-
-
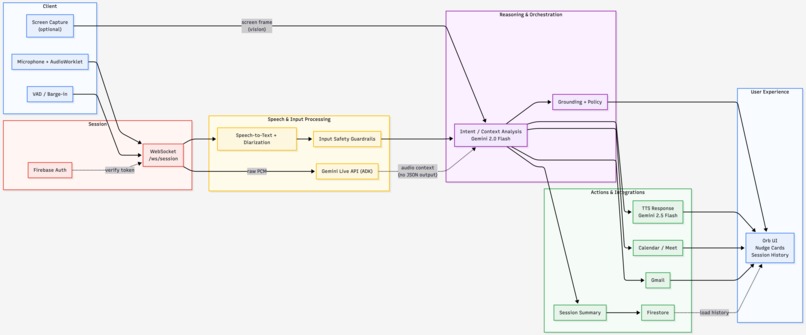
System architecture - dual-path Gemini design: Live API for audio context, 2.0 Flash for structured JSON decisions, 2.5 Flash TTS for voice
-
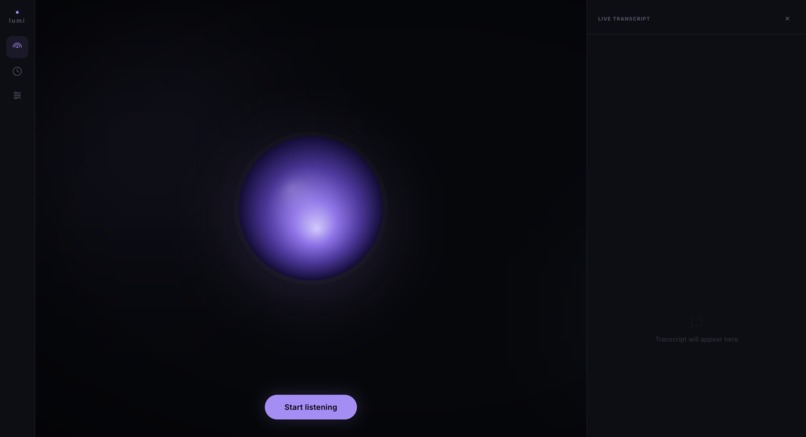
Lumi listening in the background - orb visualizer, live transcript drawer, Share screen and End session controls
