-
-
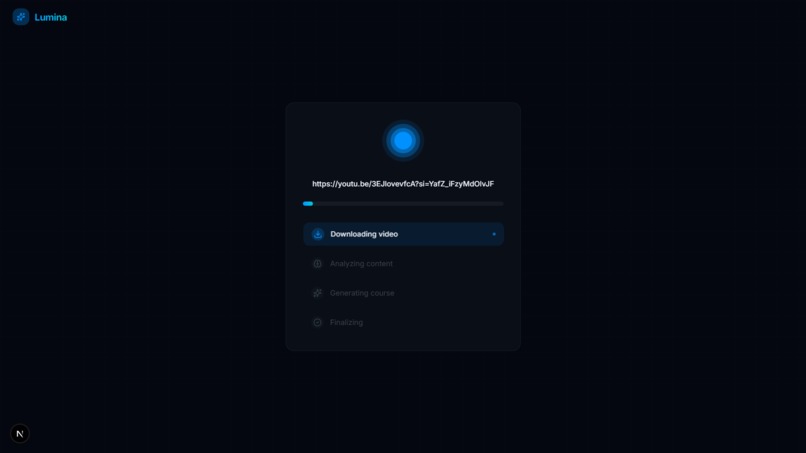
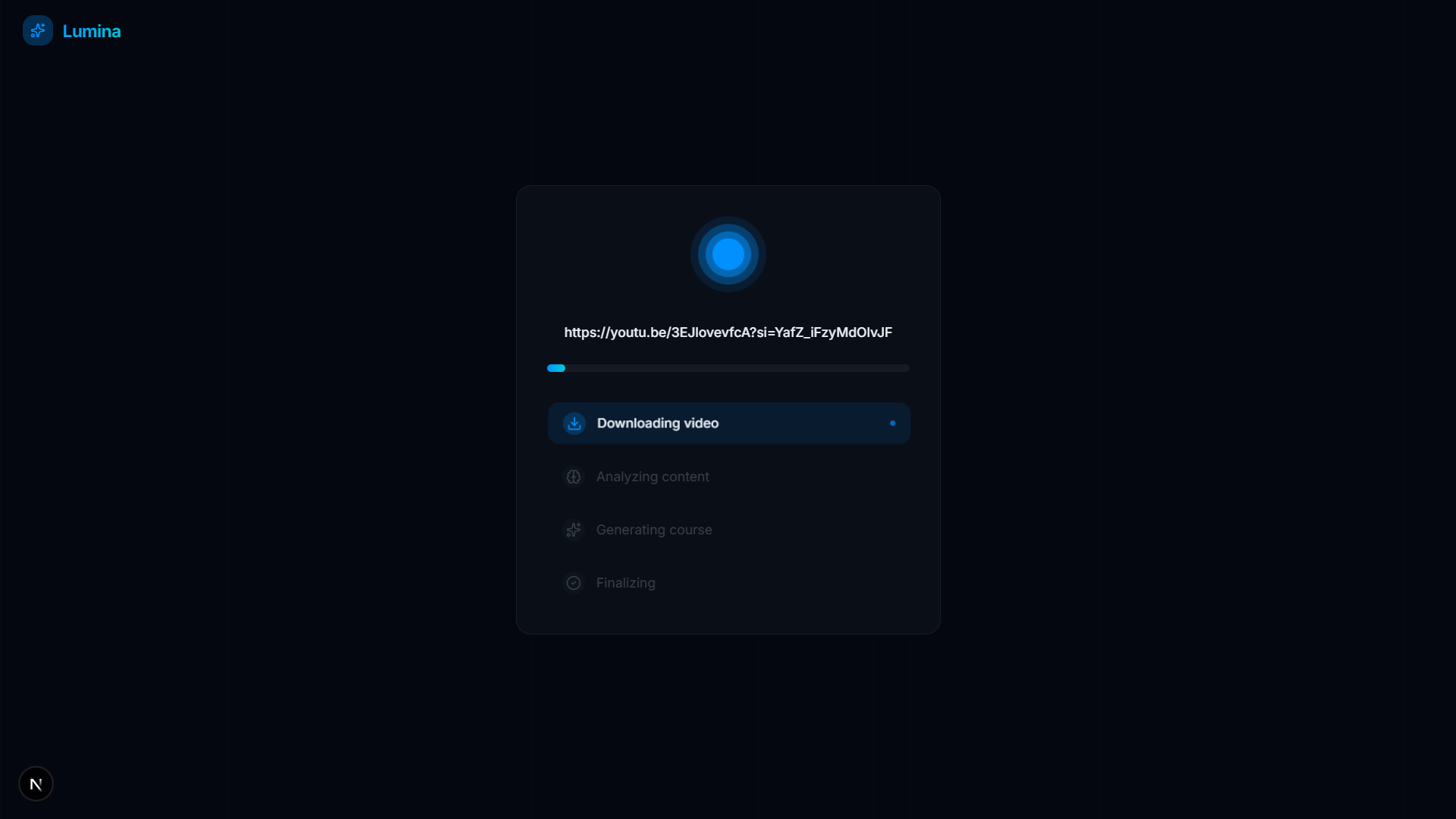
Video Downloading State
-
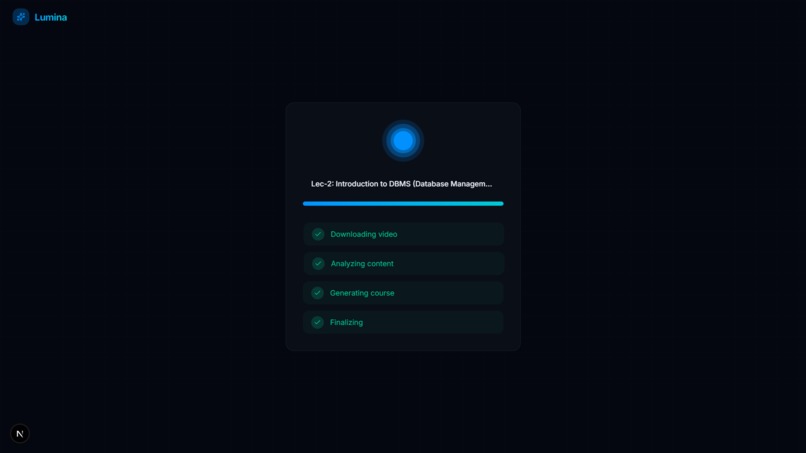
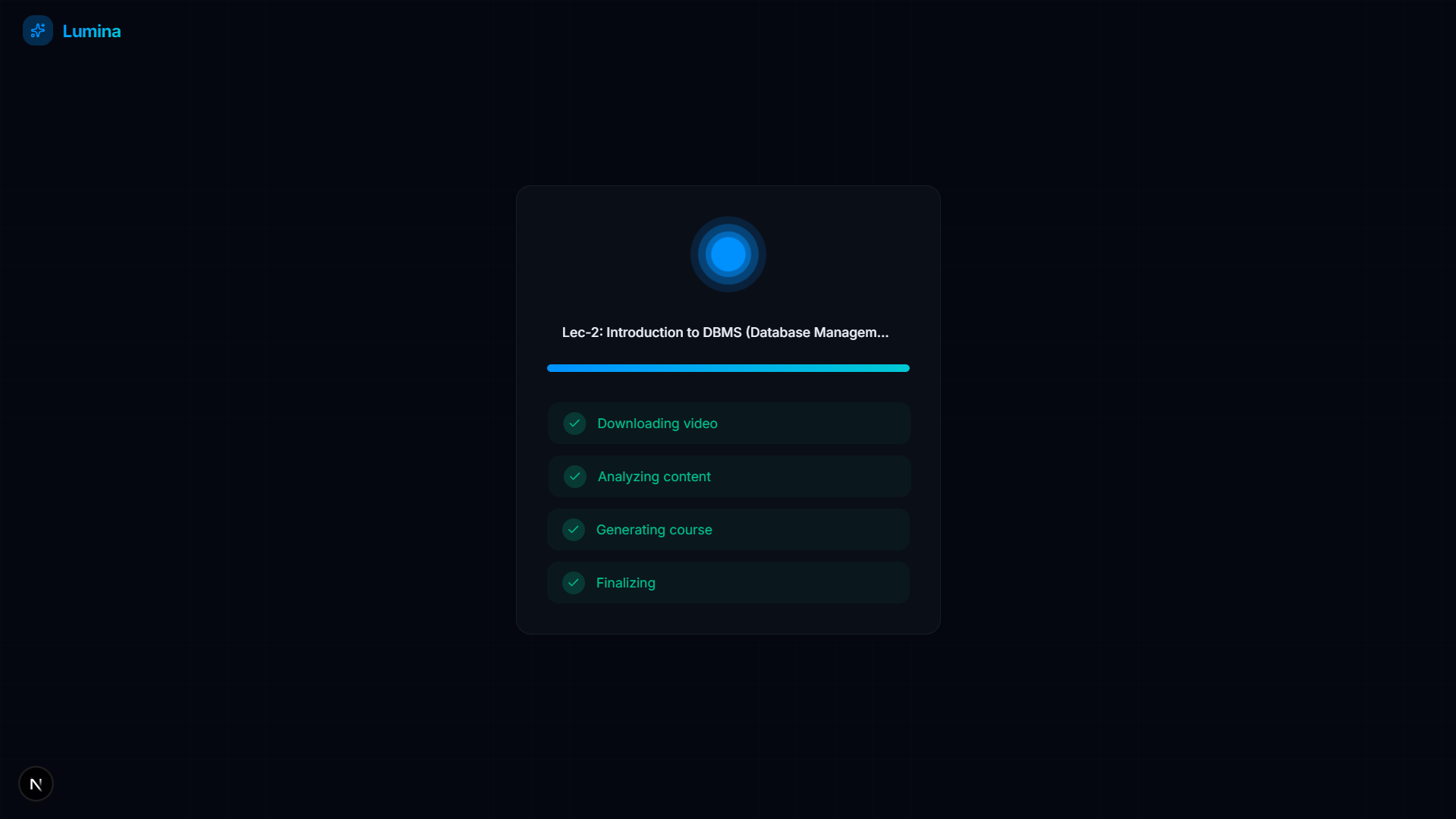
Video Analysis Complete
-
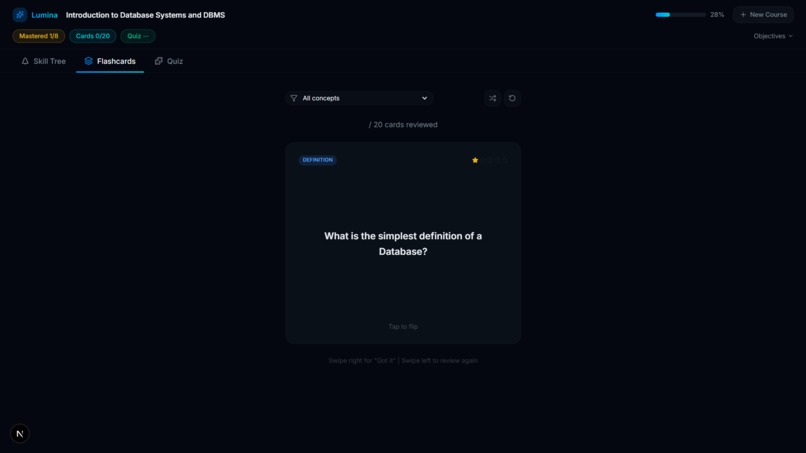
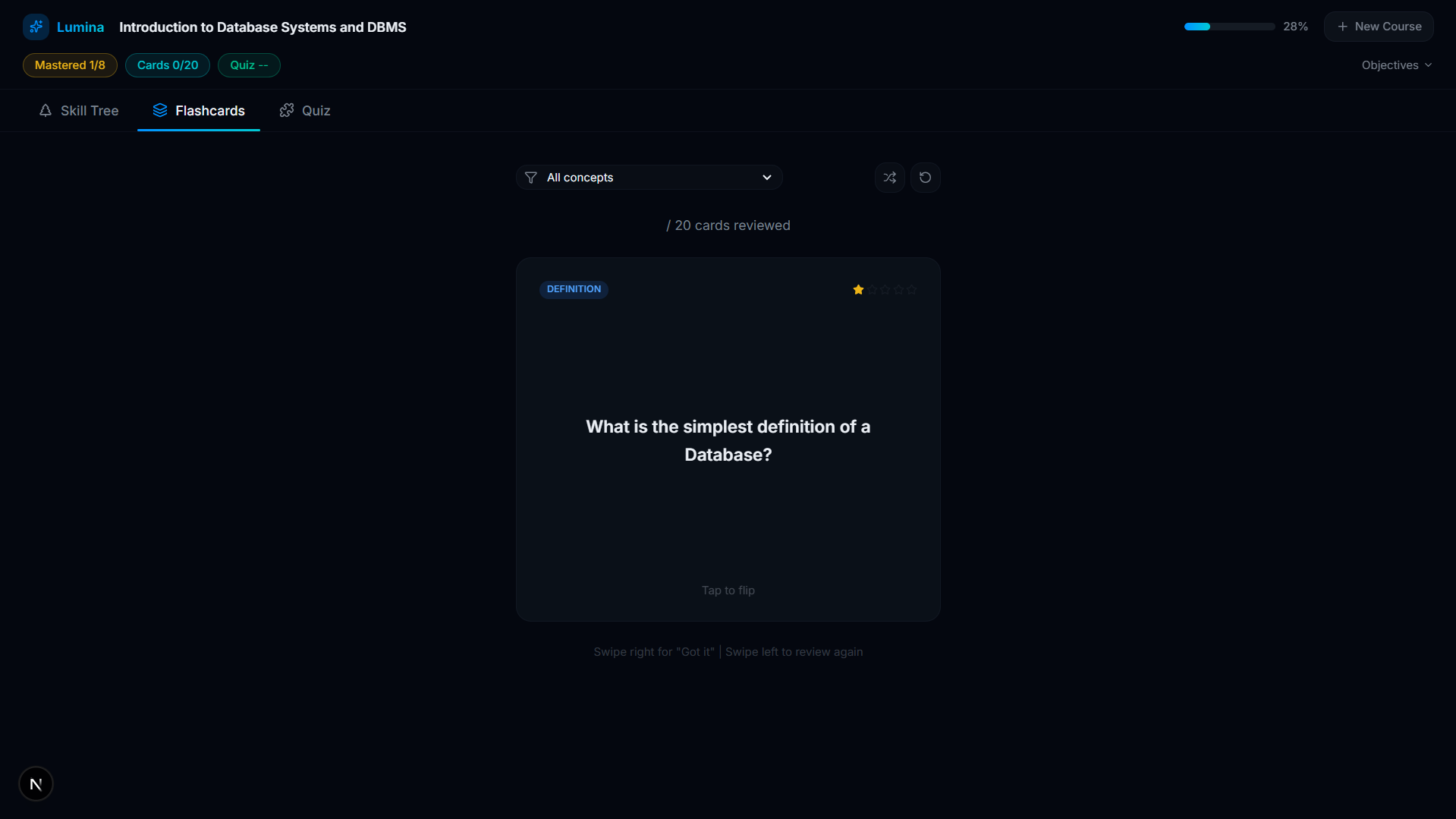
FlashCards
-
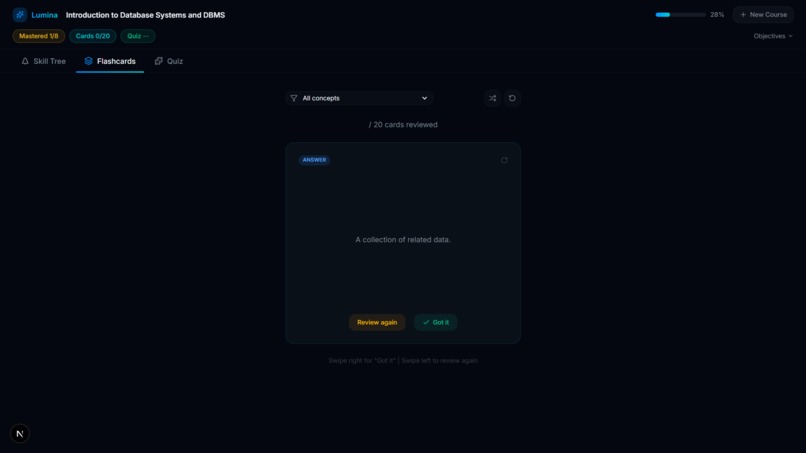
FlashCards Answer
-
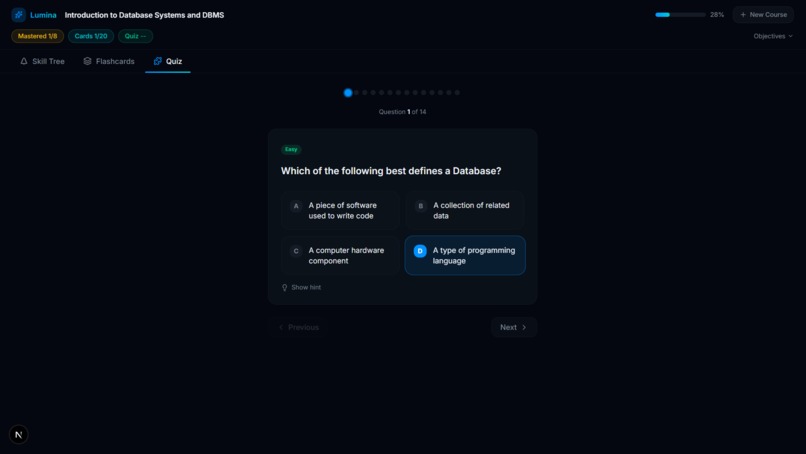
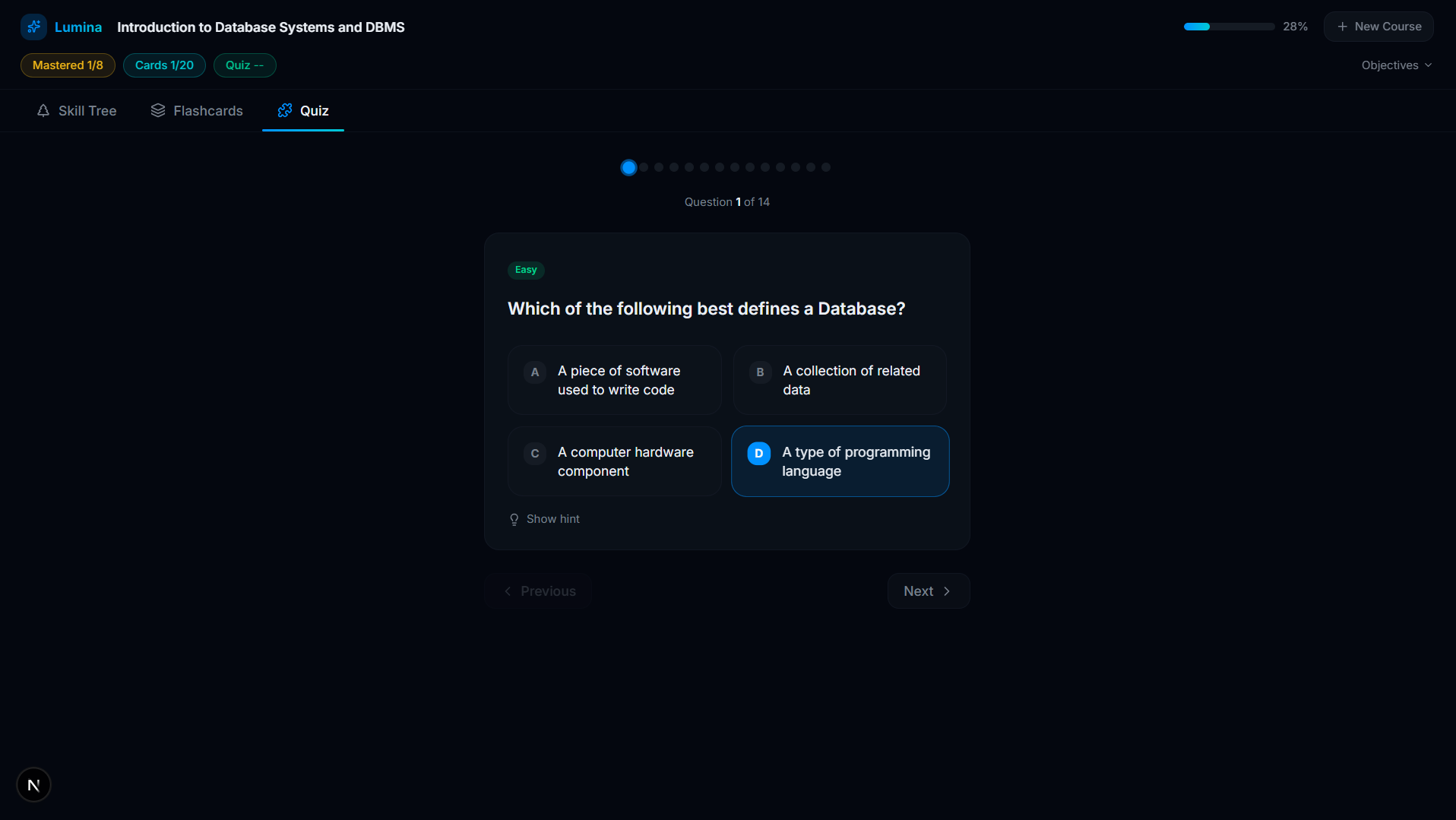
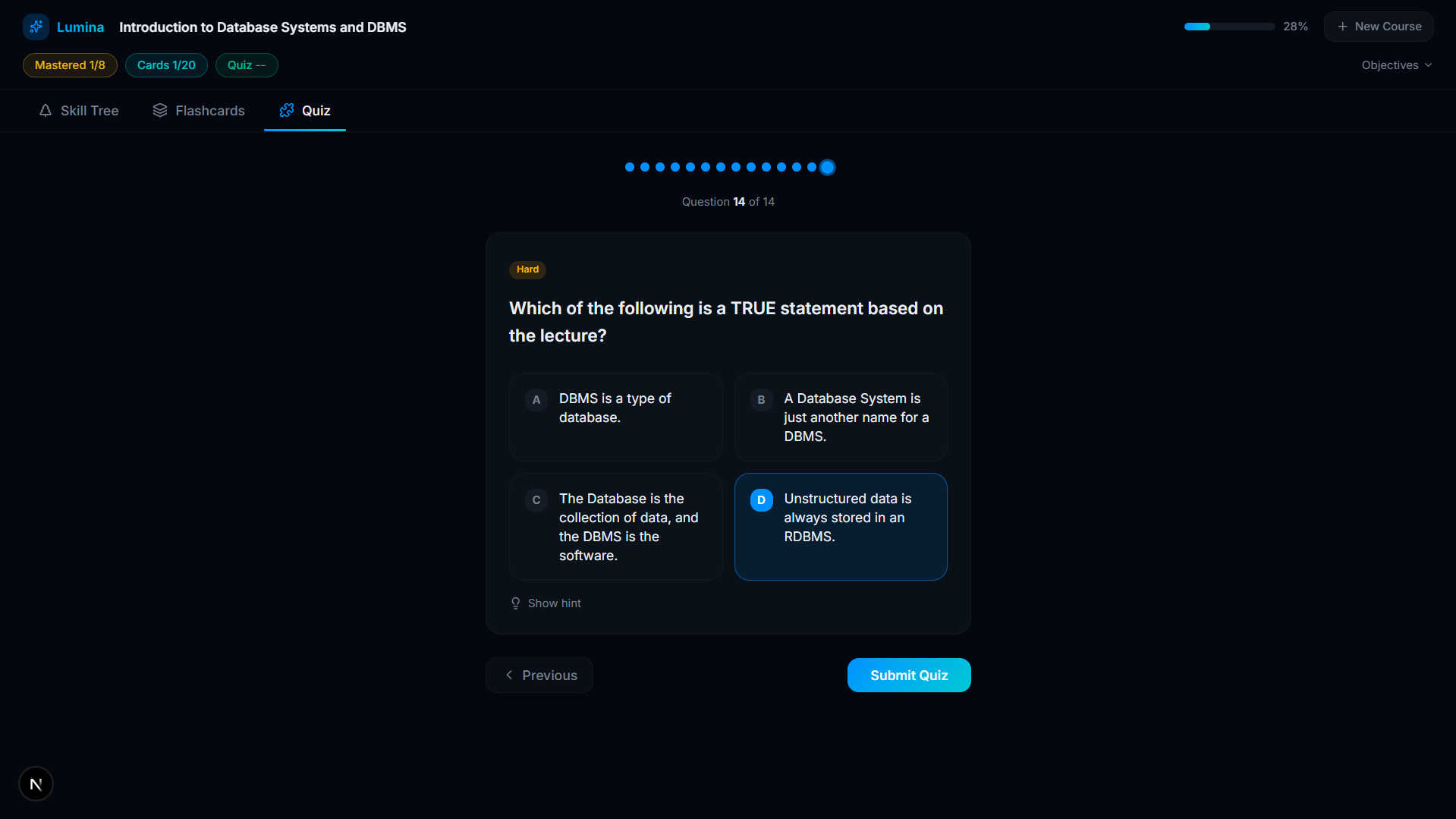
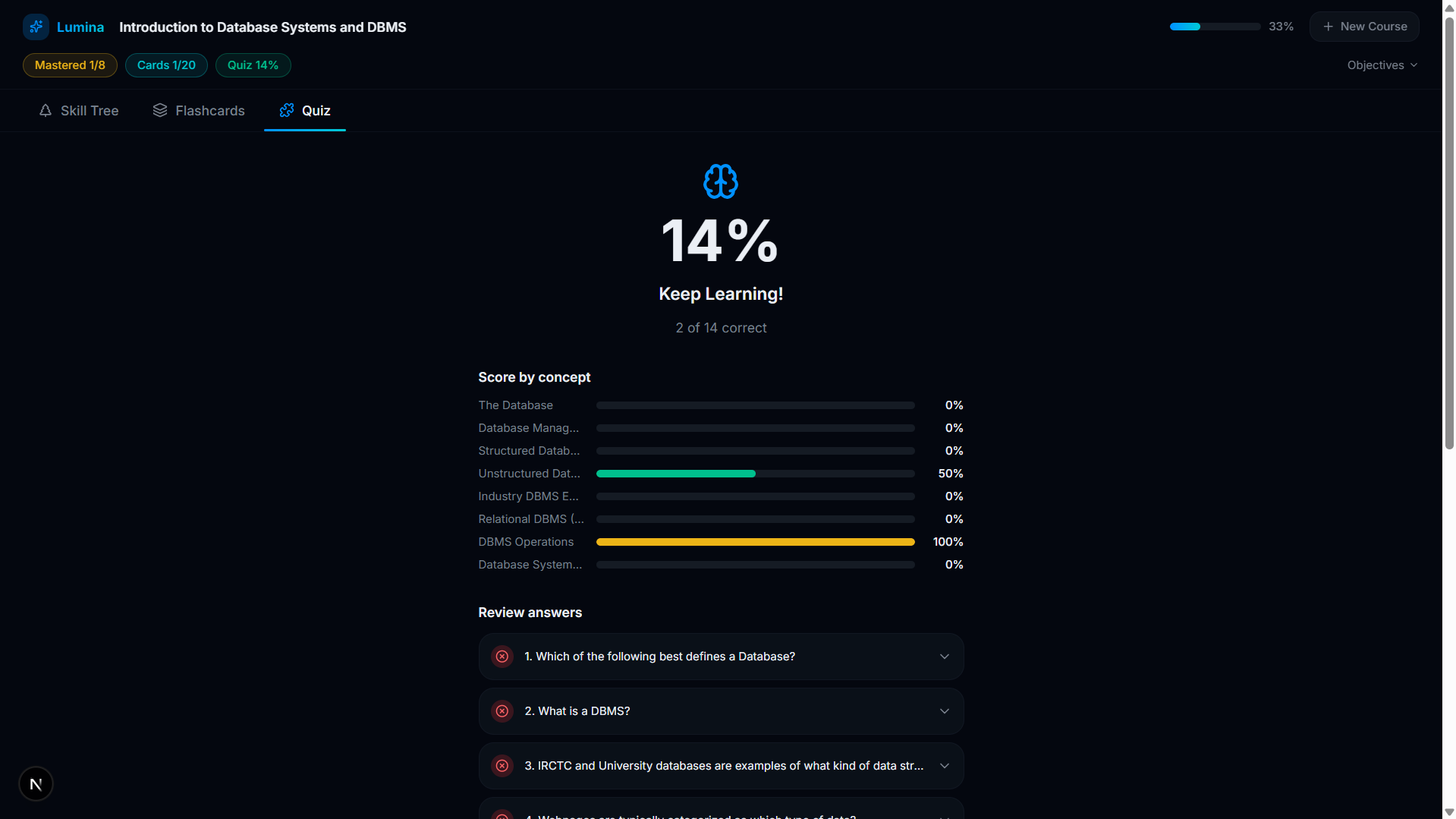
Quiz
-
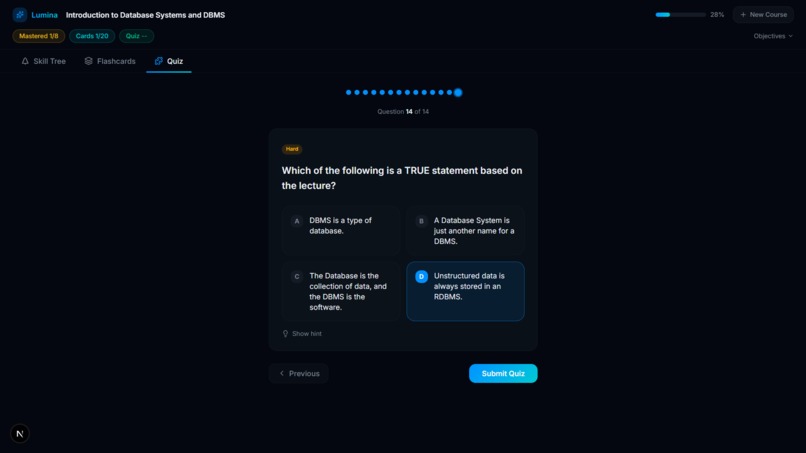
Quiz Submission
-
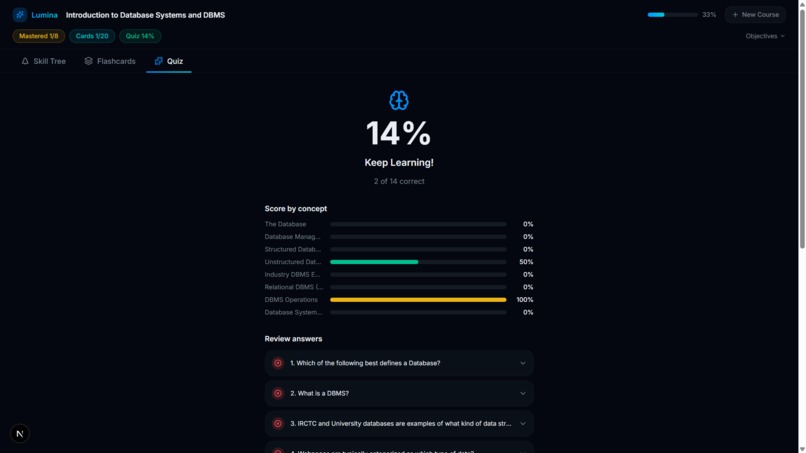
Quiz Result And Score
-
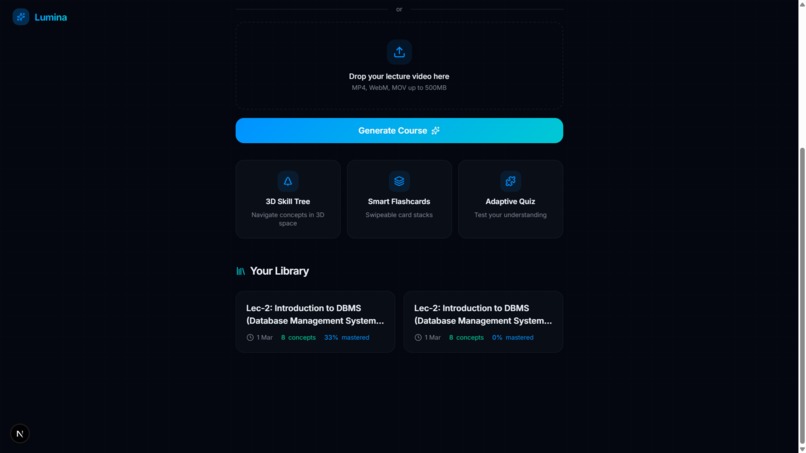
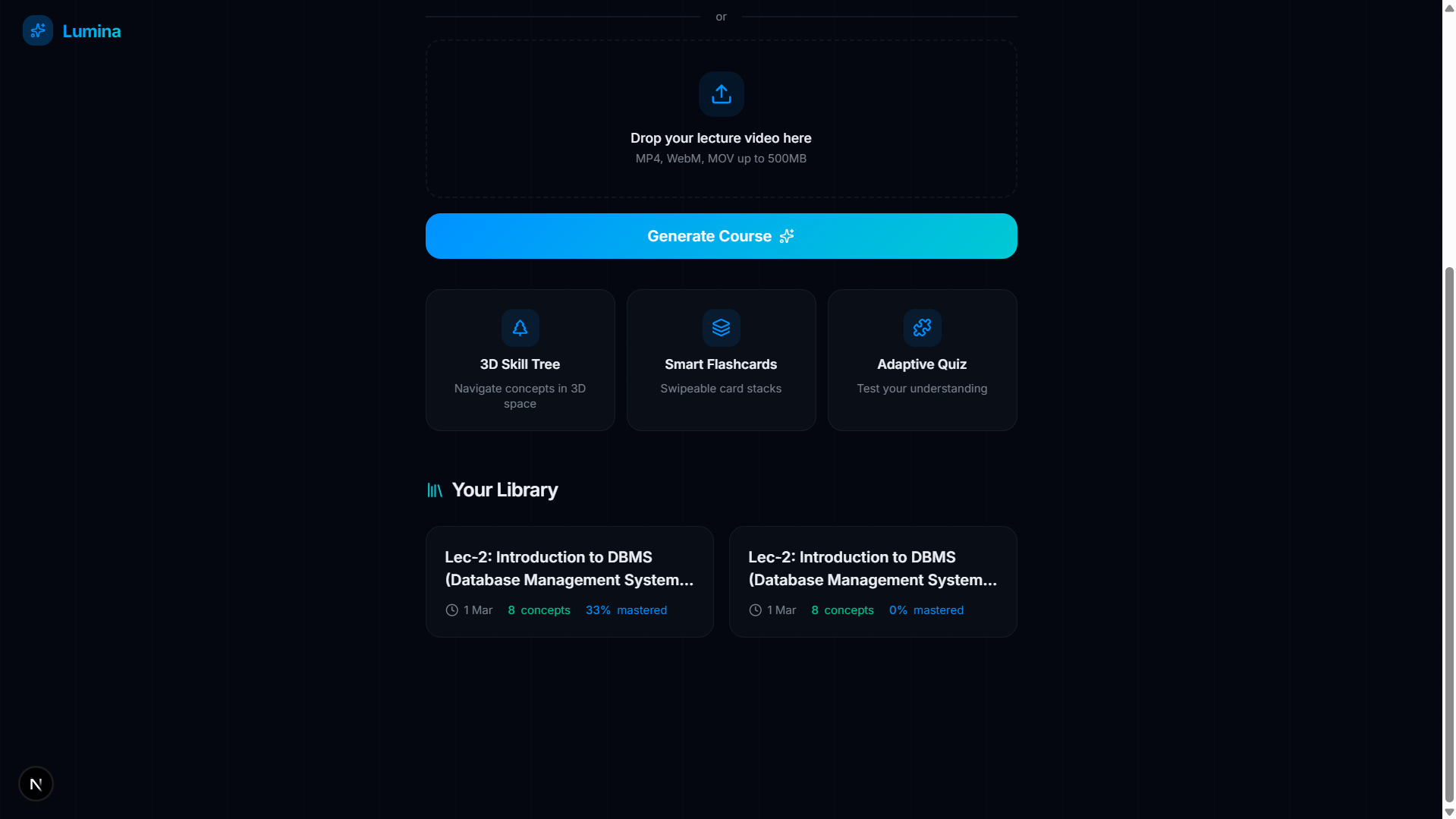
My Library
-
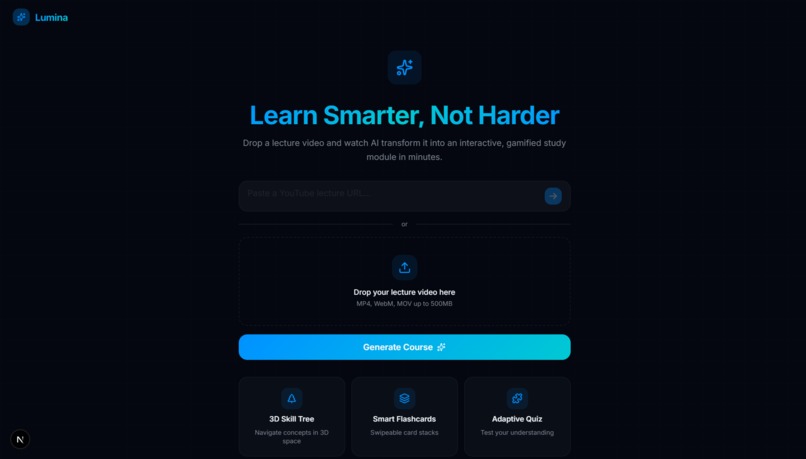
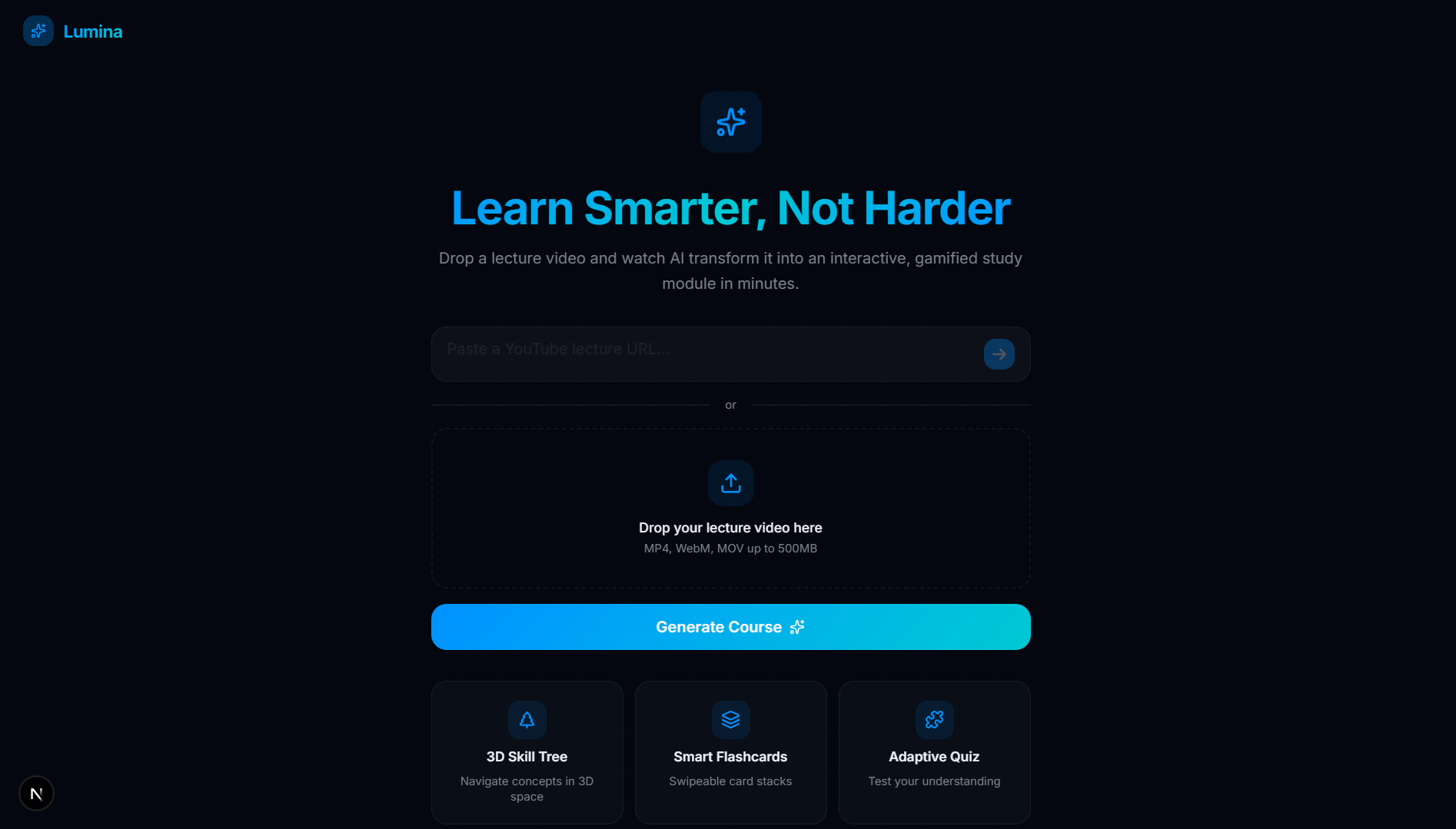
Landing Page
