Inspiration
Security today has a paradox: the organizations most vulnerable to attacks are often the least able to afford continuous, high-quality penetration testing. A single engagement can cost $15,000–$40,000 and still requires weeks of specialist effort across reconnaissance, tool orchestration, evidence triage, exploit-path reasoning, and reporting.
In practice, this means many teams ship code that has never undergone rigorous offensive validation.
That gap became our thesis.
We asked a hard question:
Can an LLM-orchestrated agentic system deliver meaningful, end-to-end penetration testing workflows without a human analyst driving every command?
Not a single-tool wrapper. Not a chatbot with security-themed prompts.
A real pipeline that can:
- inspect a target,
- determine an execution strategy,
- run industry-standard offensive tools,
- distinguish signal from scanner noise,
- infer causal exploit pathways, and
- produce a professional report suitable for engineering action.
We added one non-negotiable design constraint: privacy-first local inference.
When you scan a target, you are effectively mapping its attack surface. That context should not be involuntarily exfiltrated to a third-party cloud model endpoint.
So Lumina defaults to Ollama + llama3.1:8b, giving us local model execution and strong control over data flow.
The goal is simple and urgent: help teams remediate weaknesses before they become headlines.
What it does
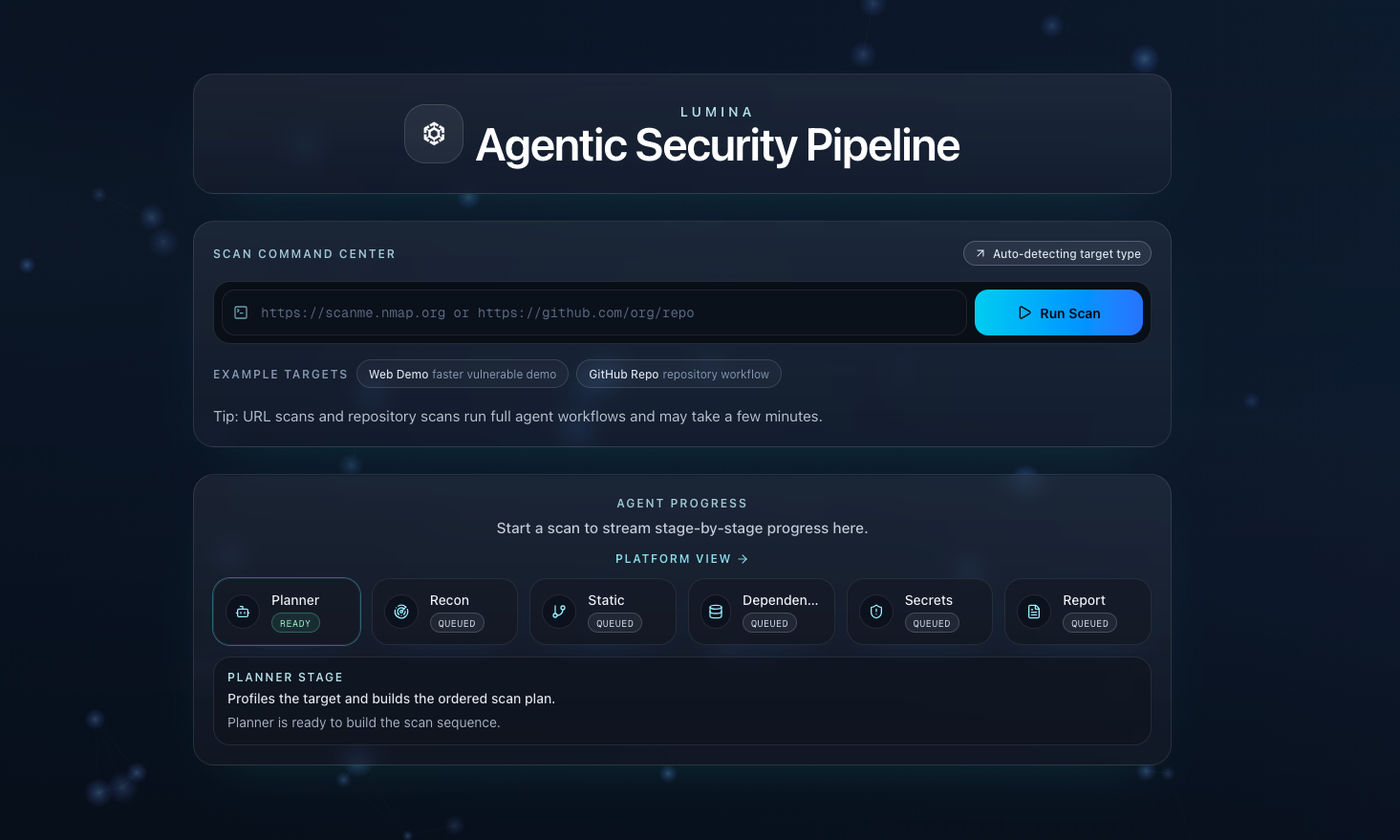
Lumina accepts either:
- a web URL, or
- a GitHub repository target (and supports mounted local repo paths in backend mode)
and executes a full penetration-testing pipeline from planning to report generation.
