-
-
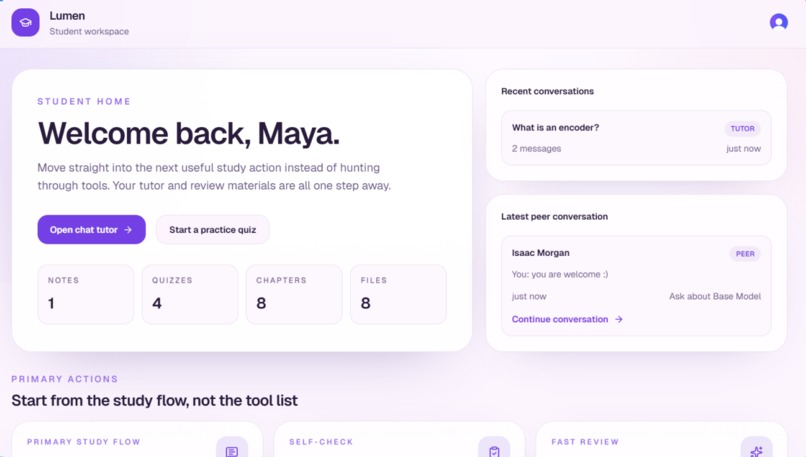
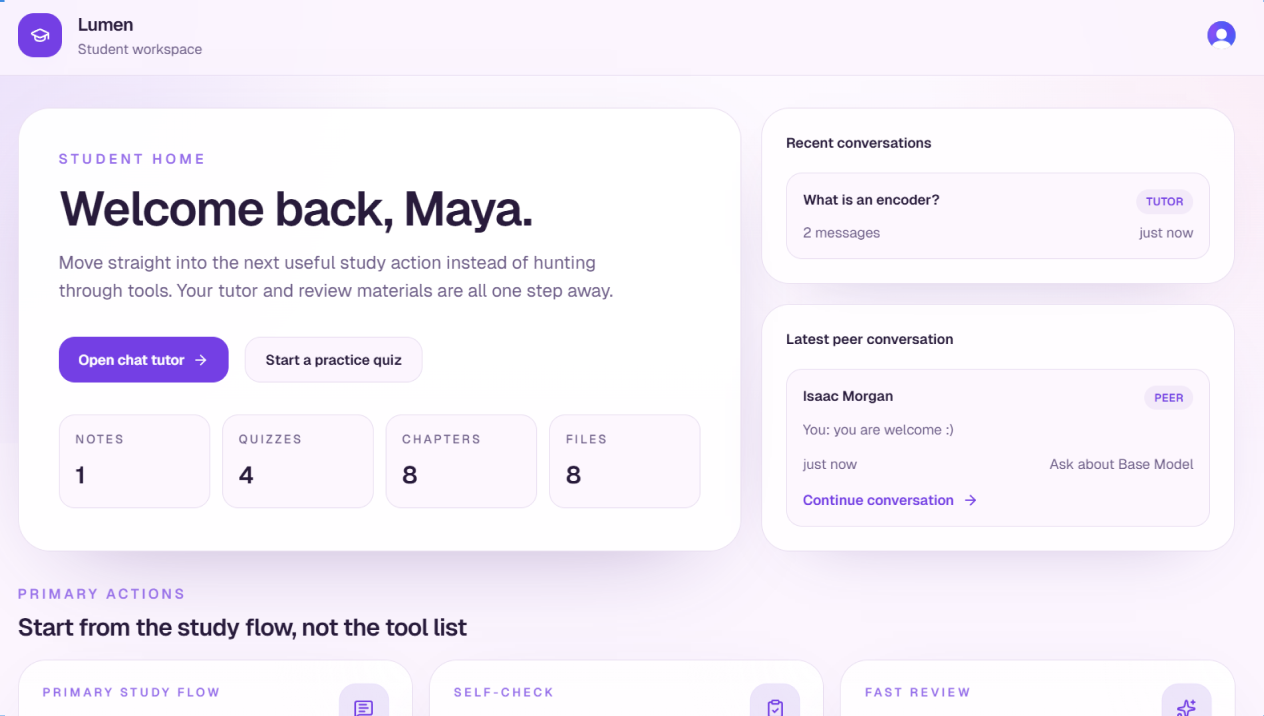
Landing Page
-
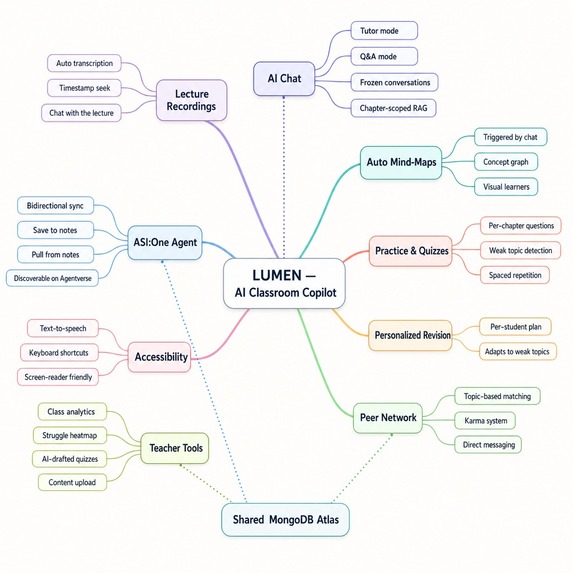
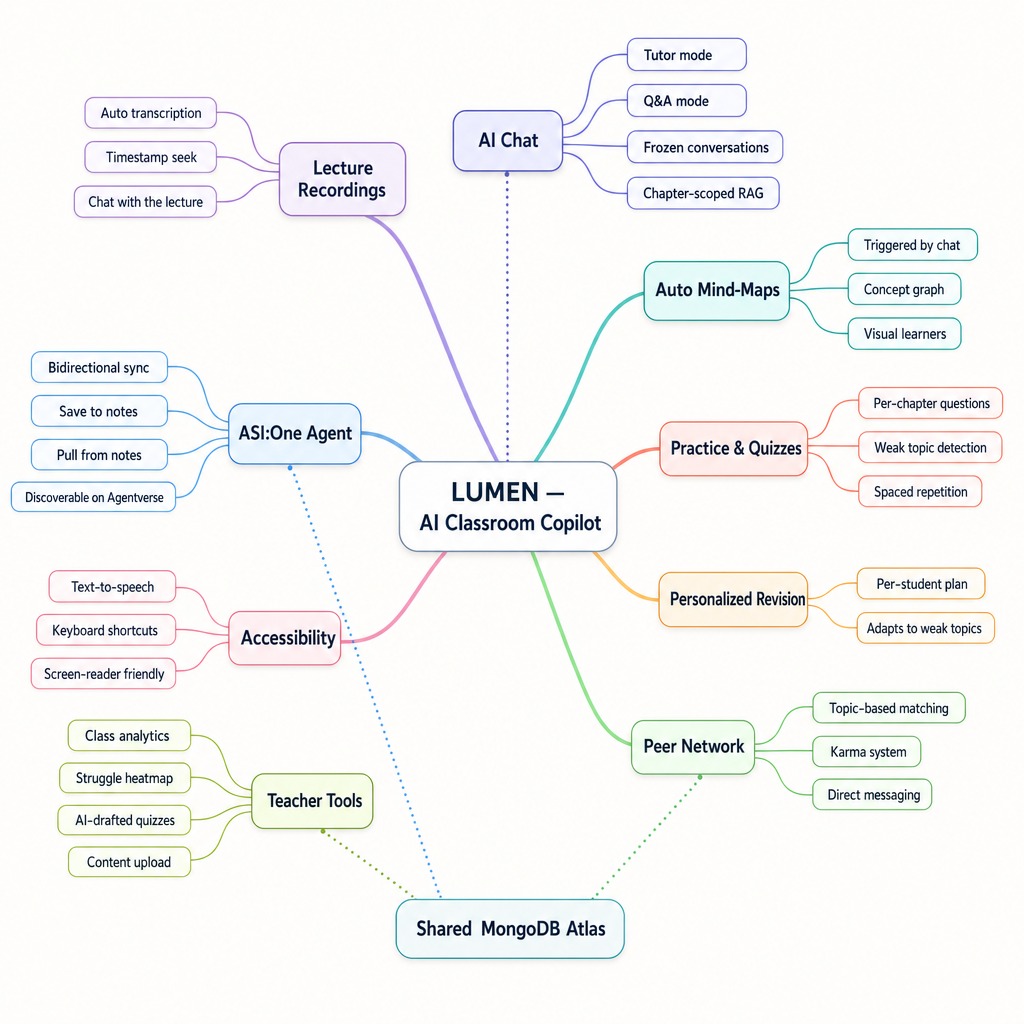
Flowchart
Inspiration
University lectures move fast. Students who fall behind once often stay behind — not because the material isn't available, but because there's no good way to navigate it. A student struggling with attention mechanisms at 2am has the lecture recording, the PDF, and a generic AI chatbot that knows nothing about their course. None of it is connected.
Teachers are flying blind too. They don't know which topics the class is struggling with until an exam reveals it. By then it's too late.
We wanted to build something that actually knows the course — ingests the real materials, understands them semantically, and uses that to support both sides of the classroom.
