-
-
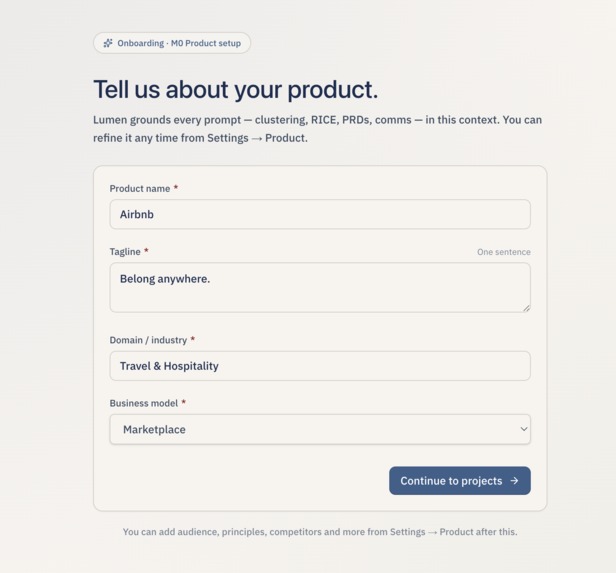
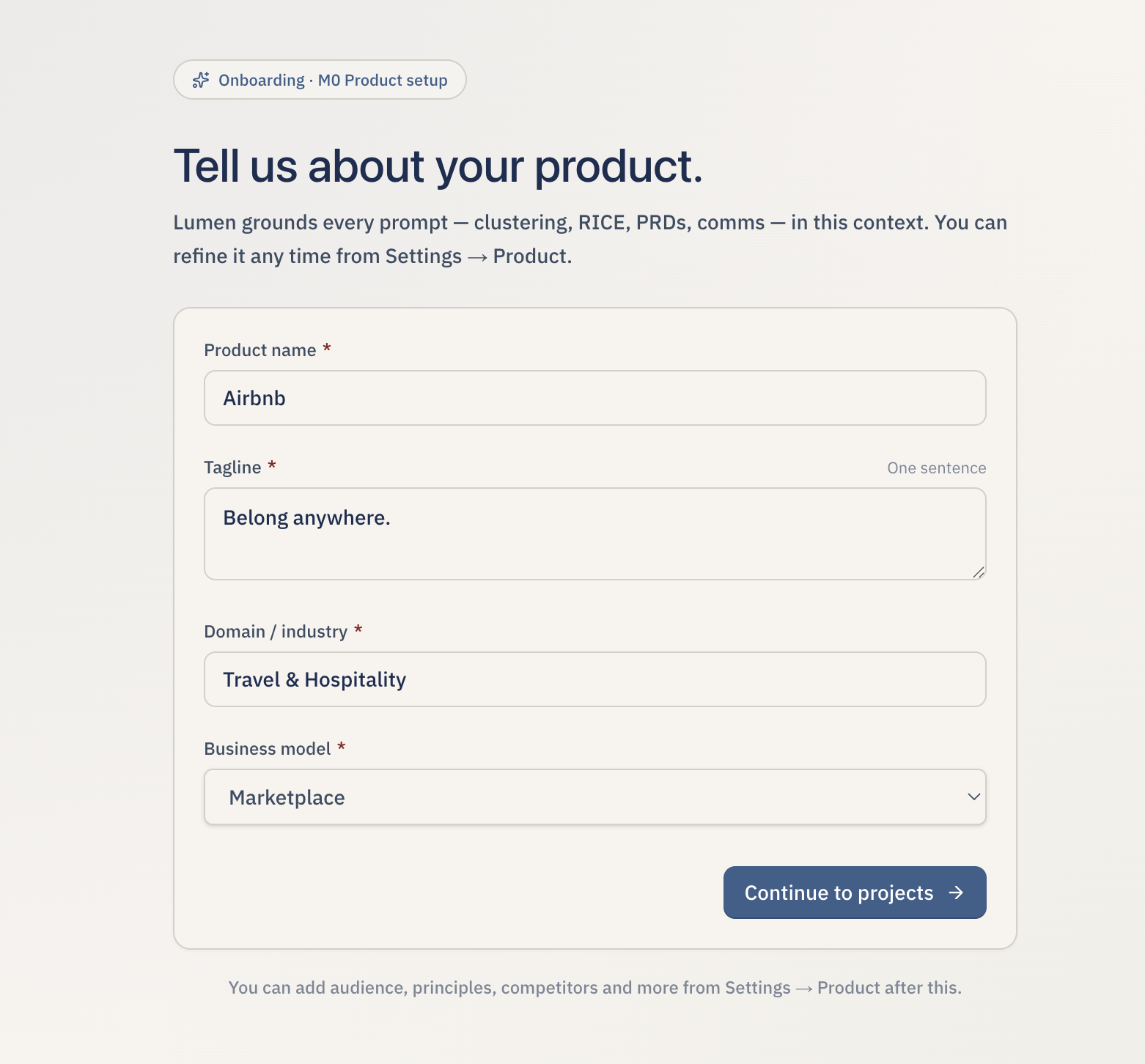
Tell about the Core Product you want to work on
-
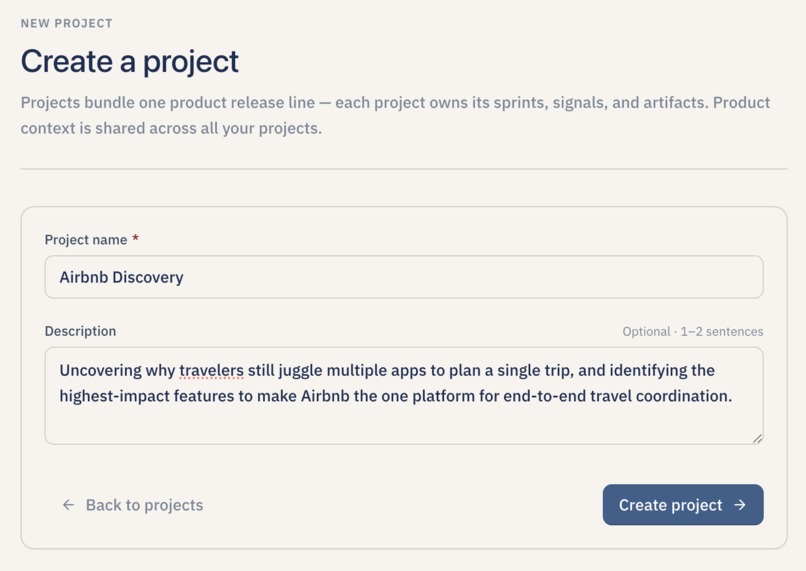
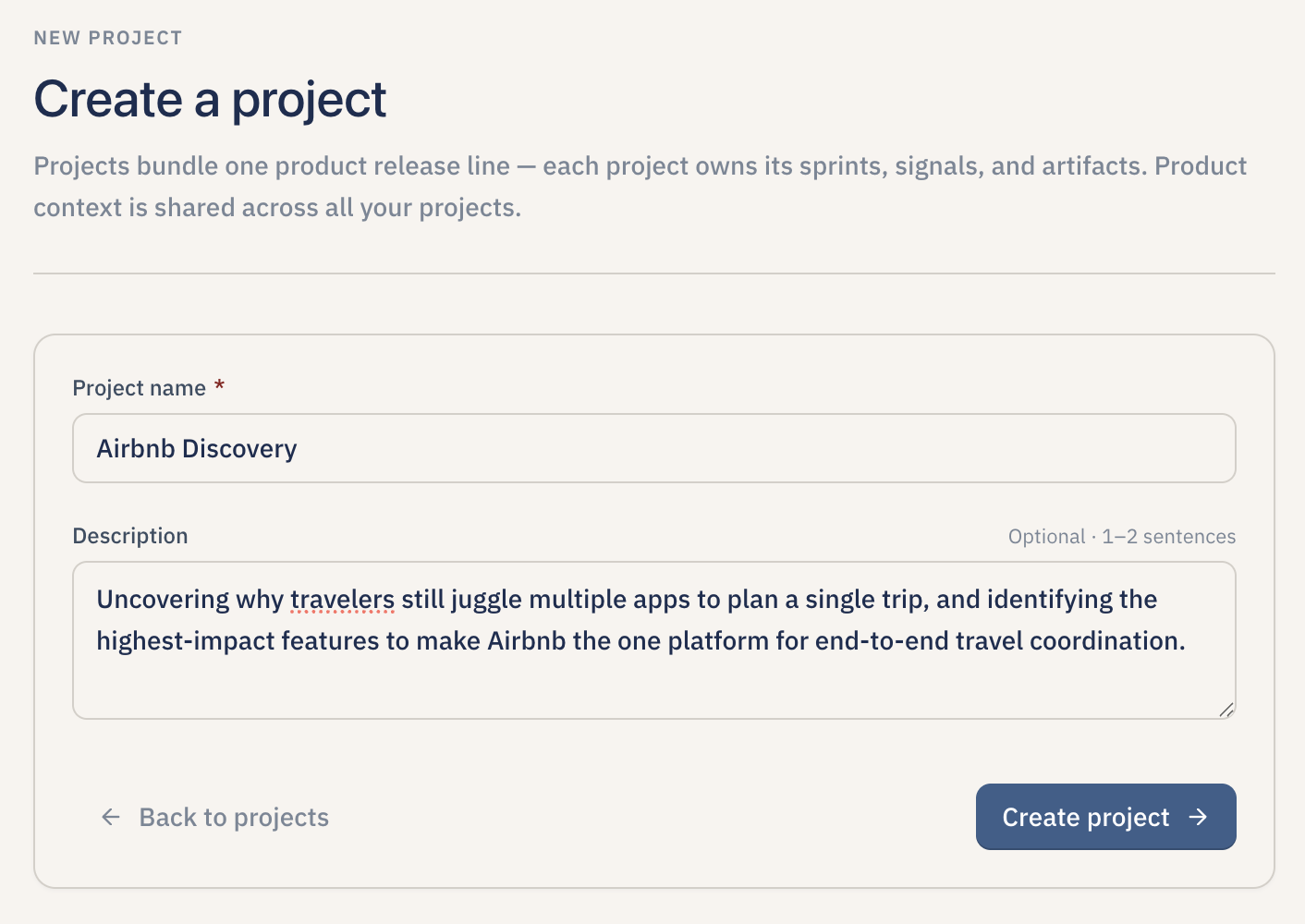
Create your first project to get started A project anchors your product context and every sprint of discovery you run inside Lumen.