-
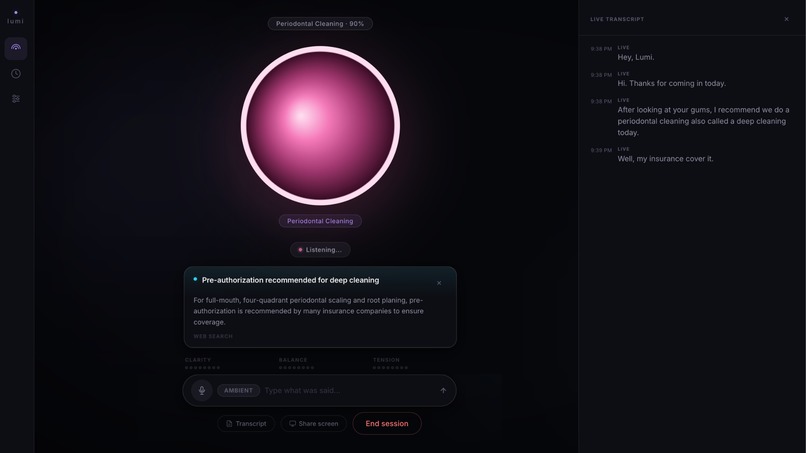
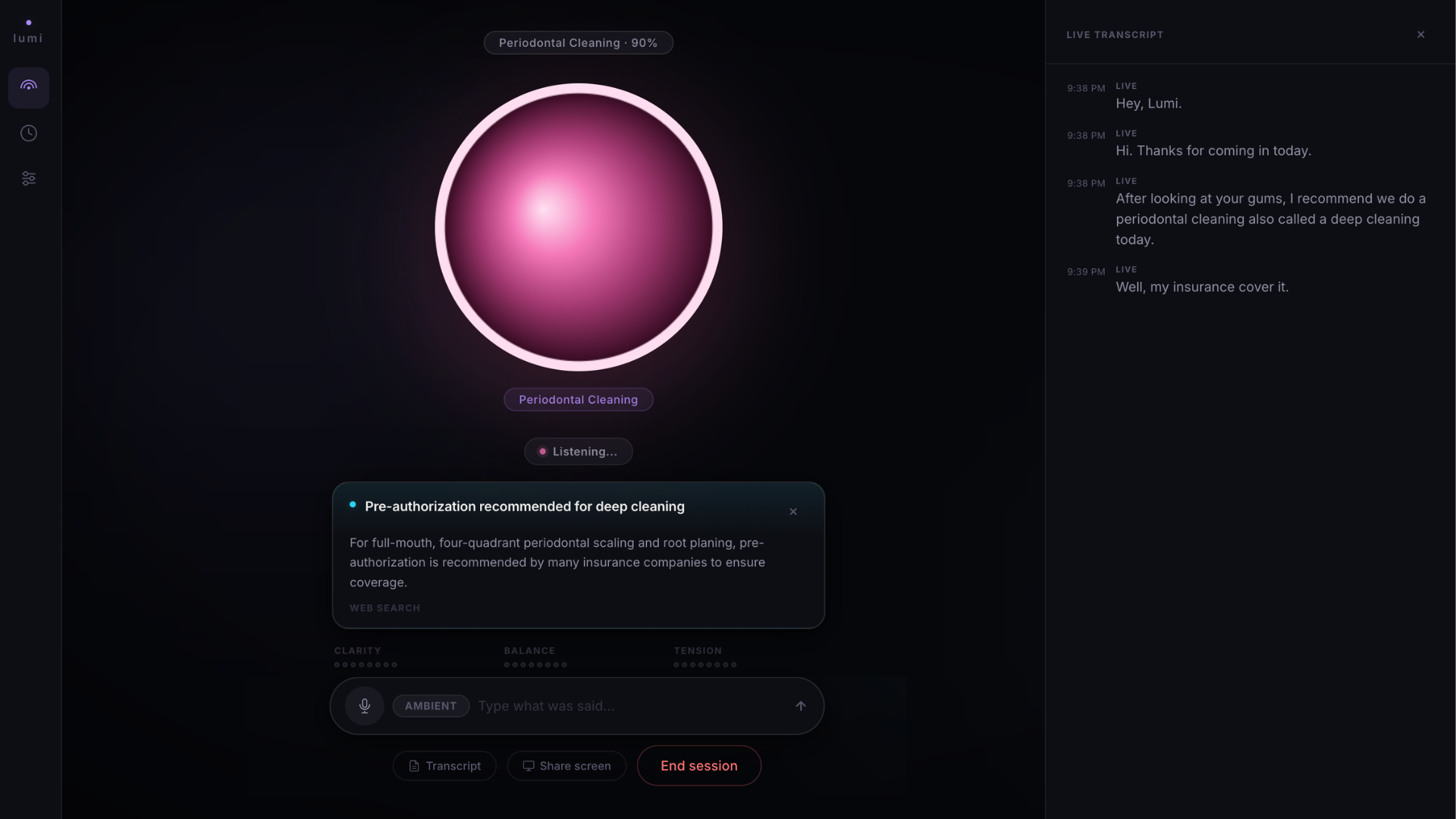
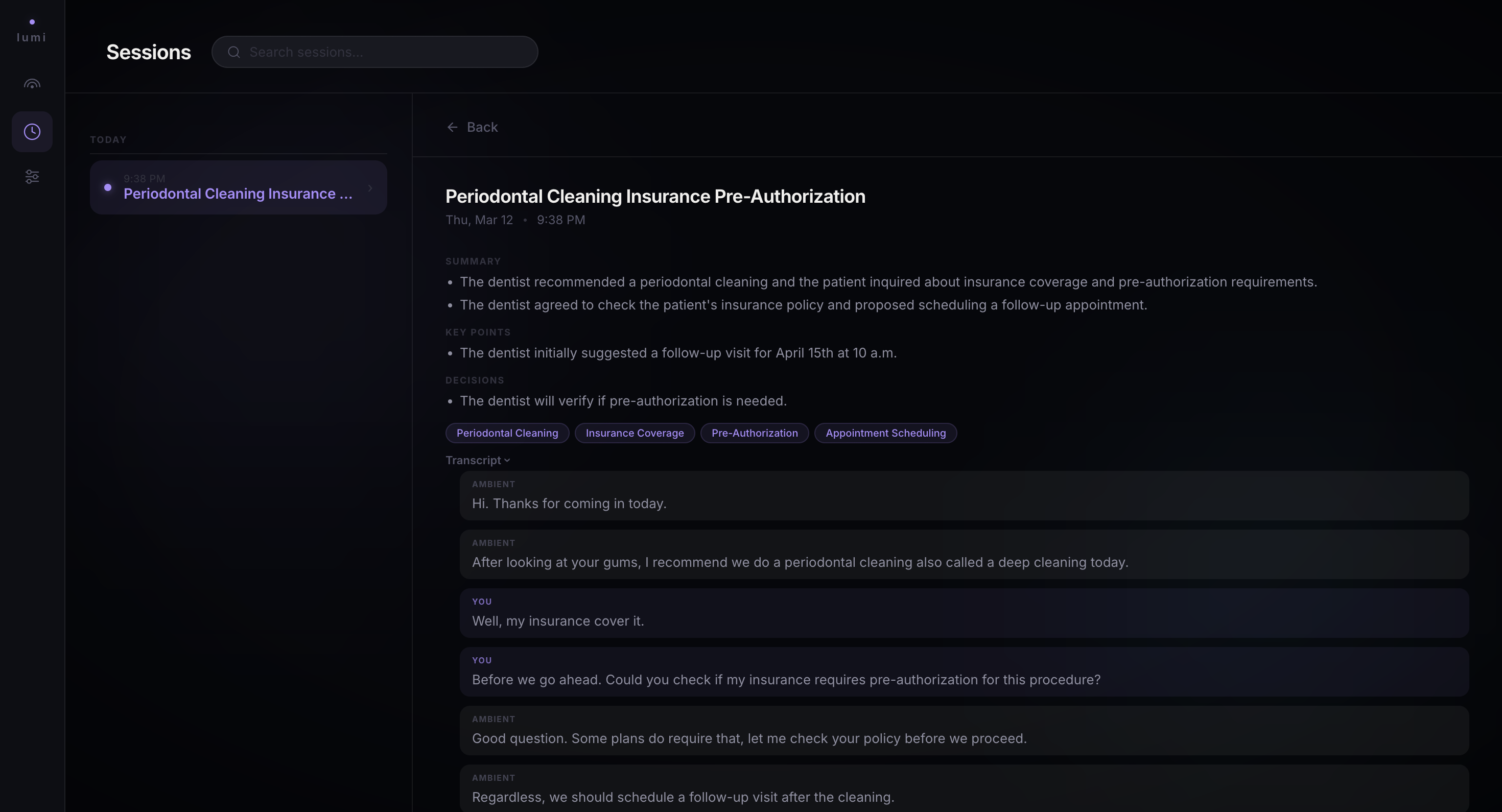
Lumi surfaces a grounded pre-authorization warning mid-conversation - sourced via Google Search before the card appears
-