End-to-end flow
Dynamic planning
- For repos, Lumina builds a structural fingerprint (file tree signals, extensions, dependency manifests).
- For URLs, it performs a pre-scan fingerprint (
httpx + whatweb) before selecting appropriate web stages. - If URL signal is weak/uncertain, conservative guardrails keep a baseline of recon + SQLi + XSS to avoid under-testing.
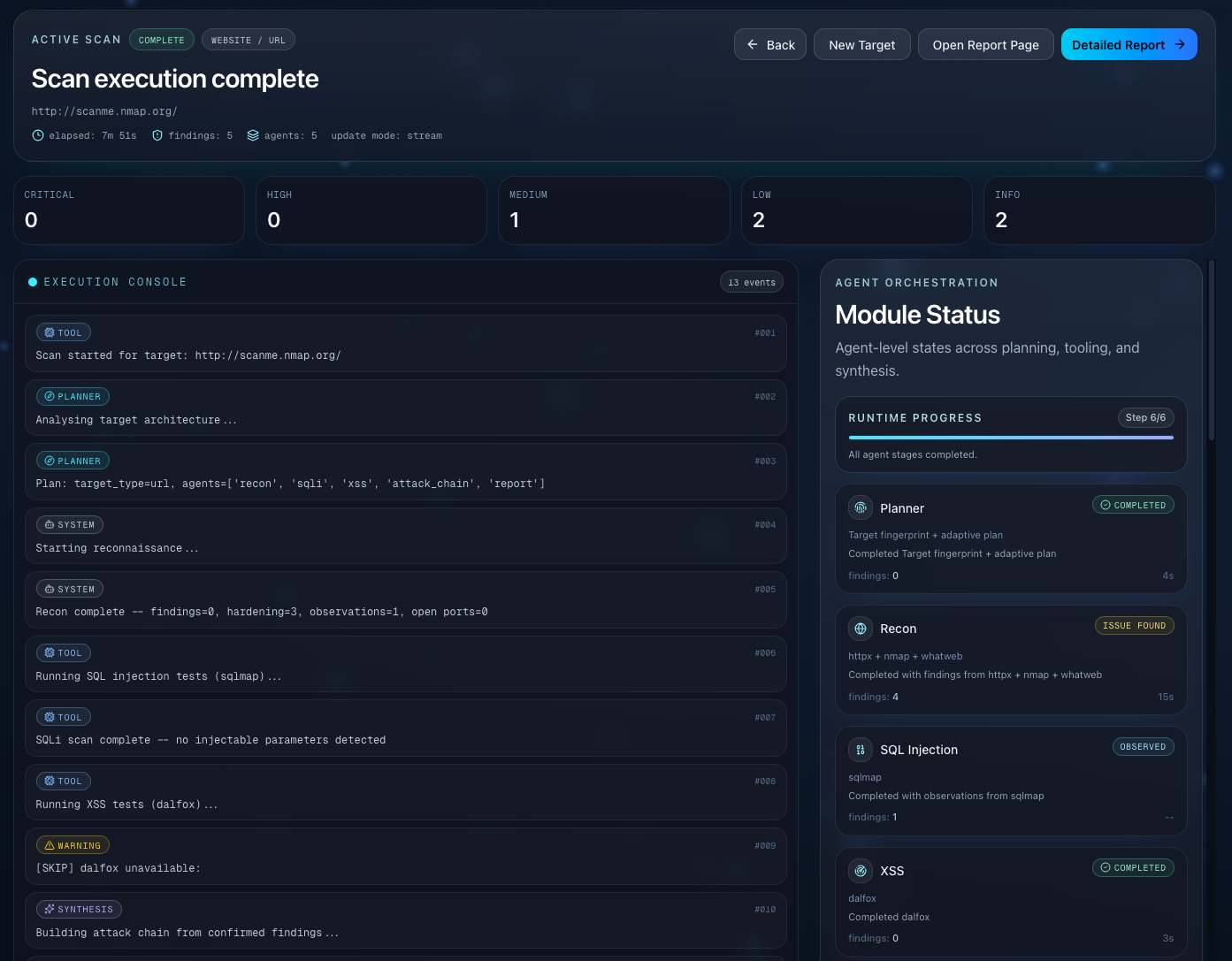
Agent-driven execution
- Security stages run their toolsets.
- If tools produce no meaningful output, LLM interpretation is gated.
- Operational errors (timeouts, missing binaries, connectivity failures) are logged as operational telemetry, not promoted as vulnerabilities.
Live reasoning + progress streaming