-
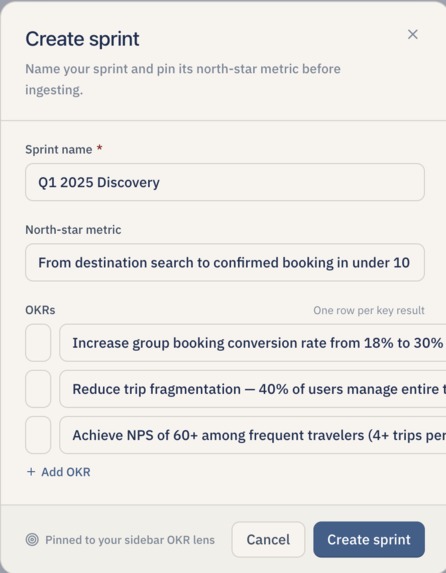
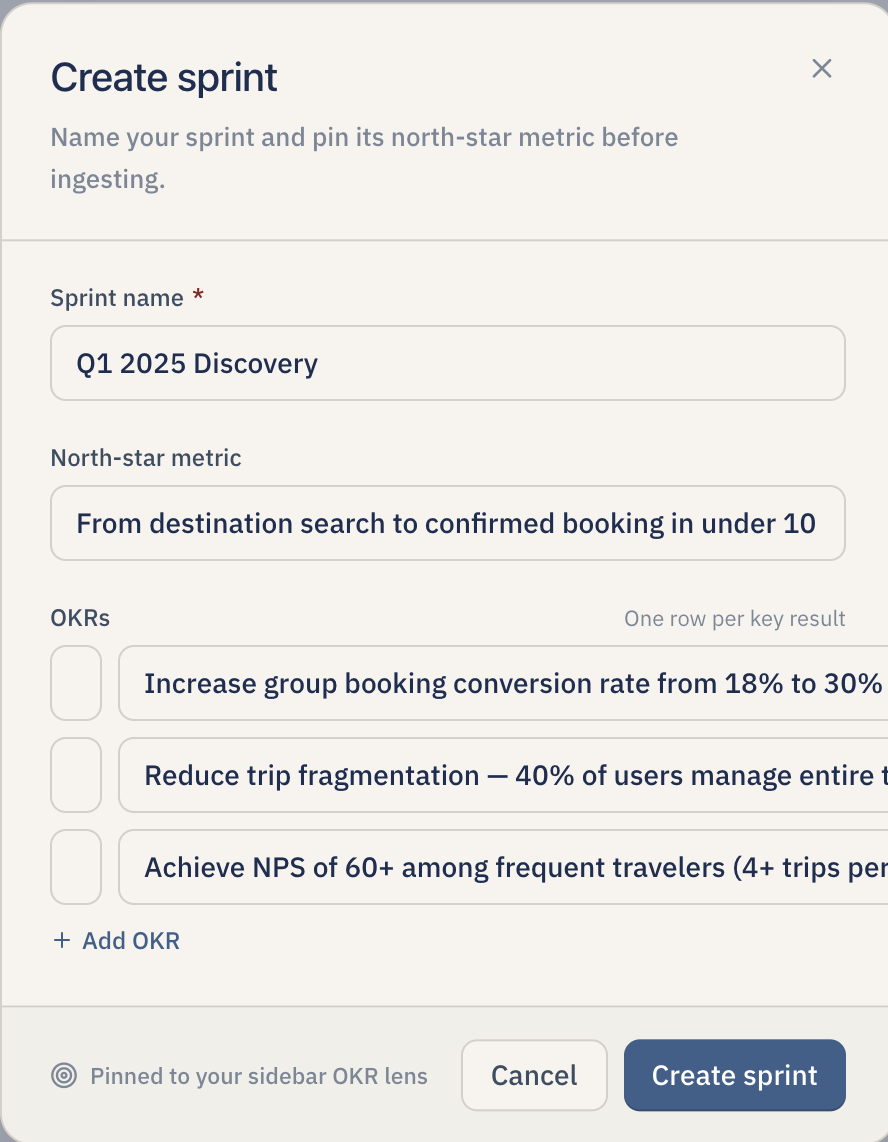
Create Sprint for the Project
-
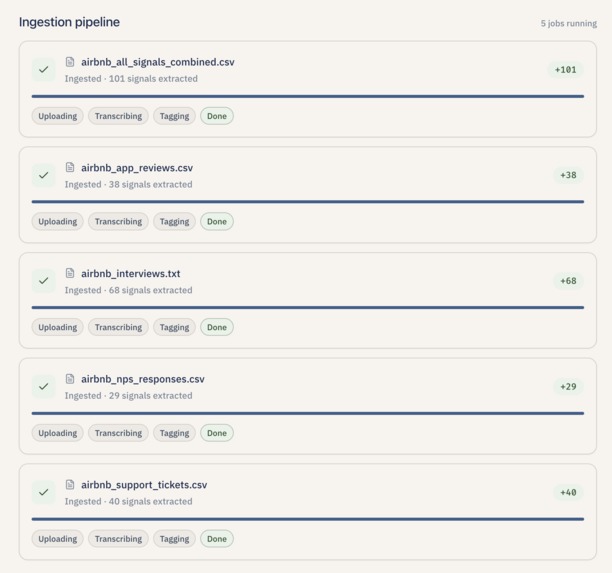
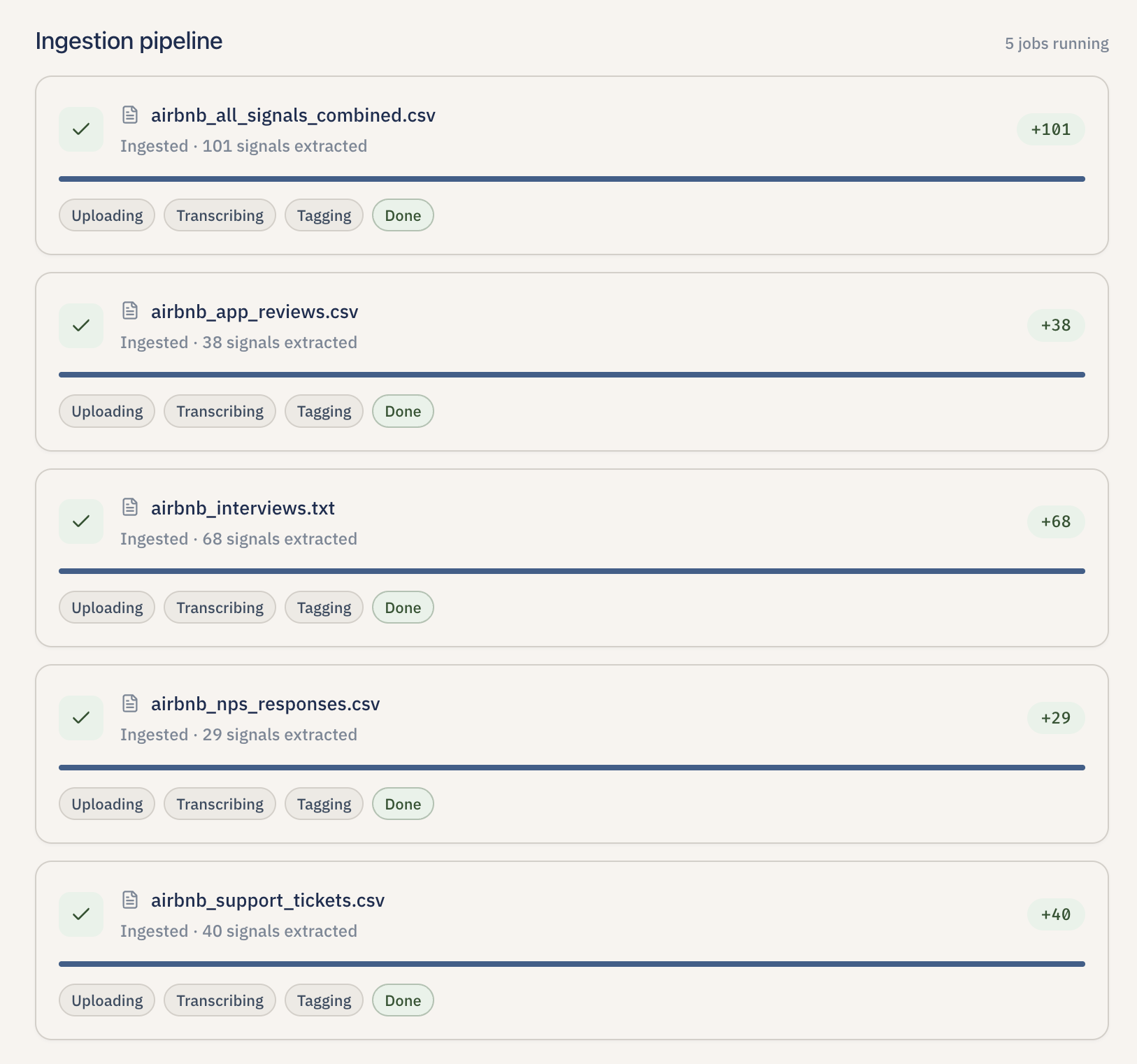
Parallel file uploads turn raw CSVs and transcripts into counted, tagged signals before synthesis.
-
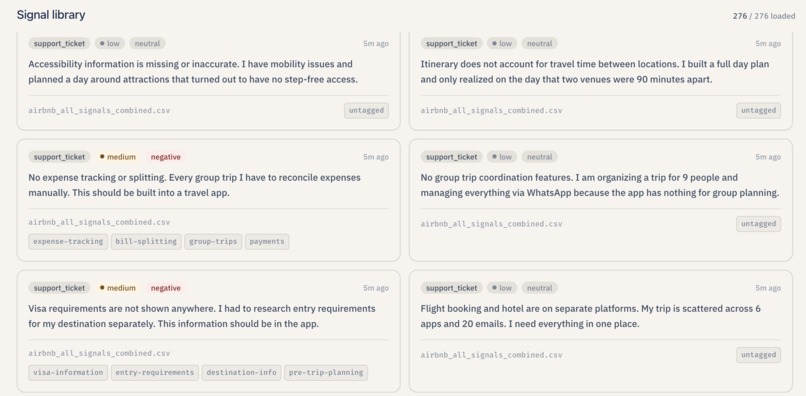
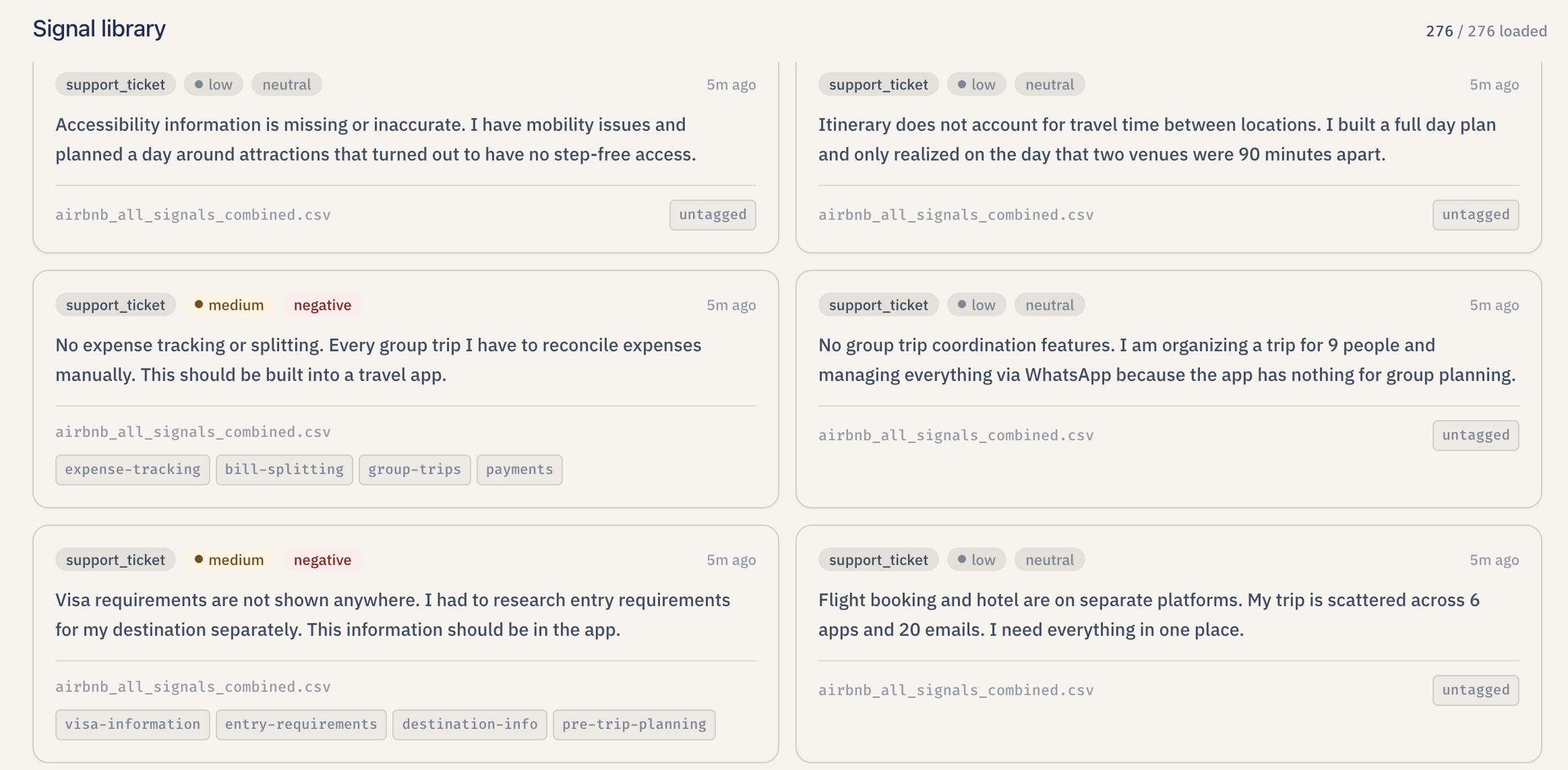
Scrollable list of atomic feedback rows with sentiment, severity, and source badges.
