NOTE TO JUDGES: I fell severely ill during the final hours of this hackathon. The backend is fully deployed to Google Cloud, the WebSockets are live, and the code is fully pushed to GitHub, but I am physically too sick to record a proper voiceover demo video. Please review the GitHub repository and the live code. Thank you for understanding.
Inspiration
Traditional AI agents rely on a clunky, high-latency request/response cycle. You type or speak, wait for the processing spinner, and finally get an answer. With LuminaForge v2, the inspiration was to break that barrier and build an agent that feels truly alive. We wanted an AI that could hold a natural, real-time conversation while actively "seeing" its environment through the user's camera, without the user having to manually hit a "send" button.
What it does
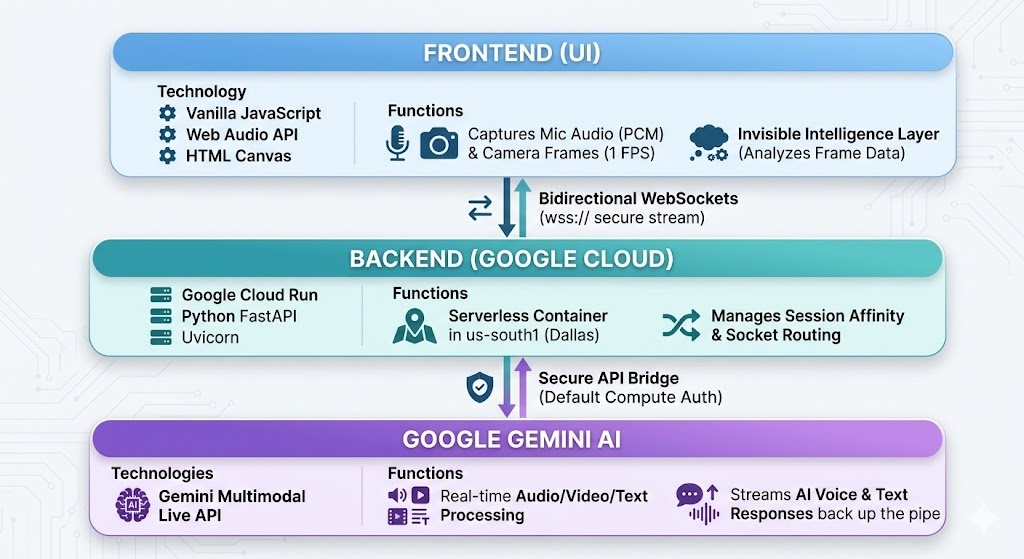
LuminaForge v2 is a full-duplex, multimodal AI assistant. It establishes a continuous, bidirectional WebSocket connection to stream raw PCM audio directly from the user's microphone while simultaneously injecting 1 FPS camera frames into the data stream.
What makes it unique is its "Invisible Intelligence Layer." Before the frontend sends a video frame to the AI, it analyzes the canvas locally for brightness, composition, color, and camera tilt, enriching the payload with metadata so the AI has immediate environmental context without needing to process it from scratch.
How we built it
The architecture is split into a lightweight frontend and a scalable, serverless backend.
The Frontend (The Body)
Built with vanilla JavaScript and the Web Audio API. We utilized AudioWorklet nodes to capture continuous microphone input without blocking the main UI thread. Camera frames are grabbed via an HTML5 <canvas> element, analyzed, and fired down a dedicated video WebSocket lane.
The Backend (The Brain)
We built a Python FastAPI server running on Uvicorn. This server handles the incoming WebSockets and acts as the secure bridge to the Google Gemini Multimodal Live API.
The Infrastructure
To ensure low latency for real-time voice, the backend is containerized and deployed to Google Cloud Run in the Dallas (us-south1) region.
Challenges we ran into
Deploying a continuous-streaming WebSocket application to a serverless environment was a massive headache.
Cloud Run Port Binding: We fought a prolonged battle with Google Cloud Run's strict timeout constraints and port mismatches. Locally, our Uvicorn server ran on port 8000, but Cloud Run expects 8080. The container kept building successfully but crashing instantly upon deployment until we injected a custom Procfile configured with standard ASCII encoding to force the correct Linux bindings.
WebSocket Dropping: Serverless containers spin up and down dynamically. If a user is mid-sentence, shifting them to a new container breaks the audio stream. We had to implement strict
--session-affinityin our GCP deployment to ensure the user's live socket stays locked to a single instance.Module Pathing on Serverless: Packaging the Agent Development Kit (ADK) samples required careful directory restructuring so the Cloud Build context didn't leave critical Python agent files behind on our local disk.
Accomplishments that we're proud of
Successfully moving from a local, hard-coded environment to a fully public, serverless deployment on Google Cloud. Getting bidirectional audio and video streaming perfectly synchronized over WebSockets with zero hardcoded API keys in our GitHub repository (utilizing Google's default compute service accounts instead).
What we learned
We learned the extreme intricacies of the gcloud run deploy command, specifically how to map custom entry points using a Procfile and how to secure real-time WebSocket connections in a serverless architecture. We also learned how to handle binary audio frames versus base64 JSON payloads over sockets.
What's next for LuminaForge v2
The next step is expanding the "Invisible Intelligence Layer" on the frontend to include local object detection via TensorFlow.js before it ever hits the socket, drastically reducing the token overhead sent to the Gemini model.
Built With
- css3
- fastapi
- google-cloud-run
- google-gemini-live-api
- html5
- javascript
- python
- websockets

Log in or sign up for Devpost to join the conversation.