
Inspiration
"In 1949, former RSNA President Leo Henry Garland, MD, found experienced radiologists would miss important findings in approximately 30% of chest radiographs. Despite all the advancements, 75 years later that error rate has remained about the same. “ - https://radiologybusiness.com/topics/healthcare-management/healthcare-quality/error-rates-radiology-have-not-changed-75-years
Doctors reviewing and analyzing chest X-Rays have error. We decided to create an Artificial Intelligence model would provide a real life value in assisting medical professionals in saving lives.
What it does
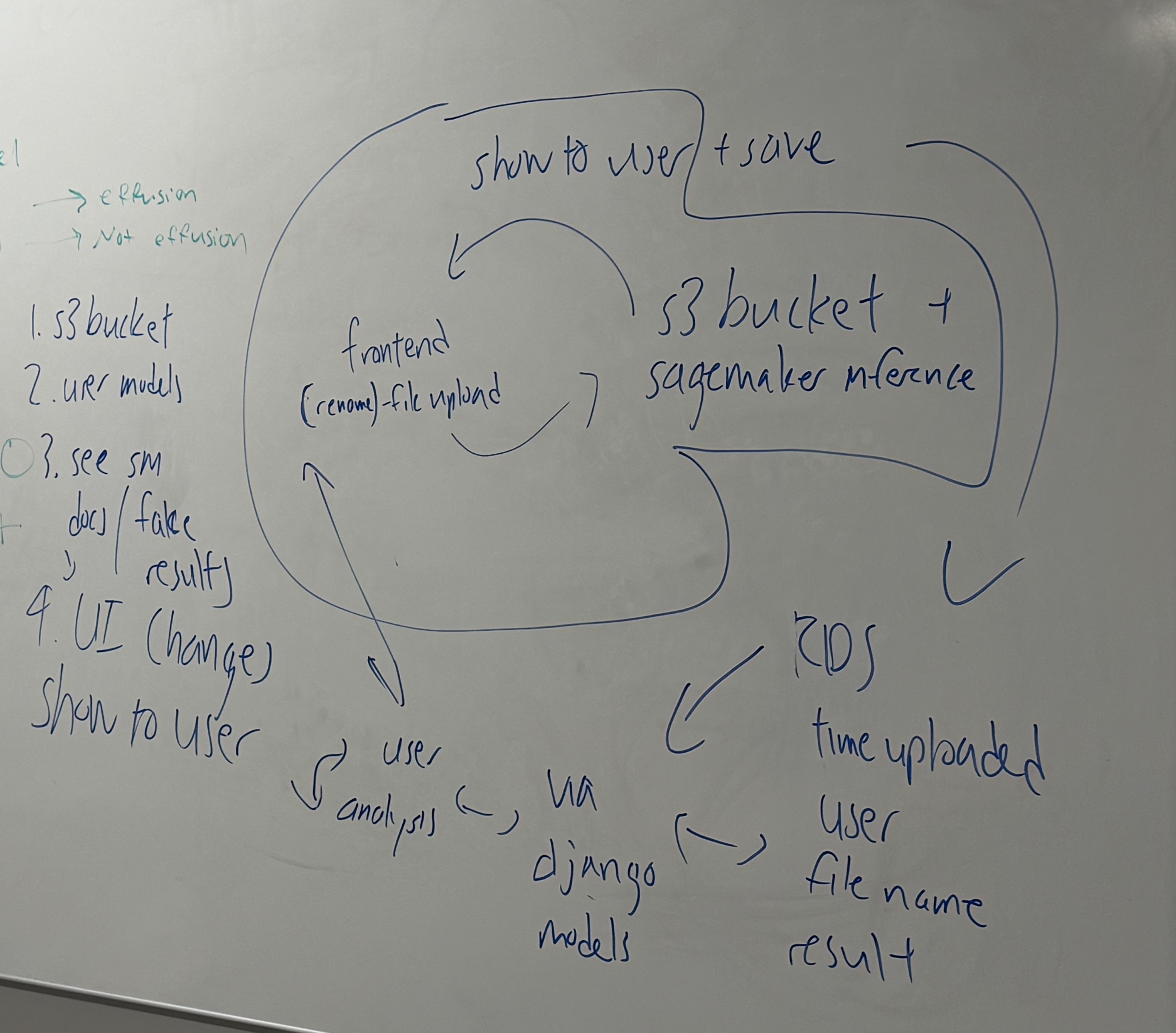
Our model takes an image of a lung X-Ray scan, returning a confidence on whether or not the lung in the image exhibits symptoms of the selected disease. The images that are uploaded are stored in a S3 bucket for future viewing, and can be linked to specific user accounts so that individuals and doctors can see scans and the results. We use a relational database (sqlite) holding both user and analysis models in order to store information.
How we built it
Backend- Flask Frontend- Bootstrap5 Model Training- SageMaker + PyTorch Storage- S3 LLM Models- Gemini 2.5 Pro, ChatGPT 5
Challenges we ran into
Due to time constraints, we wanted to find a dataset that was already labeled. Labeling turned out to be quite a large issue in chest X-rays: the Kaggle description actually states "One major hurdle in creating large X-ray image datasets is the lack resources for labeling so many images." We found one dataset that was around 120k images and was labeled using Natural Language Processing (accuracy around 90%,) and initially had issue with uploading such a large amount of images into an S3 bucket. One of the AWS mentors suggested that we split the image uploads between all our computers, which helped, but we still ran into bandwidth issues.
Initially, we were planning to do an all-in-one model, but after doing analysis on the data set, we realized that: a) some of the images had multiple diseases labeled together. b) a large amount of the scans (52%) were labeled as "No Finding," only leaving around 31k images that had both a single label and were not "No Finding." After this realization we switched to a binary classification model with the goal of determining whether or not a scan was a specific disease, instead of trying to guess what it could be a combination of.
Accomplishments that we're proud of
Despite it being our first time using SageMaker, on top of working with a limited data set, we were proud that we were able to successfully create a model, exporting it to S3 so that we could have an inference endpoint.
Additionally, coming into the hackathon, we actually didn't do much planning and brainstorming. As soon as we came up with an idea however, we were extremely diligent in deciding a good project structure, and all the individual parts that we would need to flesh out.
What we learned
We learned so much about AWS services especially S3 and Sagemaker. Figuring out how to store images in S3 buckets, how to train models in conjunction with PyTorch, and opening inference endpoints so that we could make calls to it from our backend!
As for planning in the hackathon, we learned the importance of prioritizing things that take longer times- especially file uploads that are dependent on bandwidth and other factors.
What's next for LungEffusion
We would like to add additional features- in addition to the currently existing logic, we would like to utilize Amazon RDS to do more storage on image details. In particular, we would store user information, image upload timestamps, the file name, and the result produced from the inference endpoint. This would extend into functionality where doctors can link up with their patients, and see previous scans/results of their patients.
Built With
- amazon-web-services
- bootstrap5
- django
- ec2
- python
- pytorch
- s3
- sagemaker

Log in or sign up for Devpost to join the conversation.