-
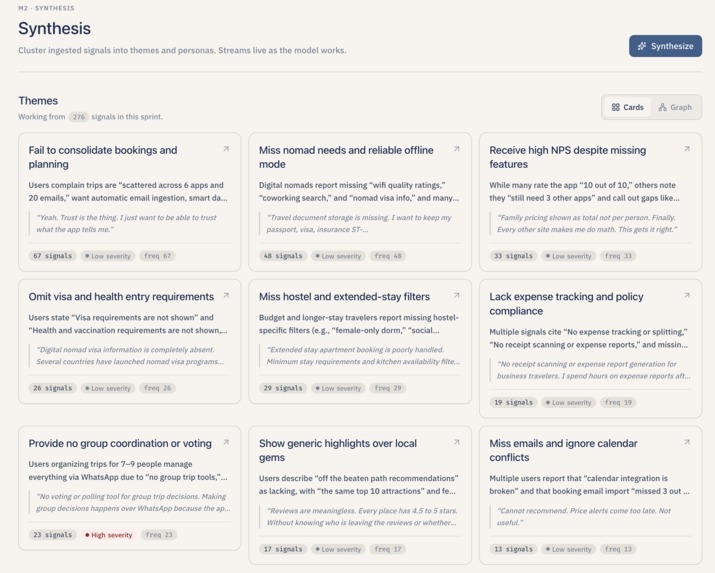
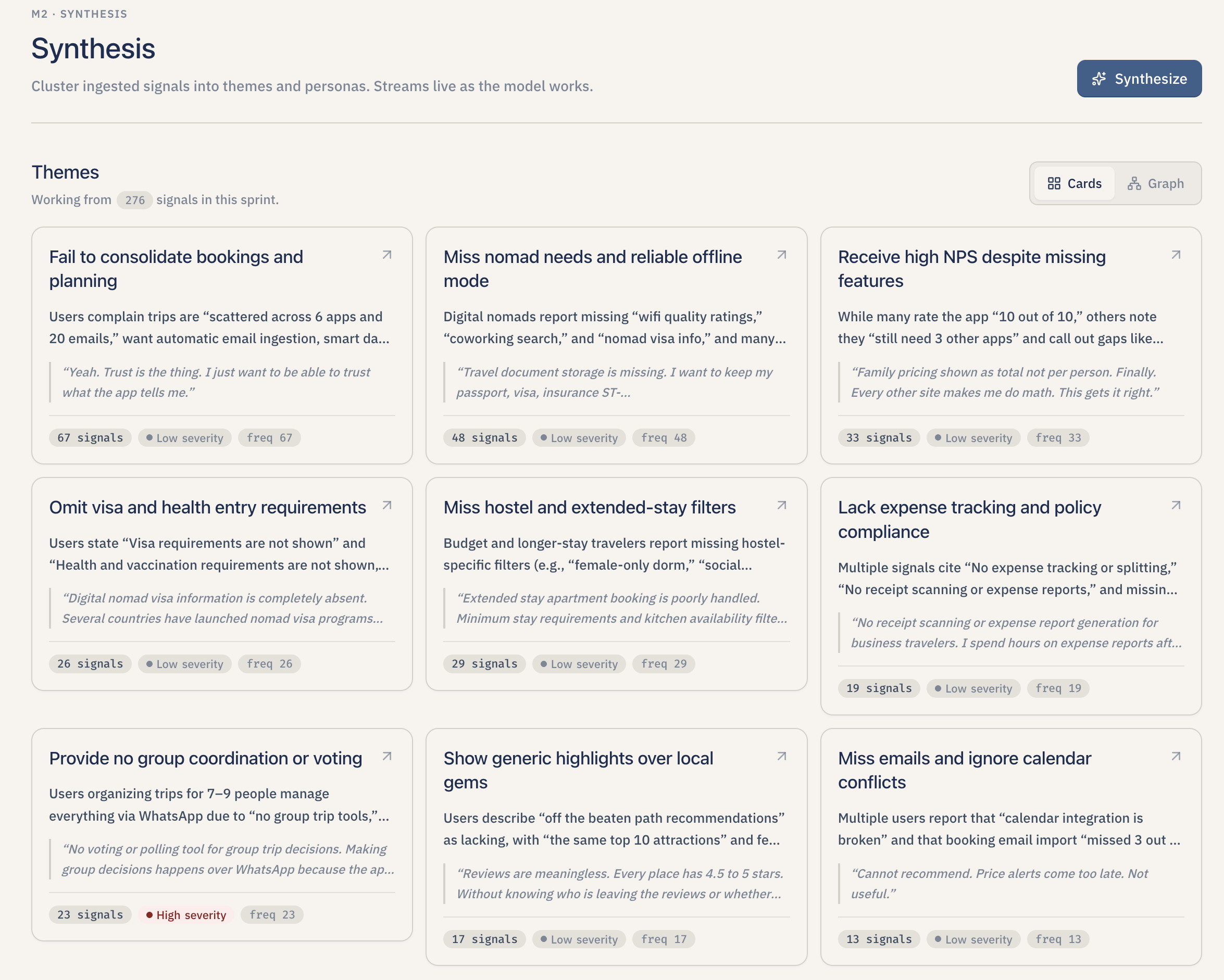
Signals into theme clusters for pattern spotting.
-
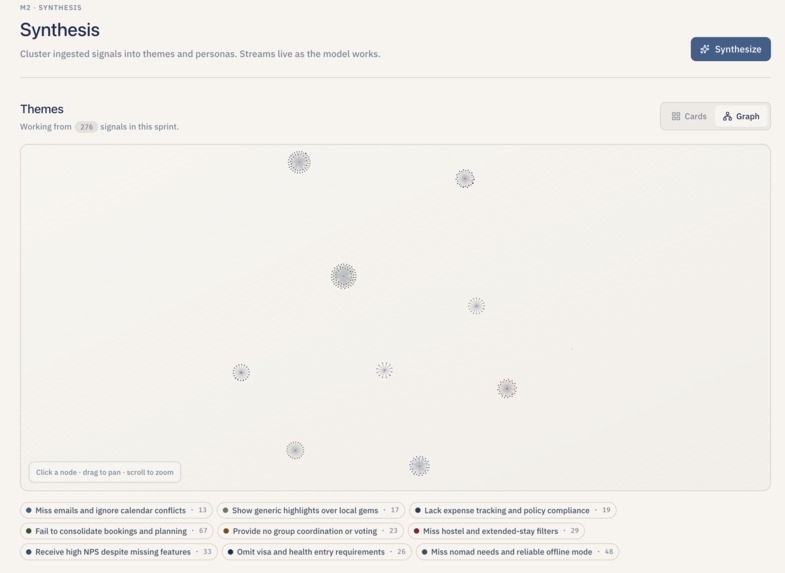
Theme clusters
-
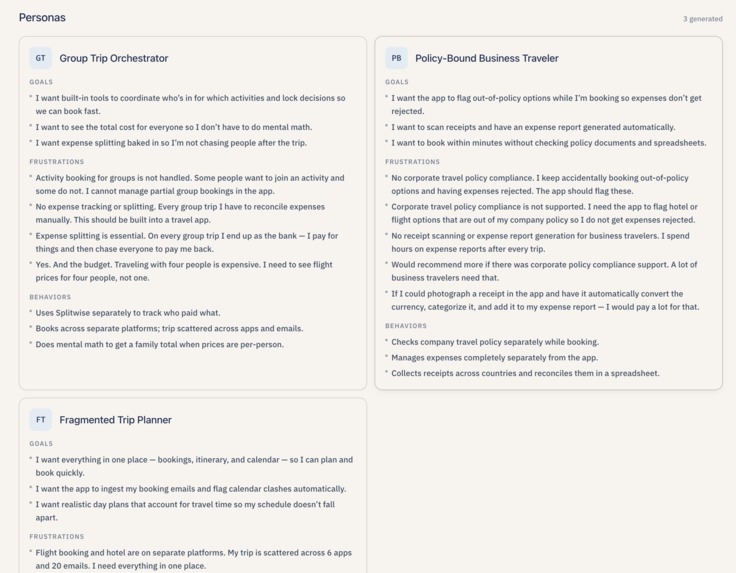
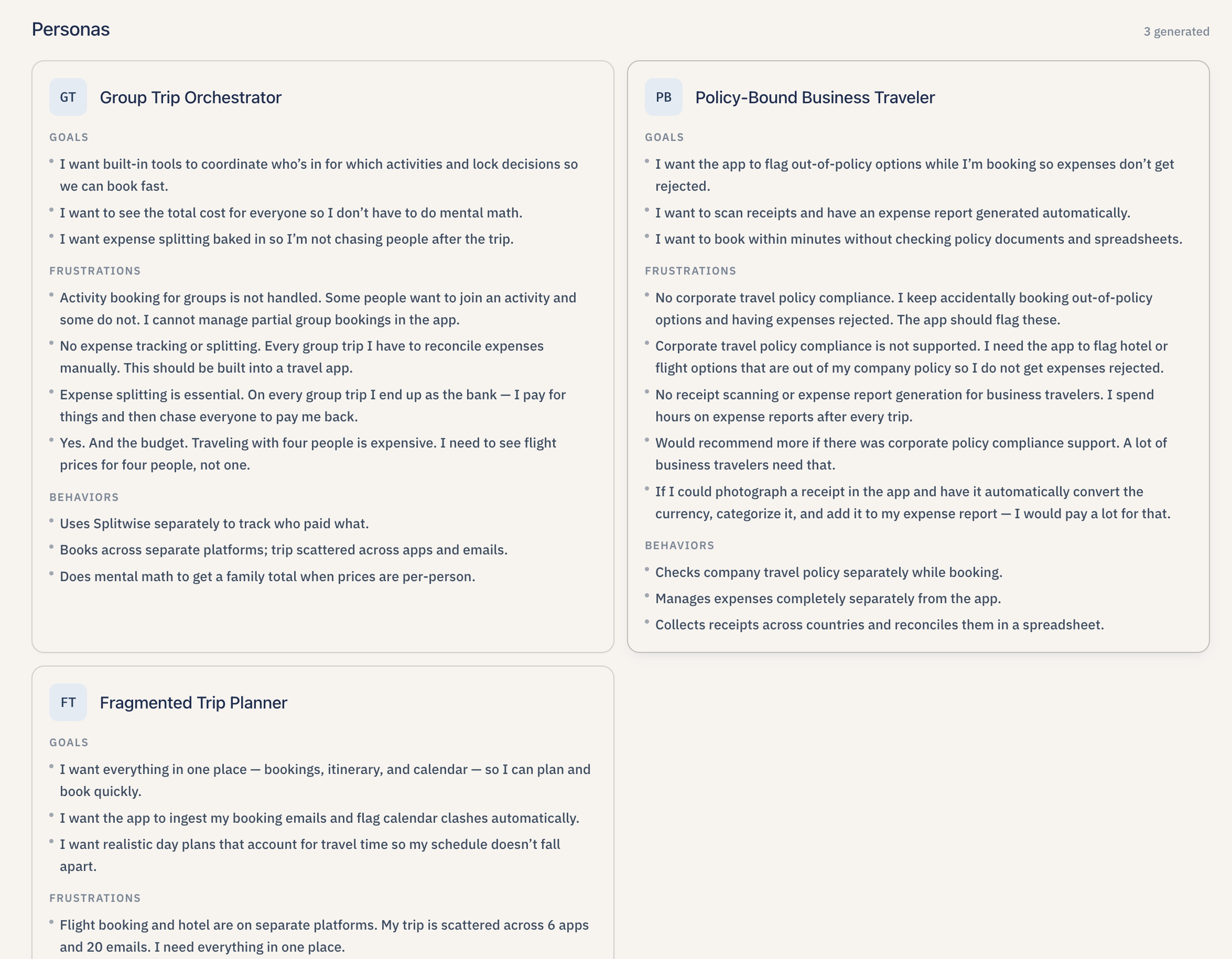
AI-generated user archetypes, name, goals, frustrations and behaviors, streamed on Synthesis after themes, grounded in the sprint’s signals.