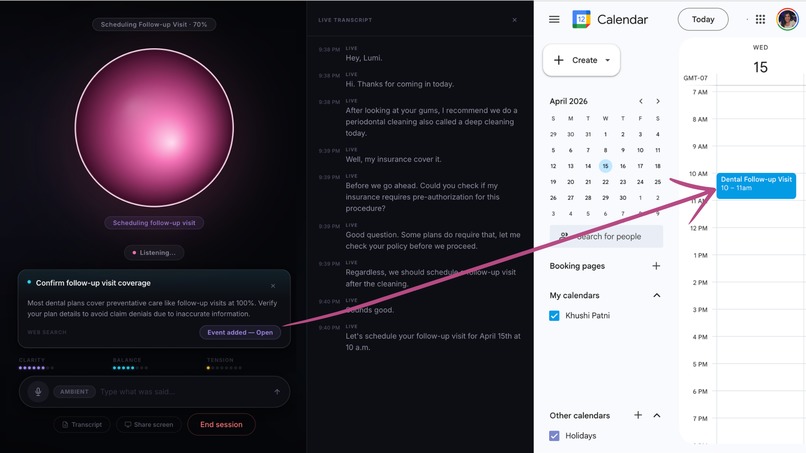
Scheduling intent detected - Google Calendar event and Meet link auto-created in one shot, no typing required
-
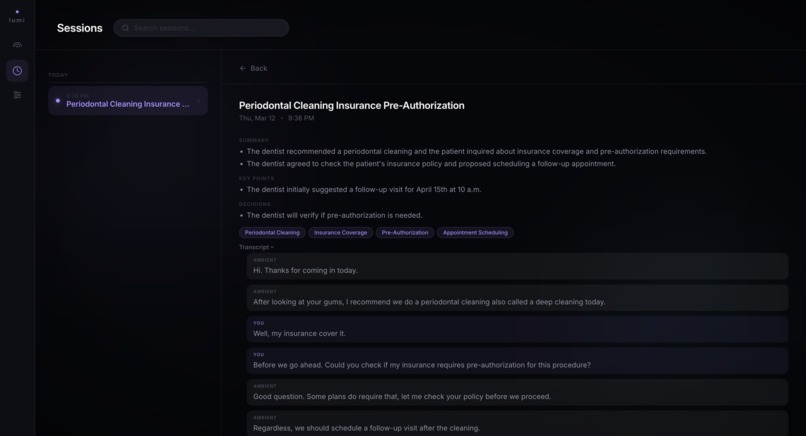
AI-generated session summary: title, key decisions, action items, and topics saved to Firestore at session end
-
