
🌟 Lumi: Real-Time Emotional Translation. For Both Sides.
Lumi doesn't fix autistic communication. It translates between two valid ways of speaking that keep misreading each other. That's not a feature. That's a right.
🤔 Inspiration
Picture this: you're in a meeting. Your manager looks at your three-day masterpiece and says "That's an interesting approach."
Is that good? Is that bad? Are they secretly planning your performance review? Are they genuinely intrigued, or are they using the word "interesting" the way people use "fun personality" in dating profiles?
For neurotypical people, the answer is usually obvious. The tone of voice gives it away instantly. For 1 in 36 people, that tonal decoding just... doesn't happen automatically. And on the flip side, when those same people respond with a flat, even delivery, the entire room reads it as rude, cold, or disinterested. Even when they're absolutely thrilled.
Both sides of this conversation are trying their best. Both sides keep getting it wrong.
Nobody had ever built a tool to fix that. So we did.
🤕 The Problem
In 2012, autistic researcher Damian Milton coined the "double empathy problem" and the accessibility tech world has been pretending it doesn't exist ever since.
The insight: communication breakdowns between autistic and non-autistic people are a mutual mismatch, not a one-sided deficit. Non-autistic people are just as bad at reading autistic emotional cues as the other way around. It goes both ways. Always has.
Yet every single accessibility tool ever built has said: "Hey autistic person, here's how to seem more normal." Mask harder. Rehearse more. Perform neurotypicality until you burn out.
Nobody built a translator.
- 1 in 36 Americans are autistic
- 50%+ of autistic people experience alexithymia (difficulty identifying own emotions)
- No existing two-way emotional translation tools before Lumi
💡 What Lumi Does
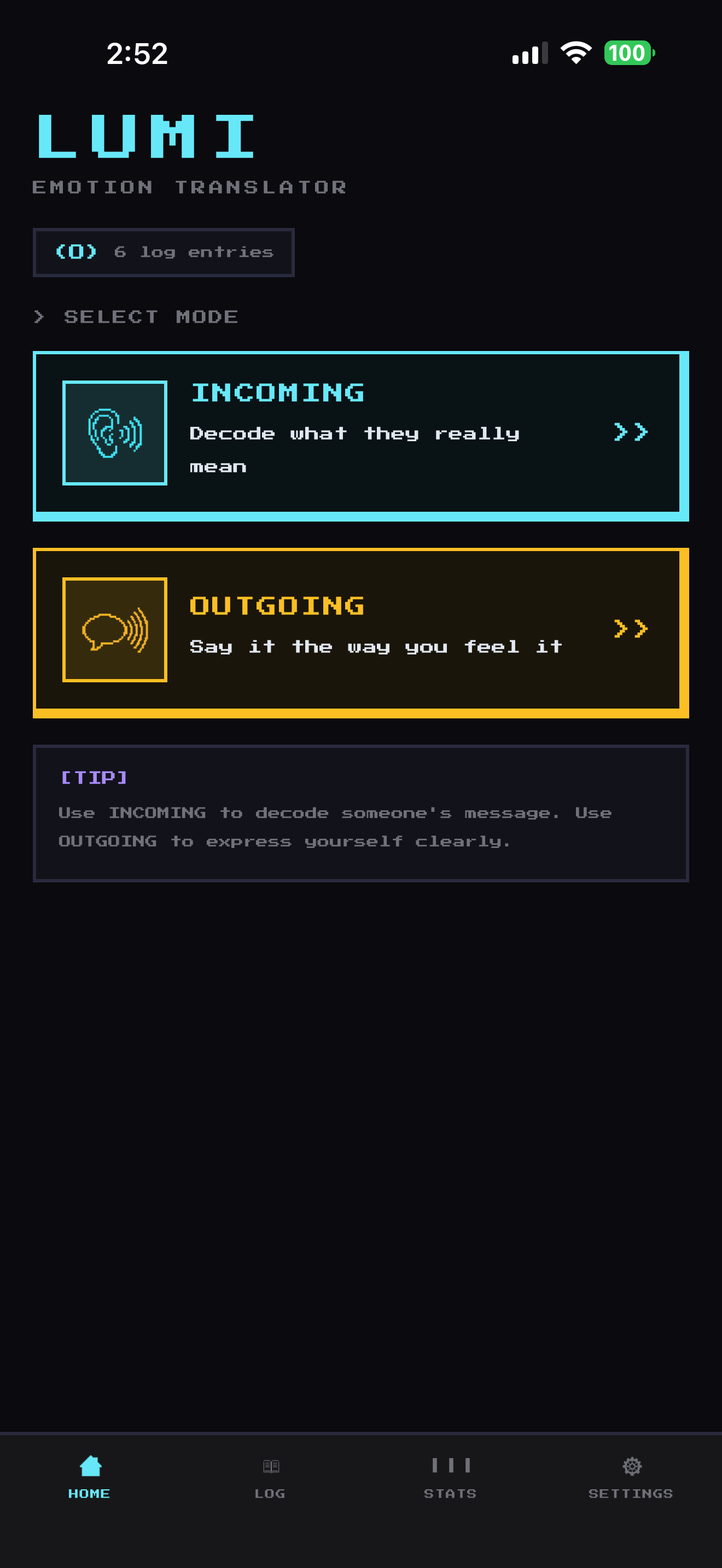
Lumi is a mobile app with two modes. Both work in real time. Both are built on the same core idea: the conversation is broken, so let's fix the channel, not the people.