-
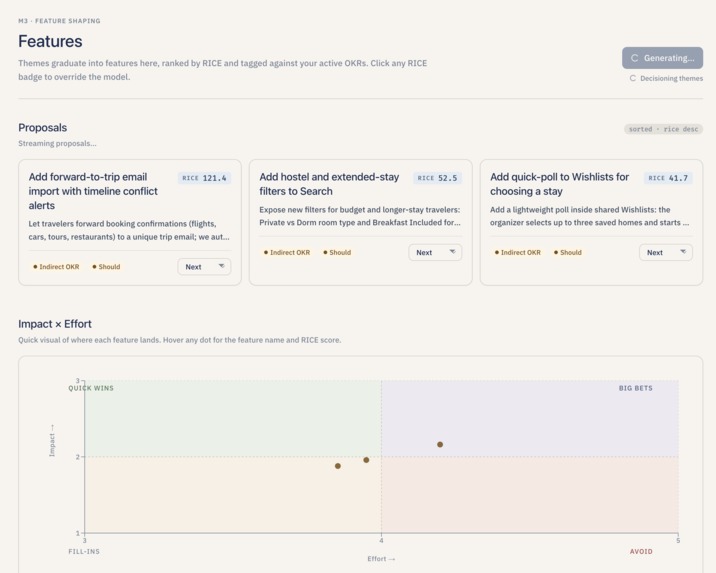
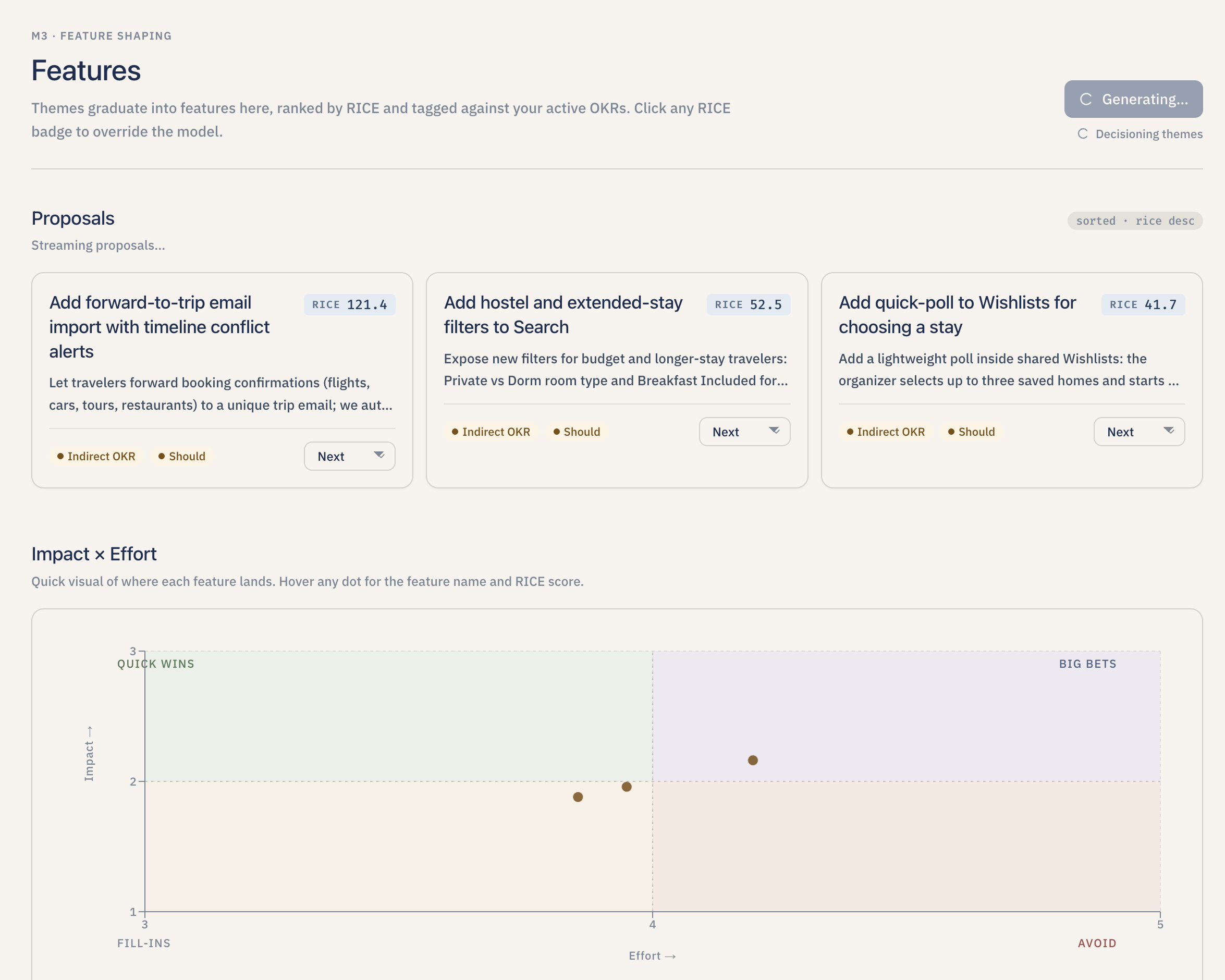
RICE-scored feature proposals with OKR alignment and roadmap hints for prioritization.
-
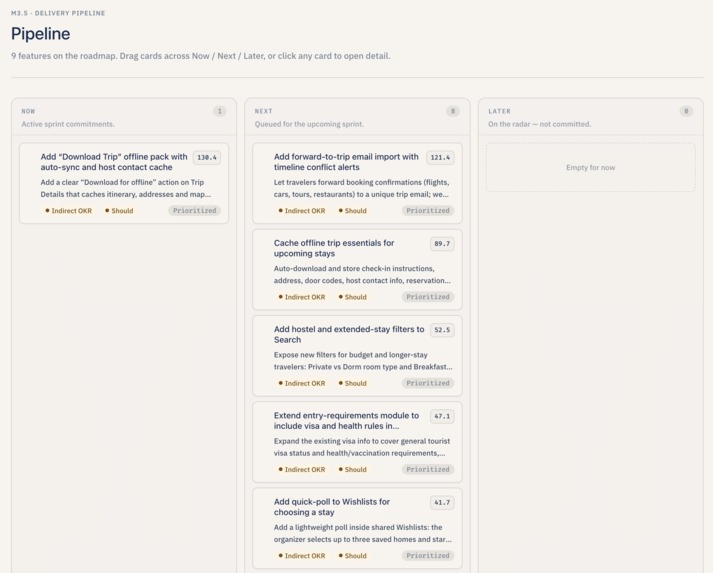
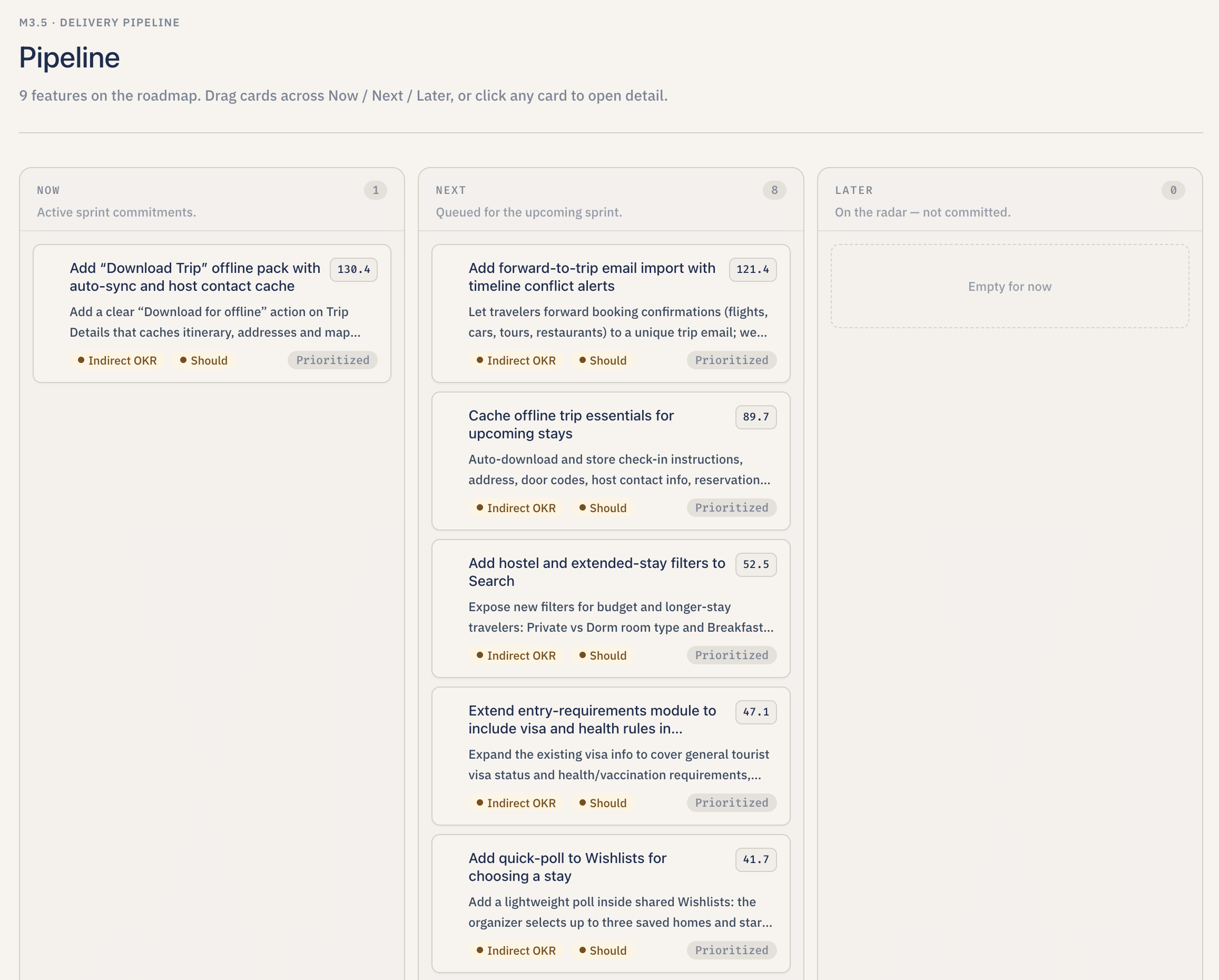
Drag-and-drop Kanban with Now / Next / Later and pipeline status for delivery planning.