-
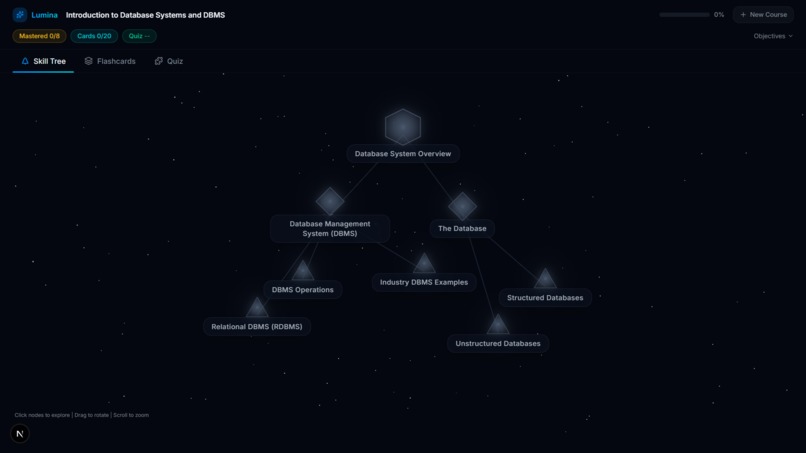
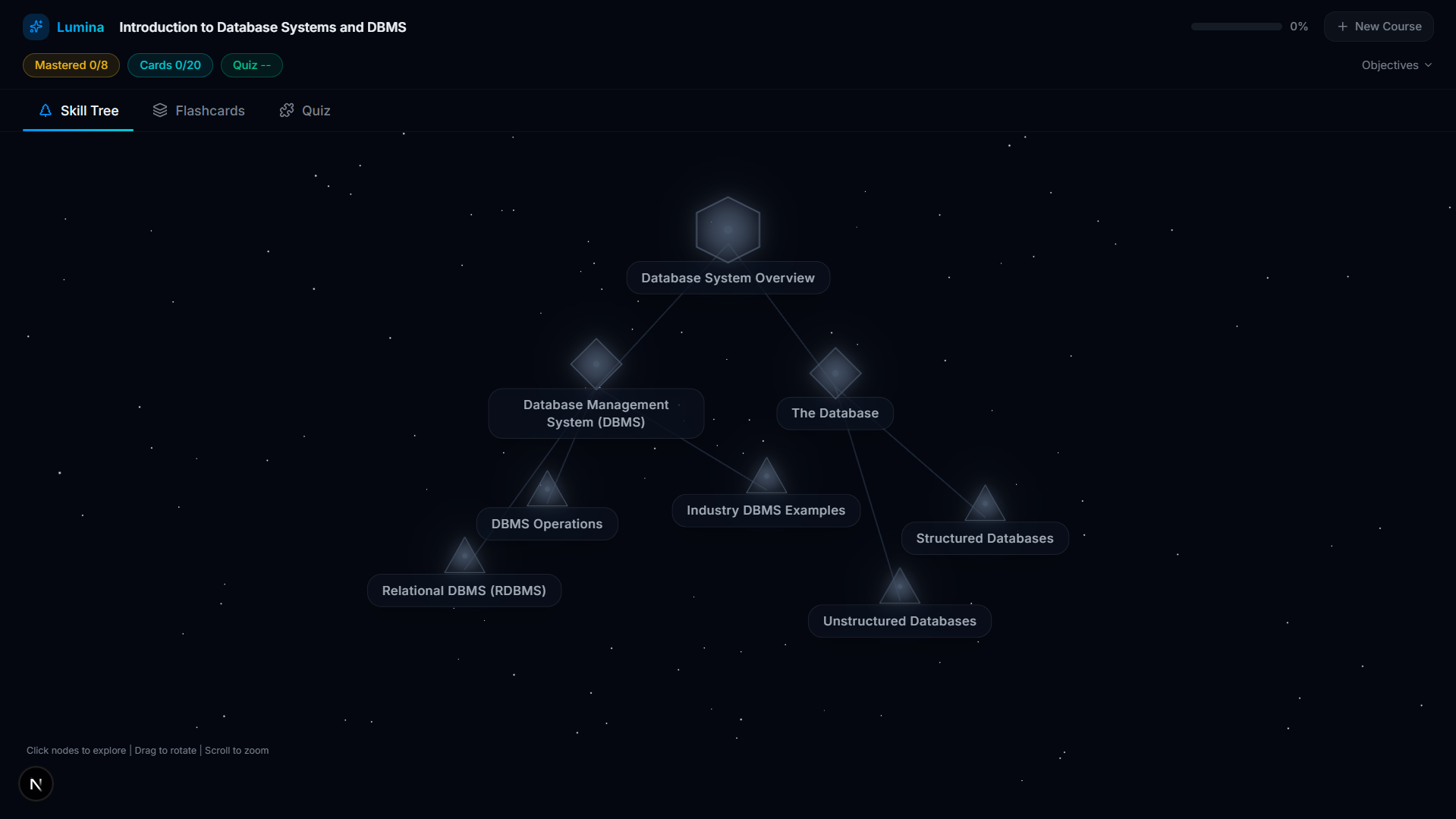
Skill Tree
-
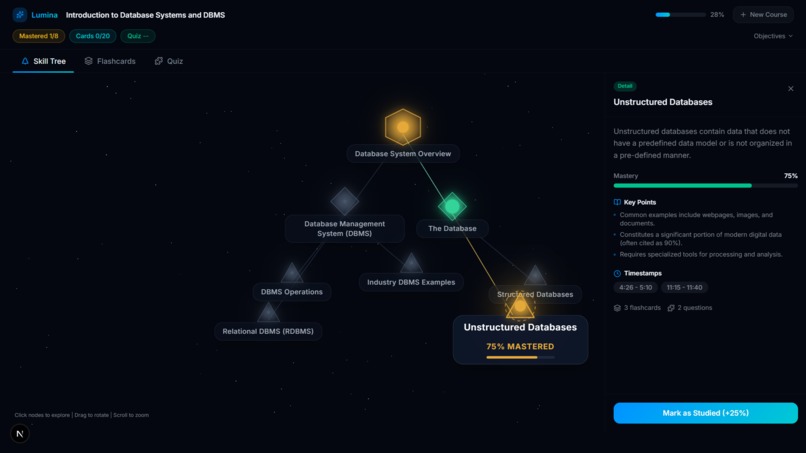
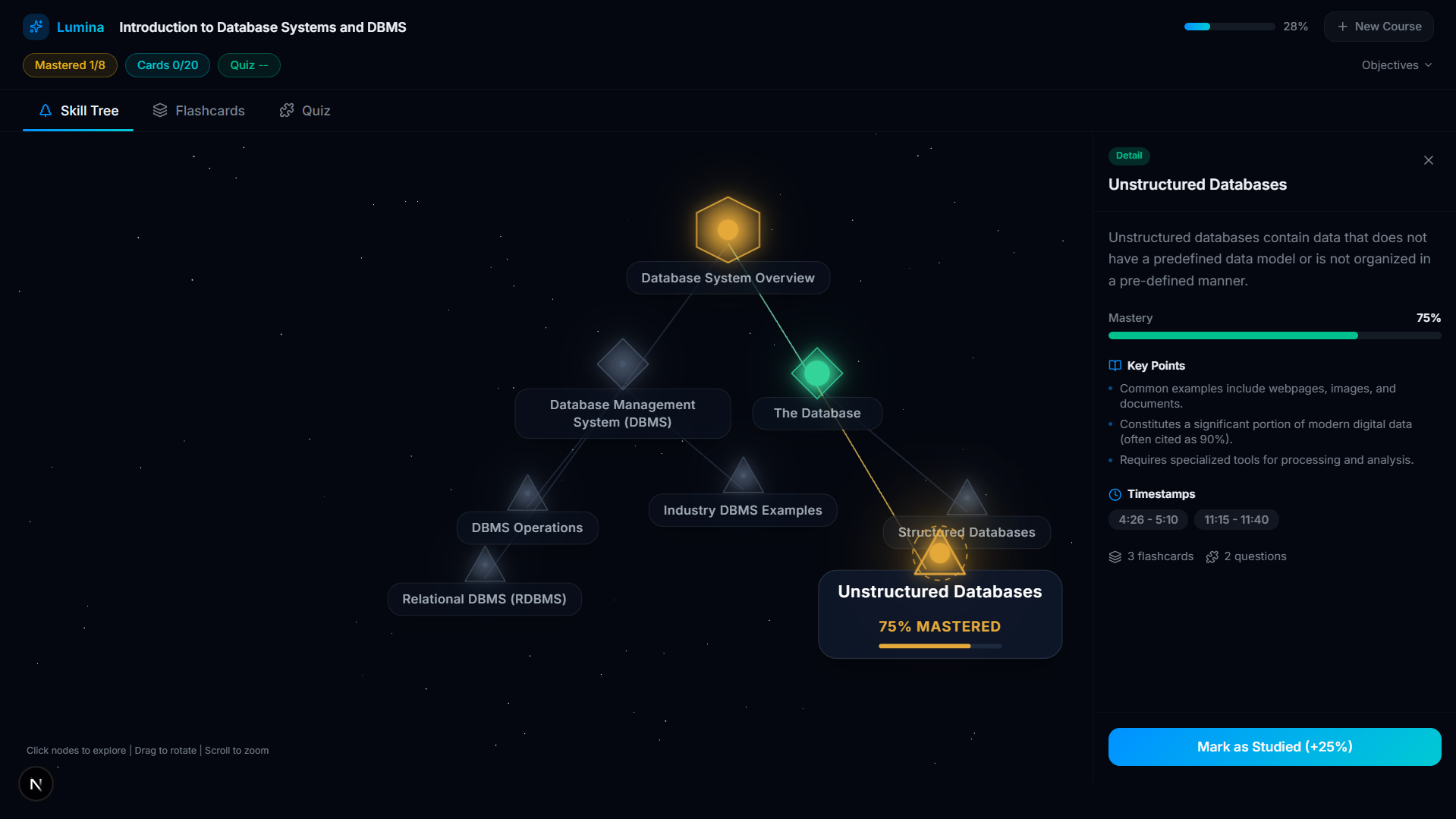
Module Mastery
-
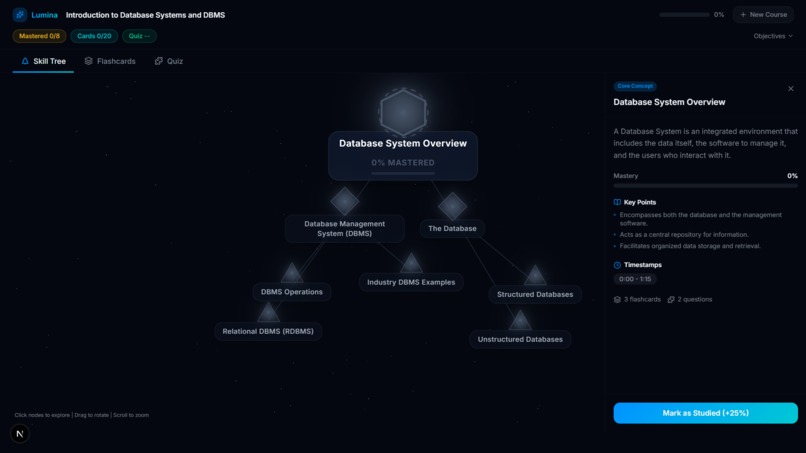
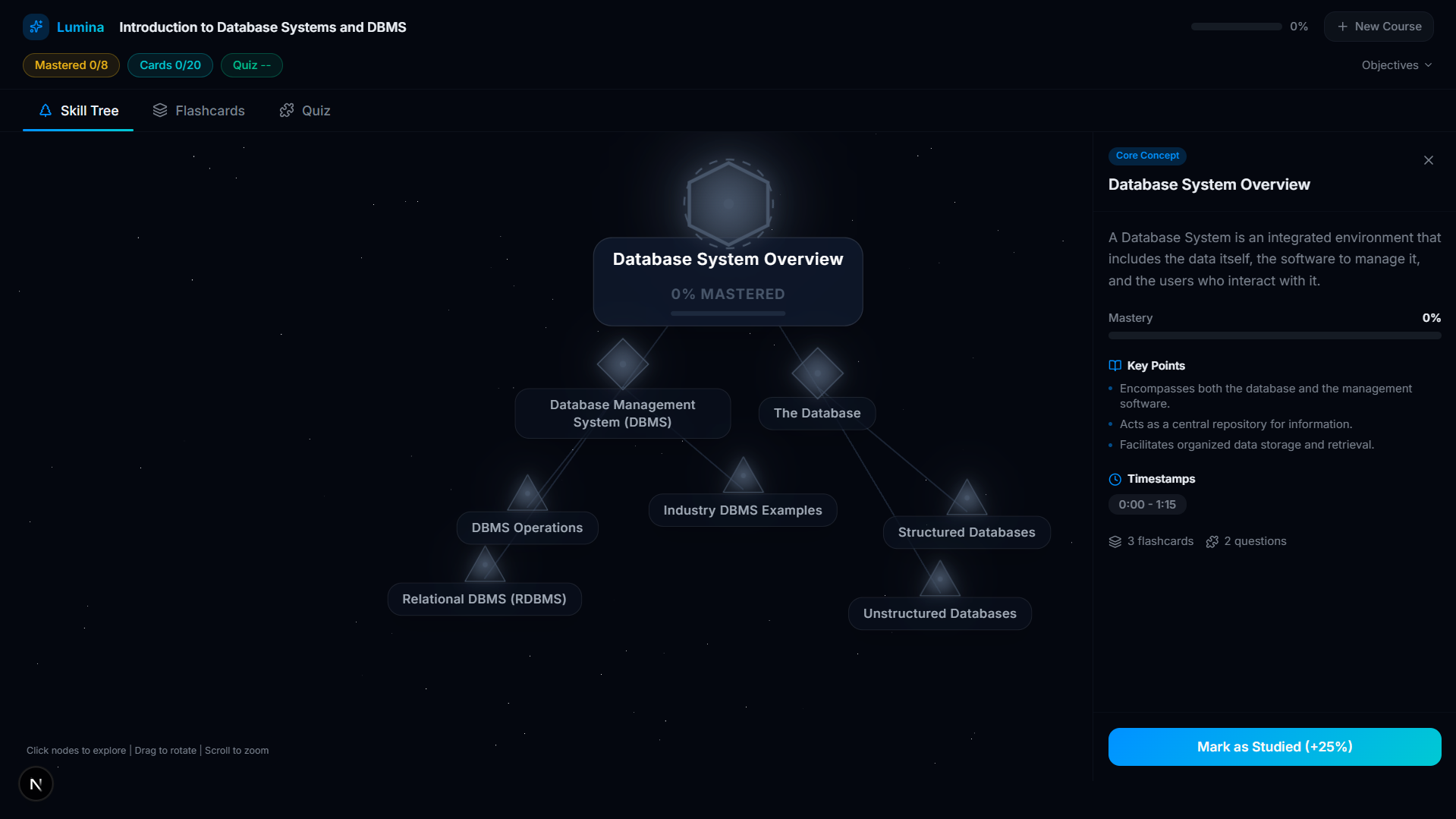
Skill Tree Module

Inspiration
Have you ever stared at a 2-hour long lecture on YouTube and felt overwhelmed before you even hit play? We consume more video content than any generation before us, yet we still learn passively. Watching a video doesn't guarantee retention.
We asked ourselves: What if we could turn passive video consumption into active, game-like exploration?
This inspired Lumina, an AI-powered educational co-pilot that ingests any YouTube educational video or lecture and automatically constructs a personalized, interactive, 3D "Skill Tree". Instead of a linear