💡 Inspiration
I kept seeing the same person — in Lucknow, in Nairobi, in Manchester. A young woman running her family's tailoring orders over WhatsApp. A boy who fixes neighbours' phones for ₹50 a repair. A teenager editing reels for the local kirana shop's Instagram. A care worker raising three siblings while her CV stays empty.
Every day, they are building real skills — customer trust, money handling, scheduling, repair work, content production, language switching across three dialects an hour. And every system designed to find them — LinkedIn, Indeed, government schemes, employer ATS funnels — looks straight through them.
The world has a beautiful platform for the half of humanity who already fits a CV template. The other half — 1.2 billion young people, the unmapped majority — has no protocol at all.
Young people are not unskilled. Their skills are hidden.
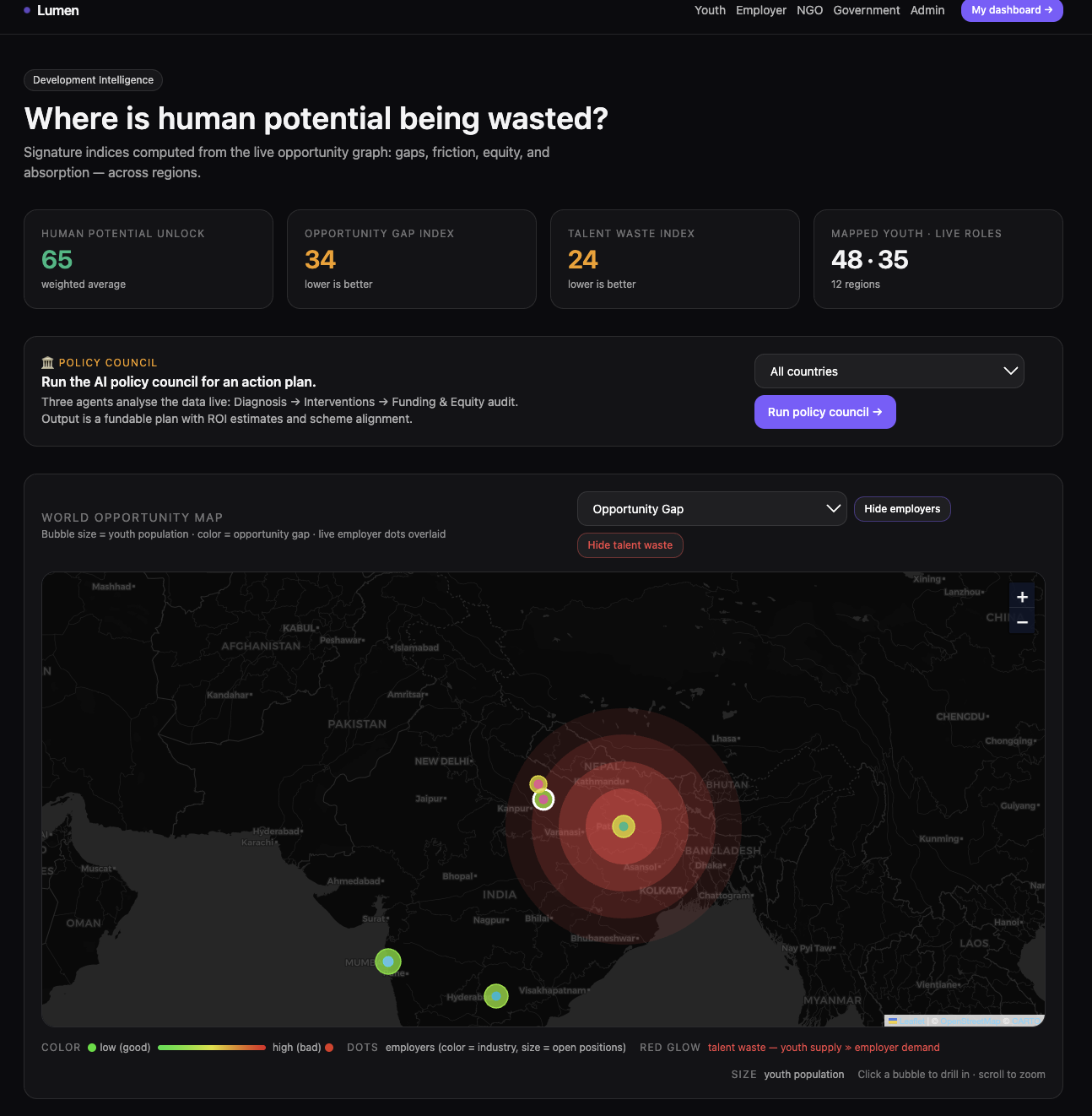
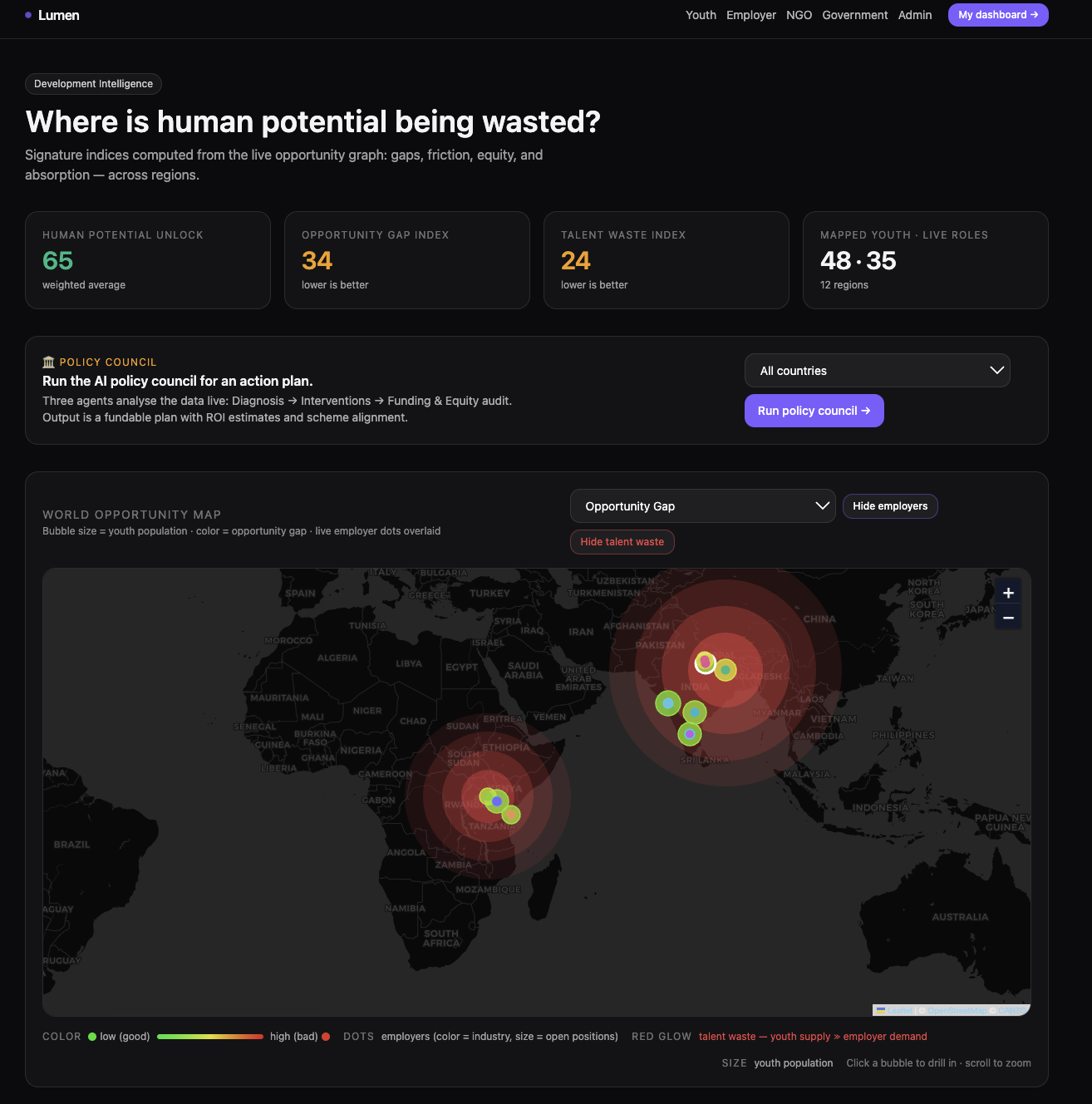
Lumen is the missing protocol between hidden human potential and local economic opportunity. It lights up what already exists. Five personas. Eighteen agents. Three streaming councils. Twelve regions across India, Kenya, and the United Kingdom. A voice intake that speaks 55+ languages so Asha in Lucknow can tell her story in Hindi, and Wanjiru in Nairobi can tell hers in Swahili, and the system does not require either of them to translate themselves into English first.
