-
-
Login page
-
This is teacher home page
-
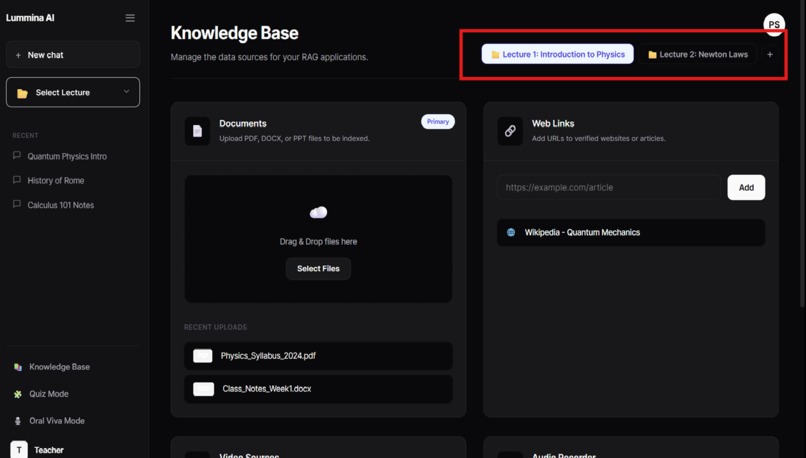
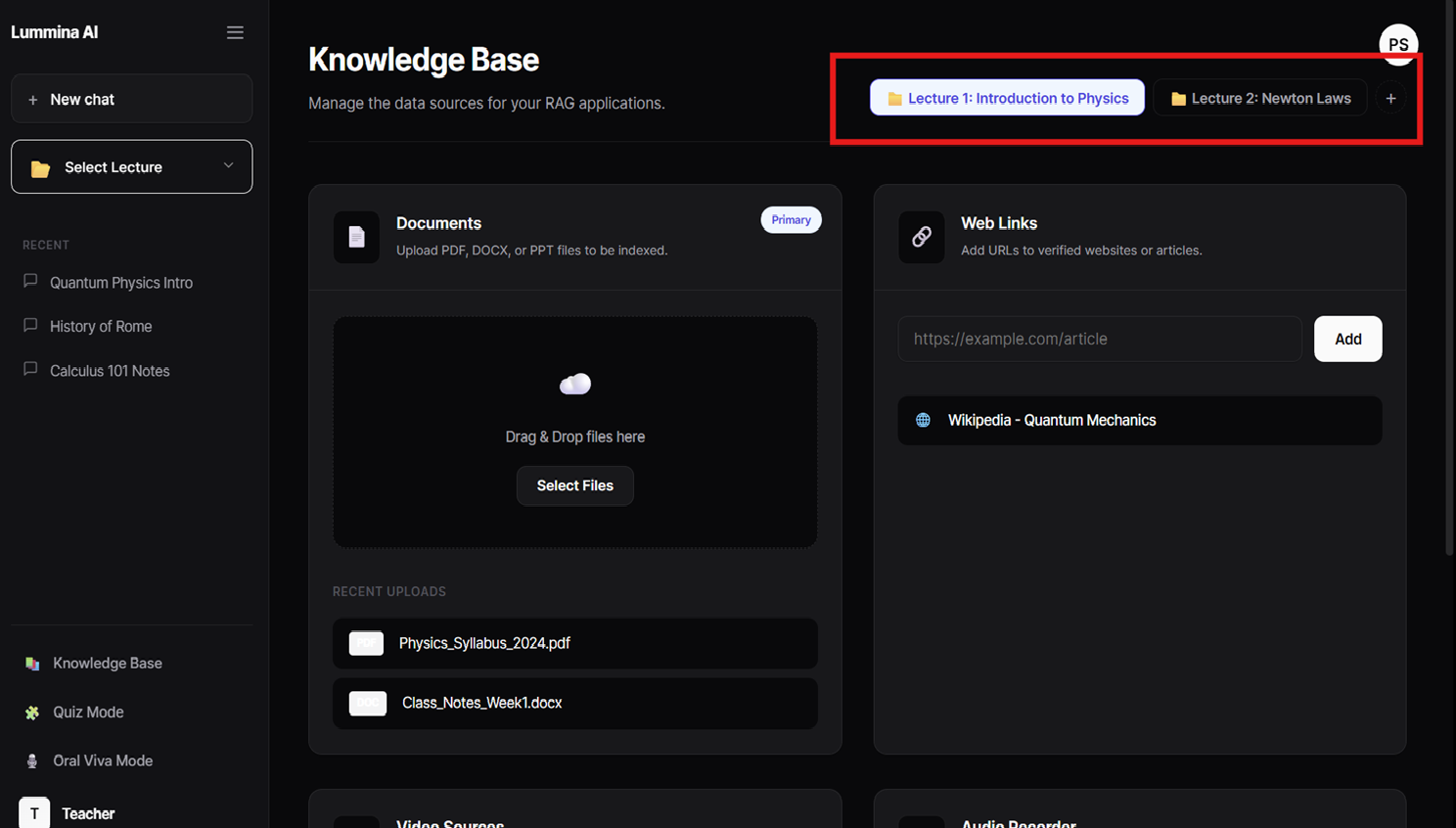
This is knowledge page where teacher uploads documents
-
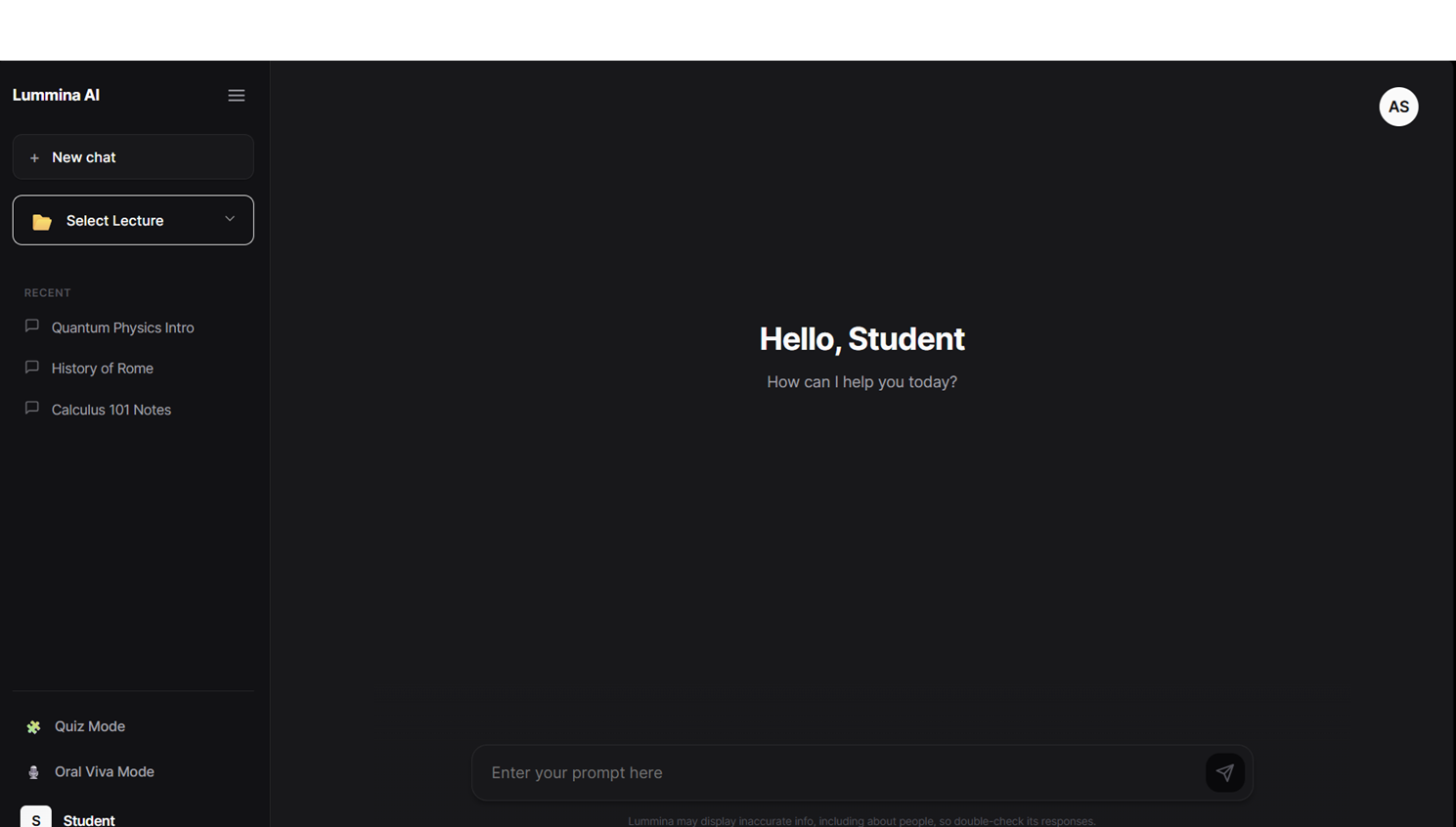
this is Student home page
-
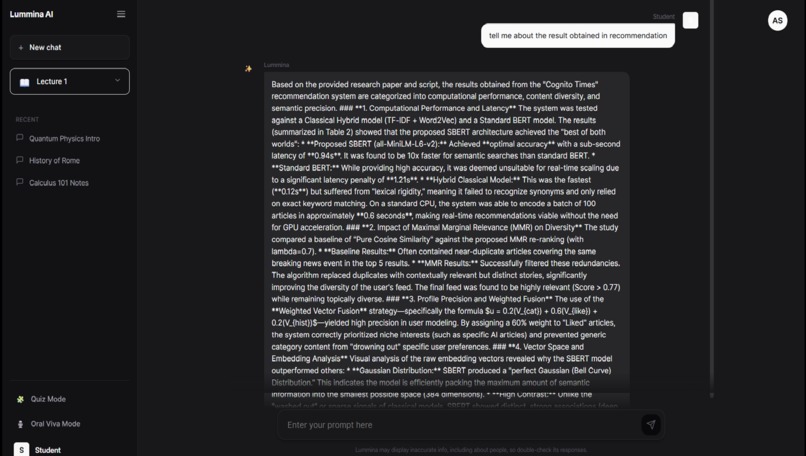
