-
-

Step 1 - overview of uploaded documents and their details
-
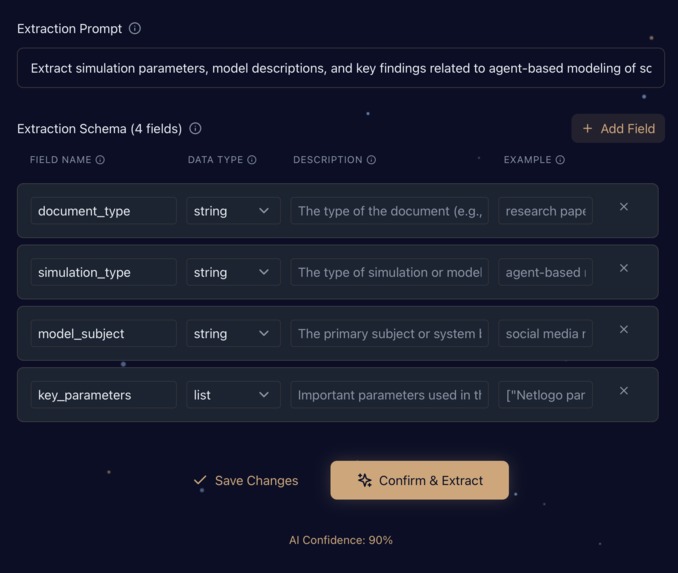
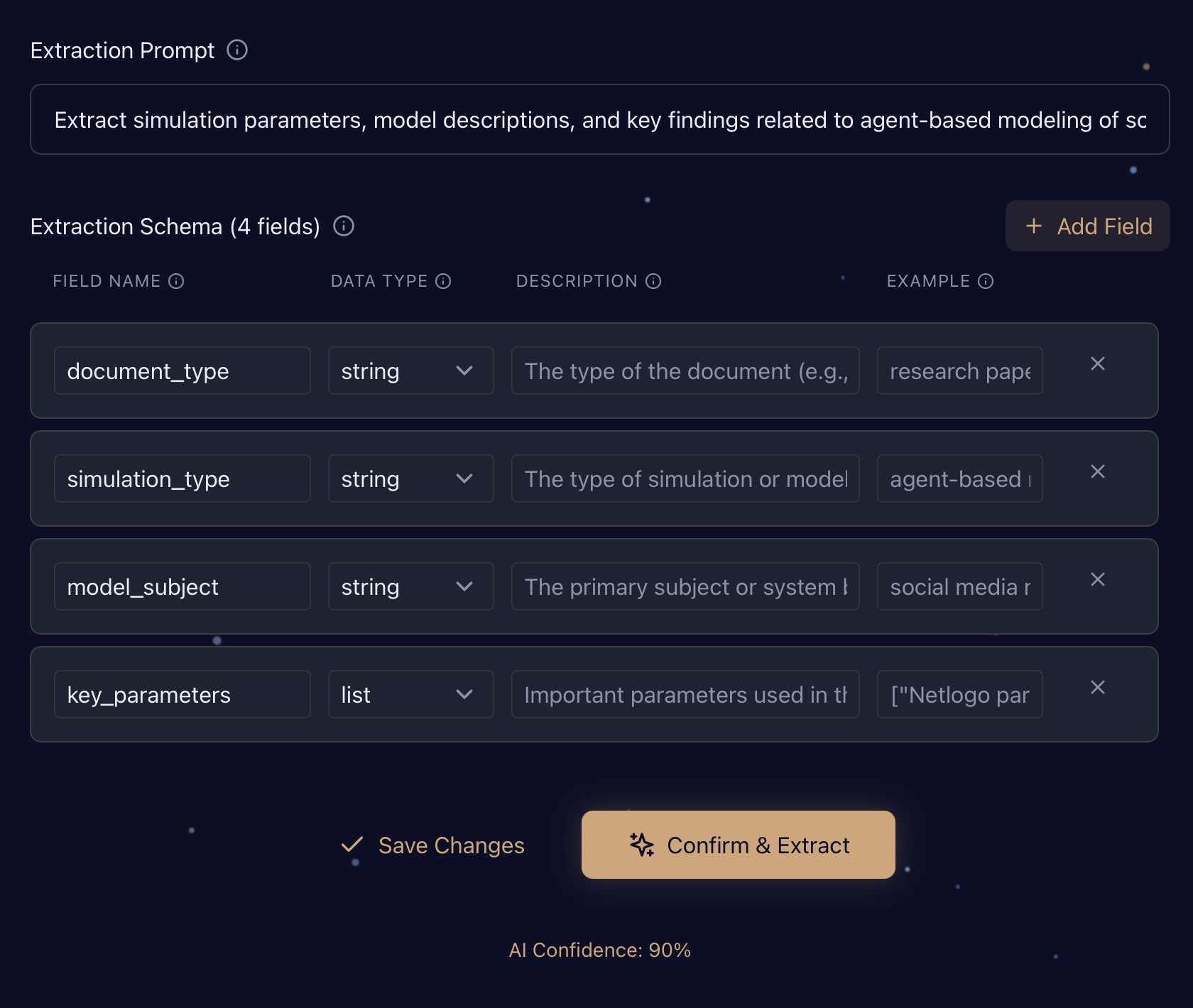
Step 2 - AI-generated extraction prompt and extraction schema (column names and details)
-
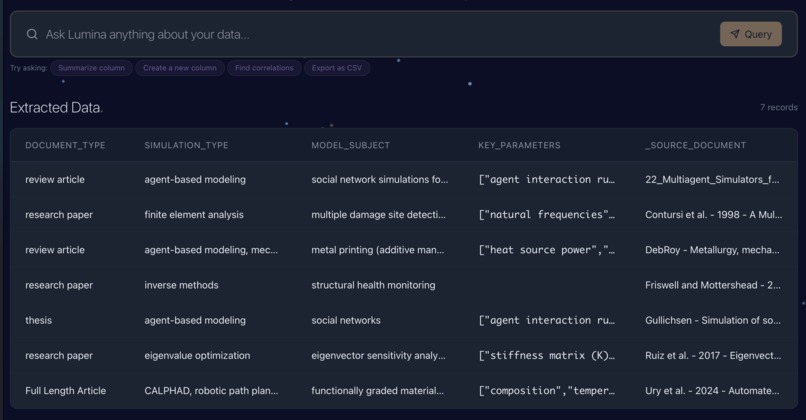
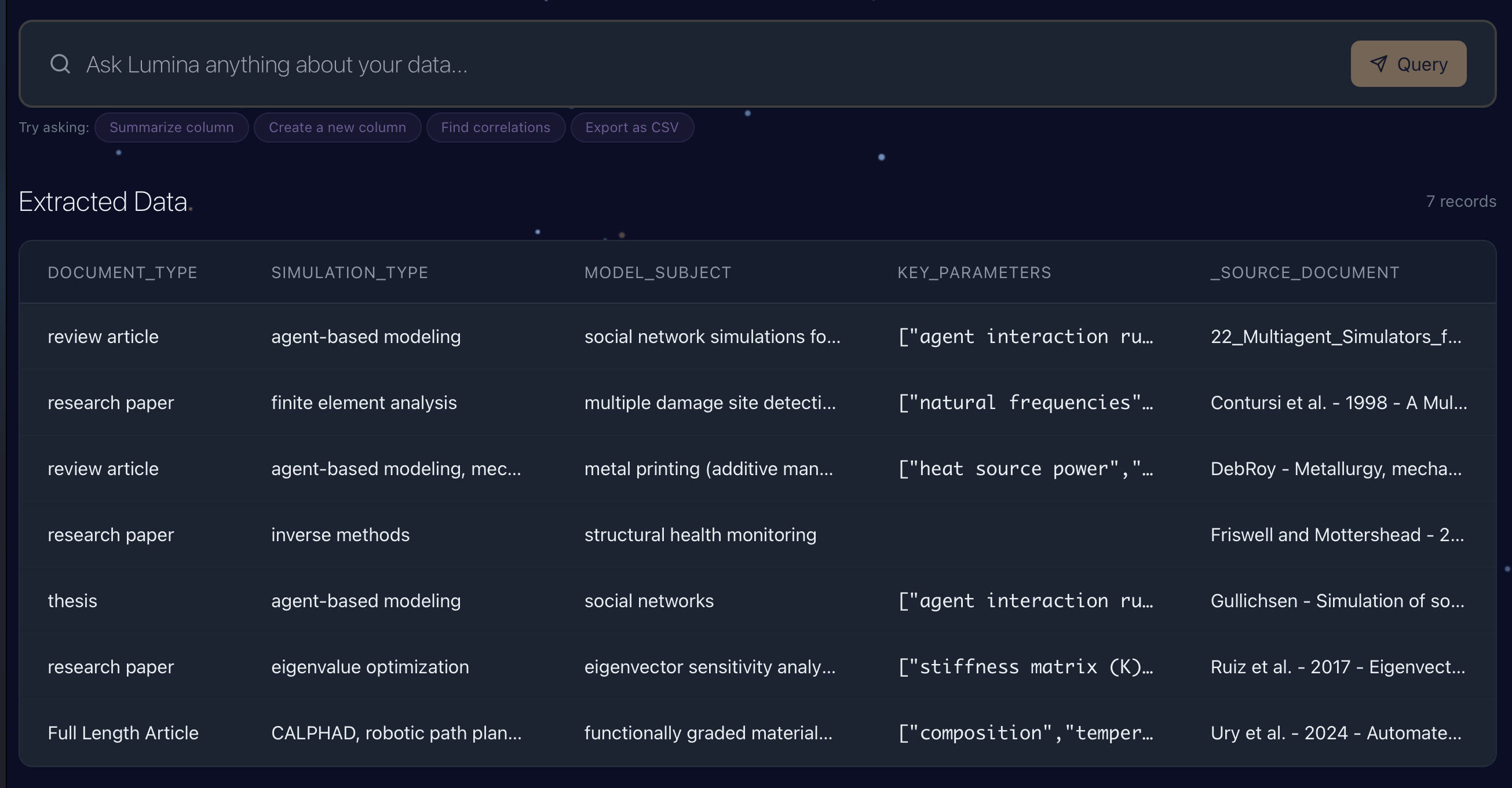
Step 3 - Tabular data extracted from the uploaded documents, ready to be queried and exported

Inspiration
In 2025, AI can generate photorealistic videos and solve competition math, but good luck uploading more than 10 PDFs to analyze. We built Lumina so you can process and analyze your documents in mass faster than ever before.
tldr; Lumina transforms weeks of manual document analysis into minutes of intelligent conversation. Upload 100 research papers, ask 'What methodologies were used?', and get a structured database instantly—then query it conversationally to uncover insights hidden across your entire corpus.
Even in 2025, most professionals across different fields such as research, finance, healthcare, law, and engineering are still required to manually sift through overwhelming volumes of structured (spreadsheets, databases) and unstructured data (reports, PDFs, emails, transcripts). Extracting