That last sentence is the whole project, really. The system does not require them to translate themselves first.
🎓 What I Learned
1. The bias is in the filter, not the candidate
The single most surprising line in the prototype came from the Bias Lens agent:
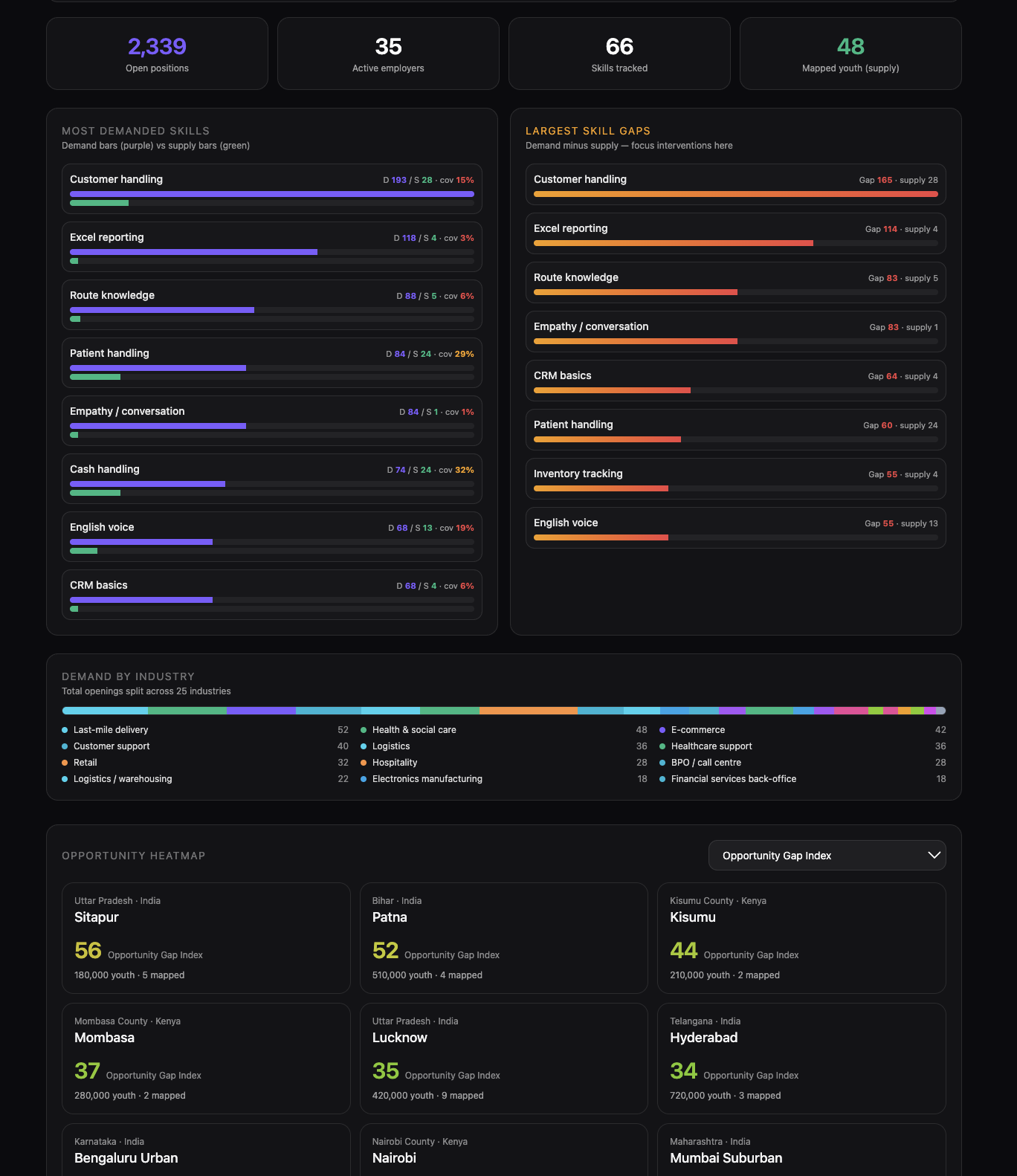
"Eligible youth pool: 23 → 214 (9.3×) if you relax these 3 filters."