- Planner/interpreter/attack-chain/report tokens stream live to the UI via SSE.
- Users see stage-level execution state in real time (queued/running/complete/issue).
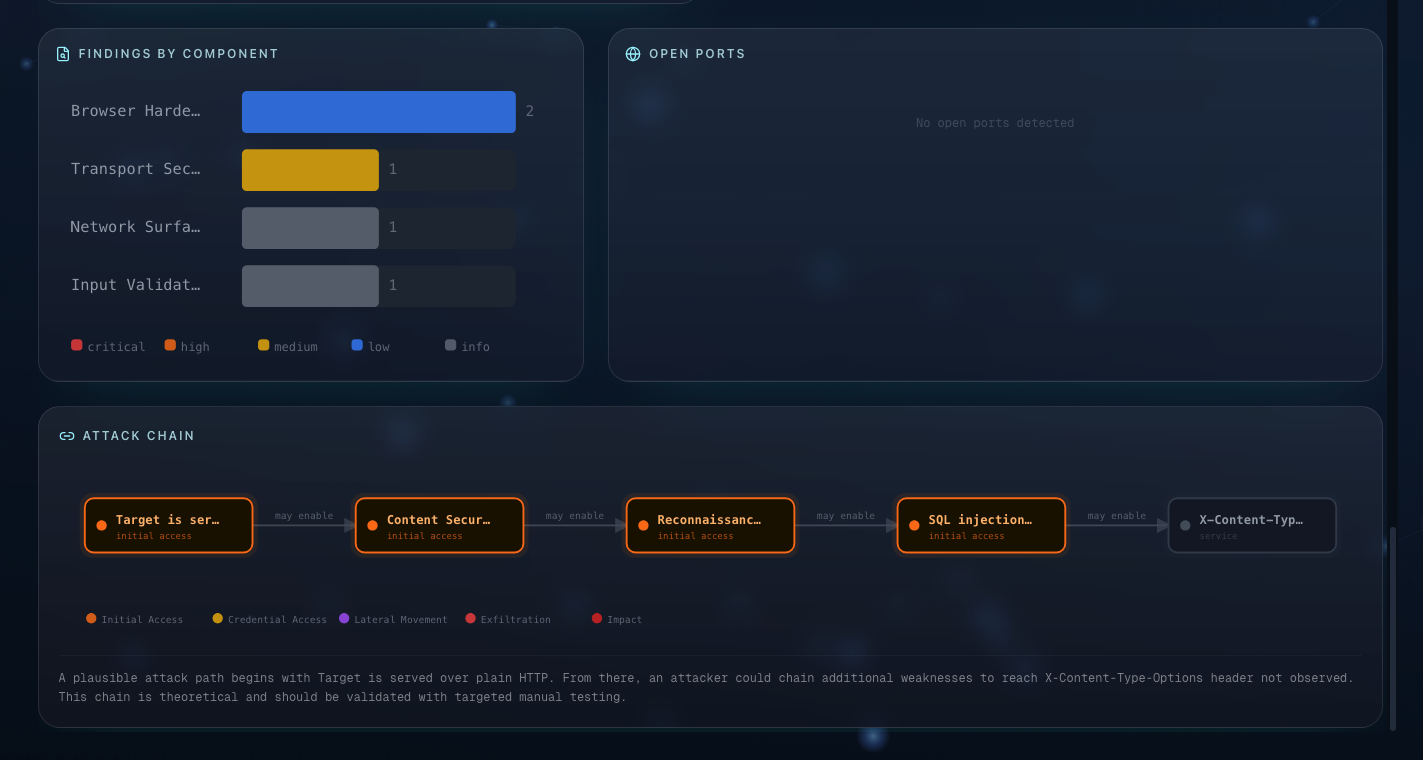
Attack-chain synthesis
- A dedicated stage reasons over the complete finding set.
- Produces a causal exploit chain aligned to MITRE ATT&CK