-
-
Landing Page
-
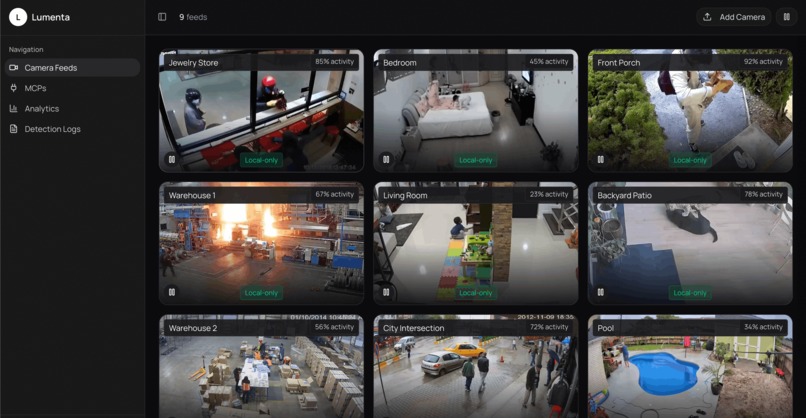
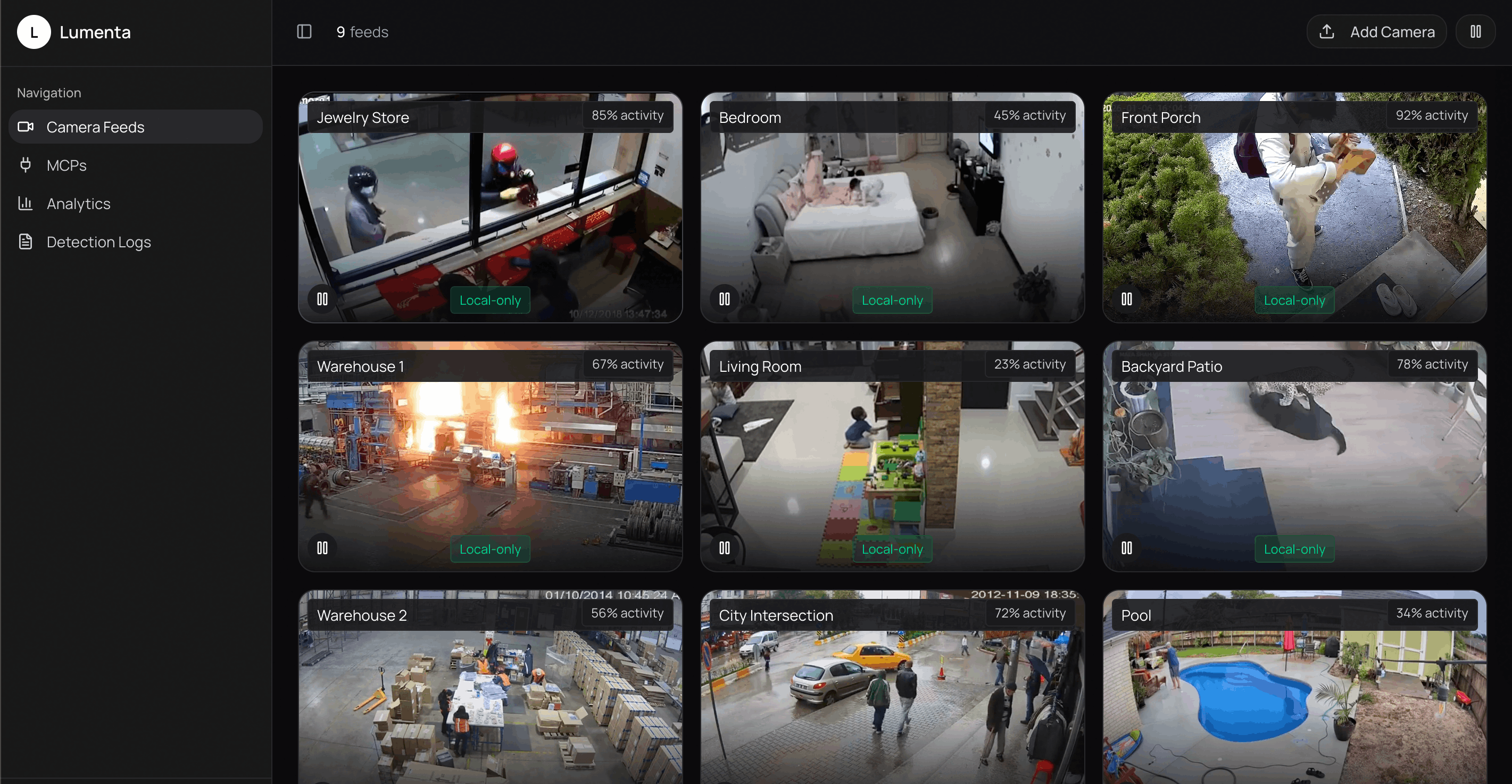
Cameras Feed
-
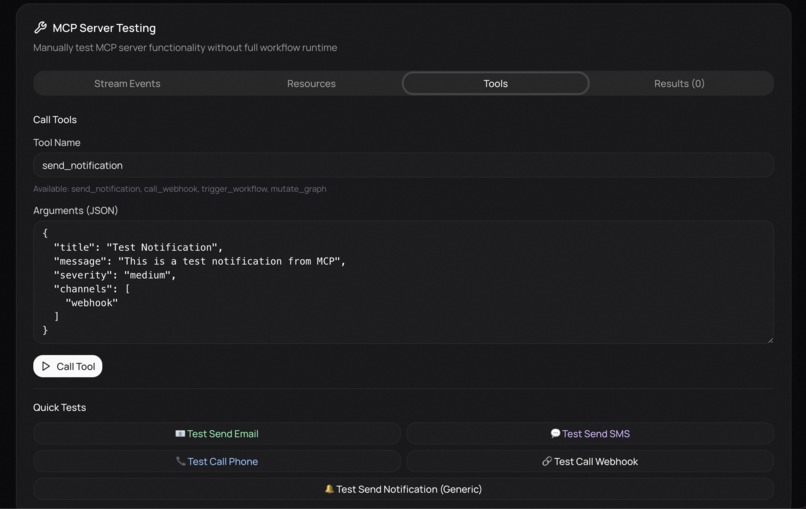
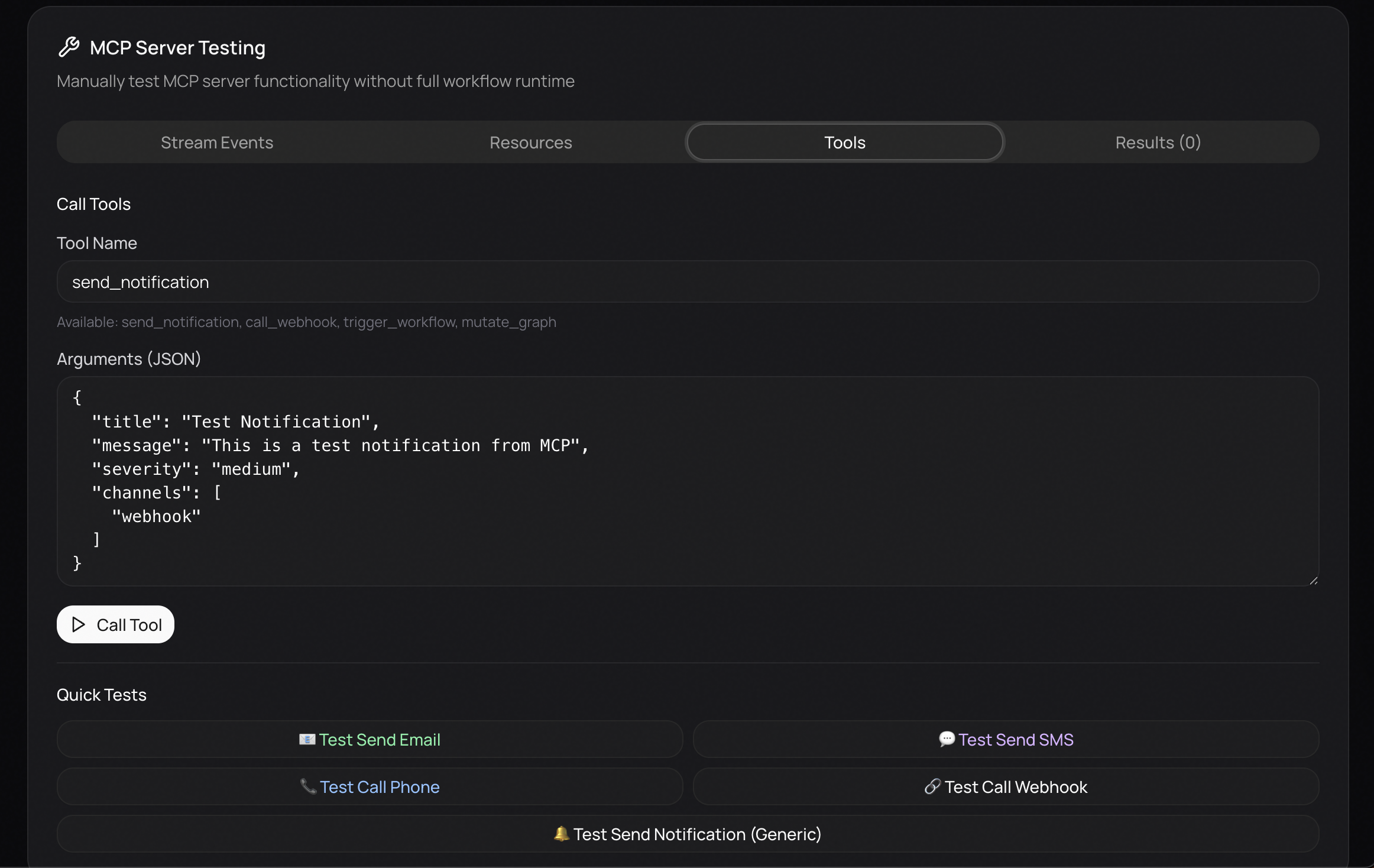
MCP Control Panel
-
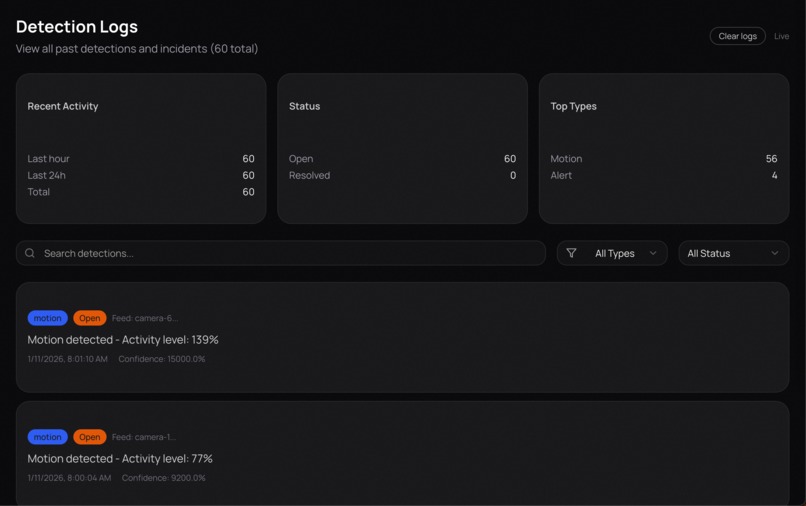
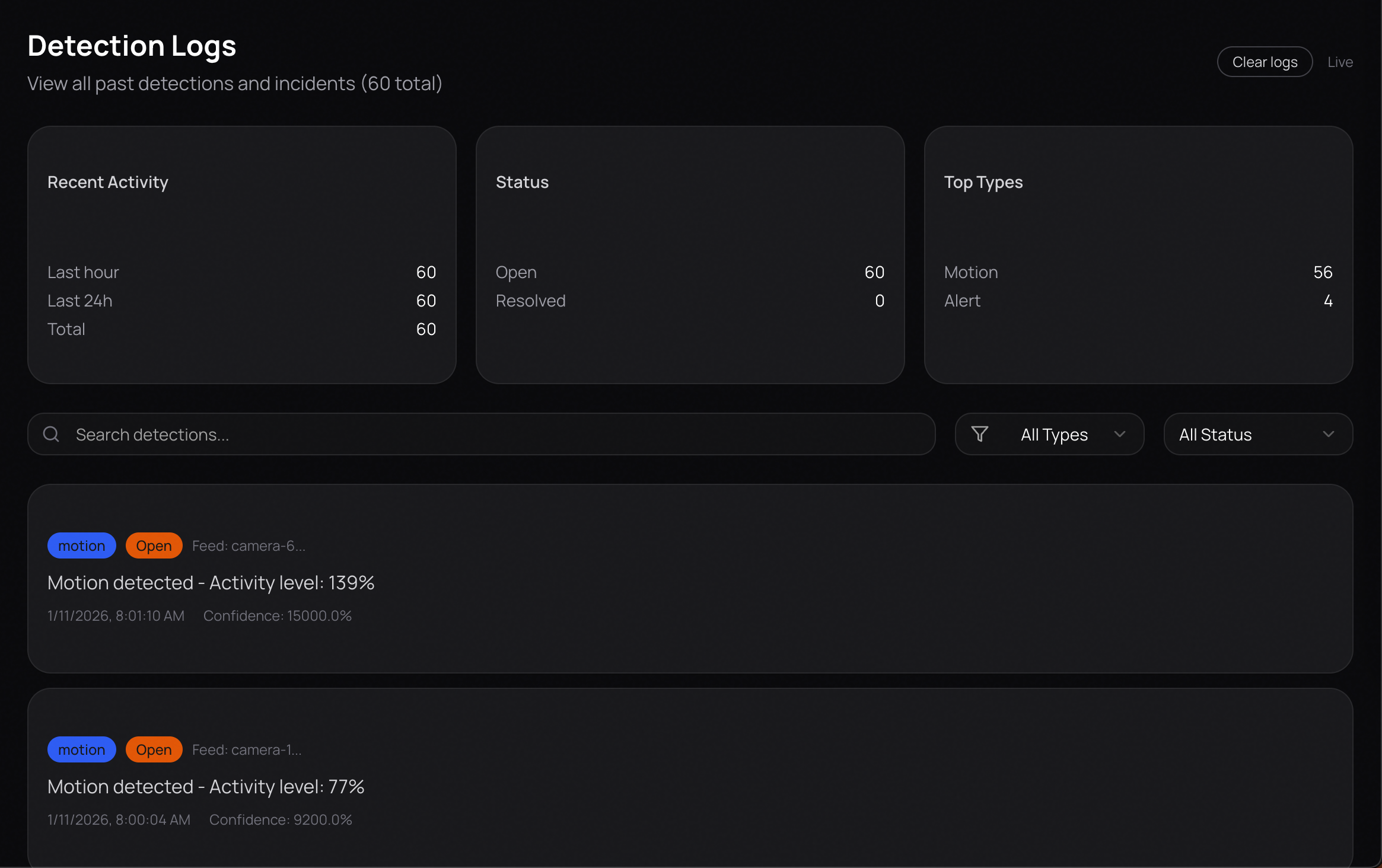
Detection Logs
-
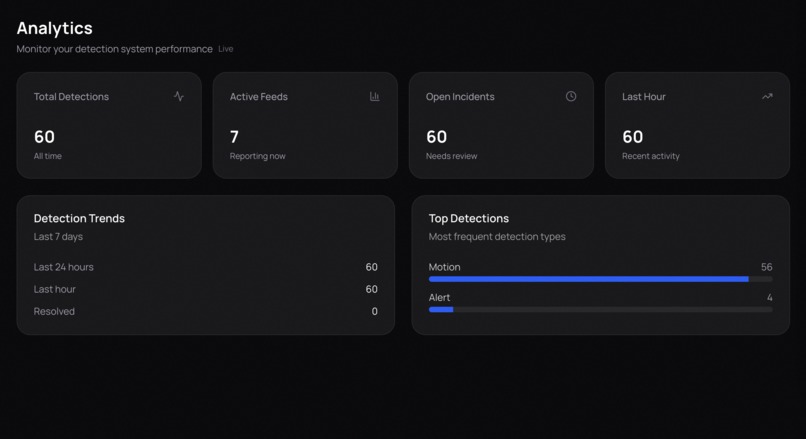
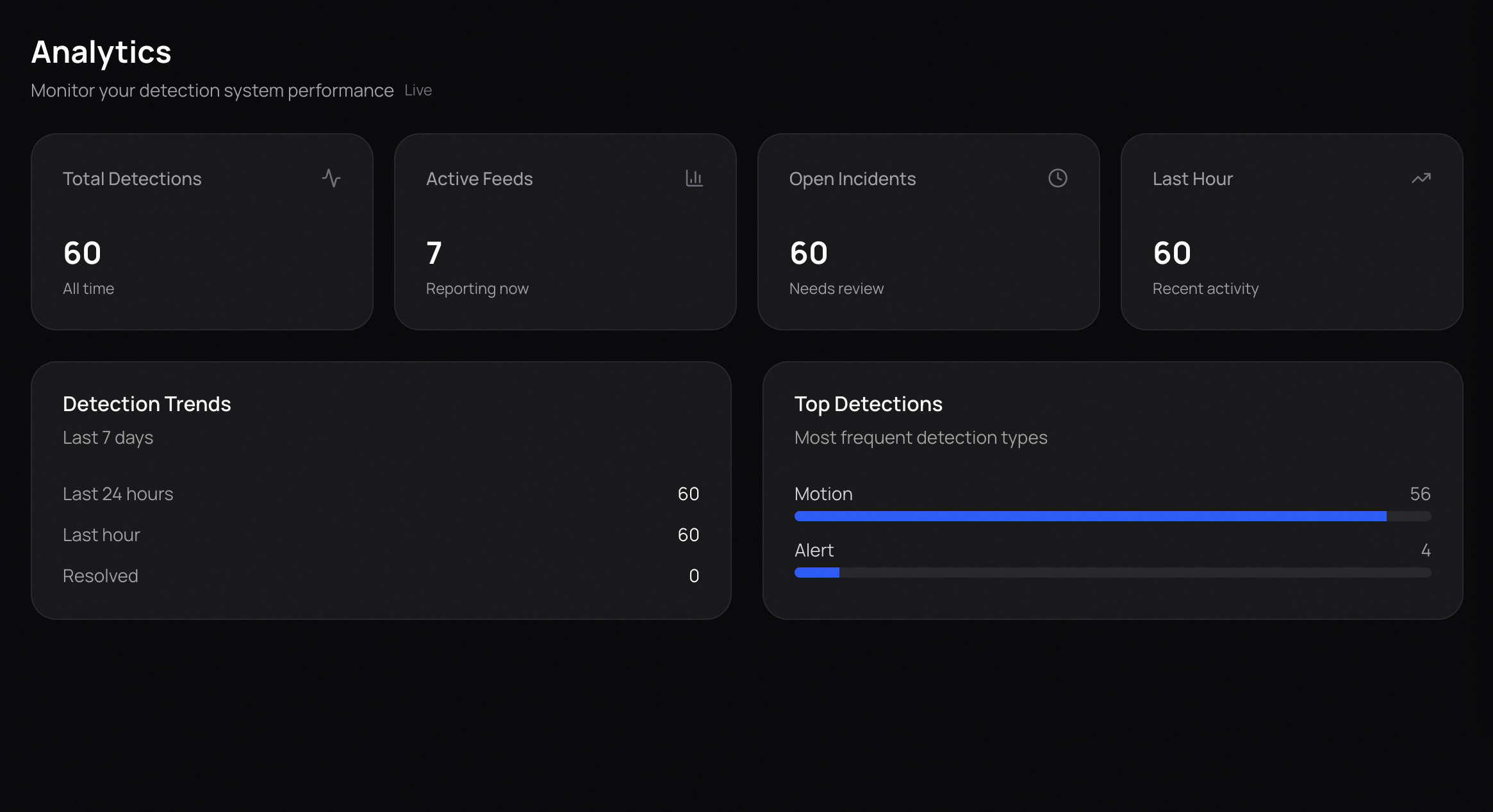
Analytics
What it does
Lumenta is an AI-powered video surveillance platform that monitors multiple camera feeds in real time to detect and respond to security incidents, safety hazards, and notable events. It uses computer vision and AI to analyze both live and recorded video, identifying objects, people, vehicles, and activities across a wide range of environments.
The system processes video frames using YOLOv8 for object detection and Google Gemini for semantic analysis. All detections and incidents are automatically logged to MongoDB, enabling comprehensive analytics and historical review of security events. From this, it extracts meaningful events with associated timestamps and severity levels. These events are displayed in an interactive timeline, appearing only when their timestamps are reached during video playback, which makes reviewing footage faster and more intuitive. Lumenta also features a visual workflow builder that allows users to create node-based automation pipelines. Analyze nodes monitor for specific conditions such as robberies, falls, or package theft. When these conditions are detected, action nodes are automatically triggered to send phone calls, emails, or text messages to designated recipients. Gemini is used to interpret natural language descriptions and route actions to the correct services through the Model Context Protocol (MCP).
Whether it is monitoring a jewelry store for theft, a bedroom for child safety, a front porch for package security, or a warehouse for potential hazards, Lumenta functions as an automated security system that is always watching, intelligently analyzing activity, and responding immediately when critical events occur.
