amazon Nova foundation models:
- Content Curator Agent searches YouTube Data API, ranks results using Nova Multimodal Embeddings for semantic similarity, and sequences them into a learning path. Nova Multimodal analyzes video thumbnails to extract visual teaching cues that text search misses.
- Tutor Agent handles text and voice Q&A using Nova 2 Lite for reasoning and Nova 2 Sonic for real-time voice transcription and synthesis over WebSocket.
- Assessment Agent uses Nova Multimodal to read handwritten student work, identify correct steps, and pinpoint specific misconceptions.
- Progress Analyst Agent tracks engagement patterns, predicts when learners are at risk of dropping off, and adjusts the learning path in real time.
The stack is a Next.js frontend talking to a Node.js/Express API gateway, which routes AI requests to a Python FastAPI service that owns all agent orchestration. PostgreSQL stores learner profiles and session data; Redis handles caching and rate limiting. Session memory is isolated per learner, and when context approaches token limits, Nova 2 Lite summarizes older history rather than truncating it.
Challenges we ran into
Multi-agent coordination without context leakage was the hardest architectural problem. Each agent needs enough shared context to be coherent, but learner data must stay isolated between sessions. We solved this with a structured AgentMemory object per learner that agents read from and write to through the orchestrator no direct agent-to-agent communication.
Latency targets were tight. Voice Q&A needed to complete the full round-trip (transcription → reasoning → synthesis) in under 2 seconds. Text Q&A needed to respond in under 3 seconds. Meeting those targets required careful timeout enforcement at each agent boundary and graceful degradation when a step ran long.
Multimodal image analysis for handwritten math was more nuanced than expected. Getting Nova Multimodal to reliably identify specific misconceptions not just "this step is wrong" but "you're applying the power rule where you need the product rule" required careful prompt engineering and structured output schemas.
Resilience across external dependencies YouTube API rate limits, Bedrock availability, Redis connectivity required layered fallbacks at every integration point. The system needed to degrade gracefully rather than fail hard when any one dependency was unavailable.
Accomplishments that we're proud of
The end-to-end onboarding workflow is the thing we're most proud of: a learner uploads a photo of handwritten work, and within seconds the system has read their handwriting, identified a specific misconception, and generated a sequenced learning path targeting that exact gap. That's a genuinely novel experience that didn't exist before.
The voice interaction layer also came together well. A learner can ask a question out loud and get a spoken explanation back in under 2 seconds the same conversational dynamic as talking to a human tutor, available at 11pm when there are no office hours.
We're also proud of the feedback design in the Assessment Agent. The system gives feedback that's specific and encouraging not a grade, but a diagnosis. It tells you exactly what to fix and queues a practice problem targeting that gap. That distinction matters a lot for learner psychology.
What we learned
Building a multi-agent system taught us that orchestration is the hard part. Picking the right model for each task is straightforward once you've mapped the problem. Managing shared state, enforcing timeouts, handling partial failures, and keeping the user experience coherent across four agents firing in sequence that's where the real complexity lives.
We also learned that prompt engineering for structured output is a first-class engineering concern, not an afterthought. The quality of the Assessment Agent's misconception detection is almost entirely a function of how precisely the prompt defines what a "misconception" is and what format the response should take.
Finally: graceful degradation is a feature, not a fallback. Designing every integration point to have a meaningful fallback cached content when YouTube is rate-limited, AI-generated paths when content discovery fails, fail-open rate limiting when Redis is unavailable made the system feel reliable in a way that "it works when everything works" never does.
What's next for LusiLearn
- Peer collaboration — study groups, peer tutoring marketplace, and cross-level mentoring matched by skill complementarity and learning goal alignment
- Educator dashboard — surface the Progress Analyst's intervention signals to teachers so they can focus human attention where it matters most
- Expanded content sources — Khan Academy, Coursera, and GitHub integration alongside YouTube
- Mobile app — voice-first interface optimized for learners who study on the go
- Longitudinal learning graphs — track skill development over months and years, not just sessions, to give learners a real picture of their growth
- A/B testing for recommendations — validate which content sequences actually improve outcomes and feed that signal back into the Content Curator
Built With
- amazon-bedrock
- amazon-web-services
- express.js
- fast-api
- kiro
- next.js
- node.js
- nova
- python
- strands


Log in or sign up for Devpost to join the conversation.