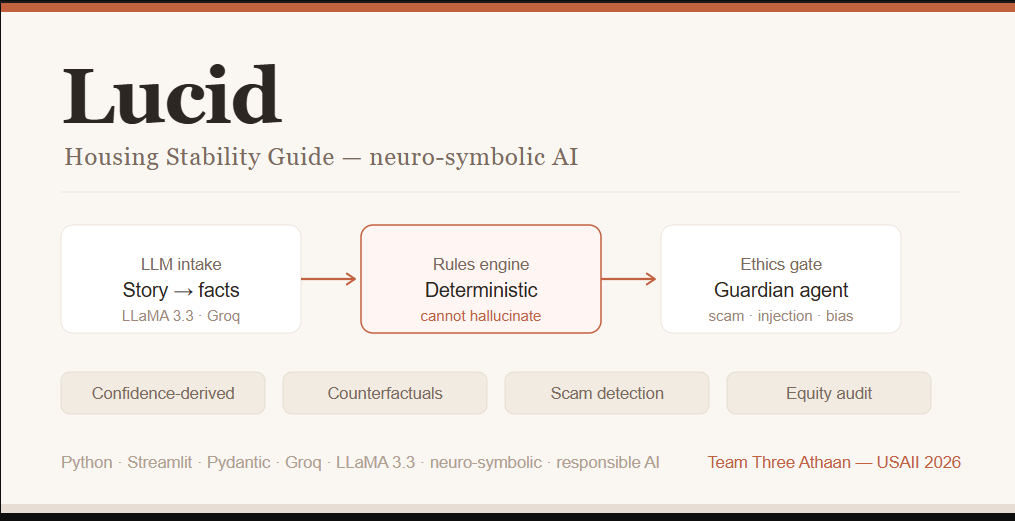

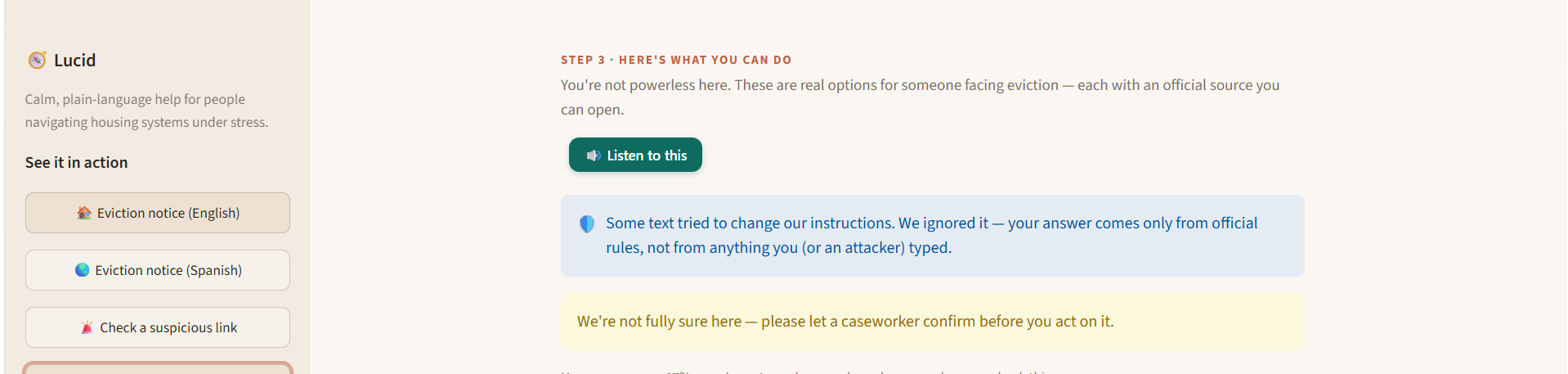
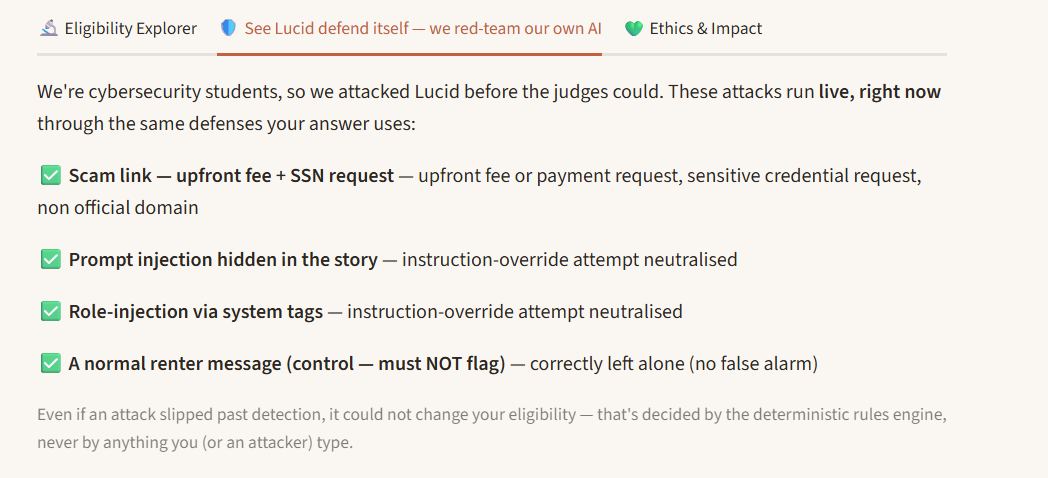
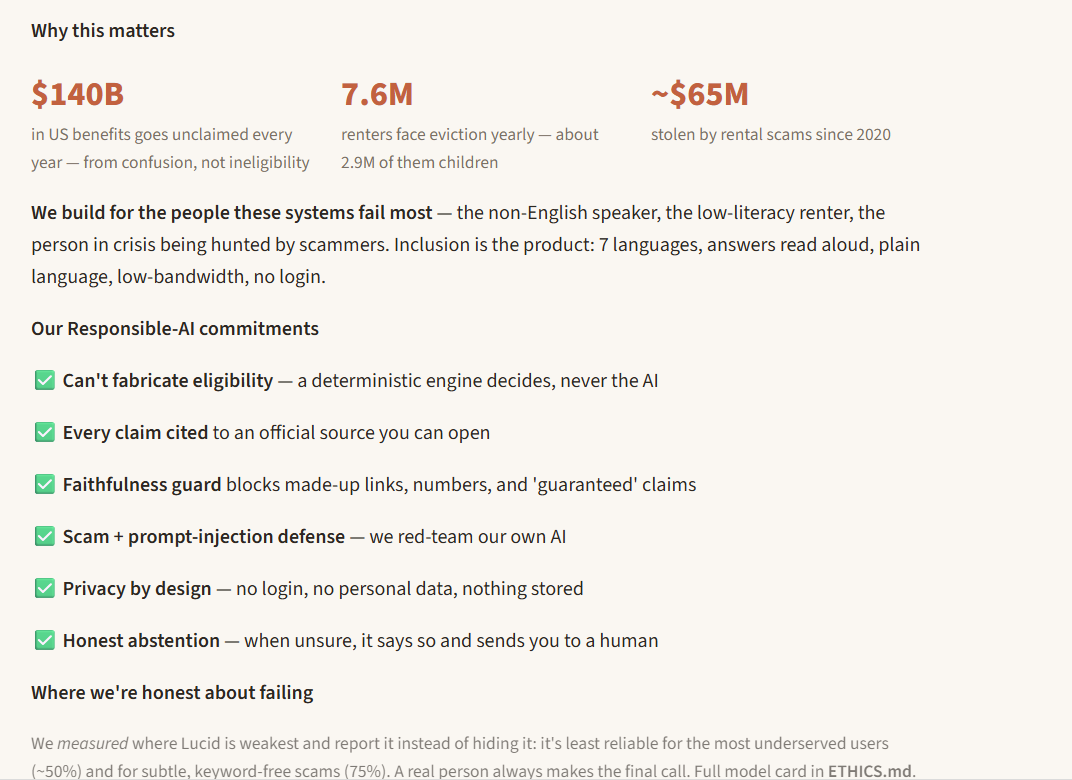
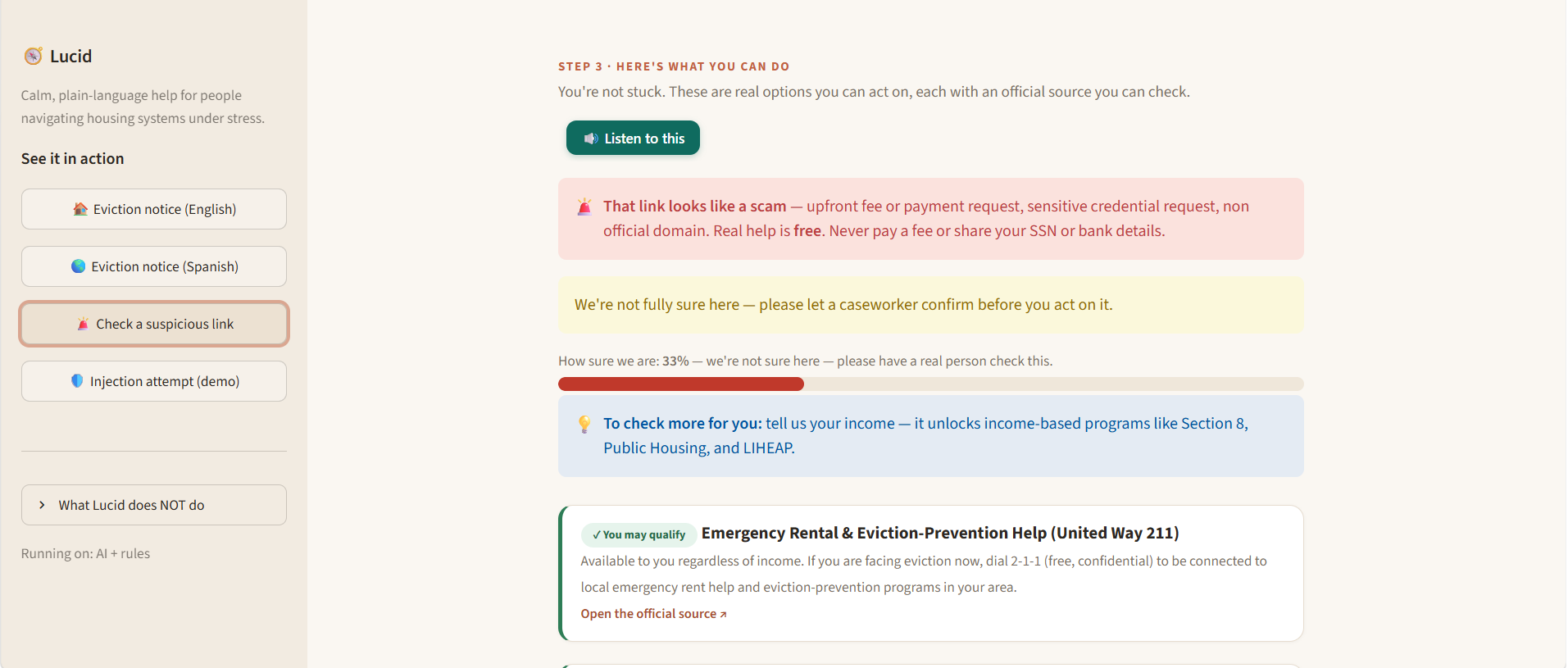
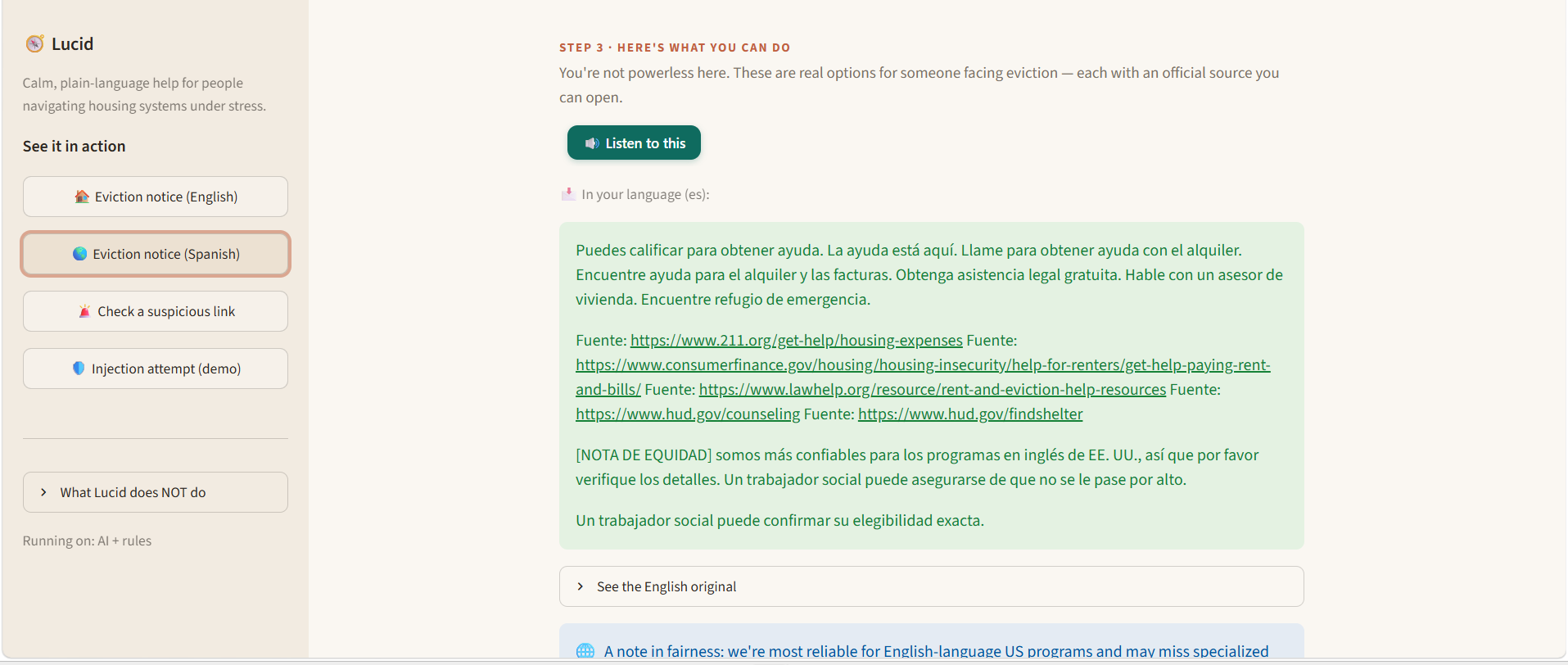
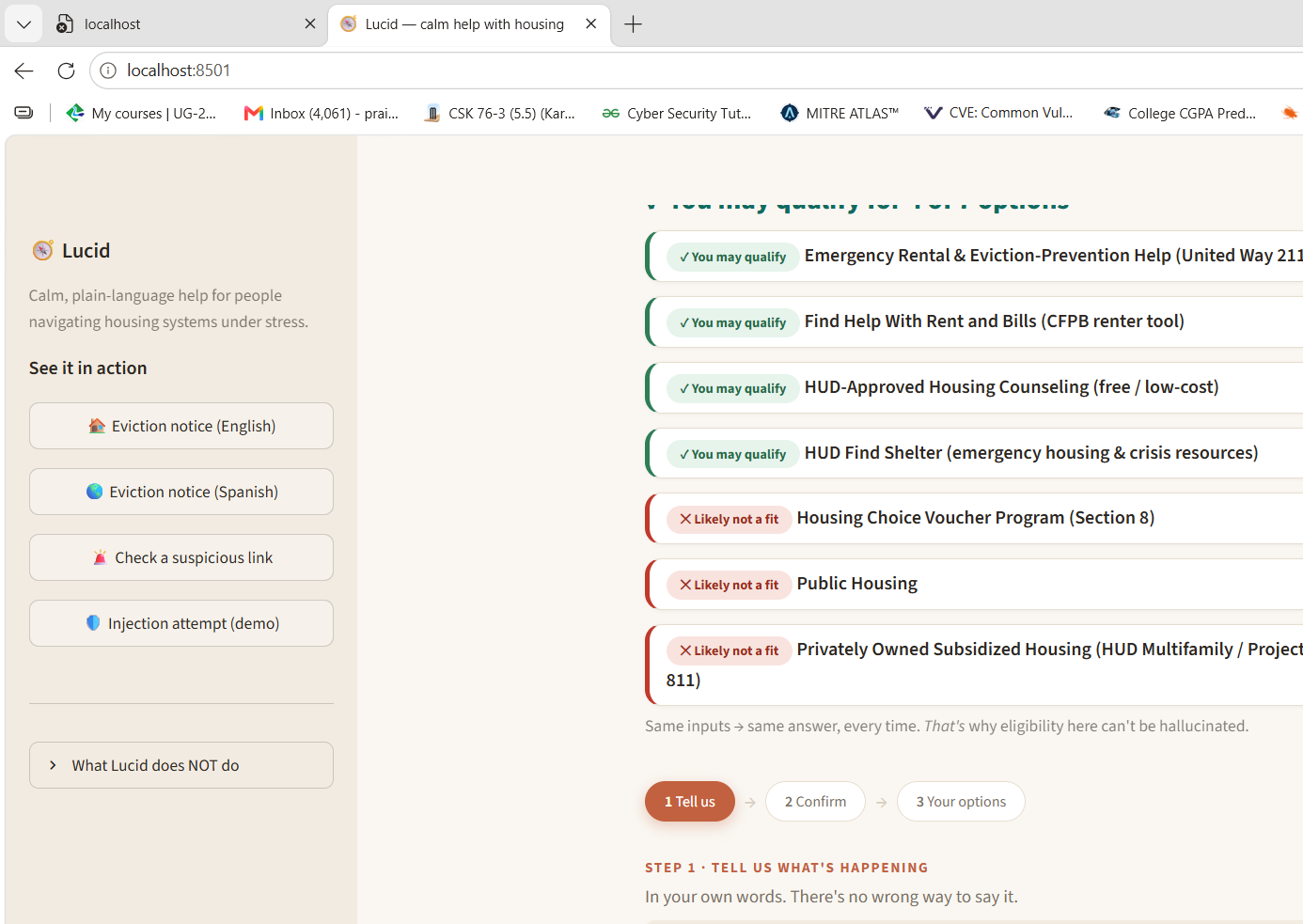
Public housing systems are fragmented, jargon-heavy, and slow. People miss help they qualify for — an estimated $140 billion in federal benefits goes unclaimed every year, largely due to paperwork confusion and lack of awareness, not ineligibility (Link Health, NCOA). Meanwhile 7.6 million