-
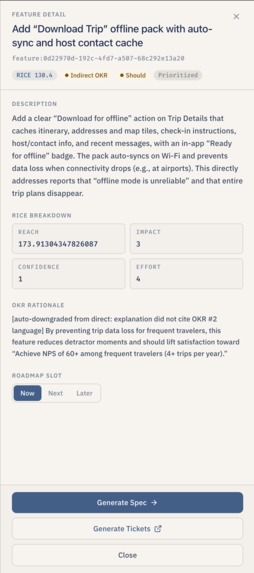
Feature Details
-
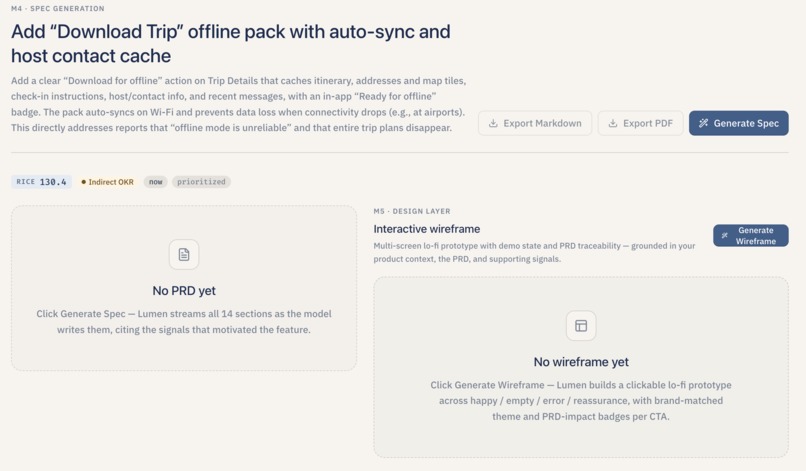
Streaming PRD sections with evidence tied back to original signals for one feature.
-
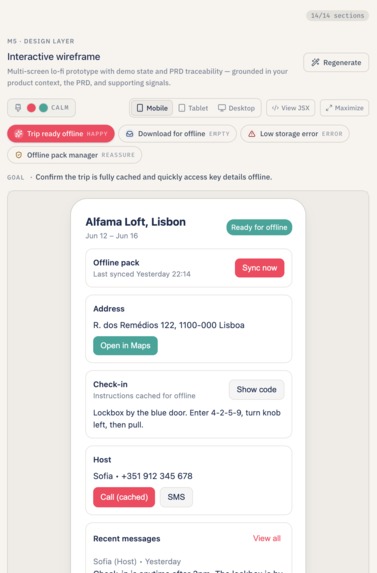
Lo-fi UI preview and UX flow generated from the same feature context.
-
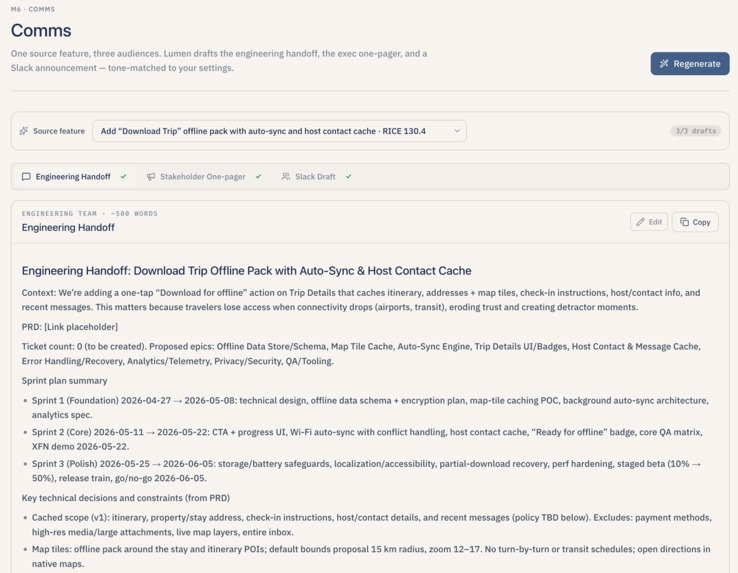
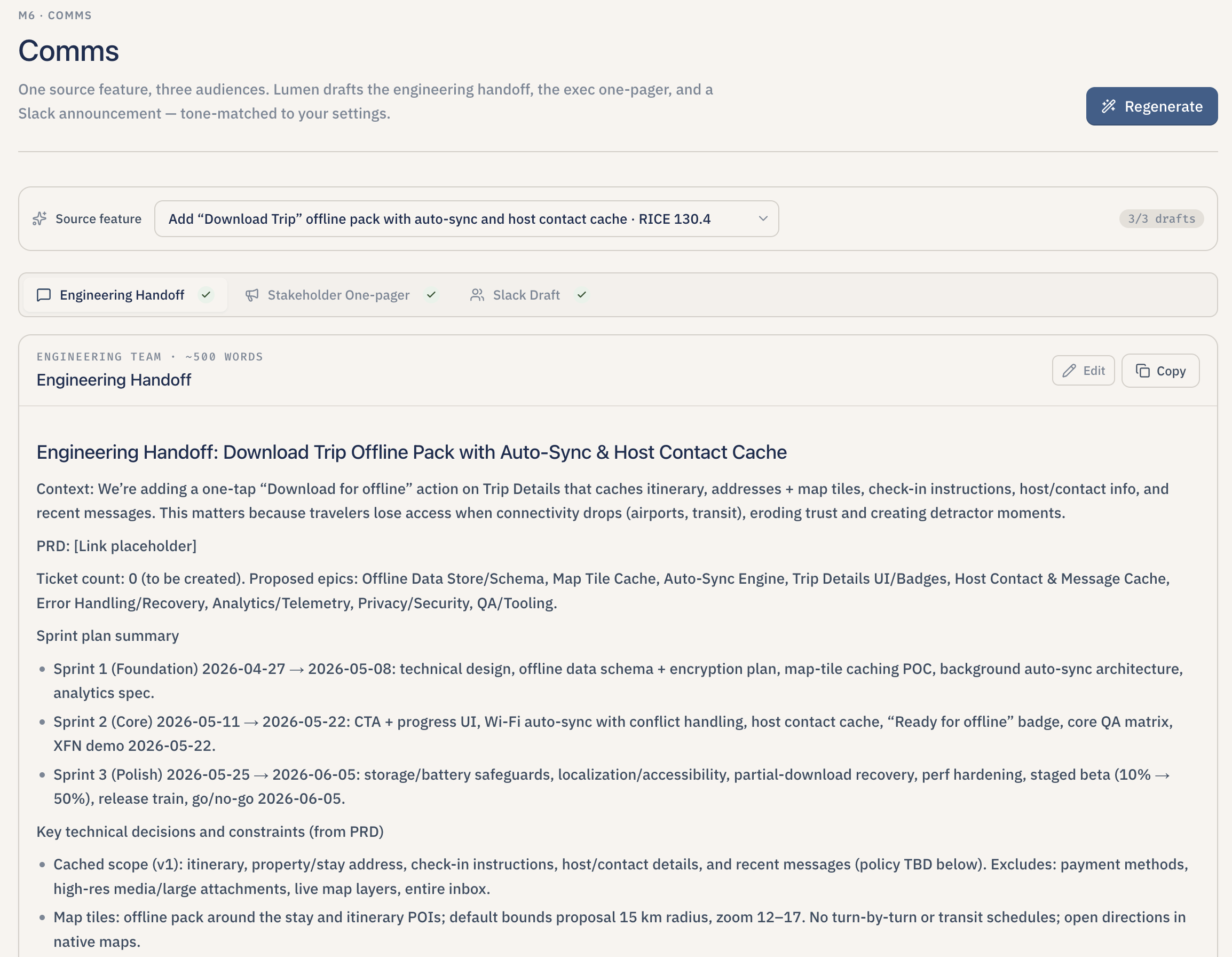
Stakeholder-ready markdown (handoff, one-pager, Slack-style) generated from the feature.
