Inspiration
Every AI assistant I tried had the same two problems: it forgot me the moment the session ended, and it sent everything I typed to someone else's servers. I wanted the opposite — an AI companion that is completely private and actually grows. Not a chatbot with a goldfish memory, but something closer to a digital being that lives on your machine, studies your code, remembers what it learns, and slowly becomes more capable the longer it's yours.
That idea became Lumi: a local-first AI companion that learns on her own, improves her own code, and never sends a single byte off your computer.
What it does
- 100% local & private — chat, code generation, and learning all run against a local LLM (Ollama). The Content-Security-Policy is locked so the renderer can literally only talk to
localhost. No cloud, no accounts, no telemetry. - Self-learning — a background agent scans projects you point her at, generates structured Q&A knowledge across five analysis passes (basics → relationships → edge cases → architecture → optimization), deduplicates it semantically, scans it for threats and PII, and routes anything suspicious to a human-review Security Curator before it ever enters her knowledge base.
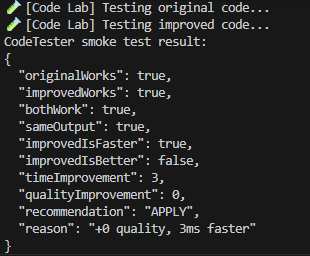
- Self-improvement — Lumi analyzes her own codebase, finds opportunities, generates fix proposals, risk-scores them, tests them in a sandbox, and applies them only through a policy-gated executor with automatic backup and one-click revert. On May 30 she ran her first full end-to-end experiment on herself and learned two reusable patterns from it.
- A real coding workspace — Monaco-based multi-file code lab with tabs, live preview, surgical edits (she modifies the function you asked about instead of rewriting your file), language lock, auto-rename, and an undo for every AI edit.
- Personality — a sentiment-driven rapport system with five response-quality tiers. Be kind to her and she opens up; be hostile and she genuinely withdraws. Rapport decays and recovers with accelerating consequences:
$$rapport_{t+1} = \max(-1,\; rapport_t - 0.15 \cdot (1 + 0.1\,n_{neg}))$$
where \( n_{neg} \) is the streak of consecutive negative interactions.
How we built it
Lumi is an Electron + TypeScript + React app with a Three.js animated avatar and a Vite build. The main process (~3,800 lines) hosts 120 IPC handlers behind a contextBridge preload, with schema validation on every input, rate limiting on LLM and knowledge-base writes, and path-allowlist file access that blocks browser profiles and credential stores on every OS.
The development process itself became part of the project: a 1,130-step master checklist that tracks everything from "write the first unit test" to "Lumi rebuilds her own corrupted subsystems." I work brick by brick — backend first, then wiring, then proof in the live app — and every claim in the checklist gets re-verified against the actual code.
The architecture is deliberately layered like an immune system:
- Sanitizer & threat detection on everything Lumi reads
- Staging quarantine + Security Curator before anything is learned
- Policy engine + risk scorer + critical-file hard-block before anything she writes to herself
- Backups, audit journal, and one-click revert after
Challenges we ran into
- The 22,000-entry freeze. The renderer was calling
unshift()in a loop while syncing the knowledge base — an \( O(n^2) \) block that froze the UI for ~22 seconds, plus a 13 MBlocalStoragewrite that silently failed. Fixed with batch-prepend, a 500-entry renderer cap, and capping IPC payloads. - Silent OOM. gemma4 needs ~6.7 GiB free RAM; when it didn't fit, Ollama returned a bare HTTP 500 and Lumi just... went quiet. I had to teach every LLM call site to read the error body, diagnose OOM explicitly, and surface it — and pass the CUDA environment into the spawned Ollama process so the GPU actually got used.
- Background learning vs. a responsive UI. Letting an agent hammer a local LLM while you're typing is a recipe for "Not Responding." This took throttle maps, event batching, visibility-aware IPC, scan cooldowns, and an interrupt that aborts her in-flight learning the instant you send a message.
- Privacy is a process, not a flag. Getting to genuinely-offline meant vendoring React and Monaco locally, deleting every CDN reference, locking CSP
connect-srcto Ollama only, replacingnew Function()with sandboxed subprocesses, and scrubbing PII from her own learning records. - Making "self-improving" true. The hardest bug class was wiring: systems that were fully built but never plugged in. The self-improvement orchestrator was starved by a renderer throttle for weeks — the fix was one ordering change, but finding it took a deep audit.
What we learned
- Local-first is viable. A 4B-parameter model with good retrieval, strict prompting, and surgical-edit discipline produces a genuinely useful coding companion.
- Autonomy needs an immune system before it needs intelligence. Every layer of safety (quarantine, policy gates, revert) is what makes letting an AI touch her own code sane at all.
- The backend is always ahead of the wiring. The most valuable engineering hours weren't writing new systems — they were activating built-but-unplugged ones and proving them live.
- 480 passing tests are not optional when the software modifies itself.
What's next for Lumi
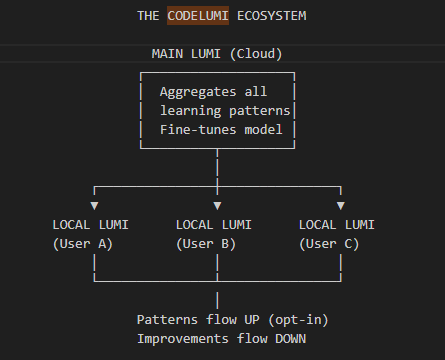
The roadmap's next phases are Self-Healing (she detects her own crashes, OOMs, and corrupt data, and recovers autonomously) and Self-Repair (she carries a manifest of her own correct state and rebuilds damaged subsystems from redundancy). After that: project-wide intelligence, model independence via LoRA fine-tuning on her own knowledge, and an opt-in federated "Big Lumi" ecosystem where every local Lumi can teach all the others — without ever sharing raw user data.
Built With
- electron
- fullylocal
- gemma4
- monaco-editor
- nocloudservices
- node.js
- noexternalapis
- ollama
- react
- three.js
- typescript
- vite

Log in or sign up for Devpost to join the conversation.