semantics with structured nodes, edges, justifications, and Mermaid output.
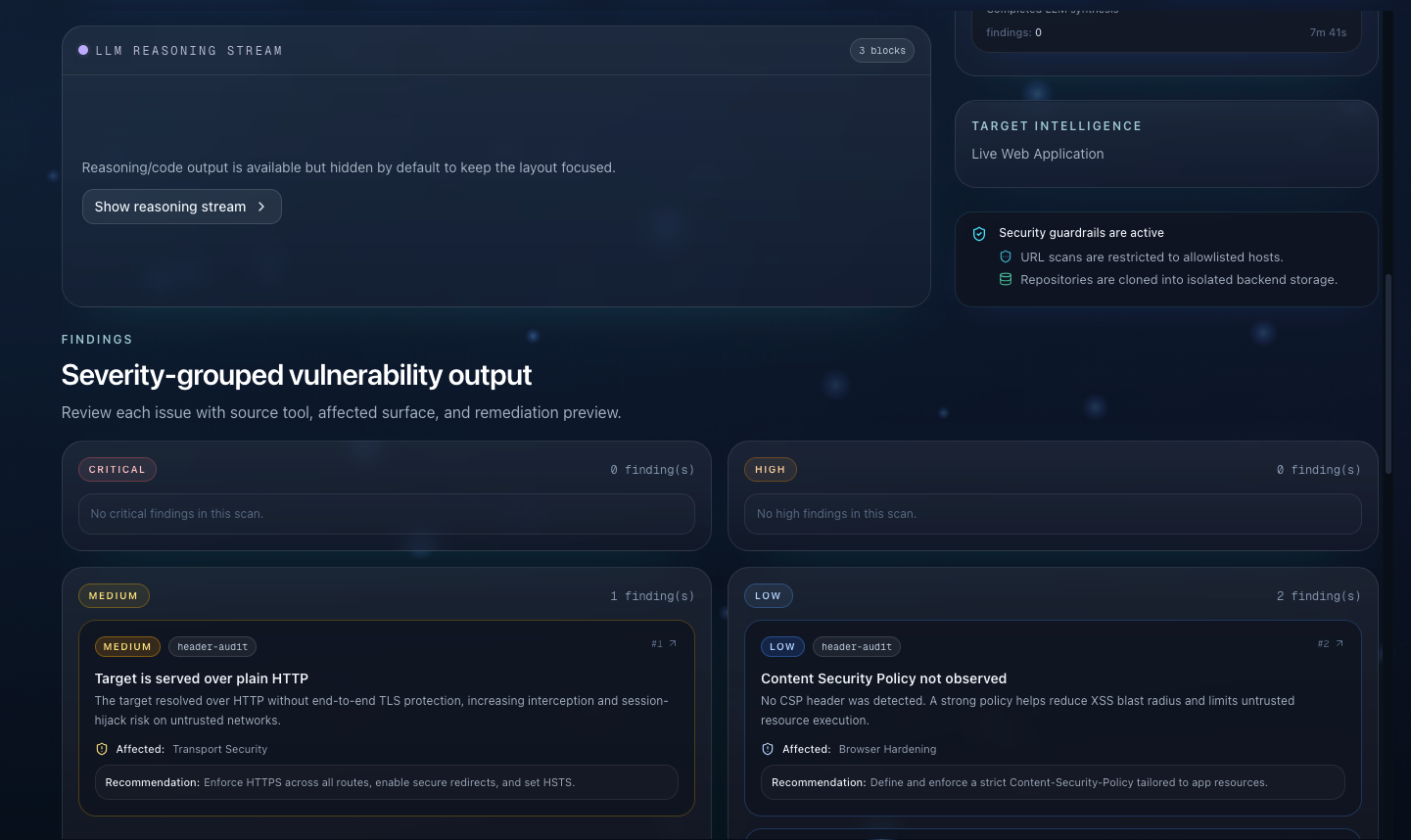
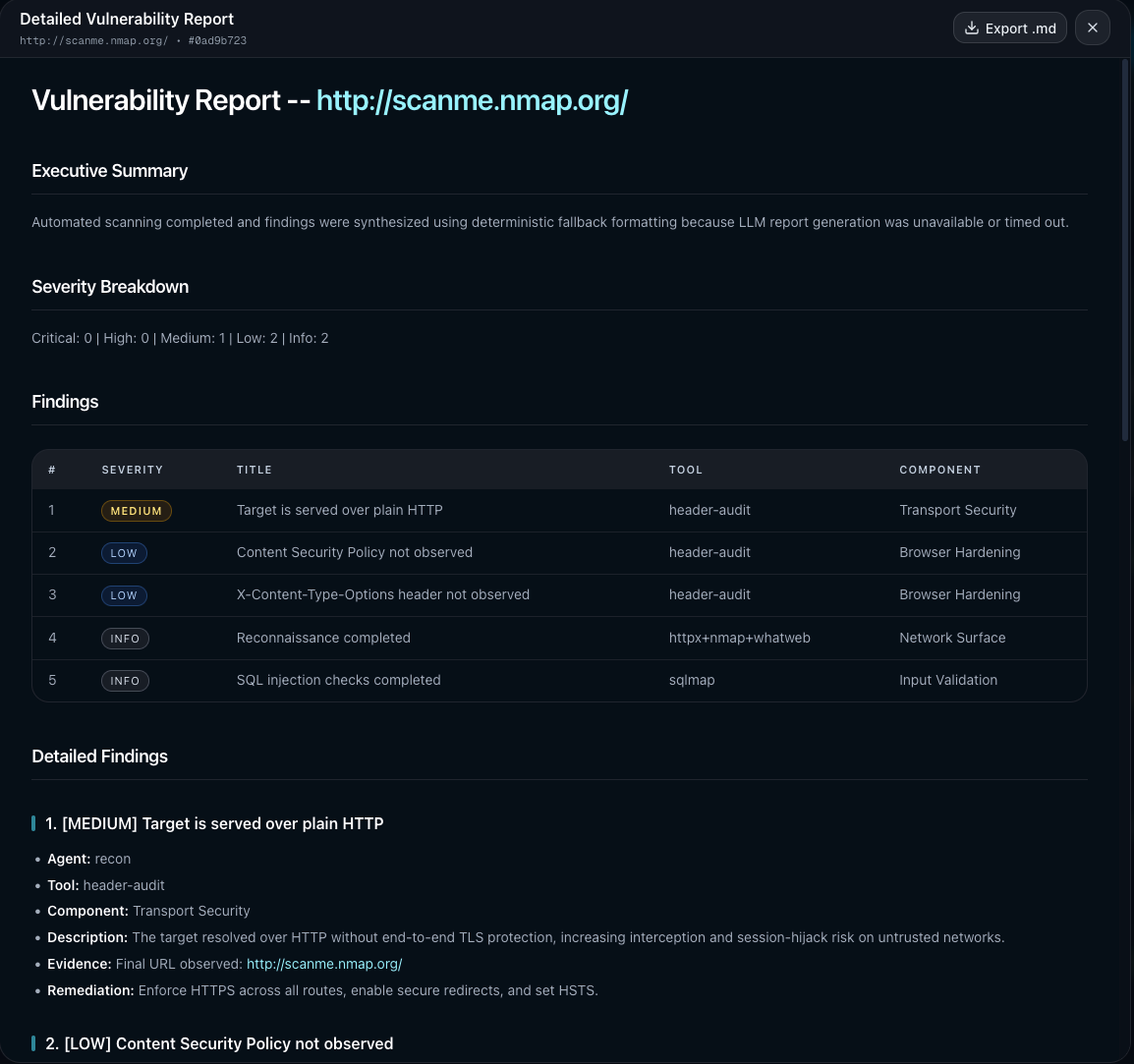
Structured report generation
- Final report includes executive summary, severity distribution, findings table, detailed evidence/remediation sections, attack-chain narrative, and risk score out of 10.