-
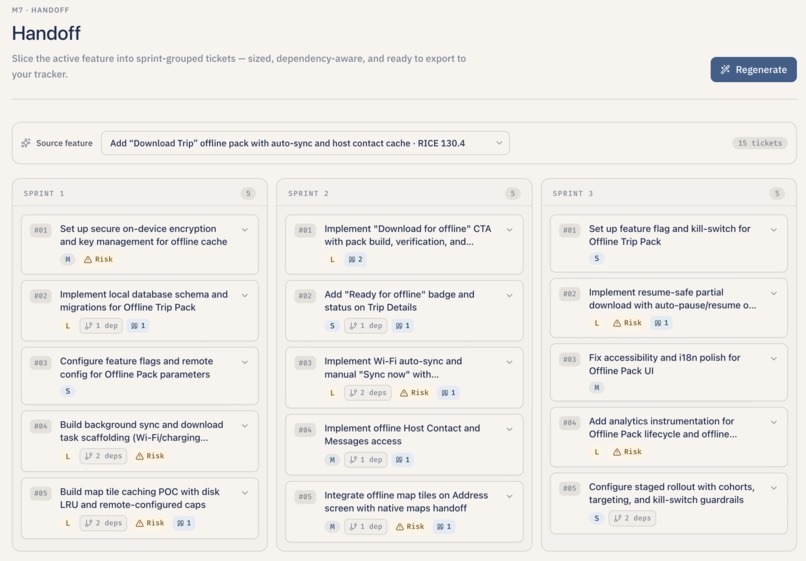
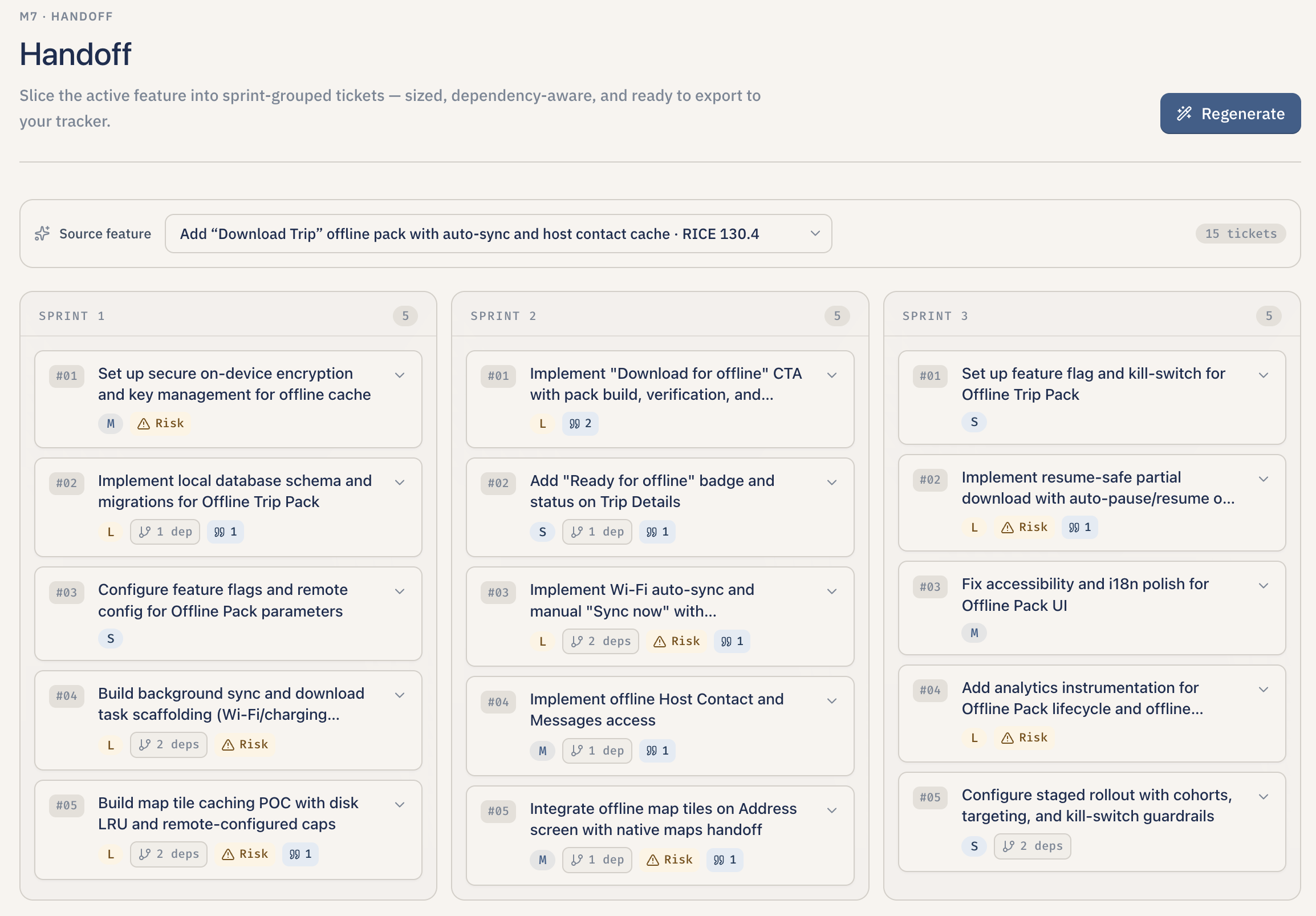
Sized tickets with acceptance criteria and export to Markdown, MCP JSON, Linear, or Jira.
Lumen
Tagline: From scattered feedback to a dev-ready spec — in one flow.
Inspiration
We kept noticing the same gap on every product team we worked with: writing software has gotten dramatically faster, but deciding what to build, and getting that decision into engineers' hands, has not. Product Managers (PMs) and founder-PMs still spend their evenings stitching together interview notes, support exports, app store reviews, and stray Slack messages, and then turning all of that into a roadmap, a Product Requirements Document (PRD), a wireframe, and a clean set of tickets — over and over, by hand, every sprint.
The painful part is not the writing. It is the loss of the thread. By the time a feature lands in a ticket, it is hard to tell which user actually asked for it, why this work was prioritized over something else, or which Objective and Key Result (OKR) it is supposed to move. Decisions stop being traceable.
Lumen is our attempt to fix that. We wanted one workspace where raw feedback flows in at one end and dev-ready tickets, with the original user quotes still attached, come out the other end — so a team can spend less time retyping the week and more time shipping the right things.
What it does
Lumen is an Artificial Intelligence (AI) -native product discovery app. A user (a PM, a founder, a product lead) signs in, sets up their product once, creates a project and a sprint, and then walks the app through one continuous flow:
- Upload feedback. Lumen accepts plain text, Portable Document Format (PDF) files, Microsoft Word documents (DOCX), and Comma-Separated Values (CSV) exports. It can also detect interview transcripts (timestamped speaker turns) and split them into one signal per participant turn while filtering out the interviewer's voice. Each piece of feedback becomes a "signal" — tagged with sentiment (positive / negative / neutral), severity (high / medium / low), and topic tags so it is easy to triage later.
- Synthesize themes and personas. Lumen groups all the signals in the sprint by meaning, names each group in plain English ("Users abandon meal plans mid-week" instead of "Cluster 3"), and explains what the pain is. It then proposes two to three personas — but only after grounding every frustration and behavior in the user's own words. If the sprint does not have enough signals to do this honestly, Lumen says so and skips the personas instead of inventing them.
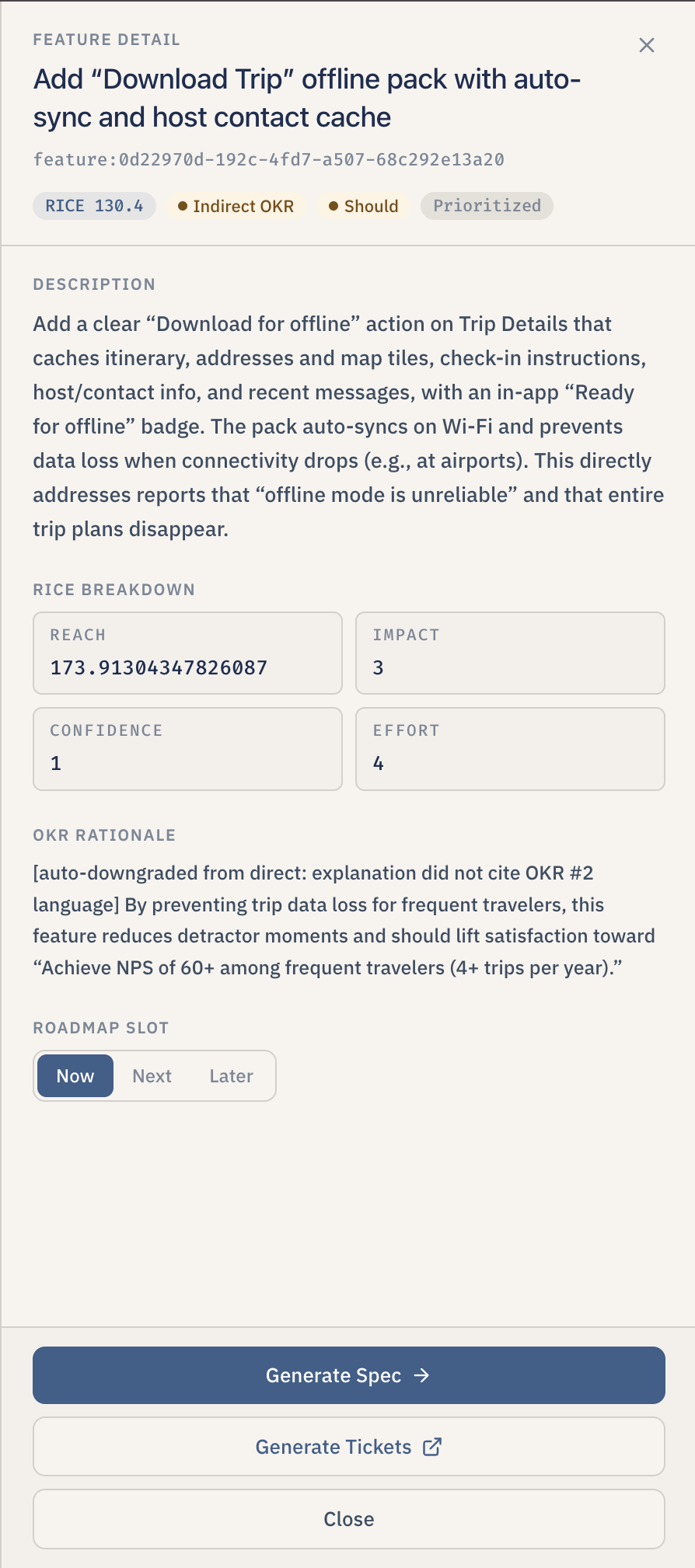
- Decide what to build. For each theme, Lumen drafts one feature proposal with a RICE score (Reach, Impact, Confidence, and Effort), a MoSCoW priority (Must have / Should have / Could have / Won't have), an OKR alignment ("direct," "indirect," or "none"), and a roadmap slot ("Now," "Next," or "Later"). The PM can override any of those numbers and the score recalculates instantly.
- Run the pipeline like a board. All proposed features land on a drag-and-drop board with three columns — Now, Next, Later — so the user can reprioritize by dragging cards. Each card shows the RICE score, the OKR alignment tag, and the MoSCoW badge. Clicking a card opens a side drawer with the full breakdown and rationale.