video timeline, you get a beautiful, explorable map of concepts that you must unlock through mastery, backed by active recall techniques like flashcards and adaptive quizzes.
What it does
Lumina acts as your personal tutor to deconstruct complex video lectures into bite-sized, interconnected learning objectives.
- Automated Knowledge Extraction: Simply paste a YouTube URL. Lumina runs background processing to fetch the video's transcript, extract its core semantic concepts, and establish prerequisites between them.
- 3D Skill Tree Interface: We visualize the extracted knowledge as a dynamic, physics-based 3D graph (using Three.js). You start at the root concept and unlock deeper nodes as you progress.
- Active Recall Engine: For every concept on the tree, Lumina's AI automatically generates targeted flashcards and adaptive multi-choice quizzes based only on what was stated in the video.
- Mastery Tracking: As you complete flashcards and quizzes, the skill nodes physically react—glowing from grey (unstarted) to gold (in-progress), and finally to green (100% mastered). Progress is persistently tracked via a local database.
How we built it
Lumina is built using a modern, fully async stack designed for high performance AI workloads:
- Backend (Python & FastAPI): Our backend relies on an asynchronous architecture. When a user submits a URL, FastAPI spawns a background
asynciotask. We useyt-dlpto pull transcripts and metadata. - AI Processing: We integrated Google's Gemini models via the official SDK using Pydantic structured output. The AI is prompted to return a rigid JSON schema representing the
ConceptNode,Flashcard, andQuizQuestionmodels, heavily constrained to prevent hallucination. - Database (SQLite & SQLAlchemy): We implemented asynchronous persistent job tracking using