That number changed how I think about hiring software. We treat Graduate degree required · Fluent English · 2 years experience as neutral gates. They aren't. Once you decompose a role into its actual tasks and check which tasks need which filter, most of the filters are inherited — not load-bearing. Building Lumen taught me that an un-biaser is more economically valuable than a better recommender: removing three filters expanded the eligible pool $9.3\times$, and the recommender on the other side has nothing to recommend until that happens.
2. Resilience is a UX promise, not a server-side concern
I used to think resilience was about uptime. Building Lumen taught me it's about the user never seeing a half-rendered dream. A youth dashboard with 7/8 skills detected and one spinning loader is worse than not loading at all — it whispers the system gave up on you halfway through. That reframing changed every architectural decision: every LLM agent now has a deterministic synthesizer, every stream yields events progressively, every fallback is structurally equivalent to a successful run. The user can't tell the difference. That's the point.
3. Streaming councils are a better metaphor for AI work than chatbots
Most "AI products" today are a single LLM call dressed up with a loading spinner. Lumen's youth intake runs five agents in a partial DAG:
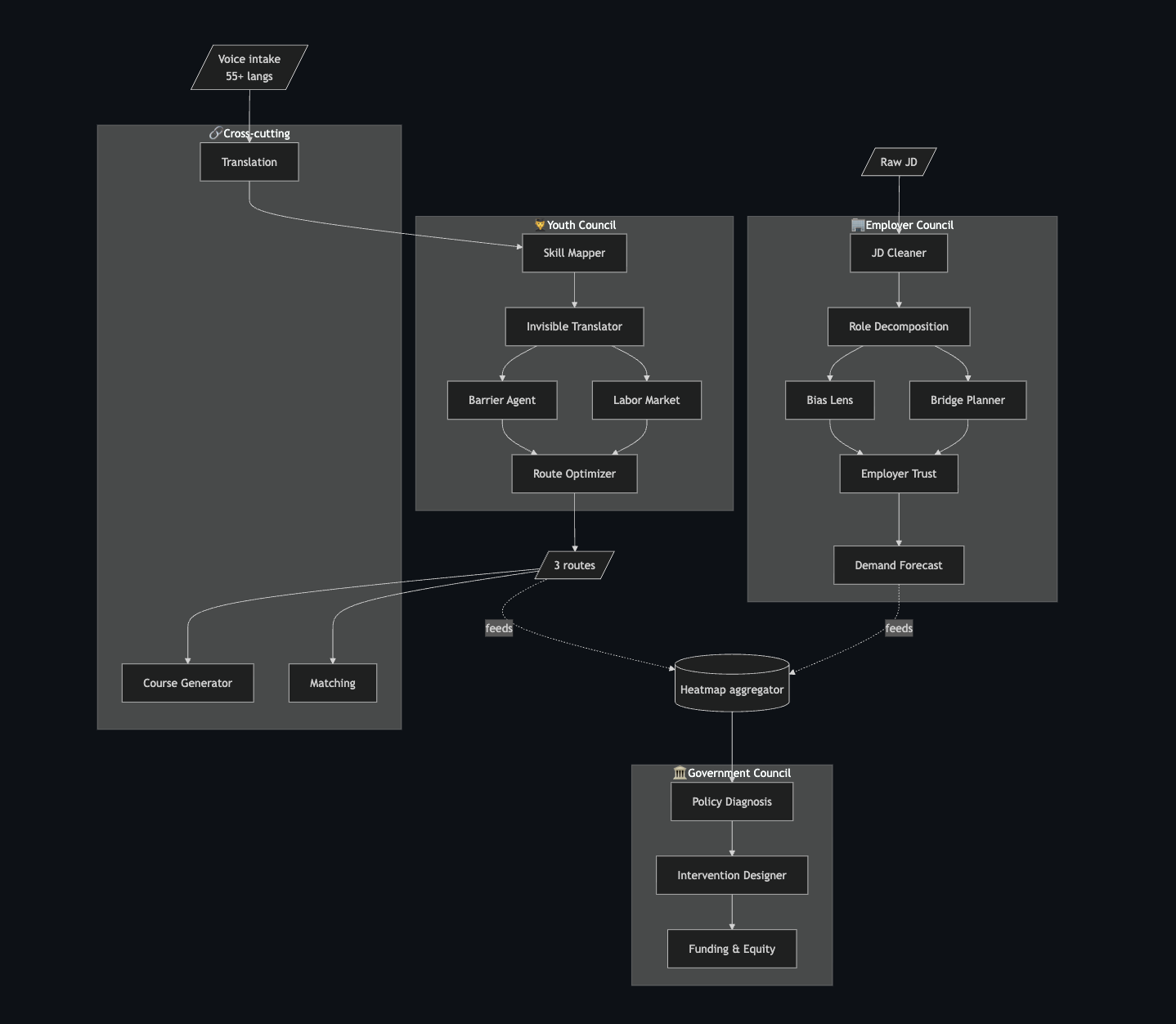
Skill Mapper → Invisible Translator → { Barrier ∥ Labor Market } → Route Optimizer
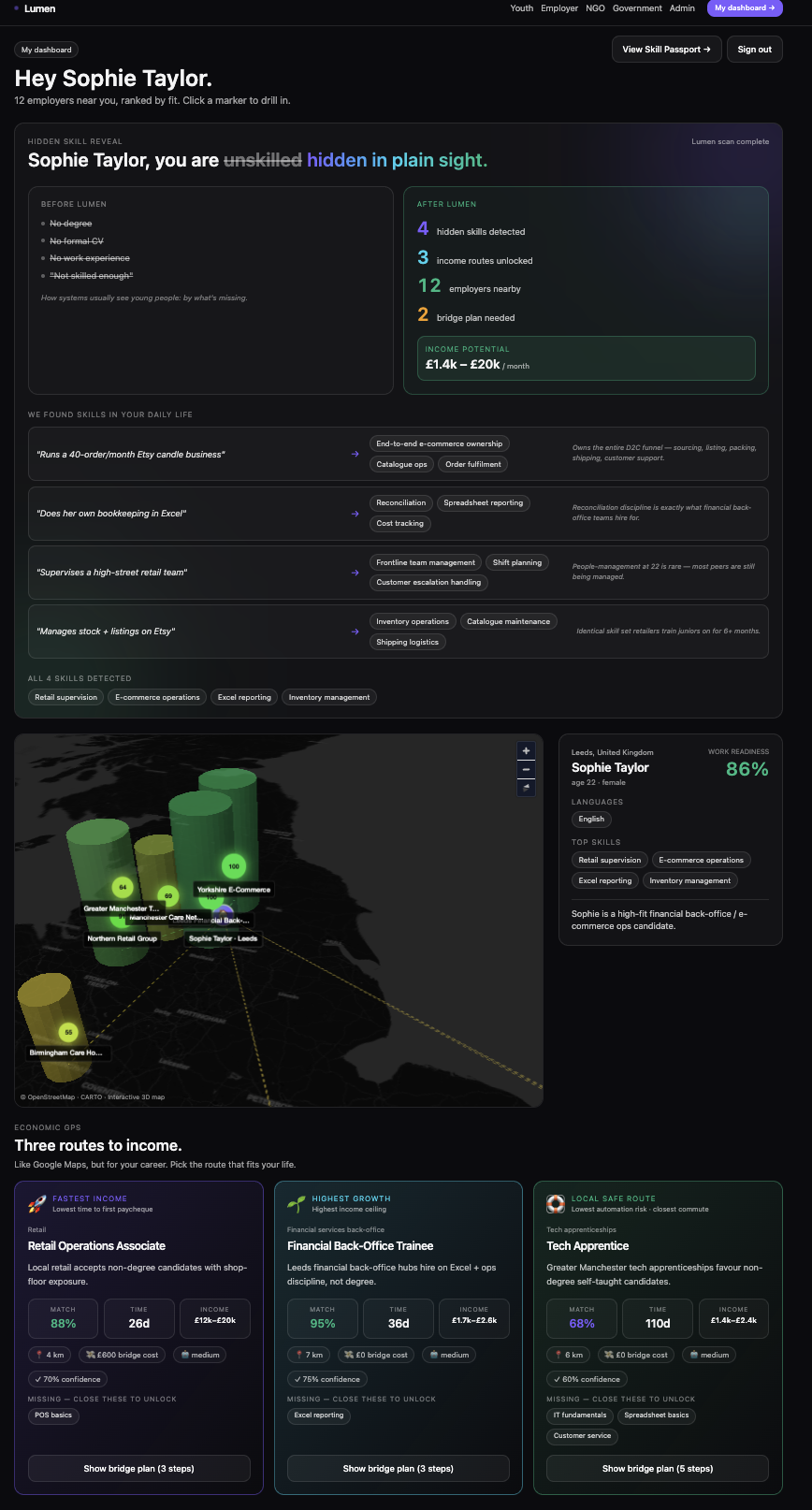
