-
-
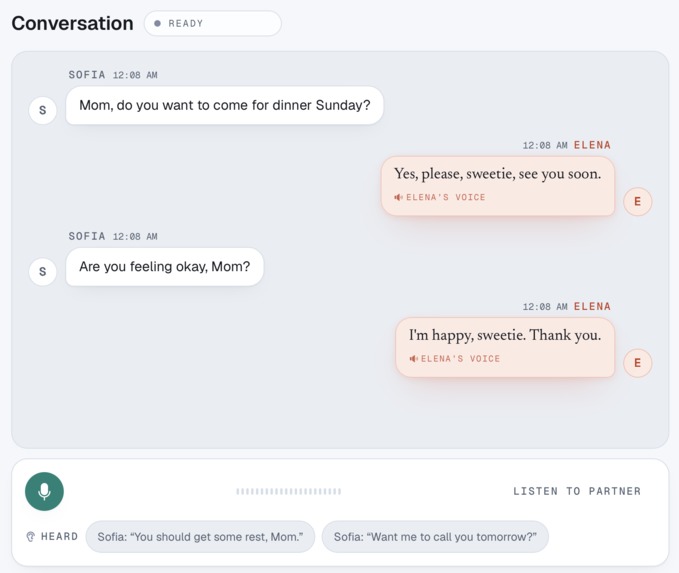
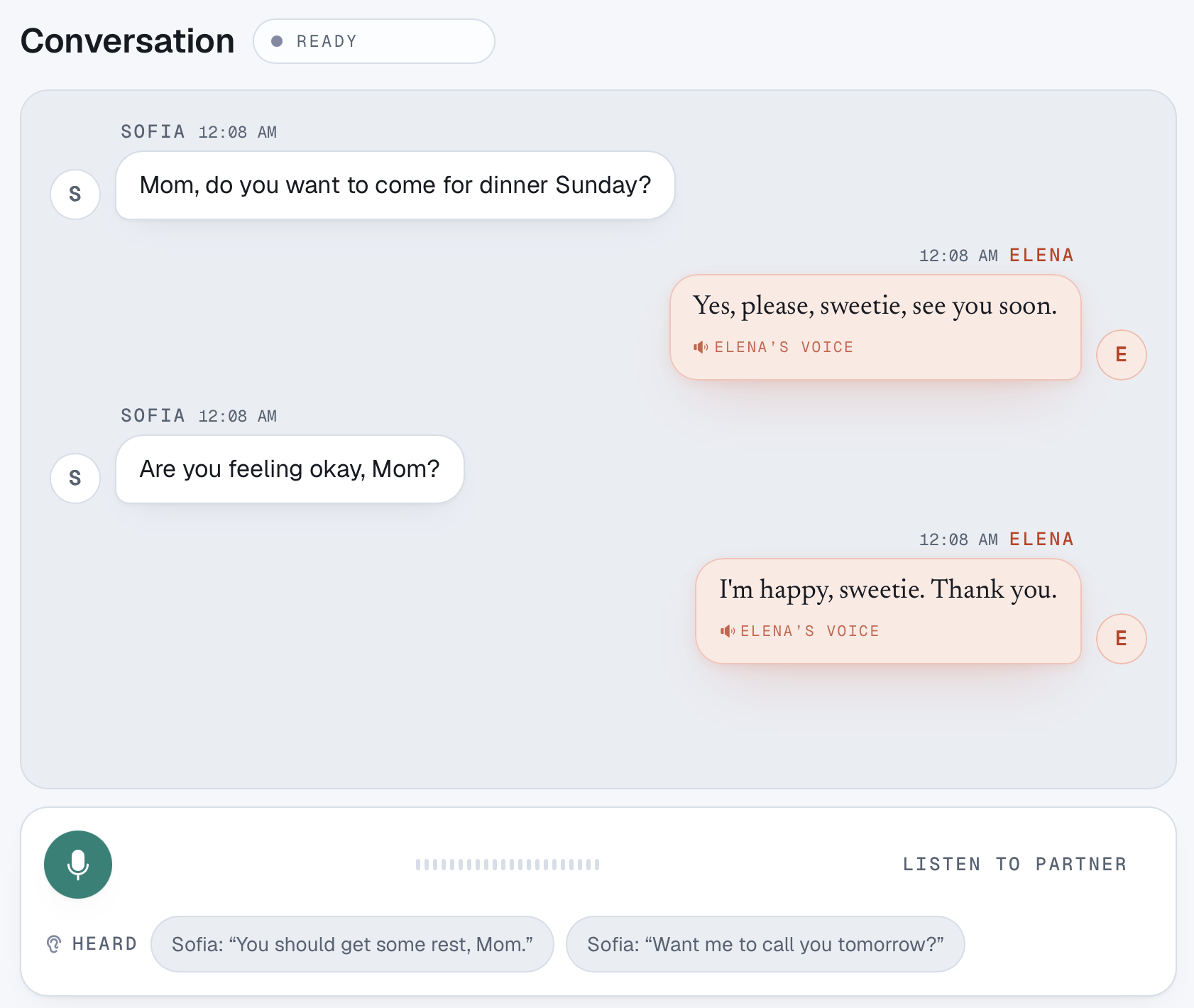
