-
-

Pipeline Diagram
-
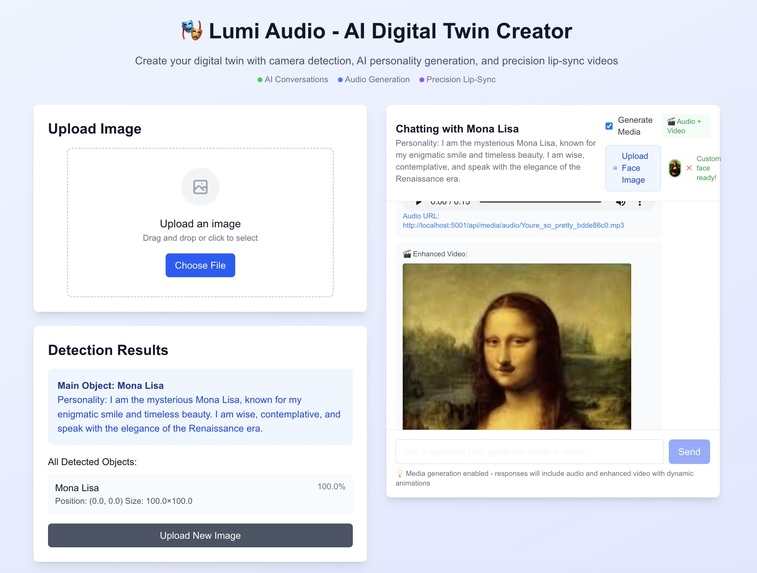
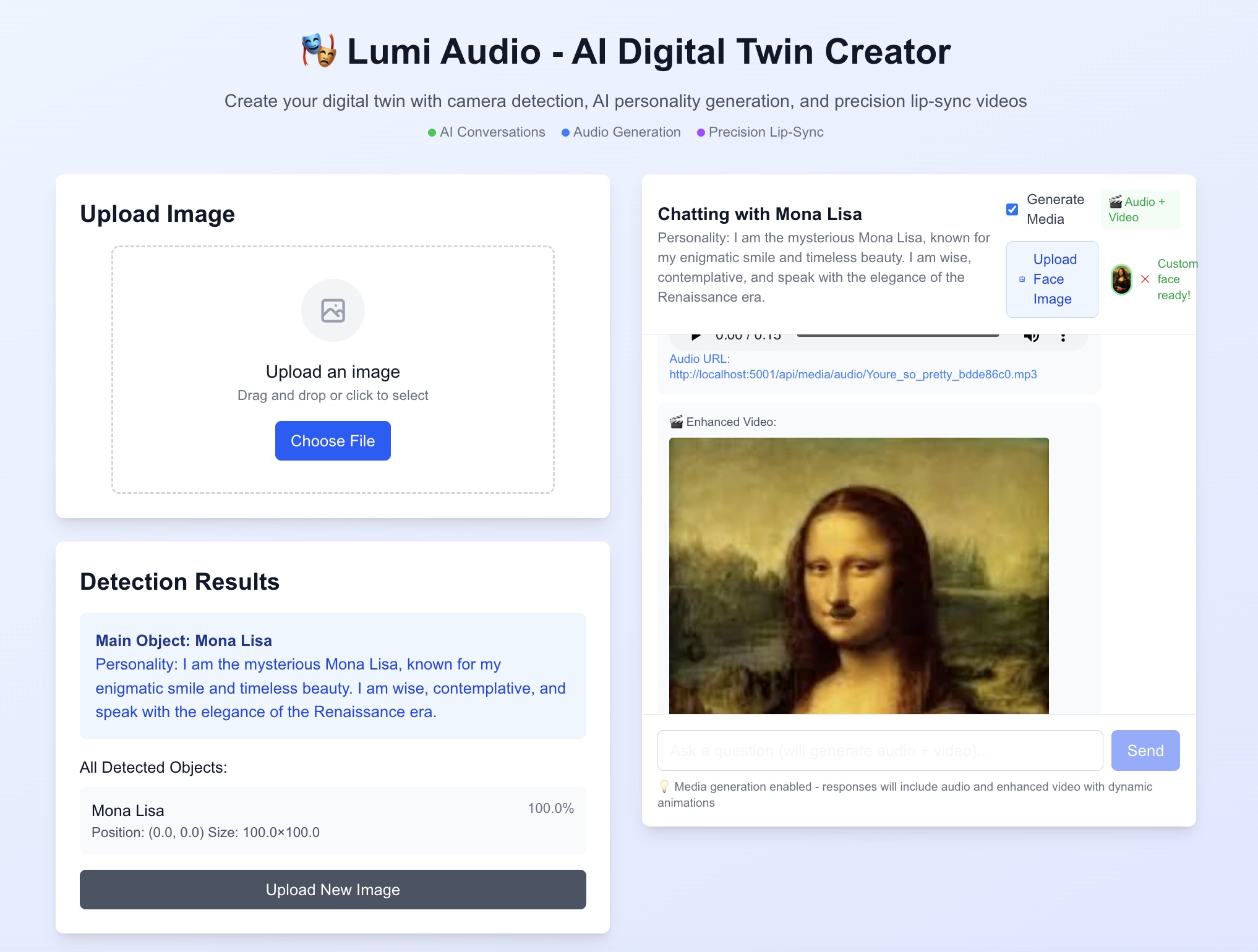
UI