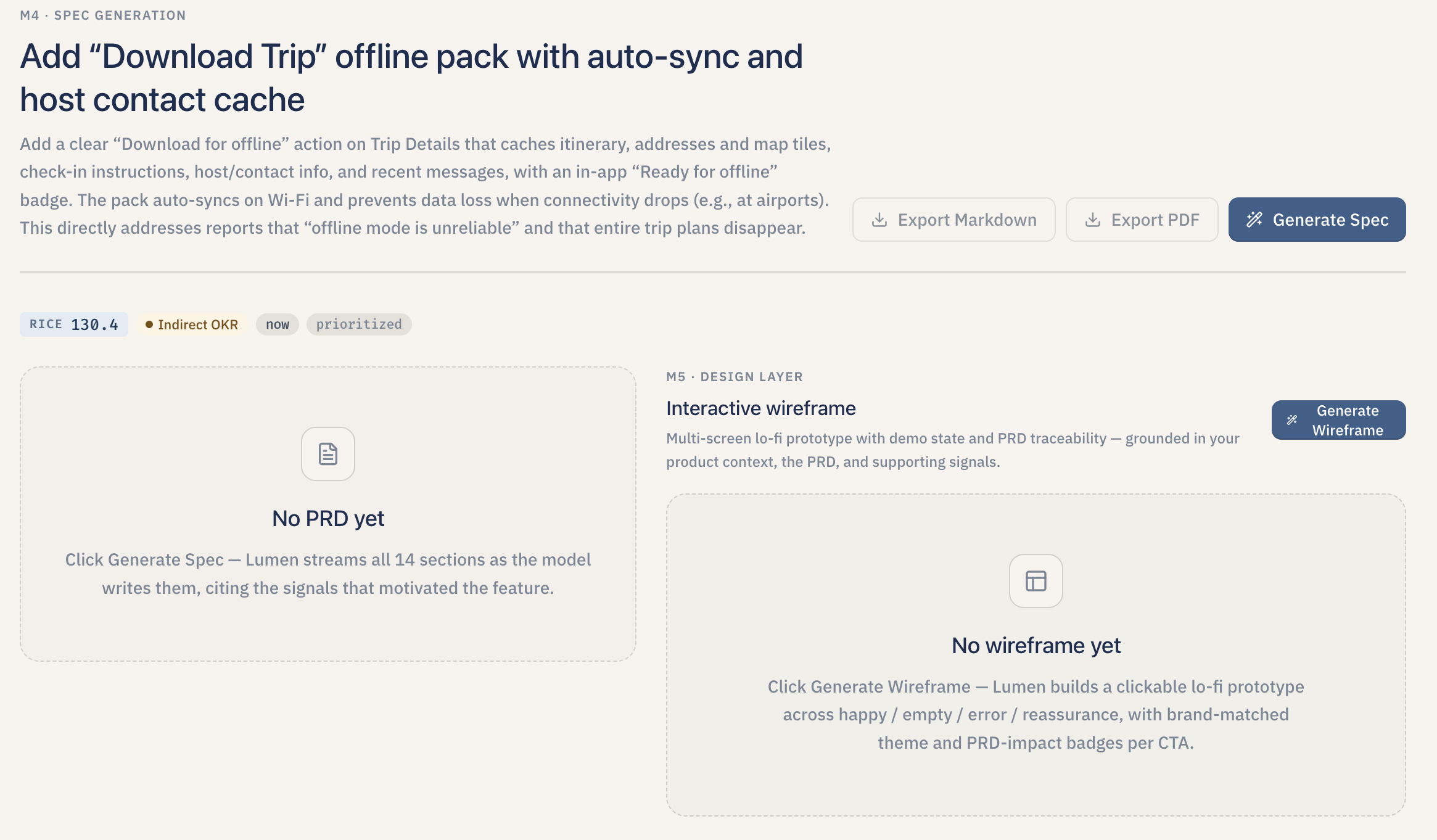
- Generate the PRD. For any selected feature, Lumen streams a fourteen-section PRD in real time — overview, success metrics, messaging, timeline, personas, user scenarios, user stories, what is explicitly out of scope, open issues, anticipated questions, and more. Every claim about a user is cited inline against the original signal that backs it up, so a reader can click through and see the verbatim quote.
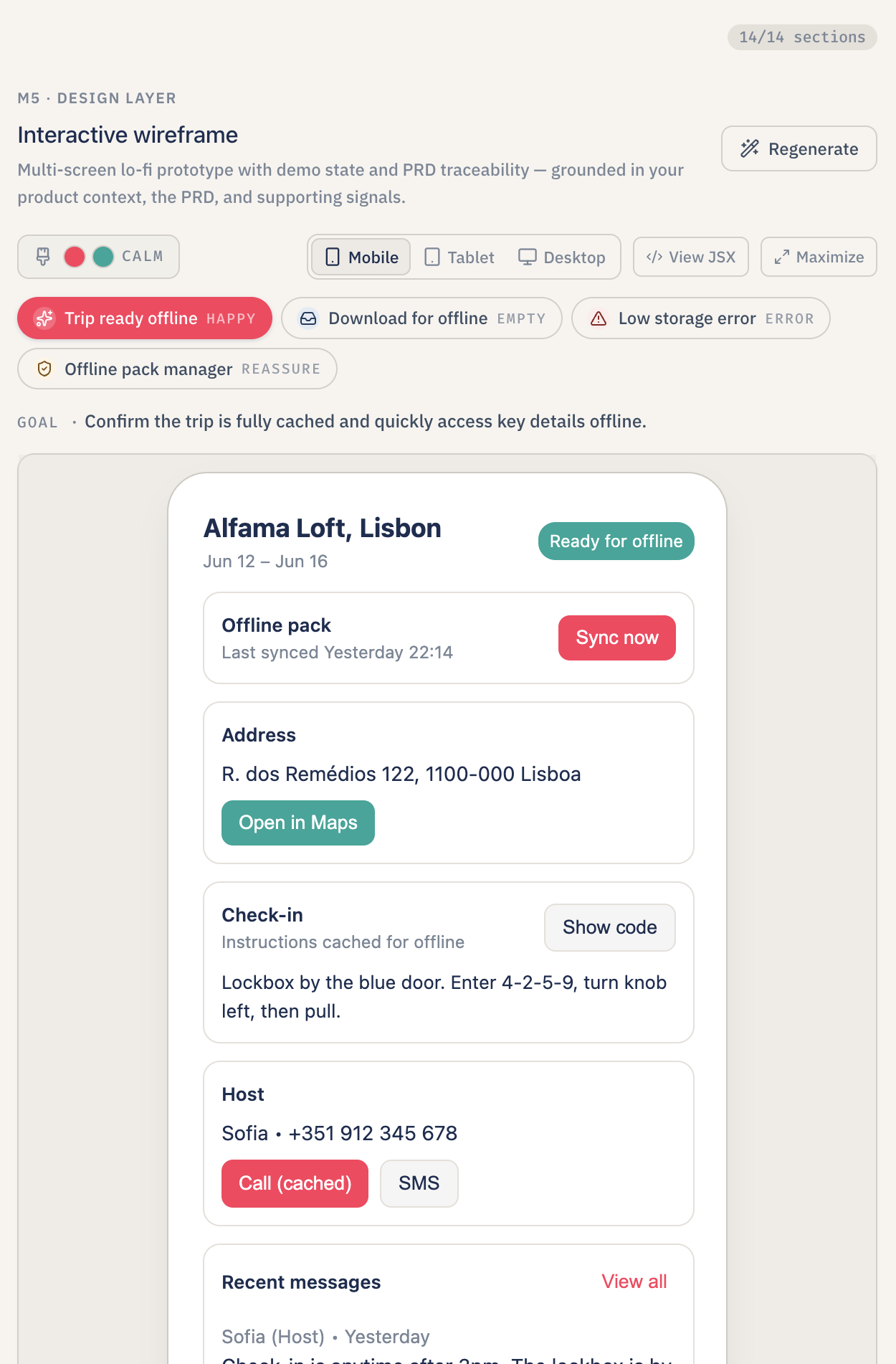
- Sketch the design. From the PRD, Lumen produces an interactive low-fidelity (lo-fi) wireframe brief — three to five screens covering the happy path, an empty state, and an error state, with a brand color theme inferred from the product context. The wireframes are clickable previews, not static images: tapping a button on one screen actually navigates to the next.
- Draft the communications. With one click, Lumen drafts an engineering handoff document, a one-pager for executives, and a Slack-ready announcement — each tuned to the team's saved tone preferences (for example, "direct, technical, no fluff" for engineers; "confident, concise, outcome-focused" for executives).
- Ship the tickets. Lumen breaks the feature into sprint-grouped developer tickets (Foundation / Core flows / Polish), each with acceptance criteria written in Given/When/Then format, a size estimate (Extra Small through Extra Large), explicit dependency links between tickets, a risk flag when something looks dicey (touches authentication, depends on an external Application Programming Interface (API), or has unclear design), and the original user quotes that motivated the work attached as evidence.
- Export to wherever the team works. Tickets can be downloaded as Markdown, as Model Context Protocol (MCP) -shaped JavaScript Object Notation (JSON) for Cursor / Claude Code, as a Comma-Separated Values (CSV) ready to import into Linear, or as Extensible Markup Language (XML) for the Atlassian / Jira importer. The exported file always carries the relevant PRD context and the original user quotes alongside the ticket.
There is also a Settings area where the PM can edit every prompt the AI uses, set their tone preferences, and tune the RICE weights. A product context captured during onboarding (product name, audience, guardrails, competitors, existing live features) is automatically prepended to every prompt so the AI's outputs stay on-brand without the user having to repeat themselves.
How we built it
Lumen is a single repository with a Next.js 14 front end (App Router, TypeScript, Tailwind) and a FastAPI back end (Python 3, async throughout). They communicate over a normal Hypertext Transfer Protocol (HTTP) JSON API, plus Server-Sent Events (SSE) for everything that takes more than a couple of seconds.
Front end. The user-facing app is built on Next.js 14 with the App Router. We use a small shared api client that automatically attaches a Bearer token (kept in localStorage) to every request, plus a dedicated SSE helper (connectSSE) with exponential-backoff retries and an optional fallback that polls a GET /api/v1/jobs/{job_id}/status endpoint when the stream drops before a done event arrives. Drag-and-drop on the roadmap board uses @dnd-kit/core and @dnd-kit/sortable. Modal dialogs, tabs, and toasts come from Radix UI primitives. The PRD editor renders Markdown live with react-markdown and exports to Portable Document Format with @react-pdf/renderer. The signal graph view is built on react-force-graph-2d.
Back end. FastAPI serves a versioned /api/v1 namespace with one router per stage of the flow: authentication, product, projects, sprints, ingest, synthesize, decide, generate (PRDs), design (wireframes), comms, handoff (tickets), and settings. We use Pydantic v2 for request and response models, async SQLAlchemy (with asyncpg) for the database, and parameterized raw Structured Query Language (SQL) where we need tighter control over things like vectors, arrays, and JavaScript Object Notation Binary (JSONB) columns. For long generations, the routers return SSE streams instead of waiting for the full response.
Database and migrations. We run Postgres on Supabase. The schema is defined in two migrations: a first cut and then a clean-slate restructure that locked in the strict one-user-to-one-product model and added automatic updated_at triggers on every table. The schema covers users, products, projects, sprints, signals, themes, personas, features, artifacts (PRDs, wireframes, comms documents), tickets, prompts (per-user editable), tone configuration, and RICE weight configuration. Because Supabase exposes a transaction-mode connection pooler (PgBouncer), we had to disable both asyncpg's and SQLAlchemy's prepared statement caches and assign every prepared statement a Universally Unique Identifier (UUID) -based name to avoid collisions on reused backend connections.
Embeddings and vector search. Every ingested signal gets a 1536-dimensional embedding from OpenAI's text-embedding-3-small model, computed on the cleaned post-tag text. Embeddings are stored directly in Postgres using the pgvector extension on the signals.embedding column, with a Hierarchical Navigable Small World (HNSW) index using cosine similarity. When a key is not configured, the embedding service falls back to a deterministic pseudo-random vector keyed off the input text so the rest of the pipeline still runs end-to-end for local smoke tests.
Theme clustering. Theme synthesis is the only place we run a real "Retrieval-Augmented Generation (RAG) -like" loop, and it is deliberately scoped. We pull every signal embedding for the sprint, run scikit-learn's KMeans with k = min(9, max(2, n // 5)), then for every cluster centroid we ask Postgres for the top ten signals nearest that centroid (ordered by cosine distance with pgvector's <=> operator). Those top-ten quotes are what the Large Language Model (LLM) actually sees when it names the cluster — not a random sample. After the model returns names and severities, we run a second pass that retries any cluster that came back unnamed (or with a placeholder like "Cluster 3"), then merge near-duplicate names and absorb tiny clusters into their nearest neighbor before persisting.