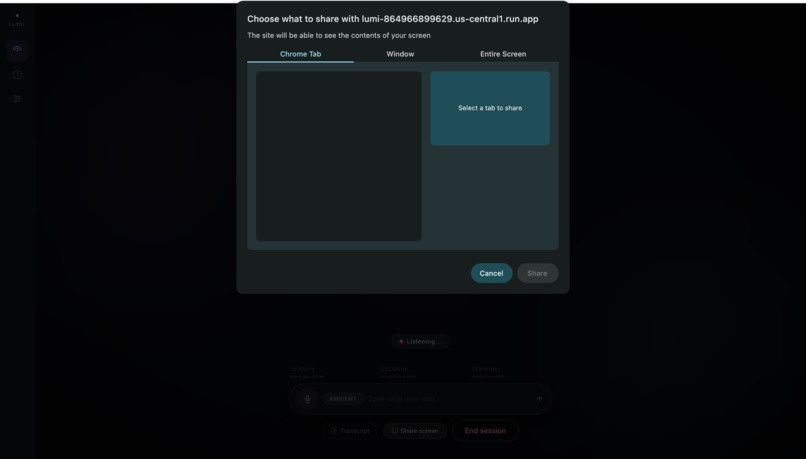
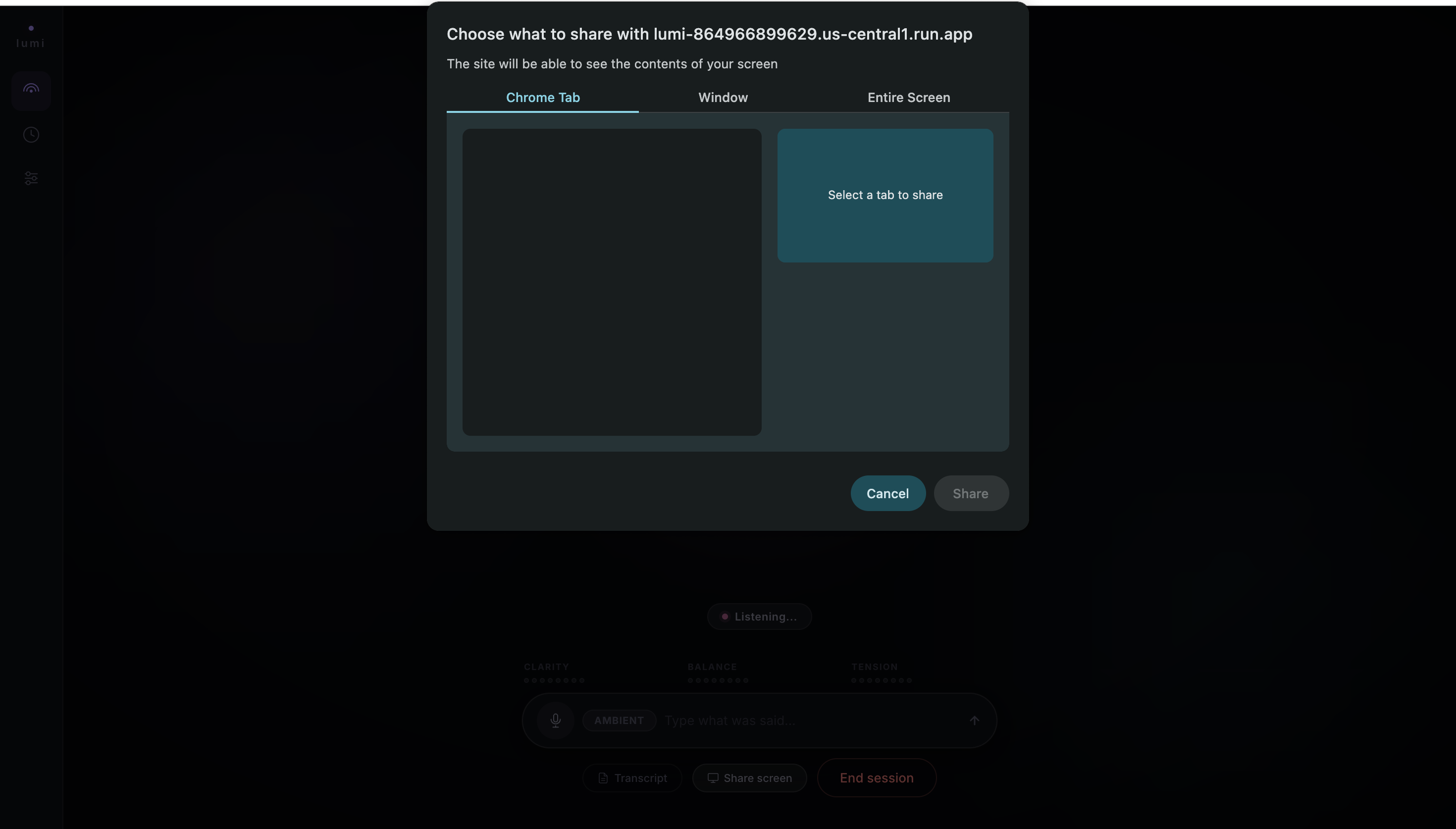
Share any tab, window, or entire screen - Lumi sees exactly what you see and answers questions about on-screen content
-
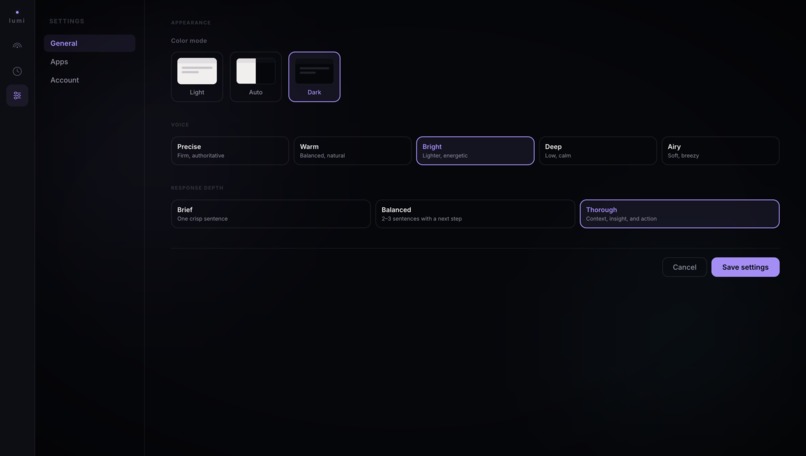
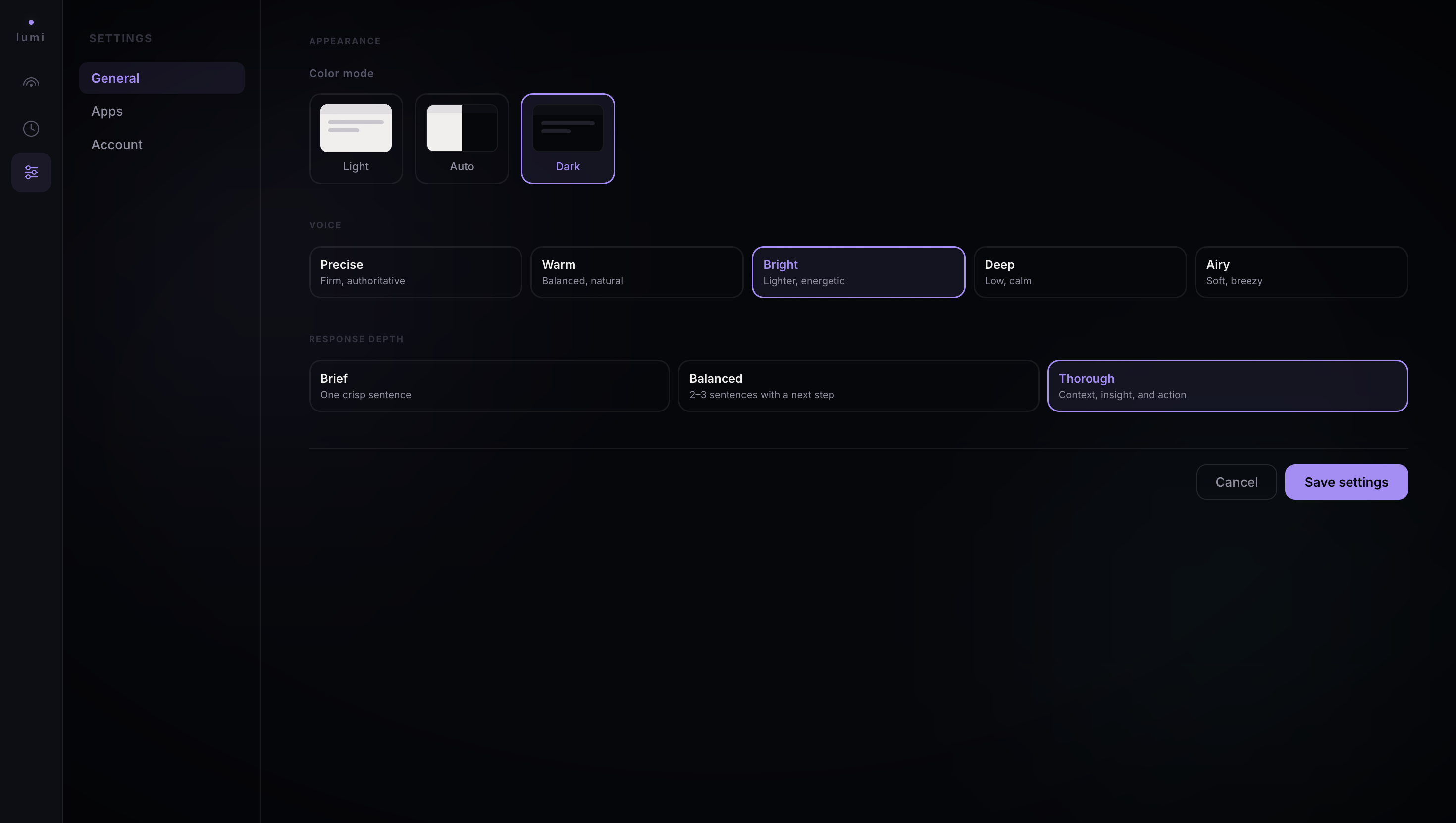