meaningful insights from these sources is labor-intensive, mentally exhausting, and highly prone to human error. The financial impact of this inefficiency is staggering; manual data tasks cost U.S. companies $28,500 per employee annually, and poor data quality from these errors costs the average business $15 million per year.
This traditional workflow not only wastes valuable time and cognitive effort but also delays critical decision-making, slows innovation, and limits people’s ability to focus on high-level thinking and creativity. Even after information has been extracted, users often struggle to relocate a specific insight they once encountered but can no longer trace back to its source. As data continues to grow exponentially, the gap between available information and accessible, actionable knowledge is becoming wider than ever.
What if this process could be automated, intelligent, and effortless? By reimagining the way humans interact with data, we aim to eliminate repetitive manual tasks, reduce errors, and accelerate discovery, which empowers small businesses and teams to spend more time solving complex problems rather than searching for information.
What it does
Here is an example Workflow:
- Upload 50 clinical trial PDFs
- Ask: "Create a database with trial phase, participant count, and adverse events."
- Lumina creates a structured table matching your request (e.g., trial_phase, participant_count, adverse_events as columns), orchestrates parallel extraction across documents, and validates those responses with your criteria (Gemini, PyDantic)
- Query conversationally: Ask "Which Phase III trials had cardiovascular events?" and get instant results with source citations and original text (Llama 3.1 Nemotron 8B v1, Nim Retriever and Reranker)
- Iterate dynamically: Ask "What were the dropout rates?" and Lumina's router agent automatically detects this requires a new column, extracts the data, and updates your database and it's all in one conversation
- Further discover connections in your response by asking it to generate a knowledge graph (LangChain, LLMGraphTransformer, Llama3.1-Nemotron 8B)
- Export and share your database in CSV format
Lumina transforms a static folder of documents into a dynamic, intelligent knowledge base, enabling users to synthesize information, identify connections, and uncover new insights with remarkable speed and accuracy.