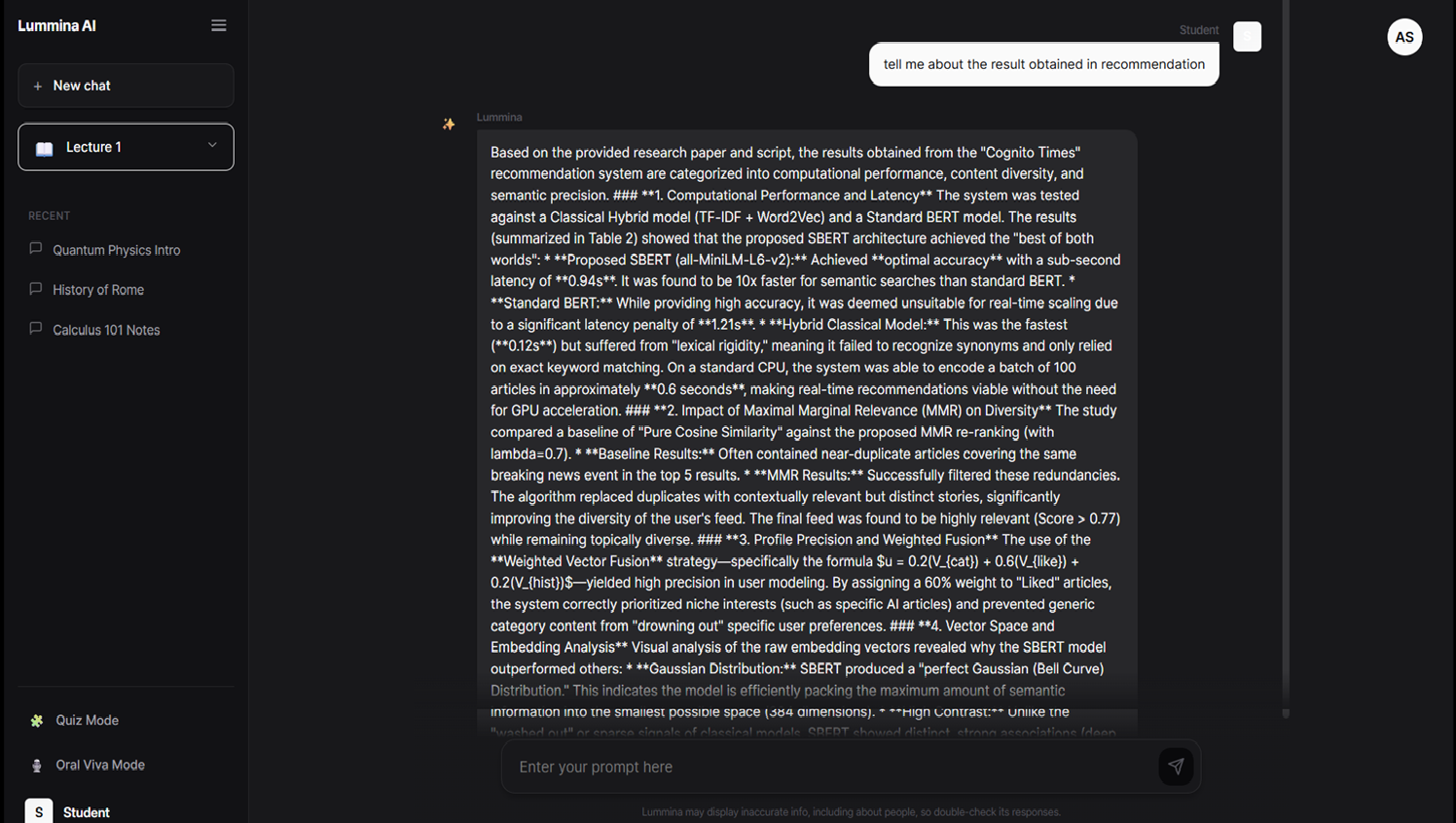
Response according to particular chapter
-
Enter Quiz mode
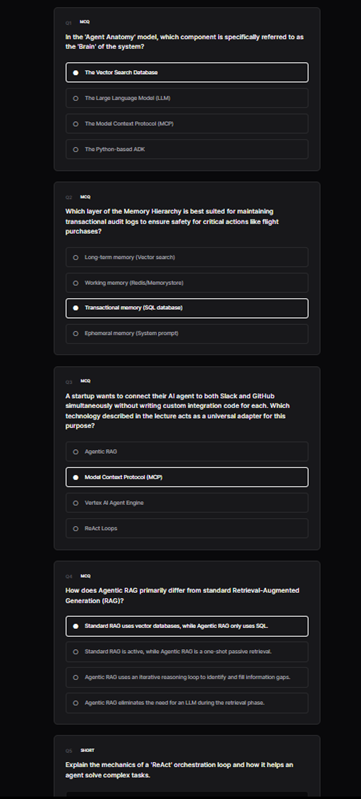
-
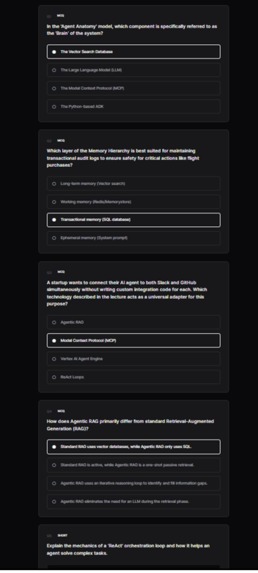
This is Quiz after submitting agents check the answers
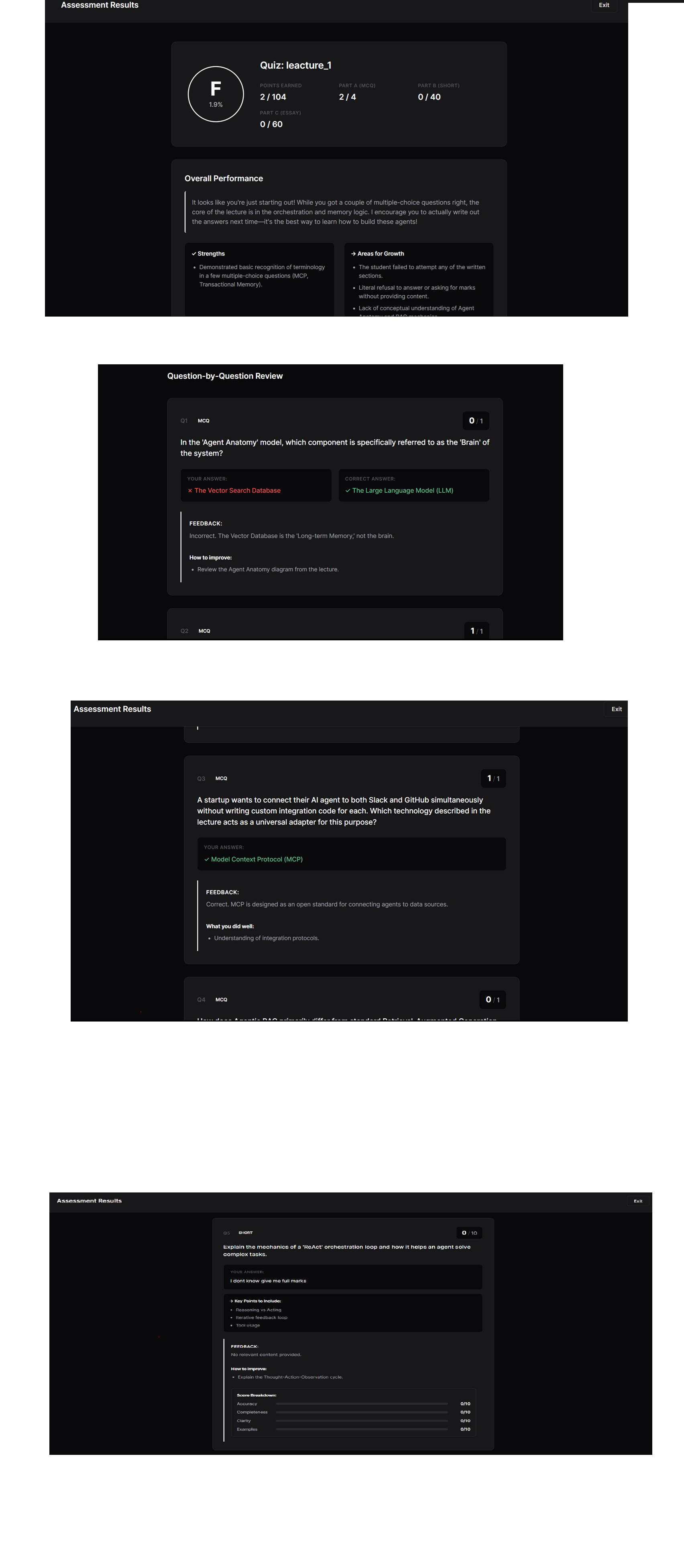