- Deterministic fallback reporting ensures useful output even when LLM synthesis is delayed or malformed.
Features
- LangGraph state-machine orchestration with deterministic stage routing
- Dynamic agent selection for URL and repository targets
- Real-time LLM token streaming through SSE
- MITRE ATT&CK-inspired exploit-chain graph construction
- Live pipeline visualization with per-agent status transitions
- Severity-grouped findings with evidence drill-down
- Findings-by-component visualization and attack-chain UI
- Exportable Markdown vulnerability report
- Swappable LLM backend architecture (default local Ollama; OpenAI-compatible supported)
- Dockerized backend execution for reproducible tool runtime
- OWASP Juice Shop-compatible workflow for demo/testing scenarios
- Dual target model (web + repo) with differentiated planning logic
- Evidence drawer with raw, untruncated context for analyst transparency
- Port-map visual layer for reconnaissance output interpretation
- Reliability guardrails for malformed JSON, parser failures, and tool noise suppression
- Repo scan ETA guidance in UI to set user expectations (e.g., 5–7 min full scan)
Tools our agents use
Reconnaissance
- httpx: endpoint probing (status, title, redirect behavior, technology hints)
- nmap: service + port discovery with version context
- whatweb: server/framework/CMS fingerprinting
SQL Injection
- sqlmap for validated injection probing and exploitability checks
XSS
- dalfox for reflected/payload-driven XSS testing against discovered input surfaces
Static analysis
- semgrep for broad source-level security rules
- bandit for Python-specific security linting
- cppcheck for C/C++ memory safety and undefined behavior signals
Dependency auditing
- pip-audit for Python package CVE detection
- npm audit for Node advisory surface
Secrets scanning
- trufflehog and detect-secrets for credential and entropy-pattern detection
Attack-chain synthesis
- LLM stage builds causal exploit graph from confirmed findings with explicit edge justification logic
Report generation
- LLM + deterministic fallback synthesis into structured, exportable Markdown
Core principle: the LLM interprets and synthesizes, but foundational evidence is produced by established offensive/security tooling.
How we built it
Lumina is composed of a Python backend and a Next.js frontend, connected by FastAPI REST + SSE interfaces.
Orchestration layer (LangGraph)
At the core is a compiled StateGraph using shared GraphState to accumulate:
- target context,
- planner output,
- findings,
- attack chain, and
- final report.
Routing is deterministic and governed by planner output (agents_plan) with conditional transitions, improving auditability and reproducibility.
Planner system
- Repo planning: file-system walk (bounded), extension/dependency signal extraction, schema-constrained planner prompt, JSON validation + repair pass + safe fallback.
- URL planning: pre-scan signal acquisition (
httpx,whatweb), adaptive stage selection, conservative guardrails when confidence is low.
Tool layer
Each tool is wrapped as a typed execution function with normalized output contracts.
Nodes invoke _has_real_output() gates before interpretation to prevent operational failure text from becoming false positives.