Conversation in Your Own Voice From a Few Taps
-
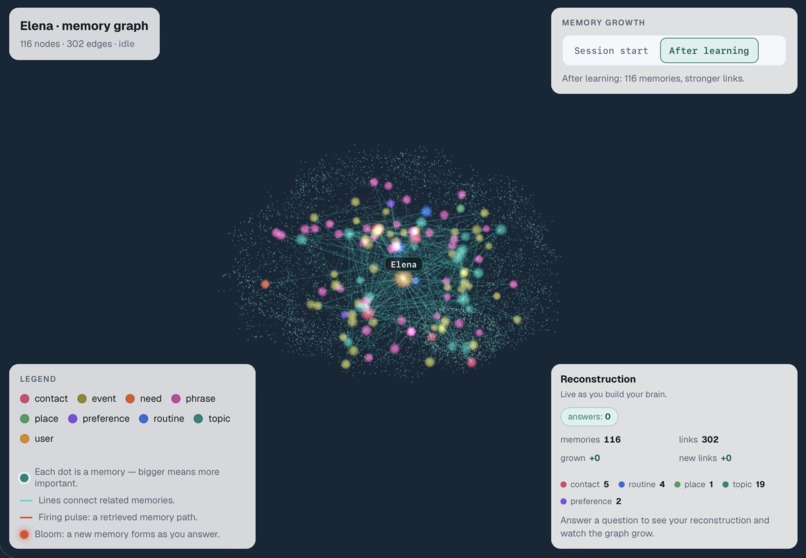