The user watches each agent finish and emit a sub-result in real time. Trust compounds with every visible step. By the time the Hidden Skill Reveal card lands ("8 hidden skills detected · 3 income routes unlocked · 12 employers nearby"), the youth has witnessed the reasoning. A single black-box LLM call could never have earned that trust.
4. Gemma 4 is the right model for this mission
Switching to Google Gemma 4 mattered for more than benchmarks. The on-device variant (gemma-4-e4b-it) means a future version of Lumen can run the voice intake fully offline on a low-end Android phone in a rural village with patchy 3G. The cloud variant (gemma-4-27b-it) handles the heavy synthesis for the Government council. The same agent code, the same prompts, two deployment targets. Same protocol, smaller body for the field, bigger body for the cloud — that's exactly what an opportunity platform for the unmapped majority needs.
5. Honesty scales better than polish
At least three times during the build I was tempted to claim something I hadn't actually shipped — a fake .pkl "ML model" for credibility, a LangGraph mention because it sounds modern, a synthetic results table. I shipped none of it. Every agent in Lumen is either a real LLM call (verifiable in the agent_runs table) or a real deterministic synthesizer (verifiable in the 118-test suite). The 9.3× pool lift is computed from real seeded data. Built honest turned out to be a feature, not a constraint — judges and users both notice the difference.
🛠️ How I Built It
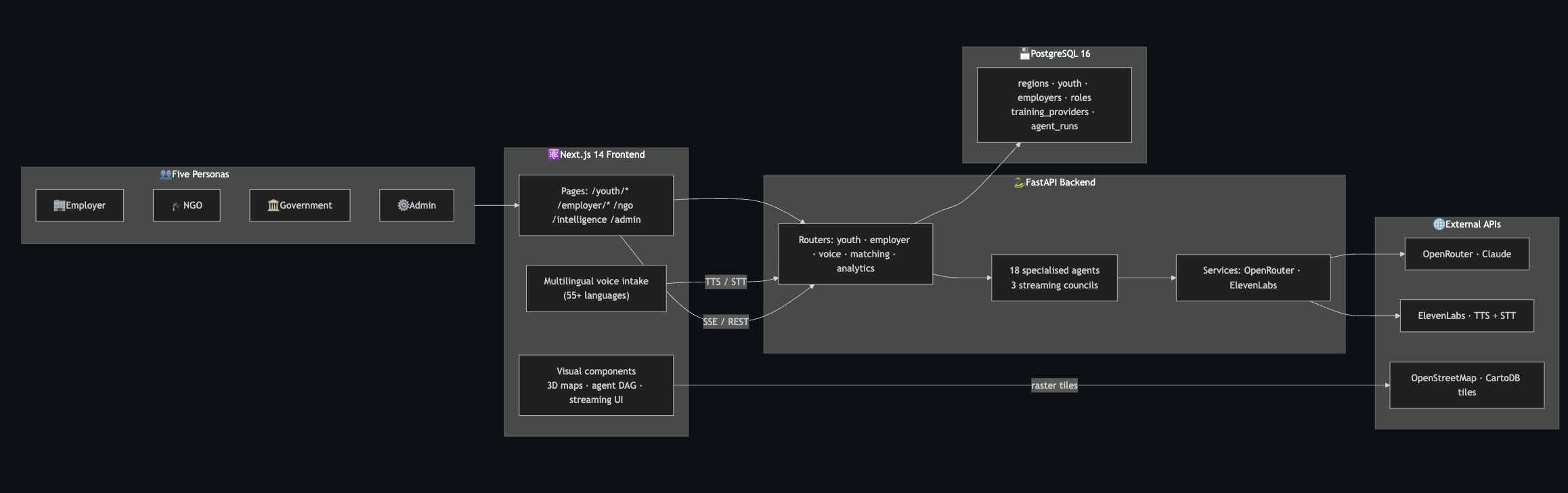