Customize Lumi's voice persona, color mode, and response depth - Brief, Balanced, or Thorough
-
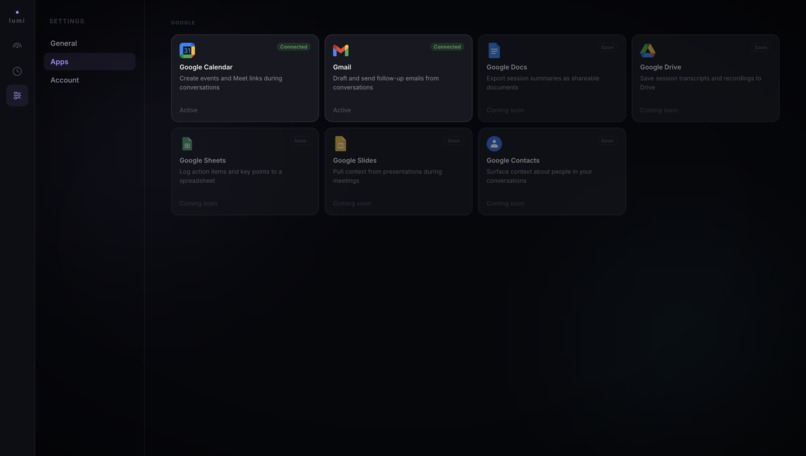
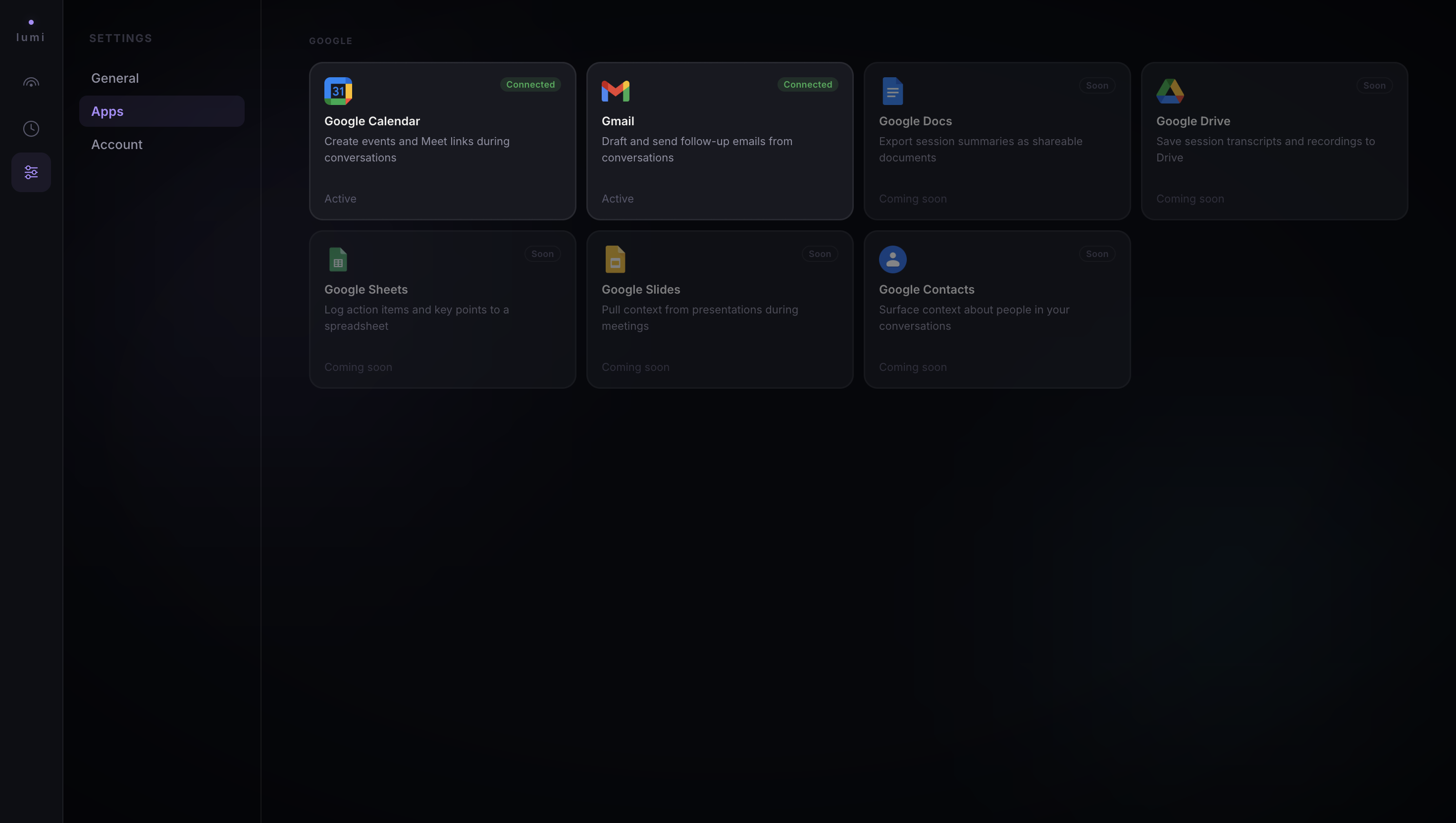
Google integrations panel - Calendar and Gmail connected via OAuth2; Docs, Drive, Sheets coming soon
-
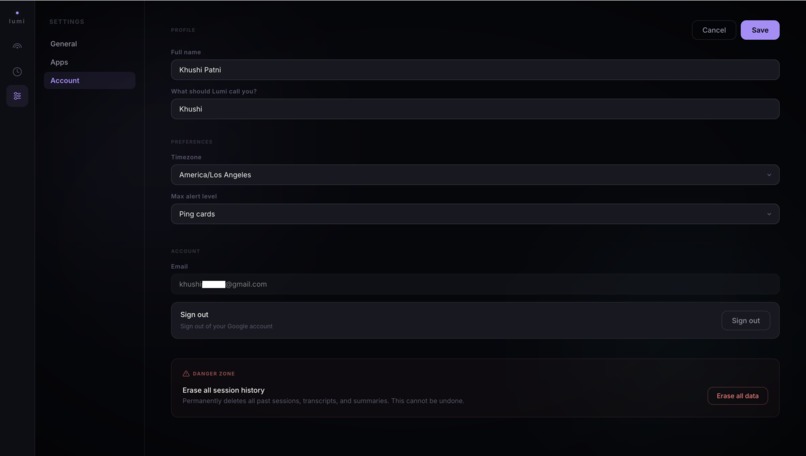