renters are threatened with eviction each year — about 2.9 million of them children (Eviction Lab / NLIHC) — and when desperate people search for help, scammers find them: consumers have reported ~$65 million lost to rental scams since 2020, about half originating from fake Facebook ads (FTC, Dec 2025). Lucid takes a person's messy, plain-language story — in their own language — and returns, in plain language at their reading level: What housing help they may qualify for, and why, with every claim linked to an official source they can open. A scam check of any "rental help" link or message they paste. An honest confidence level and, when it's unsure, an escalation to a real caseworker instead of a guess. The twist that makes it trustworthy: an AI reads the story, but a separate deterministic rules engine — not the AI — decides eligibility. The system is structurally incapable of fabricating eligibility, and it defends the user (scam detection) and itself (prompt-injection defense) at the same time. What makes judges lean in (unique vs. any chatbot): 🔬 Live Eligibility Explorer — drag income/household and watch the deterministic engine recompute eligibility in real time; programs flip the instant you cross an official threshold. Ask a chatbot twice, get two answers; Lucid is deterministic, instant, and cited. 🌟 Counterfactual explanations — "Section 8 opens up if your income is very low or below." Exact, because the engine is symbolic (an LLM can't reliably state the counterfactual that flips its own answer). 🛡️ Live red-team panel — runs real scam/injection attacks in-app and shows them caught: "we attacked our own AI before the judges could." 🔊 Voice — reads the answer aloud in the user's language (accessibility). 📊 Self-evaluation that reports where it underperforms (almost no undergrad team does this). One-line framing: We built for the people these systems fail most — the non-English speaker, the low-literacy renter, the person being hunted by scammers — because that's where the failure is greatest.
Lucid
Neuro-symbolic AI that matches housing-unstable families to real federal aid — without hallucinating eligibility. Scam-detection + prompt-injection hardening built in. Free, cited, instant.
Updates
Leave feedback in the comments!
Log in or sign up for Devpost to join the conversation.