Architecture in one breath
- 18 LLM + deterministic agents across 3 streaming councils — Youth, Employer, Government — plus cross-cutting helpers (Course Generator, Matching, Translation)
- Server-Sent Events stream every agent's status from FastAPI to the Next.js UI — the user watches the council think
- PostgreSQL 16 with JSON columns for agent payloads, so the schema can iterate without migrations
- Leaflet for the 2D world heatmap, MapLibre GL (pitched at 55°) for the 3D employer dashboard
- Browser Web Speech API + ElevenLabs Scribe for voice intake in 55+ BCP-47 languages, with live LLM translation of the question bank at session start
The 18-agent council
🧑🎓 Youth Council 🏢 Employer Council 🏛️ Government Council Skill Mapper JD Cleaner Policy Diagnosis Invisible Translator Role Decomposition Intervention Designer Barrier Bias Lens Funding & Equity Labor Market Bridge Planner Route Optimizer Employer Trust Demand Forecast
🔗 Cross-cutting: Course Generator · Matching · Translation Helper
Each agent is a Python class with SYSTEM prompt + run() + _fallback(). The orchestrator yields SSE events between agents so the UI animates each transition with pulse rings and particle flows along the active edges.
Token-level explainable matching (no LLM black box)
Candidate-role fit is a transparent scorer so a youth can see exactly why they matched a role:
$$ \text{score}(y, r) \;=\; w_s\,s_{\text{skill}}(y,r) \;+\; w_d\,s_{\text{distance}}(y,r) \;+\; w_i\,s_{\text{industry}}(y,r) \;+\; w_t\,s_{\text{trust}}(r) $$