aiosqlite. Since video processing takes time, the UI creates a job and polls the backend, keeping the user updated through specific steps: \( Downloading \rightarrow Analyzing \rightarrow Generating \rightarrow Completed \). - Frontend (Next.js & React Three Fiber): The UI is constructed using Next.js, TailwindCSS, and Framer Motion for sleek animations. The crown jewel—our Skill Tree—is built in
@react-three/fibermapped with 3D force-directed graph logic. We bound our React State (Zustand) to Three.js materials to visually represent mastery in real-time.
Challenges we ran into
- Hallucinations & Context Limits: Summarizing entire 2-hour lectures can break context windows. We had to carefully construct our prompts and enforce strict Pydantic schemas so the LLM would only return valid JSON syntax for complex nested relationships (parents vs. children nodes).
- 3D Graph Physics: Structuring an arbitrary JSON array of concepts into a visually pleasing, non-overlapping hierarchical tree was incredibly difficult. We had to write custom D3-force layout physics inside the
Three.jscanvas to simulate repulsion between siblings and attraction to parents so the nodes dynamically organize themselves on-screen. We had to balance forces similar to Coulomb repulsion and Hooke spring attraction:
$$ F_{repulsion} = k_e \frac{q_1 q_2}{r^2}, \quad F_{attraction} = -k x $$
- Persisting Complex State: Managing the synchronization between our 3D canvas objects, our React global state (
zustand), and the browserlocalStoragebecame challenging. If a user refreshed, we had to seamlessly remap their 50% mastery on a single nested node back into the 3D visualizer without causing a re-render crash.