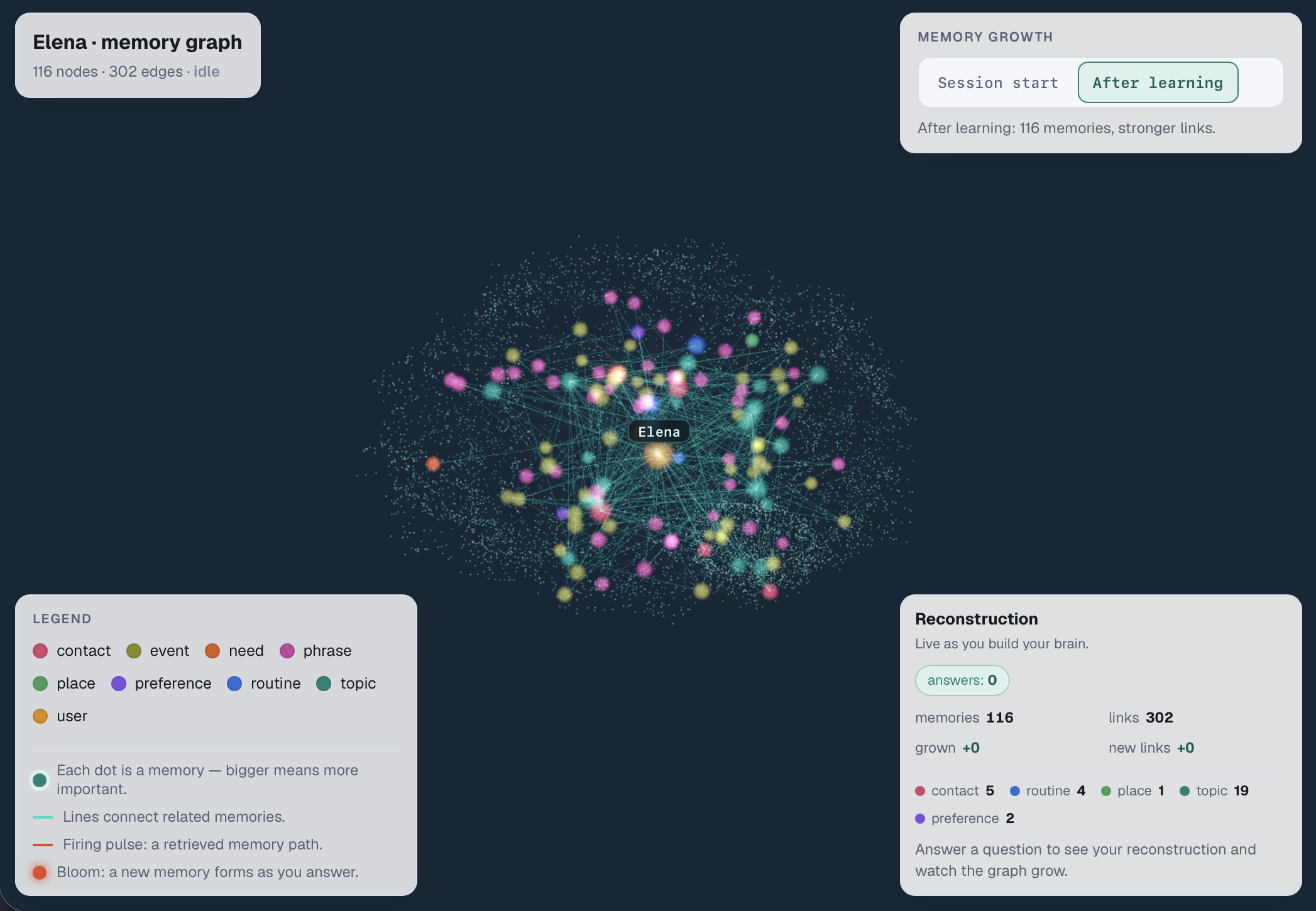
A Living Map of your Brain Which Learns
-
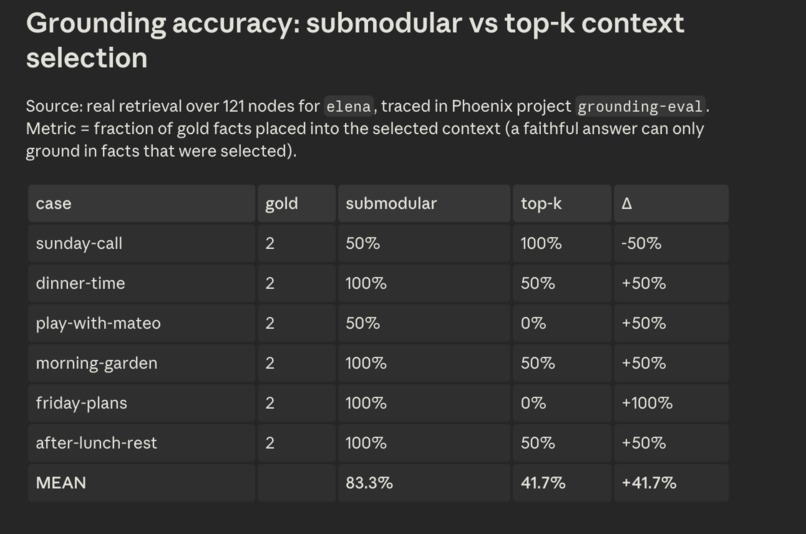