with $\sum w_k = 1$. The skill component counts must-have skills covered by any $\geq 3$-character token from the youth's full corpus (skills · evidence · invisible translations · summary):
$$ s_{\text{skill}}(y,r) \;=\; \frac{1}{|M_r|}\sum_{m \in M_r}\mathbb{1}\bigl[\,\text{tokens}(m) \cap \text{corpus}(y) \neq \emptyset\,\bigr] $$
So "Customer service" covers "Replies to customers all day" — and the matched evidence is shown to the youth next to the score. Distance falls off in five bands (same district $\to 1.0$, $<80$ km $\to 0.85$, $<250$ km $\to 0.65$, $<800$ km $\to 0.45$, far $\to 0.25$) so a job a 30-minute matatu ride away decisively beats one 600 km away even if the latter pays more — because the real-world score should reflect the real-world commute.
Resilient LLM layer — built for chaos
Lumen runs through a single chat client (backend/app/services/openrouter.py) that picks its gateway by env vars:
if TRUEFOUNDRY_API_KEY and TRUEFOUNDRY_BASE_URL:
# production / resilient path — cross-provider failover,
# retries, observability handled upstream
use_truefoundry_ai_gateway()
else:
use_openrouter_direct()
When TrueFoundry AI Gateway is configured, all 18 agents transparently get cross-provider failover (OpenRouter → Anthropic → Google direct), retries, caching, and per-call observability — zero changes to the agent layer. Underneath, every agent's run() wraps the LLM call in a try block; on failure, a hand-tuned _fallback() synthesizer produces a structurally identical output. The SSE stream keeps flowing. The UX never hangs.