LLM orchestration. All model calls go through a single provider-agnostic wrapper (call_llm) that maps two logical roles — smart (Claude Sonnet 4.6 class) and fast (Claude Haiku 4.5 class) — to concrete model identifiers. Anthropic is the primary path; OpenAI's GPT-5 / GPT-5-mini sit behind the same interface as a fallback. The wrapper normalizes Anthropic and OpenAI responses into one shape ({text, tool_calls, stop_reason}) so the rest of the codebase never sees provider-specific JSON. Streaming is supported on both providers, again as a single normalized event format.
Product context injection. Whenever a route passes a project_id into the LLM wrapper, the wrapper joins through the projects table, fetches the owning product row, and prepends a <product_context>...</product_context> Extensible Markup Language (XML) block to the system prompt. Every downstream stage — tagging, clustering, feature proposals, PRD writing, wireframes, comms, ticket generation — gets the same grounding without each module having to fetch product context on its own.
Structured outputs. Tagging, clustering, feature proposals, PRDs, wireframes, comms, and tickets all use Anthropic tool use (or its OpenAI equivalent) with strict JSON Schema definitions. That keeps the database honest — for example, the ticket tool requires acceptance_criteria to be an array of strings, size to be one of XS / S / M / L / XL, and dependencies to be a list of T-XX identifiers from the same call. After the model returns, we still run our own validation pass: deduplicating tickets, breaking dependency cycles with a depth-first search, dropping source_quote_ids that do not exist in the supplied signal allow-list, and clamping invalid sprint groups back to "sprint_1."
Streaming everywhere. Synthesis, feature proposals, PRD generation, comms generation, and ticket generation are all Server-Sent Event streams. Tickets and PRDs both use bounded-concurrency fan-out — three parallel workers behind an asyncio.Semaphore. PRDs use a custom stream_in_order helper so sections render top-to-bottom even though they are generated in parallel; tickets use stream_as_completed per sprint so each sprint column on the handoff board fills in independently and a single sprint failure does not wipe the others. Every long-running endpoint also writes its state into an in-memory job tracker so the front end can poll GET /api/v1/jobs/{job_id}/status if the stream disconnects mid-flight.
File parsing. The ingest pipeline handles .txt, .pdf (via PyPDF2), .docx (via python-docx), and .csv (via the standard library). Plain text is split into paragraphs; transcripts are auto-detected by looking for at least three timestamped speaker turns in the first two hundred lines and then split into one signal per non-interviewer turn. CSV ingestion picks the best text-bearing column from a small allow-list and falls back to concatenating all non-metadata columns rather than silently dropping a row. Tagging and embedding then run in parallel for each row behind another asyncio.Semaphore.
Exports to Supabase Storage. Ticket and PRD exports are rendered into bytes (Markdown, MCP JSON, Linear CSV, or Jira XML), uploaded to a lumen-exports bucket on Supabase Storage with upsert: true, and the resulting public Uniform Resource Locator (URL) is returned to the front end. Each export carries the same shape: ticket identifier, title, description, acceptance criteria, size and reasoning, dependencies (translated from Universally Unique Identifiers back to readable T-XX strings), the relevant PRD excerpt, and the original user quotes that motivated each ticket.
Authentication and product gate. Authentication is intentionally lightweight for a hackathon: a base64-encoded user identifier acts as the Bearer token, and the front-end layout enforces a "must complete onboarding before entering the app" gate by checking the has_product flag on the cached user object and live-checking the back end on every page load. Once a product exists, the layout resolves the active project, persists it to localStorage, and ensures the active sprint is loaded before rendering any of the staged pages.
Demo recovery path. Because we knew an AI-heavy demo can fall apart on stage, we added an environment-flag escape hatch. When LUMEN_DEMO_CACHE is enabled and the user is operating on the fixed demo sprint or feature, the synthesis, features, PRD, and tickets endpoints will replay pre-recorded JSON responses (dumped from a healthy run by a small dump_demo_cache.py script) instead of calling the model. The events are still emitted as SSE so the user-facing experience is identical.
Containerization. Both services have their own Dockerfile and run together via docker compose, with environment variables for the database URL, the Anthropic and OpenAI keys, the Supabase service key, and the front-end origin for Cross-Origin Resource Sharing (CORS).
Challenges we ran into
- Streaming cleanly across a chain of AI steps. Most of Lumen is "AI fans out, the database persists, the front end animates." Getting that to feel reliable — keeping ordering consistent, handling one slow model call without blocking the others, recovering when a stream drops mid-flight — took several iterations of the SSE helper, the bounded-concurrency wrappers, and the in-memory job tracker.
- Forcing structure onto AI output. Free-form text from a model is easy to render in a chat box, but the back end has to insert into typed columns and arrays. We ended up using strict tool schemas everywhere and adding a layer of post-validation on top — deduping tickets, breaking dependency cycles, retrying clusters that came back without a real name, and downgrading "direct OKR alignment" claims that did not actually quote the OKR.
- Honest scope on ingestion. A dream version of Lumen would pull from every support tool, every interview platform, and every app store. The version that actually ships supports document upload, plain text, and CSV. We documented what is in and what is not, and pushed connectors to the roadmap rather than faking them.
- Keeping the AI on-brand. Without grounding, every output started to drift toward generic "AI Product Manager" copy. The single
<product_context>block prepended to every prompt was the fix — but getting every router to passproject_idthrough, and keeping the block readable for the model, took a few rewrites. - Database pooling on Supabase. Supabase's pooled connection mode does not play nicely with prepared-statement caches. We chased a few "duplicate prepared statement" errors before realizing we needed to disable both layers of caching and give every prepared statement a unique name.
- Chunking the right way and writing prompts that actually use the context. Getting clean context out of the uploaded files was much harder than it looked. A long interview transcript split naively in the middle of a thought would strip the user's pain of its surrounding setup, and the AI would either over-summarize it or miss it entirely. Comma-Separated Values exports from support tools were even worse — the useful column was rarely the first one, and concatenating every column dragged in metadata the model treated as user voice. We iterated heavily on speaker-turn splitting for transcripts, paragraph-level splitting for documents, and a small allow-list plus fallback for choosing the best column in a Comma-Separated Values file. On top of that, the prompts themselves had to be tightened over and over: early versions of the tagging prompt produced generic tags like "feedback" and "issue" that destroyed downstream clustering, the early naming prompt returned bland labels like "Search issues," and the early Product Requirements Document prompt happily invented user pain that no signal supported. The fix was a mix of stricter examples in each prompt, severity and citation rules that name the failure modes out loud, and a post-validation step that rewrites or drops anything that does not trace back to a real signal identifier.
- Demo robustness. Hackathon networks are unreliable. Building the demo cache recovery path — and the small script that dumps a healthy run into static JSON — was unglamorous work, but it is the reason the live demo actually walks end-to-end.
Accomplishments that we're proud of
- One continuous flow, not seven disconnected screens. Upload → Synthesis → Features → Roadmap → PRD → Wireframe → Comms → Tickets are all wired into a single shared data model, so a user really can walk from raw feedback to exported tickets in one session.
- Themes that feel earned, not invented. Using real embeddings, real clustering, and centroid-based retrieval (instead of asking a model to "find themes" in one shot) made theme names specific enough that PMs reading them could immediately tell which signals fed which theme.
- A drag-and-drop pipeline board. Now / Next / Later columns with RICE scores, OKR alignment tags, and MoSCoW badges, all reorderable by dragging — built with
@dnd-kitand an optimistic update path so moving a card feels instant. - Four real export formats. Markdown, MCP JSON, Linear CSV, and Jira XML — each carrying acceptance criteria, sizing reasoning, dependency links, and the original user quotes attached as evidence. Engineers downstream do not have to take Lumen's word for anything.
- Clickable lo-fi wireframes. Not static images — a sandboxed React preview where the buttons actually navigate, a state object actually patches, and every interactive element is wired back to a Product Requirements Document metric or user story so the PM can see, in one place, what each click is supposed to move.
- Streaming everywhere it matters. PRD sections, feature proposals, comms drafts, and ticket batches all stream in as the model produces them, with per-section persistence so a partial failure does not wipe the whole artifact.
- A spec page that brings everything together. For any single feature, one route loads a streaming PRD editor, an evidence drawer linked back to the original user signals, and a clickable wireframe preview — so reviewing a feature does not mean opening five tabs.
What we learned
- Product Manager work is orchestration, not one giant prompt. A chain of small, stateful steps — each with strict inputs and outputs — produces dramatically better results than asking a model to "write me a PRD" in one go.
- Embedding plus clustering plus a real retrieval step beats a single global "find the themes" prompt. The themes that come out of Lumen are specific because the model sees the most representative quotes, not a random sample.
- Streaming and per-chunk updates matter as much as the underlying model. Watching a PRD assemble section by section feels completely different from watching a spinner for forty seconds.
- Inject the same product truth everywhere or the AI drifts. A single shared product context block, prepended to every system prompt, is the difference between "AI Product Manager" and "AI Product Manager for this product."
- The handoff is the product. A tool that produces a beautiful PRD but no machine-readable ticket export is a tool that engineers will quietly stop using. Getting Markdown / MCP JSON / Linear / Jira out the door turned Lumen from a demo into something a team could actually ship through.
What's next for Lumen
Things on our radar:
- A live Model Context Protocol (MCP) server for Lumen. Today we export a static MCP-shaped JSON file. Next, we want a real MCP service that exposes sprints, features, PRD slices, and tickets as tools and resources that an Integrated Development Environment (IDE) or coding agent can pull from directly.
- Two-way integrations with the trackers. Push and pull with Linear, Jira, Figma, and Notion — not just the one-shot exports we have today.
- Audio and richer ingest. Add Whisper (or a similar speech-to-text engine) so users can drop in interview recordings and call transcripts directly, with chunking and speaker turns.
- Scheduled competitor and review ingest. Automated pulls of competitor reviews and app-store feedback into the same signal → theme flow.
- Backend-driven pipeline status. The sidebar's stage hints are currently a light client-side heuristic; a richer server-tracked pipeline state would let dashboards and notifications hang off the same source of truth.
Ideas we want to explore:
- Customer support connectors. Zendesk, Intercom, and Front so support volume becomes a first-class signal source.
- A Figma plugin for the wireframe handoff so design hand-off lands as real Figma frames or structured user-experience notes tied to the Product Requirements Document.
- Prompt evaluation harness. Golden runs for every stage so a tweak to one of the editable prompts in Settings cannot silently regress quality elsewhere.
- Real multi-user workspaces, Role-Based Access Control (RBAC), and production authentication. Today's flow is hackathon-appropriate local sessions; a real team would need shared workspaces, roles, and proper login.
- Bring Your Own Key (BYOK) and enterprise deployment options. Self-hosted Lumen, with the customer's own model keys.
- An executive "decision memo" view. A one-page summary of what was decided, why, and what would change our minds — generated alongside every feature.
Lumen: feedback → priorities → spec → handoff, in one continuous flow.
Built With
- asyncpg
- fastapi
- lucide-react
- next.js-14
- openai
- pgvector
- postgresql
- pydantic
- react-18
- scikit-learn
- sqlalchemy
- storage
- tabs
- tailwind-css-4
- text-embedding-3-small
- uvicorn


Log in or sign up for Devpost to join the conversation.