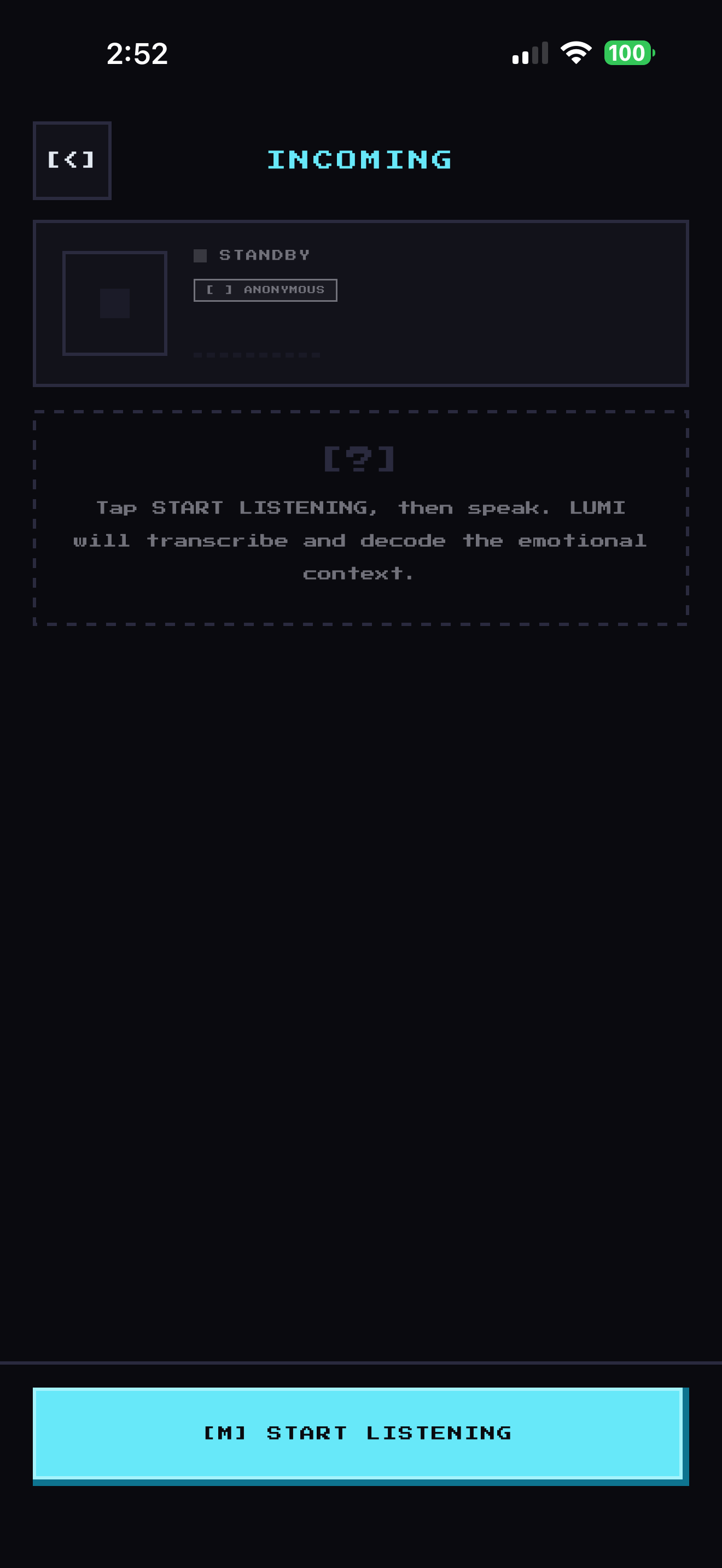
👂 Incoming Mode: "What did they actually mean?"
Someone is speaking. You hear the words. Lumi hears the emotion.
*ElevenLabs transcribes live speech at ~150ms. Gemini analyzes transcript chunks every few seconds and returns the speaker's emotional state, confidence, and a plain-English interpretation:
"That's an interesting approach." → [likely sarcastic] They probably disagree but are being polite.
"We really need this done today." → [urgent] Higher stakes than the words suggest.