How we built it
We built a full-stack web application using Next.js with the App Router and Turbopack to support real-time video processing and a responsive monitoring dashboard. The detection pipeline relies on YOLOv8 models running through ONNX Runtime Web to track objects and people across multiple camera feeds, performing frame-by-frame analysis to enable immediate detection. Speed and responsiveness are critical in security scenarios because even small delays can lead to missed incidents or slower responses. To address this, we implemented persistent storage using MongoDB Atlas to maintain a comprehensive database of detection logs, incidents, and session summaries. This allows the system to track historical events, generate analytics, and provide detailed audit trails of all detected activities across camera sessions. In addition, we built local motion detection using Canvas 2D and pixel-difference algorithms, which generate real-time motion overlays and provide instant visual feedback without waiting for AI inference. Video frames are processed in parallel, with YOLOv8 running on-device for low-latency object detection while the Gemini API performs higher-level semantic analysis in the background.
Every component was designed with real-time performance, clarity, and reliability in mind. This includes the custom node graph interface that allows users to connect analyze nodes and action workflows, as well as the event timeline that displays detections and alerts as they happen. The system continuously streams events to the Model Context Protocol (MCP) server, enabling autonomous AI orchestration that can automatically trigger phone calls, emails, or text messages when critical events are detected, ensuring alerts reach the right people at the right time.
Challenges we ran into
The most significant challenge we faced was designing a reliable video ingestion and analysis workflow capable of accurately detecting events based on custom, user-defined prompts. Early in development, we experimented with OpenCV-based techniques and ArcFace for detection and recognition. While these approaches worked for simple cases, they struggled with consistency and lacked the contextual understanding needed to handle complex, real-world scenarios.
To overcome these limitations, we transitioned to a pipeline built around YOLOv8 running via ONNX for robust object and person detection, combined with Google Gemini for deep semantic reasoning. This shift was critical. YOLOv8 provided fast and accurate low-level detections, but it was Gemini that enabled the system to truly understand what was happening in the scene. Gemini is relied on heavily throughout the entire project, serving as the core intelligence layer that interprets detections, evaluates custom prompts, assigns severity, and determines whether an event should be triggered.
Another challenge was ensuring that Gemini-driven analysis could scale without introducing latency. Since semantic reasoning is central to Lumenta’s functionality, we carefully designed the pipeline to run object detection locally and in parallel, while Gemini processes higher-level reasoning asynchronously. This balance allowed us to maintain real-time responsiveness without sacrificing accuracy or contextual understanding.
Accomplishments that we're proud of
One of our biggest accomplishments was successfully building a reliable and accurate workflow engine after multiple iterations and early setbacks. Designing a system that could correctly interpret custom prompts, trigger the right analyze nodes, and execute the appropriate actions proved far more complex than expected. Additionally, we built a robust data persistence layer using MongoDB that automatically captures and organizes detection logs, session summaries, and incident reports, enabling powerful analytics and long-term trend analysis. Through extensive refinement, testing, and tighter integration between detection, semantic reasoning, and automation logic, we achieved a workflow engine that behaves consistently and accurately in real-world scenarios.
We are also proud of the system’s integration with the Model Context Protocol (MCP). Events are streamed continuously to the MCP server, allowing AI-driven orchestration to operate autonomously and in real time. This enables seamless execution of actions such as phone calls, emails, and text messages the moment critical events are detected, without manual intervention.
What we learned
We gained valuable experience building real-time computer vision systems using models like YOLOv8, including how to optimize detection pipelines for low latency and accuracy. We also learned how effective the Model Context Protocol (MCP) can be as an orchestration layer, allowing detection, reasoning, and automated actions to work together cleanly and reliably. Most importantly, we learned the importance of combining fast visual perception with higher-level semantic reasoning to build systems that understand context and respond intelligently.
What's next for Lumenta
Next, we plan to expand Lumenta’s detection capabilities with more advanced event types and long-term behavior analysis across camera feeds. We also aim to improve edge processing so more analysis can run locally for lower latency and increased privacy. Future iterations will deepen integrations with external services and emergency response systems through MCP, enabling even faster and more coordinated automated responses as the platform scales.
Built With
- gemini
- mcp
- next.js
- onnx
- yolov8






Log in or sign up for Devpost to join the conversation.