To prove the resilience claim on demand, I added a chaos-mode env flag:
$$
P(\text{LLM call fails on purpose}) ;=; \mathtt{LUMEN_CHAOS_MODE} \in [0, 1]
$$
Setting LUMEN_CHAOS_MODE=0.5 forces $50%$ of LLM calls to raise. For the 6-agent Employer Council, the probability that all six succeed is $(1-0.5)^6 \approx 1.6%$ — yet the UI renders a complete council more than $98%$ of the time, because the deterministic fallbacks pick up the slack. A pulsing amber ⚡ CHAOS 50% chip appears in the header so the judges see the failure rate while watching the system recover.
What's actually shipped
Frontend: Next.js 14 on Vercel
Backend + Postgres: FastAPI on Railway
One-shot local boot: docker compose up --build brings all three services up with idempotent seed (12 regions · 47 youth · 35 employers · 21 training providers · synthesized routes for every youth)
118 backend unit tests covering matching, employer trust, route synthesis, course synthesizer, policy fallbacks — so deterministic paths never silently regress
🧗 Challenges I Faced
1. Streaming SSE through long LLM awaits broke FastAPI's session
The Bridge Course generator can stream for 20–40 seconds. Halfway through, FastAPI's request-scoped DB session would close, and the final agent_run insert raised. Fix: any long-running SSE generator now opens a fresh SessionLocal() instead of relying on the request session. Obvious in hindsight; cost me an evening.
2. Stacked employer markers on a 3D map
Seeded employers share their region's lat/lng, so every employer in Lucknow rendered as a single overlapping marker. Fix: deterministic radial jitter — for $n$ employers in a region, place them on a ${\sim}20$ km ring at angles $\theta_k = \frac{2\pi k}{n}$, derived from a hash of the employer id so the layout is stable across renders. Stable matters: a marker that jumps every refresh feels broken, even when it isn't.
3. MapLibre popup white-on-white
The library's stylesheet is loaded after globals.css by the dynamically-imported map component (Next.js can't SSR Leaflet/MapLibre because they touch window). Result: dark-themed Lumen + library's default light popup = invisible text. Fix: !important overrides on .maplibregl-popup-content in globals.css. Sometimes the right answer is the inelegant one.
4. Multilingual voice without paid-API lock-in
ElevenLabs Scribe is excellent for STT, but I didn't want the demo to die if the API key was missing or rate-limited. Fix: a three-stage fallback chain — Browser Web Speech API primary (free, fast, decent at common languages), ElevenLabs Scribe secondary (paid, accurate, handles low-resource languages), text typing as the ultimate floor. The youth always has a way to tell their story.
5. The "9× moment" needed honest math
I wanted the "23 → 214 (9.3×)" line to be real, not theatrical. Bias Lens now reads raw filters against the decomposed task graph and computes the pool lift from the seeded youth distribution. When chaos mode triggers a fallback, the deterministic synthesizer uses the same arithmetic — so the number stays defensible whether the LLM ran or not.
6. Idempotent seed without trashing user data
The seed runs every boot and adds 12 regions / 47 youth / 35 employers / 21 providers. But if a real user has already signed up, I can't blow them away. Fix: name-matched upserts — seed entries are matched by canonical name and the refresh pass re-synthesizes only their skill_dna / routes. User-created profiles are never touched. The seed becomes a demo data harness rather than a destructive reset.
7. Renaming the project mid-build
Halfway through, I renamed the project from "UNMAPPED" to Lumen. The renderer rewrite touched 40+ files. The Docker container name stayed as unmapped-postgres on purpose — re-creating it would have wiped the seeded demo data. Sometimes the right call is to leave the past visible in the infrastructure and ship the new name on the surface.
8. Proving resilience without faking outages
For a demo, LLM failures need to be reproducible. Either I wait for OpenRouter to actually go down (unhelpful) or I fake it (dishonest). Chaos mode threads the needle: the failure is real (the client raises OpenRouterError from inside the retry block, just like a true upstream failure), the rate is configurable, and the fallback path that runs is the same code that would run in a true incident. A judge can flip it live during the demo by editing one env var.
Young people are not unskilled. Their skills are hidden.
Lumen makes them visible — and keeps the lights on, even when the models flicker.

Log in or sign up for Devpost to join the conversation.