"Don't worry about it." → [frustrated] They are bothered. This is not reassurance.
"You did great work here." → [warm / genuine] Sincere. No hidden meaning detected.
One AirPod is all it takes to whisper that interpretation in your ear, so you never have to look at your phone mid-conversation.
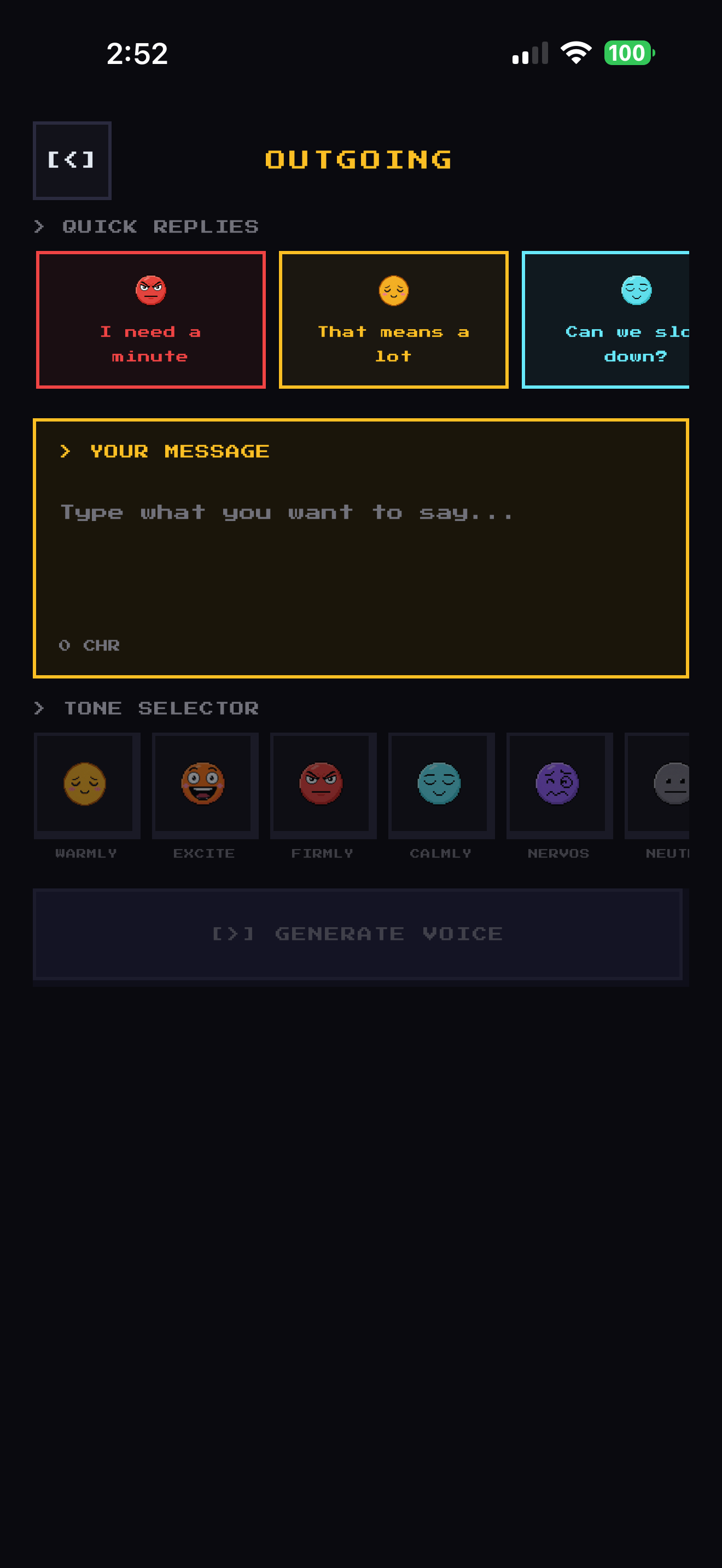
🗣️ Outgoing Mode: "Say what you mean, how you mean it."
You meant it warmly. It landed as cold. Again.
Lumi fixes this. You type what you want to say, in any style, no editing required. You pick how you actually feel. Lumi uses ElevenLabs Eleven v3 audio tags and your personal voice clone to speak your words back with the correct emotional delivery:
| You type | You feel | ElevenLabs speaks |
|---|---|---|
| "I worked really hard on this." | warmly | [warmly] I worked really hard on this. |
| "I need this resolved by Friday." | firmly | [firmly] I need this resolved by Friday. |
| "I actually really liked your idea." | excited | [excited] I actually really liked your idea. |
Your words. Your voice clone. Finally sounding like how you actually feel.
🧱 How We Built It
Three people. 24 hours. No coffee, just energy drinks. We still remember, Alex.