How we built it
Architecture: Full-stack system with React frontend, async FastAPI backend, and 7-agent orchestration via OpenAI Agents SDK.
AI Pipeline:
- NVIDIA NIMs for GPU-accelerated embedding (llama-3.2-nv-retriever-300m), reranking (nemoretriever-reranker-500m), and generation (llama3.1-nemotron-8b-v1)
- Hybrid RAG: FAISS vector search + SQLAlchemy structured storage
- Custom NIMWrapper to add structured output support to OpenAI Agents SDK for the deployed NIM models
Infrastructure: Models deployed on AWS EKS (g6e.xlarge), backend on EC2 (scalable from t3.micro), with complete reproducibility. Use the ./manage-lumina.sh script, which provides a guided TUI (terminal user interface) for deployment, configuration, and service management. Full documentation available in the repo.
Key Innovation:
- Multi-agent validation loop: after schema generation, specialized agents verify Pydantic code validity, test extraction accuracy, and self-correct errors before the user sees results.
- Parallel agent spawning with request throttling: Each document gets its own agent, eliminating the file count bottlenecks that limit available tools
Challenges we ran into
Resource Optimization: We wanted to test Lumina extensively, and we didn't have the budget to run the models 24/7 on the cloud. So we decided to quantize the Nemotron 8B model (fp4) to run on Apple Silicon with only 4.5GB VRAM footprint while maintaining inference quality. We also shared the quantized model on HuggingFace for others to use.
Using NIM-based models with our agentic framework: OpenAI Agents SDK does not support (yet) NVIDIA NIMs' structured output formatting. Specifically, how we should pass the structured format arguments to the model. So, we built custom NIMWrapper abstractions that bridge both frameworks while preserving full agent capabilities and structured data guarantees.
Real-Time Async Architecture: We built a WebSocket-based pipeline to provide users with live progress updates throughout the entire process (schema design → extraction → validation → query), no blocking UI or degrading performance under load.
Accomplishments that we're proud of
Enterprise-Grade Multi-Document Analysis: Built parallel agent orchestration that processes documents concurrently (tested: 8 documents in <60 seconds) with intelligent throttling to prevent API overload. Unlike consumer AI tools limited to 5-10 files, our architecture scales to 10+ documents by spawning dedicated agents per document.
Self-Validating Extraction Pipeline: We wanted to extract any information in any format from any type of document. So we couldn't limit our PyDantic structure to be a template; instead, the LLM generates it on the fly based on the user's request. So we gave our agent the tools needed to run validation loops to catch schema errors and correct them, so 19 out of 20 times (95%) the agent gets it right.
What we learned
Advanced Agentic AI Implementation and Patterns: We gained extensive experience developing agentic frameworks with the OpenAI Agents SDK, including how to set up an agent to use tools, designing the decision-making logic, and implementing sequential, multi-step AI workflows. We also learned how to deploy and work with NIM and AWS EKS platforms, including setting up a Docker container and running it on the cloud.
AI Self-Correction and Validation: A key learning was developing a robust validation loop for our models, which is essential for ensuring the reliability and accuracy of AI-generated structured data. The agent has full control over generating the Pydantic model, which generates the structured data. However, this freedom comes with challenges regarding whether the Pydantic code is fully functional or not. In the background, once our agent generates a Pydantic schema, it then uses several validation tools to ensure its code is valid.
Asynchronous Systems Architecture: We learned how to design and manage asynchronous request handling, a vital skill for building responsive and scalable applications that can process multiple documents and agent tasks in parallel. We additionally implemented a WebSocket communication method connecting the frontend and backend, informing the user about every step of the data extraction process in real-time.
What's next for Lumina
Immediate Roadmap:
- Persistent PostgreSQL backend for saved knowledge bases
- User authentication and workspace management
- Neo4j knowledge graph integration for cross-document insight discovery
- Collaborative features: shared workspaces, report exports, database merging
Vision: Democratize enterprise-grade document intelligence for small teams and researchers who can't afford $50K/year tools like Palantir and Primer.ai
Built With
- amazon-eks
- amazon-web-services
- gemini
- llama
- nvidia
- nvidia-nim
- python

Log in or sign up for Devpost to join the conversation.