Accomplishments that we're proud of
- Successfully integrating React Three Fiber with complex, physics-based positioning that reacts smoothly and beautifully to state changes. The "wow" factor of interacting with your own learned knowledge is real.
- Creating a deeply reliable prompting pipeline that outputs consistently perfect hierarchical JSON from messy YouTube transcripts.
- Building a fully detached, async background worker system in Python so that the UI never blocks while Gemini crunches thousands of tokens of transcript data.
What we learned
- Prompt Engineering is Software Engineering: We learned that you can't just "ask" an LLM for a skill tree; you have to programmatically enforce it through structured outputs and schema validators.
- We deepened our understanding of 3D coordinate mathematics and bridging WebGL (Three.js) contexts with standard React DOM contexts.
What's next for Lumina-AI powered Educator
- Multi-modal Support: Extending ingestion beyond just YouTube transcripts to process raw PDF textbooks, Slides, and directly uploaded MP4s via Gemini's native multi-modal capabilities.
- Spaced Repetition: Introducing a timed scheduling algorithm (like Anki) to notify the user when a concept's "Mastery" starts decaying over weeks of inactivity.
- Multiplayer Trees: Allowing students in the same class to share the same Skill Tree and compete to master the nodes fastest!
Built With
- fastapi
- framer-motion
- google-gemini-3.0-flash
- next.js-14
- pydantic
- pytest
- python
- react-three-fiber
- sqlite
- tailwind-css
- three.js
- typescript
- vitest
- yt-dlp
- zustand

Log in or sign up for Devpost to join the conversation.