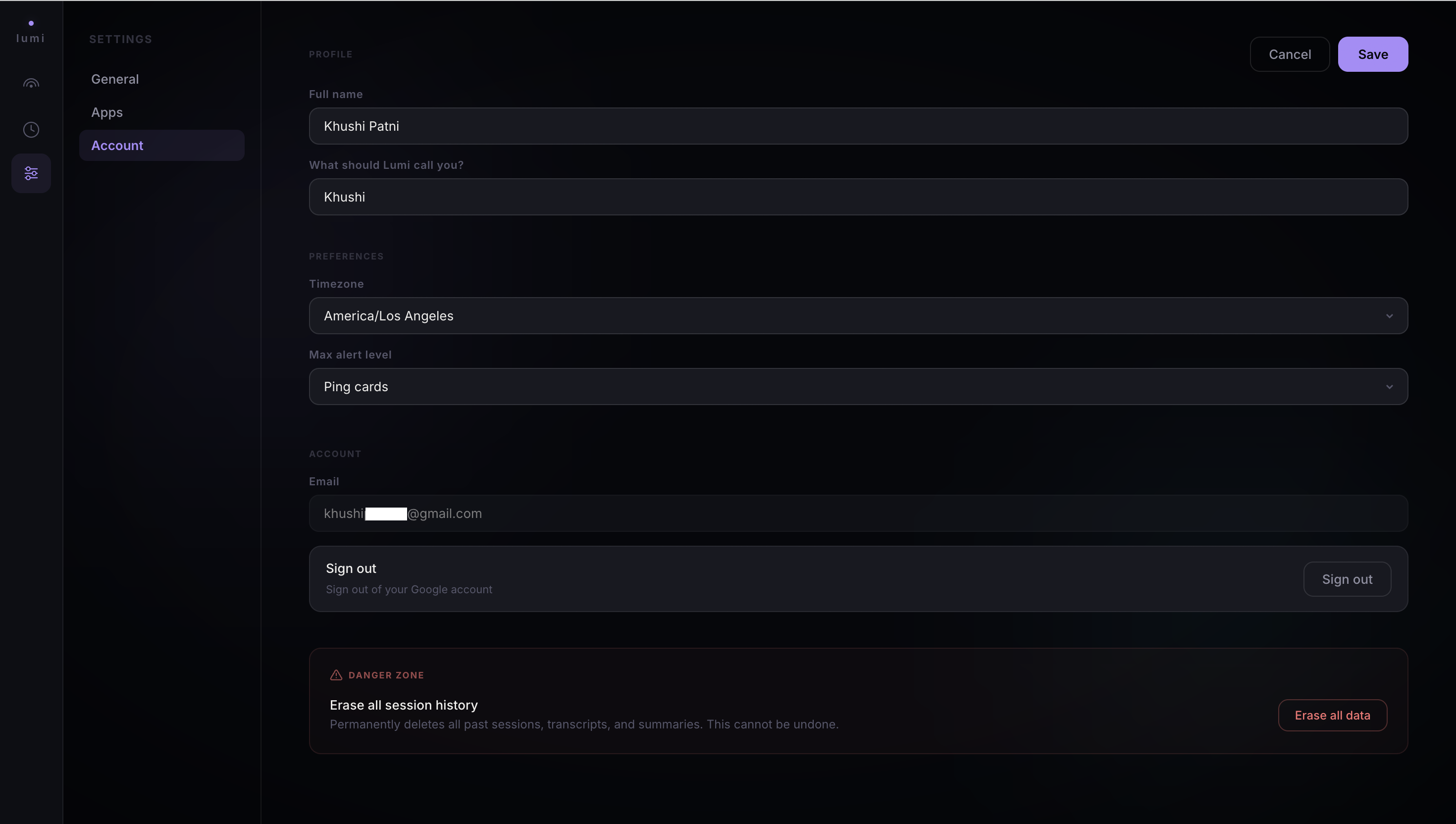
Account settings - profile, max alert level, timezone, and danger zone for wiping session history

Inspiration
Most AI assistants are reactive: you stop what you are doing, open a tab, and ask for help. But in a doctor’s appointment, a negotiation, or a job interview, you do not get to pause the moment to type a prompt.
I wanted to build an assistant that could exist inside a live conversation: present without being intrusive, helpful without being disruptive. That became the core design principle behind Lumi:
Lumi knows when to stay silent.