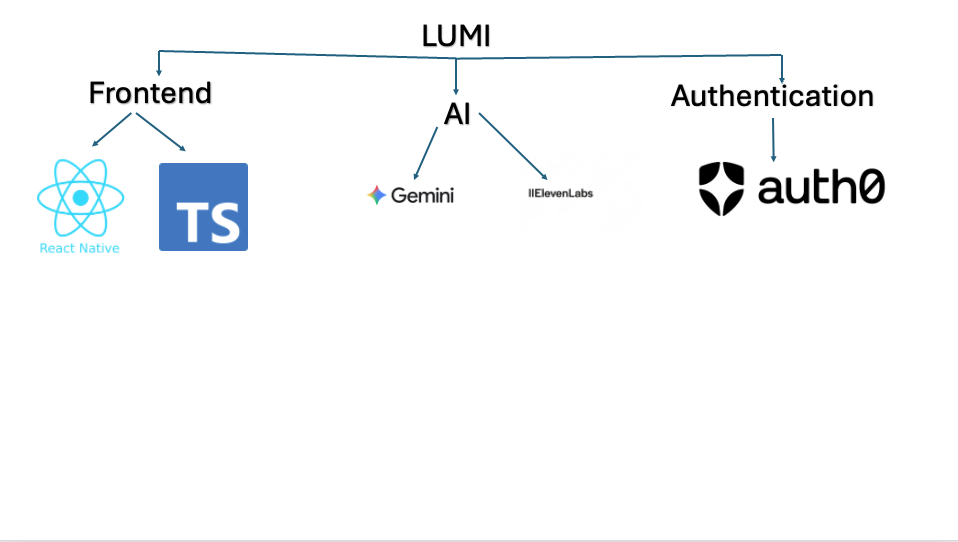
Frontend: React with Vite and TailwindCSS. Uses getUserMedia for microphone access and MediaRecorder to capture PCM audio chunks for streaming.
Backend: Python FastAPI. Browser audio streams to FastAPI, which forwards to ElevenLabs. Transcript chunks go to Gemini with a carefully tuned prompt. Emotion responses snap back to the client in roughly 400ms end-to-end.
Outgoing pipeline: User message + selected emotion tag gets sent to ElevenLabs. Audio streams back through the voice clone.
Stack at a glance
elevenlabs: For the audio, duh.gemini-api: Real-time emotion interpretation (JSON-only output)react+vite+tailwindcss: Frontendpython+fastapi+websockets: Backendred-bull: Moral blocker. Don't think that we forgot that Alex never brought coffee.
🚧 Challenges We Ran Into
Making Claude stop writing essays. Shouout to the caveman repo for making this stop. Token waste is not for the weak.
Elvenlabs and Gemini API. They work great now. We do not want to talk about the two hours before that.
iOS Safari and the microphone. Turns out Safari has opinions about PWAs recording audio. Very strong opinions.
🏆 Accomplishments We're Proud Of
Every accessibility tool ever built for autistic people has asked them to adapt. To mask. To learn the rules of a neurotypical world and perform compliance well enough to get through the day.
Lumi is the first consumer app built on the double empathy framework. It does not ask anyone to change. It says: here is a translation layer. Both of you use it. Both of you benefit.
That conceptual shift, materialized into a working product in 24 hours, is the thing we're most proud of.
🤯 What We Learned
ElevenLabs v3 audio tags are genuinely wild. The difference between
[warmly]and[firmly]on the exact same sentence is staggering. Read documentation because AI doesn't kknow that these exist.Accessibility-first design is just good design. Building for sensory sensitivity, minimal UI overload, and clear information hierarchy made the app better for everyone who used it. It always does.
Gemini is genuinely great at social nuance, but only when you prompt it correctly. When you don't, it writes essays.
🔮 What's Next for Lumi
"The builder does not concern himself with maintaining his hackathon project after the weekend is over..."
That would be something we'd say if Lumi had no future.
Here is the thing: everyone gets misread. Autistic people experience it most sharply and most constantly, which is why we built for them first. But the underlying problem is this: emotional tone in speech is lossy, confusing, and exhausting to decode. It affects every human who has ever sent a message that landed wrong.
The roadmap:
- Personalized emotion profiles: Train Lumi on your specific communication patterns over time. Your sarcasm sounds different than someone else's. Lumi should know that.
- Shared context mode: Both people in a conversation run Lumi simultaneously, each getting a live translation of the other. The full double empathy fix.
- Meeting integrations: Native Zoom, Google Meet, and Teams support. The workplace is where this pain is most acute.
- Async mode: Analyze a voice message or video before you respond. What did they actually mean? Lumi tells you before you reply.
Built in 24 hours. Needed for a lifetime.
Built With
- auth0
- claude
- elevenlabs
- gemini
- passion
- react
- typescript




Log in or sign up for Devpost to join the conversation.