

Inspiration
Prompting generative AI today feels backwards.
Creators are forced to describe visual space camera lenses, lighting angles, shot composition using long, fragile blocks of text or nested JSON. This disconnect makes image generation unintuitive, error-prone, and inaccessible to anyone who actually thinks visually.
LUMINA was inspired by a simple idea: what if directing AI felt like directing a real studio?
Instead of writing prompts, creators should place cameras, move lights, and feel composition while AI handles the translation.
LUMINA exists to prove that AI can reason about space, not just language.
What it does
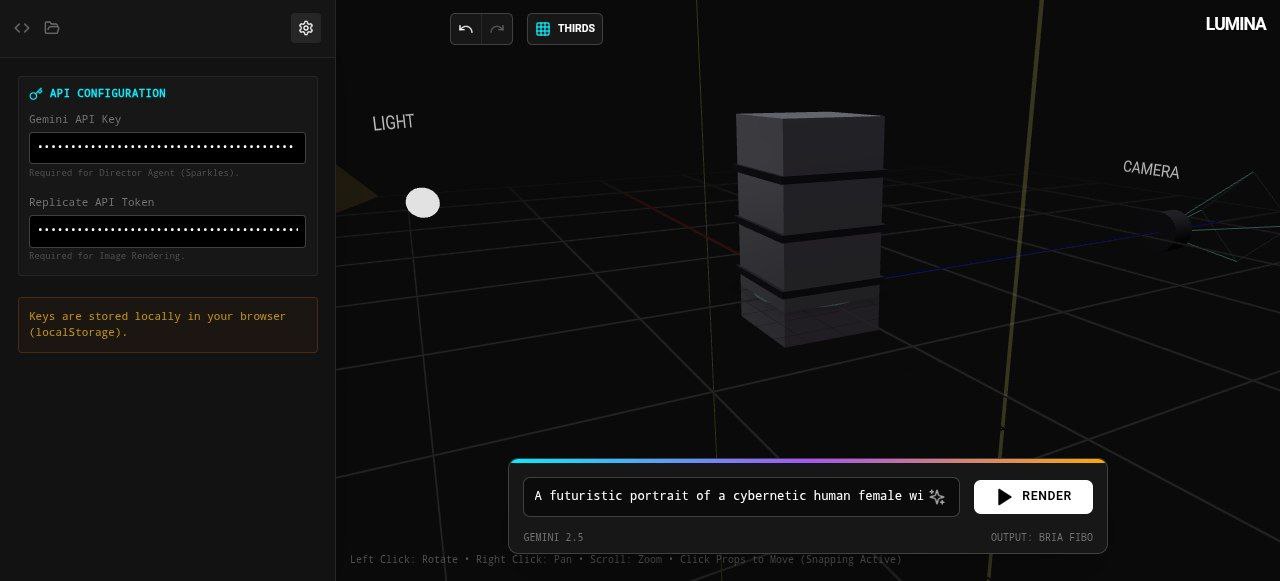
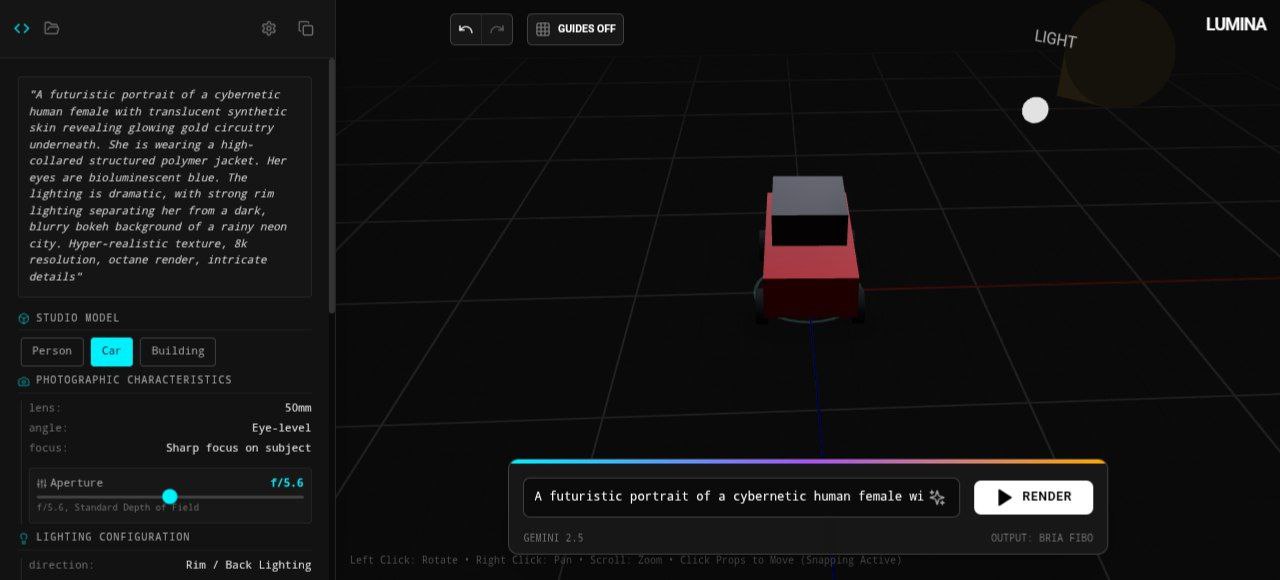
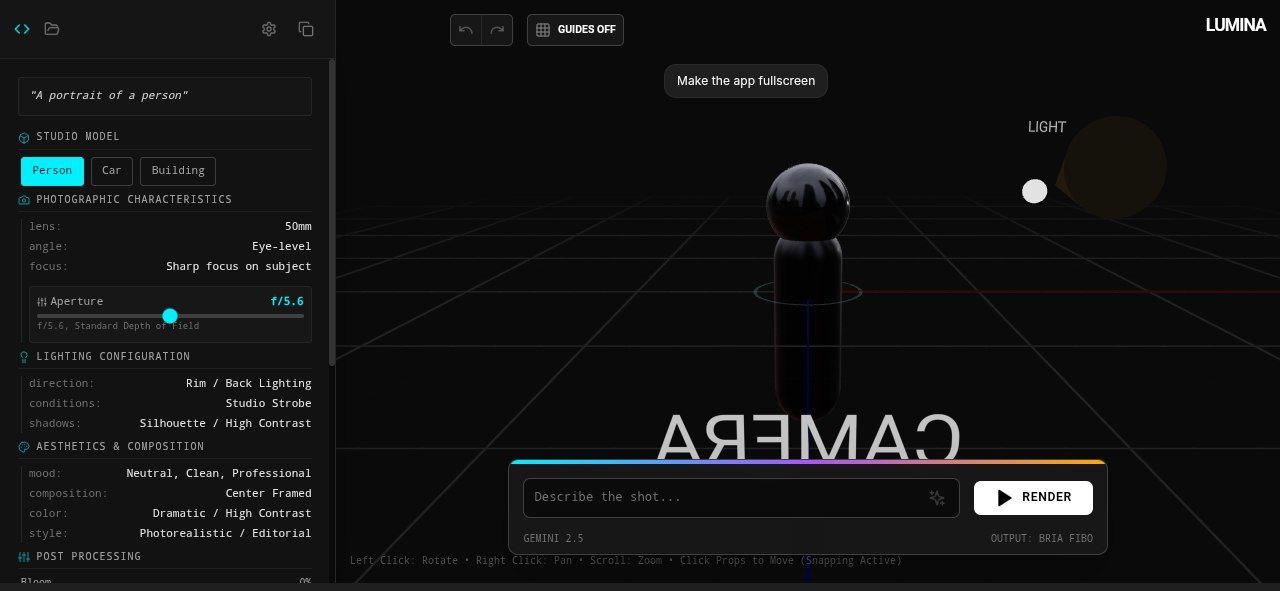
LUMINA is a next-generation Spatial Prompting Studio for the Bria FIBO image model.
Creators control AI image generation by:
- Moving a virtual camera
- Positioning lights in 3D space
- Adjusting height, angle, and distance
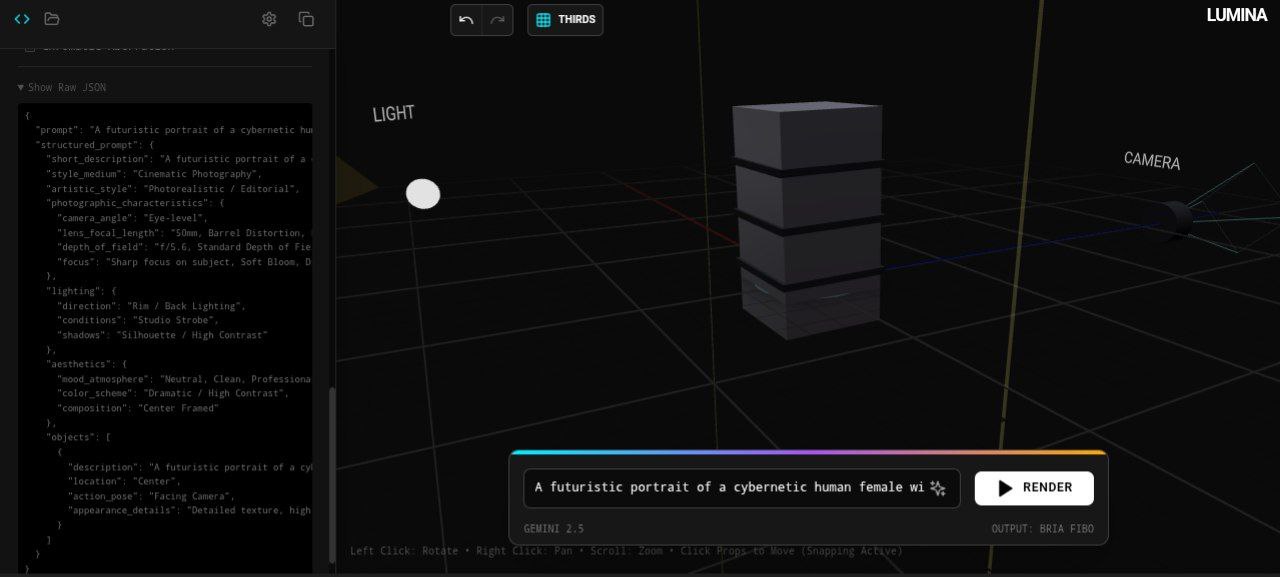
LUMINA converts these spatial decisions into precise, disentangled optical and lighting parameters automatically generating production-ready Bria FIBO JSON in real time.