What it does
Lumi is a real-time ambient intelligence layer for live conversations.
It can:
- listen through your microphone and separate speakers in the room,
- see your screen and use the latest on-screen context to understand forms, documents, and webpages in real time,
- decide how to intervene on a spectrum from silence, to a subtle card, to a whisper, to a full spoken response,
- take action by creating Google Calendar events, Meet links, and Gmail drafts,
- ground its nudges with Google Search before surfacing them,
- and handle interruption naturally, so you can cut it off mid-response just like in a real conversation.
What makes Lumi different is that it does not just decide what to say, it decides how to show up in a way that fits the social context of the moment.
The goal is not to talk constantly. The goal is to help at the right moment, in the right way.
How I built it
Lumi works because it uses two brains in parallel.
One brain listens. With the Gemini Live API, Lumi streams raw audio in real time, stays aware of the conversation, and supports natural barge-in.
The other brain thinks. Frequently, Gemini 2.0 Flash reviews the transcript and decides whether Lumi should step in. When it does, Gemini 2.5 Flash TTS delivers the response as speech in under a second.
I kept these two brains separate on purpose. The listening brain is optimized for live presence and responsiveness. The thinking brain is optimized for structured reasoning and decision-making. Trying to make one model do both created friction; separating those responsibilities made Lumi much more effective.
Lumi also supports screen-aware assistance. The latest shared screen frame is injected into each analysis pass, so when a user says, “Lumi, look at this form,” Lumi already has the visual context.
I also built Lumi around grounded assistance. Before surfacing high-stakes nudges, it checks external context through Google Search so interventions are not based only on model intuition.
Under the hood, Lumi runs on Google Cloud Run, with Firestore for state, Firebase Auth for identity, and OAuth 2.0 integrations for Google Calendar and Gmail.
Challenges I ran into
The biggest challenge was designing for timing, not just intelligence. In a live conversation, even a useful response can feel wrong if it arrives at the wrong moment. I had to figure out how Lumi could be helpful without becoming disruptive.
I was also building across multiple real-time layers at once: live audio, transcription, grounding, reasoning, voice output, and actions. Getting those pieces to work was one challenge; getting them to feel seamless was another.
A deeper challenge was restraint. I did not want an assistant that reacted to everything. I wanted one that understood that sometimes the best intervention is no intervention at all.
I had to actively design against over-helpfulness. A good ambient assistant should not repeat itself, overreact, or turn every conversational signal into an action.
On the engineering side, many of the hardest bugs came from real-time coordination: race conditions between competing outputs, barge-in state management, and making sure screen context helped without hijacking the conversation.
Accomplishments that I'm proud of
I am proud that Lumi feels less like a chatbot with a microphone and more like a genuinely live assistant.
The moment that best captures the project is when you are in the middle of a conversation, not thinking about Lumi at all, and it quietly surfaces exactly the information you needed. No prompt. No interruption. Just help at the right moment.
I am also proud that Lumi is silent most of the time. That is not a limitation; it is the product philosophy. Building an assistant that knows when not to speak is harder than building one that talks constantly.
Finally, I am proud that Lumi demonstrates a believable new interaction model for AI: one that is ambient, context-aware, multimodal, and woven into real conversations.
What I learned
I learned that the hardest part of building a real-time AI assistant is not generation, it is judgment.
A useful assistant has to understand timing, relevance, and social context. It has to know when to speak, when to verify, when to act, and when to stay out of the way.
I also learned that ambient AI is as much a systems and product design problem as it is a model problem. Users do not experience transcription, reasoning, grounding, and actions as separate components; they experience one assistant. Making that feel coherent was one of the biggest lessons of the project.
Most of all, I learned that real-time AI is not just about responsiveness; it is about restraint. An assistant that can act, speak, search, and schedule is only useful if it can also decide when not to do those things. That is what makes ambient AI feel less like better chat and more like something that can participate naturally in the flow of real life.
What's next for Lumi
Right now, Lumi helps during the conversations you are actively having. The next step is helping with the conversations and commitments forming around you as well.
I want to make Lumi more proactive and more personalized: noticing when you are about to agree to something that conflicts with your calendar, turning action items from a conversation into follow-up drafts automatically, and extending the experience beyond the laptop through a mobile companion.
The current version listens to your conversations. A future version could also listen to the ones you are not in directly, like an important Slack thread, a scheduling email in your inbox, or a calendar change happening in the background, and surface what actually matters before you even think to ask.
The longer-term vision is an intelligence layer that runs quietly alongside your life, present, helpful, and socially aware, without demanding your attention.
Built With
- artifact-registry
- audioworklet
- cloud-build
- fastapi
- firebase-authentication
- firestore
- gemini-2.0-flash
- gemini-2.5-flash-tts
- gemini-live-api
- gmail-api
- google-adk-(agent-development-kit)
- google-calendar-api
- google-cloud-run
- google-cloud-stt
- google-search-grounding
- imagecapture-api
- javascript
- python
- text-embedding-004
- vertex-ai
- webrtc
- websocket



Log in or sign up for Devpost to join the conversation.