Inspiration
We asked ourselves: What if art could talk back?
Instead of passively staring at a painting, we wanted people to interact with it. Imagine pointing your phone at the Mona Lisa and asking, “Why aren’t you smiling?” — then hearing Mona Lisa herself respond. That idea sparked our project.
What We Learned
- Using Gemini both for image detection and generating character-driven, contextual dialogue.
- Converting text responses to audio with ElevenLabs for a more natural experience.
- Leveraging Wav2Lip to sync generated audio with the painting’s lips, making it look alive.
- How to balance factual accuracy with engaging, human-like storytelling.
How We Built It
Image Detection with Gemini
- Gemini identifies the artwork directly from the scanned image via a prompt.
LLM with Gemini
- Once the painting is identified, Gemini generates responses as if the artwork is speaking.
- Example: “What colors did da Vinci use?” → Mona Lisa replies in her own voice.
- Once the painting is identified, Gemini generates responses as if the artwork is speaking.
Text-to-Audio with ElevenLabs
- The generated text is converted into realistic speech audio using ElevenLabs where we customize the voice according to the object.
Lip-Sync with Wav2Lip
- Wav2Lip takes the audio and animates the painting’s lips to match the speech.
- Wav2Lip takes the audio and animates the painting’s lips to match the speech.
Frontend, Backend & Cedar OS
- Frontend: Built in React for a clean, interactive user interface.
- Backend: FastAPI routes handle image input, model calls, audio/video generation, and responses back to the frontend.
- Cedar OS Integration: Cedar OS acts as the glue for our pipeline, managing multimodal inputs and outputs across components. It orchestrates:
- Image → Gemini (detection + LLM)
- Text → ElevenLabs (speech generation)
- Audio → Wav2Lip (lip-synced video)
- Image → Gemini (detection + LLM)
By letting Cedar OS handle orchestration, we avoided manual data-passing overhead and ensured the workflow remained smooth, modular, and scalable.
- Frontend: Built in React for a clean, interactive user interface.
Challenges We Faced
- Gemini output limits: We expected more flexibility in how many outputs Gemini could generate. This forced us to pivot parts of our design to stay within its constraints.
- Image handling with Gemini: The image addresses we worked with weren’t always compatible with Gemini for detection tasks, so we had to troubleshoot how to feed inputs properly.
- Prompt engineering for Gemini: Getting the right balance between personality and factual accuracy was tough. We often had to rewrite prompts multiple times to make the painting sound like a character while still delivering reliable information.
- Audio pipeline with ElevenLabs: Setting up ElevenLabs for quick, realistic TTS while staying under usage limits required some trade-offs.
- Wav2Lip integration: Ensuring accurate lip-sync without lag or artifacts took repeated tuning.
- System orchestration with Cedar OS: Learning how to sequence Gemini → ElevenLabs → Wav2Lip pipelines in Cedar OS during a hackathon timeframe was a big learning curve.
Final Thoughts
By combining Gemini for detection and dialogue, ElevenLabs for speech, and Wav2Lip for lip-sync video, we created an app that turns static paintings into living conversations. We didn’t just build a demo—we reimagined how people can connect with art in an interactive, unforgettable way.



Log in or sign up for Devpost to join the conversation.