What it does
Lumen is a role-based AI classroom platform. Teachers upload content; students get a study companion that knows the course.
For teachers — upload PDFs and lecture videos by chapter, draft and publish quizzes with AI assistance, view analytics on class performance and peer engagement.
For students — ask questions in tutor mode (Socratic) or QA mode (direct answers). Every answer cites the exact lecture timestamp where the topic was covered, with a clickable clip. Beyond chat: practice quizzes with weak-topic feedback, flashcards, revision summaries, private notes, and peer matching with direct messaging.
Accessibility — ElevenLabs TTS reads AI answers aloud across every student page, with full keyboard navigation built in.
Fetch.ai agent — the course knowledge base runs as a registered uAgents service on Agentverse. Students can interact with it via ASI:One using their Fetch.ai account — Q&A, study plans, revision summaries, chapter listing, note saving — without opening Lumen.
How we built it
Ingestion — PDFs are chunked and embedded. Lecture videos go to Cloudinary, then ElevenLabs Scribe transcribes them with word-level timestamps asynchronously. Everything — PDF chunks and timed transcript segments — lands in the same MongoDB Atlas vector index.
RAG chat — question gets embedded, Atlas retrieves top-K chunks, Gemma 4 31B generates a grounded answer. Recording chunks get their timestamps resolved into Cloudinary clip URLs (so_/eo_) and surfaced inline as "▶ Watch clip" buttons.
Fetch.ai agent — standalone uAgents service, decoupled from the FastAPI backend so it deploys independently. Each message is classified into one of five intents by an LLM call grounded with a live MongoDB query (so it never hallucinates a chapter tag). Runs with mailbox=True to stay reachable on Agentverse.
Frontend — Next.js App Router, Tailwind, shadcn/ui. Clerk handles auth. ElevenLabs TTS proxied through a Next.js API route with browser SpeechSynthesis fallback.
Challenges we ran into
Heterogeneous content in one index — PDFs chunk by token count; lecture recordings needed timed segments collapsed from word-level Scribe output. Getting boundaries right — meaningful enough for retrieval, precise enough to timestamp — took several iterations.
Grounding the Fetch.ai intent classifier — the LLM classifying user messages needs to know which chapters actually exist before it can route correctly. Every inference call starts with a live distinct() query to MongoDB. Without this, it hallucinated chapter tags constantly.
Cloudinary enrichment at query time — vector search returns recording_id and start_time, but cloudinary_public_id lives in a separate collection. After every search we run a batched lookup, resolve the public ID, and construct clip URLs before returning — on both the Atlas path and the in-memory cosine fallback.
Async ingestion — transcribing a 90-minute lecture can't block the upload response. We moved it to a background task with a /transcript-status polling endpoint and explicit failure states in MongoDB so recordings never get stuck in an ambiguous state.
Accomplishments that we're proud of
- RAG answers that cite exact lecture timestamps with playable clips — genuinely useful, not a gimmick
- Fetch.ai agent always in sync with the main app because they share the same live database — zero manual sync
- Accessibility mode that actually works — TTS with keyboard shortcuts throughout every student page
- Peer matching that pairs students by complementary weak and strong topics, with a gated connection flow and real-time messaging between accepted partners
What we learned
- ElevenLabs Scribe is production-quality — word-level timestamps from a 90-minute lecture in under a minute
- Cloudinary URL transformations replace a surprising amount of video infrastructure
- Grounding LLM classifiers in live database state matters more than prompt cleverness
- Agree on the MongoDB schema before writing ingestion code — changing a chunk field cascades everywhere
What's next for Lumen — AI Classroom Copilot
- Personalised Catch-Up video — splice Cloudinary clips covering a student's weak topics into one study video after a quiz, using
fl_splice - Live lecture mode — real-time transcription so the RAG index updates as the professor speaks
- Voice assistant — mic input → Gemma → ElevenLabs TTS, fully hands-free
- Multi-class support — multiple courses per teacher, multiple enrolments per student
- Institutional deployment — multi-tenant with LMS integrations (Canvas, Moodle)
Fetch.ai Deliverables:
- Shared chat: https://asi1.ai/shared-chat/efd33390-f7ba-4712-80df-506b8badb6d3
- Agentverse AI: https://agentverse.ai/agents/details/agent1q2e4y9lr38xugasm69eun24ndjznde9wvnc6x0yxsl9ay6przpvlqer7rt8/profile (Demo video showcases the agent near the end)
Built With
- clerk
- cloudinary
- elevenlabs
- fastapi
- fetch.ai
- google-gemma
- mongodb-atlas
- next.js
- openrouter
- python
- shadcn
- tailwind-css
- typescript
- uagents


Log in or sign up for Devpost to join the conversation.