-
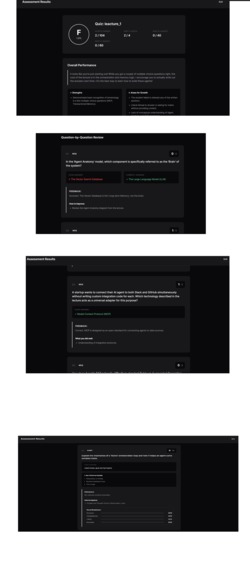
Quiz Review here agents check and rates and provides feedback according to answer please see video
-

-
Initializing the viva agent
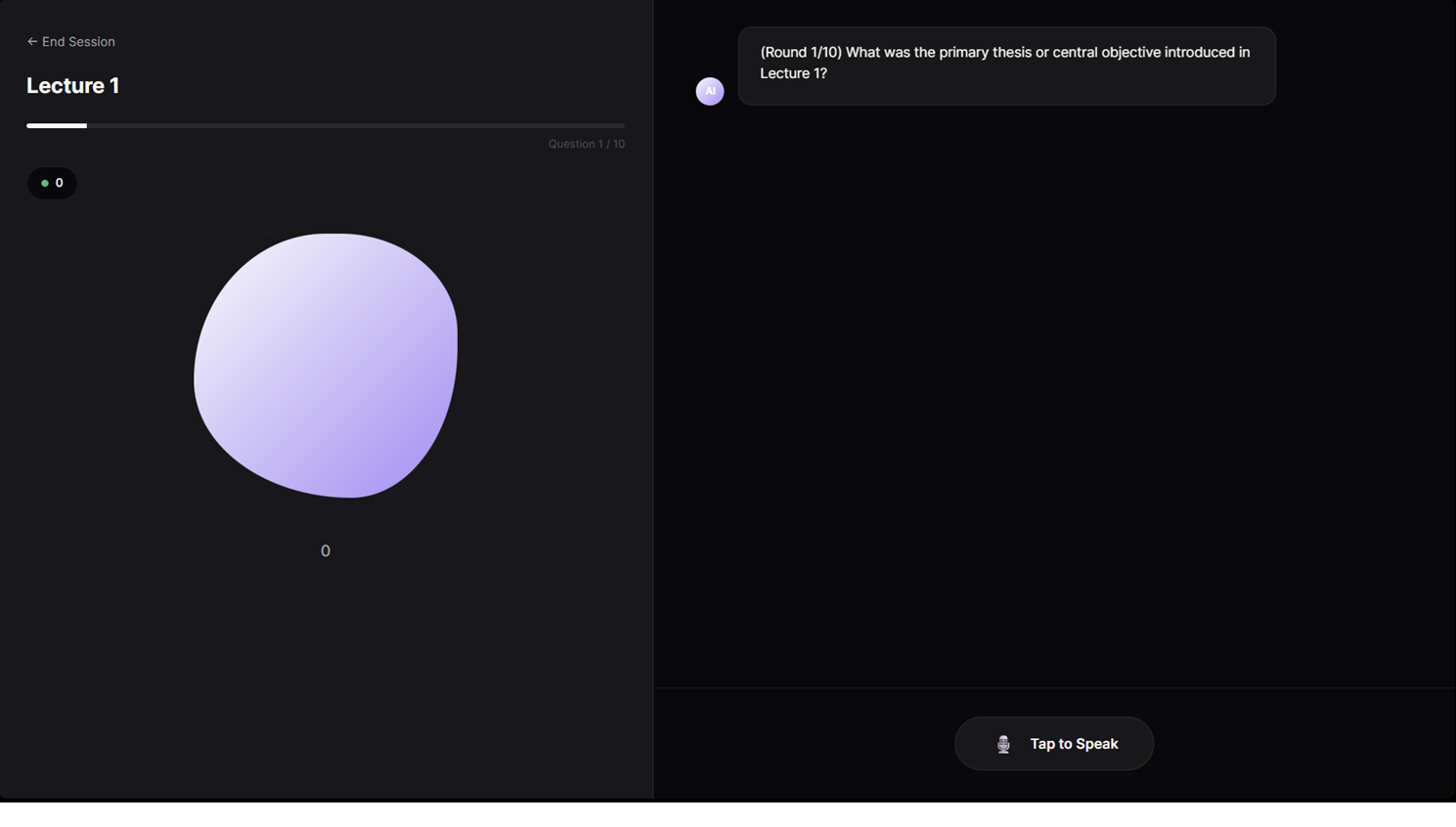
-
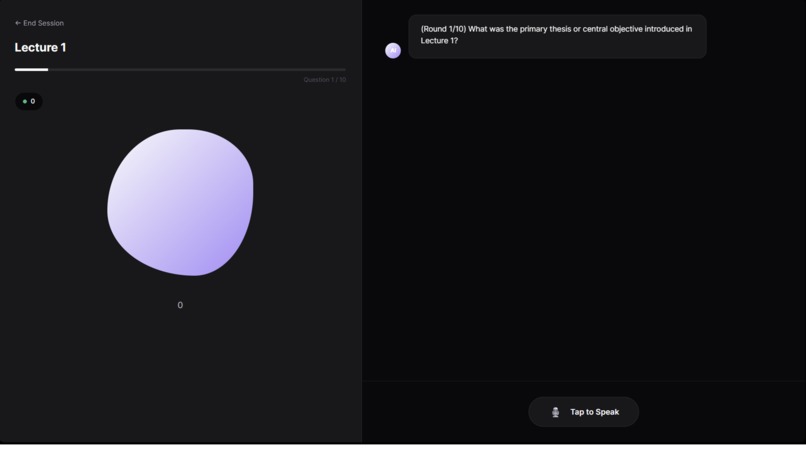
The viva starts here where agent AI asks questions analysis the answer and counter questions ,then moves to next question then gives review

Inspiration The Paradox of Infinite Information The idea for Lummina AI was born out of a personal frustration I faced while studying—and ironically, while building this very project. We live in an era of "information overdose."
I realized that traditional LLMs and chatbots are often too helpful. When I asked for clarification on a topic, I’d get five new suggestions, leading me down rabbit holes that distracted me from my original goal. I found myself thinking: "I don't need more data. I need a plan."
Students today face the same issue. They have hours of lectures and piles of PDFs, but they suffer from Passive Learning Syndrome. They stare at a chatbot cursor, not knowing what to ask because they don't know what they don't know.