At the center of the system is a Director Agent, powered by Google Gemini 2.5, which translates high-level creative intent (e.g. “make this feel like a horror film”) into concrete camera and light placements demonstrating true spatial reasoning, not prompt guessing.
In short:
LUMINA turns AI image generation from prompt writing into visual direction.
How we built it
LUMINA is built as a real-time, agent-driven 3D studio:
- Frontend: React 18, TypeScript, Tailwind CSS
- 3D Engine: Three.js with React Three Fiber & Drei
- Animation: Framer Motion for agent-driven motion feedback
- AI Director: Google Gemini (gemini-2.5-flash)
- Image Generation: Bria FIBO via Replicate
- Architecture: Spatial math → parameter mapping → live JSON synthesis
Core Systems
Spatial Math Engine:
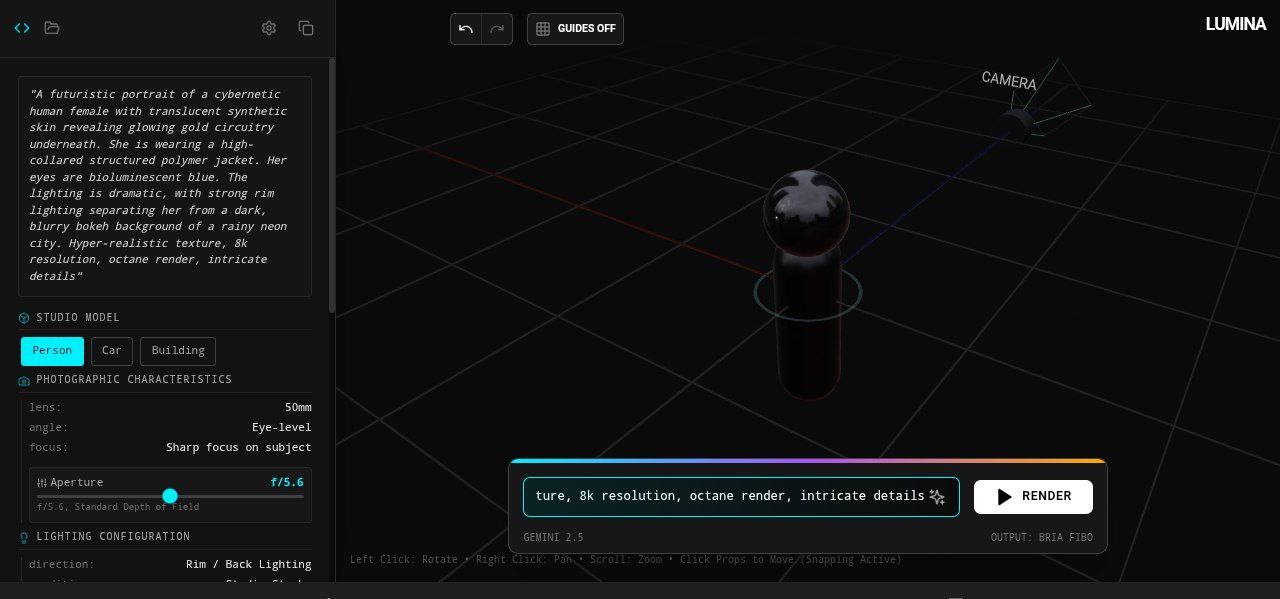
- Camera distance → focal length (18mm–200mm)
- Light angles → Key / Fill / Rim / Butterfly / Uplighting
- Z-axis movement → Low-angle (Hero) or Bird’s-eye shots
- Camera distance → focal length (18mm–200mm)
Studio Canvas (3D):
- Drag-and-drop camera & light props
- Visual FOV cones, shadow direction, and framing guides
- SHIFT + drag for precise vertical control
- Drag-and-drop camera & light props
Gemini Director Agent:
- Converts abstract intent into 3D vectors
- Context-aware scene adjustments
- Animates camera and lights so users *see
- Converts abstract intent into 3D vectors
Built With
- bria
- framer-motion
- google-gemini-api
- next.js-14
- react
- react-three-drei
- react-three-fiber
- replicate-api
- tailwind-css
- three.js
- typescript


Log in or sign up for Devpost to join the conversation.