Interpretation + report pipeline
_llm_interpret()parses structured findings from tool output.- JSON recovery path handles markdown fences and malformed planner/interpreter output.
- Deterministic structured fallback derives findings from tool-native output when LLM parse fails.
- Report layer includes both model-generated and deterministic fallback modes for resilience.
Streaming architecture
LangChain callback streams token events, appended into scan state with agent delimiters.
Frontend consumes SSE, reconstructs agent blocks, and renders live reasoning/progress without requiring refreshes.
Frontend stack
- Next.js App Router
- Tailwind + componentized glassmorphism UI
- Motion-enhanced runtime visuals
- ReactMarkdown + GFM for report rendering
- Interactive charts/graph views for findings and attack chain context
Challenges we ran into
LLM JSON reliability under local-model constraints
Small local models can drift from strict schema output.
We introduced layered recovery: fence stripping, brace-depth extraction, repair prompt, deterministic fallback.Noise vs signal in security tooling
Security binaries emit abundant non-finding noise (stderr warnings, environment errors, timeout artifacts).
We enforced output gating and interpretation constraints to minimize false positives.State accumulation correctness
Multi-stage findings had to append safely without overwrite regressions.
We standardized additive update patterns across nodes.Container/runtime path ergonomics
Repo scans execute in backend runtime paths, which initially leaked into report UX.
We added display-target mapping so reports reflect user-facing source targets.Streaming robustness
Long-running scans require resilient stream behavior.
We implemented reliable stream/polling continuity patterns and status persistence handling.Latency perception
Even correct scans feel “broken” without expectation-setting.
We added explicit guidance (URL faster, repo full scan typically 5–7 min) to reduce confusion and improve trust.
Accomplishments we’re proud of
- Delivered a genuinely agentic penetration-testing workflow rather than a single-tool façade
- Built privacy-forward local inference defaults suitable for sensitive scan contexts
- Implemented robust fallback layers so users still receive actionable artifacts under degraded LLM conditions
- Added exploit-chain reasoning with causal edge constraints
- Shipped a polished, high-clarity execution UX with live token-level transparency
- Improved report fidelity and reliability for demo and judging environments
What we learned
- Grounding is non-optional: architecture and severity interpretation degrade without explicit evidence constraints.
- Defensive engineering is the real multiplier: parser resilience, error classification, and fallback design determine reliability more than prompt cleverness.
- Agentic ≠ autonomous magic: deterministic routing plus constrained model responsibilities produce better trust and reproducibility.
- UX trust matters as much as model quality: visible progress, ETA cues, and structured evidence improve perceived and actual system quality.
What’s next for Lumina
- Parallelize independent scan stages to reduce total runtime
- Add authenticated scan support (session/header injection)
- Persist scan history for trend analysis and regression diffing
- Add CVE enrichment (CVSS + advisory correlation)
- Introduce CI/CD hooks for pre-merge security gating
- Expand post-chain iterative probing for high-priority findings
Stack
| Layer | Technology |
|---|---|
| Frontend | Next.js, React, Tailwind CSS, Motion |
| Backend API | FastAPI, Python |
| Orchestration | LangGraph, LangChain |
| LLM (default) | Ollama (llama3.1:8b) local/offline |
| LLM (optional integration path) | OpenAI-compatible backends (e.g., Featherless) |
| Security Tooling | httpx, nmap, whatweb, sqlmap, dalfox, semgrep, bandit, pip-audit, npm audit, trufflehog, detect-secrets, cppcheck |
| Streaming | SSE (sse-starlette) |
| Containerization | Docker, Docker Compose |
| Deployment | Vercel (frontend), Railway (backend) |
Built With
- bandit
- dalfox
- detect-secrets
- docker
- fastapi
- framer-motion
- httpx
- langgraph/langchain
- next.js
- npm-audit
- ollama-+-openai-compatible-apis-(featherless)
- pip-audit
- python
- railway
- react
- semgrep
- sqlmap
- sse
- tailwind-css
- trufflehog
- typescript
- vercel
- whatweb

Log in or sign up for Devpost to join the conversation.