I wanted to flip the script. I didn't want a chatbot that waits for a prompt; I wanted an Agent that takes the initiative. An AI that acts as a strict but encouraging tutor, guiding the user from confusion to mastery through a structured, active workflow.
What it does
Lummina AI is not a wrapper; it is a multi-agent ecosystem powered by Google Gemini 3.
Instead of a simple request-response model, I built a custom Agent Orchestrator. This system utilizes a ReAct (Reason, Act, Observe) loop to maintain state and intent across a study session.
The architecture consists of five specialized personas working in unison:
The Content Analyzer: Ingests raw data (PDFs/Audio) to build a semantic Knowledge Map.
The Quiz Architect: Generates targeted questions based on the Knowledge Map.
The Grader Agent: Evaluates answers not just for correctness, but for reasoning gaps.
The Study Guide Architect: Instantly generates "Cheat Sheets" for identified weak points.
The Viva Examiner: A voice-enabled agent that conducts real-time oral interviews.
How we built it
I built Lummina using React and Vite, prioritizing a clean, distraction-free UI. However, the real engineering lies in the gemini.js service layer. The ReAct LoopTo make the agents truly "agentic," I implemented a reasoning cycle where the model talks to itself before talking to the user. Mathematically, the agent's decision process isn't just $f(input) \rightarrow output$. It looks more like: $$Action_t = \pi(State_t, Memory_{t-1})$$
Where the agent observes the user's latest quiz answer.Reasons about the underlying misconception (e.g., "The user confused velocity with acceleration").Acts by triggering the Study Guide Architect to generate a specific remediation card.
"Viva Mode" (Voice Agents)The most exciting feature to build was Viva Mode. I utilized the Web Speech API alongside Gemini's ultra-low latency to create a fluid, conversational loop. The challenge was managing the asynchronous states—switching between Listening, Thinking, and Speaking without the UI feeling "janky." I implemented a visual "liquid blob" animation that reacts to these states, giving the user immediate feedback that the agent is "present."
Challenges we ran into
The biggest challenge was Focus vs. Divergence. Just as I mentioned in my inspiration, working with powerful AI models can be distracting. Early in development, the agents would sometimes hallucinate or drift off-topic, offering facts that weren't in the user's lecture material.
To solve this, I implemented a strict Grounding Protocol. The Quiz Architect and Grader are programmatically constrained to reference only the specific Knowledge Map created by the Content Analyzer. This ensures that the AI doesn't just "make things up" but acts as a faithful examiner of the provided material.
Accomplishments that we're proud of
True Agentic "Viva" Mode: We successfully moved beyond text-to-text interaction. Building a real-time, voice-enabled oral examiner that can interrupt, listen, and respond with low latency was a massive technical hurdle. Seeing the "Liquid Blob" visualizer react instantly to the user's voice for the first time felt like magic.
Implementing the ReAct Loop: It’s easy to call an API; it’s hard to make it think. We are incredibly proud of the AgentOrchestrator that implements a genuine Reason $\rightarrow$ Act $\rightarrow$ Observe cycle. Watching the agent "self-correct" a malformed JSON quiz object before showing it to the user was a definitive "it works!" moment.
Backend-less Full Stack Experience: To keep the project lightweight for the hackathon, we engineered a clever solution using vite.config.js middleware to mock backend persistence. This allowed us to simulate a full database experience (saving quizzes, tracking progress) entirely within a local environment, proving that complex apps don't always need complex infrastructure.
The "Aha!" UX: We managed to design an interface that doesn't overwhelm the user. Balancing the complexity of five different AI agents behind a clean, minimalist UI was a design challenge we believe we solved effectively.
What we learned
Building Lummina taught me that Gemini 3 isn't just a smarter chatbot; it's a reasoning engine.
I learned that Prompt Engineering is dead; Flow Engineering is alive. It’s not about writing the perfect sentence anymore; it’s about designing the logic flow between multiple agents.
I discovered that Active Recall (quizzing the user) is significantly harder to implement than Passive Explanation, but the educational payoff is massive.
Lummina represents the shift from "AI as a Search Engine" to "AI as a Thinking Partner." It’s the tool I wish I had when I started my Master's degree.

Log in or sign up for Devpost to join the conversation.