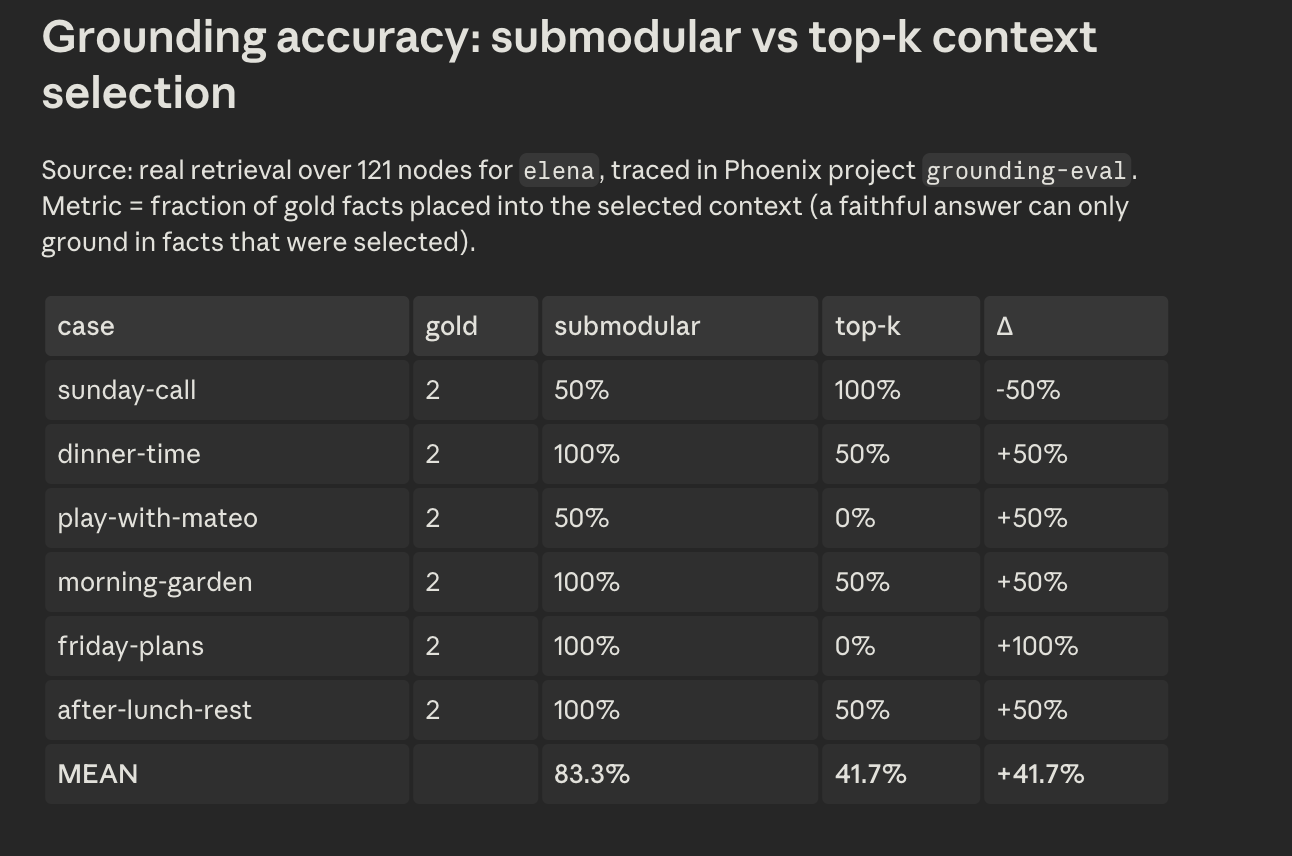
Azure Phoenix Grounding Evaluation
-
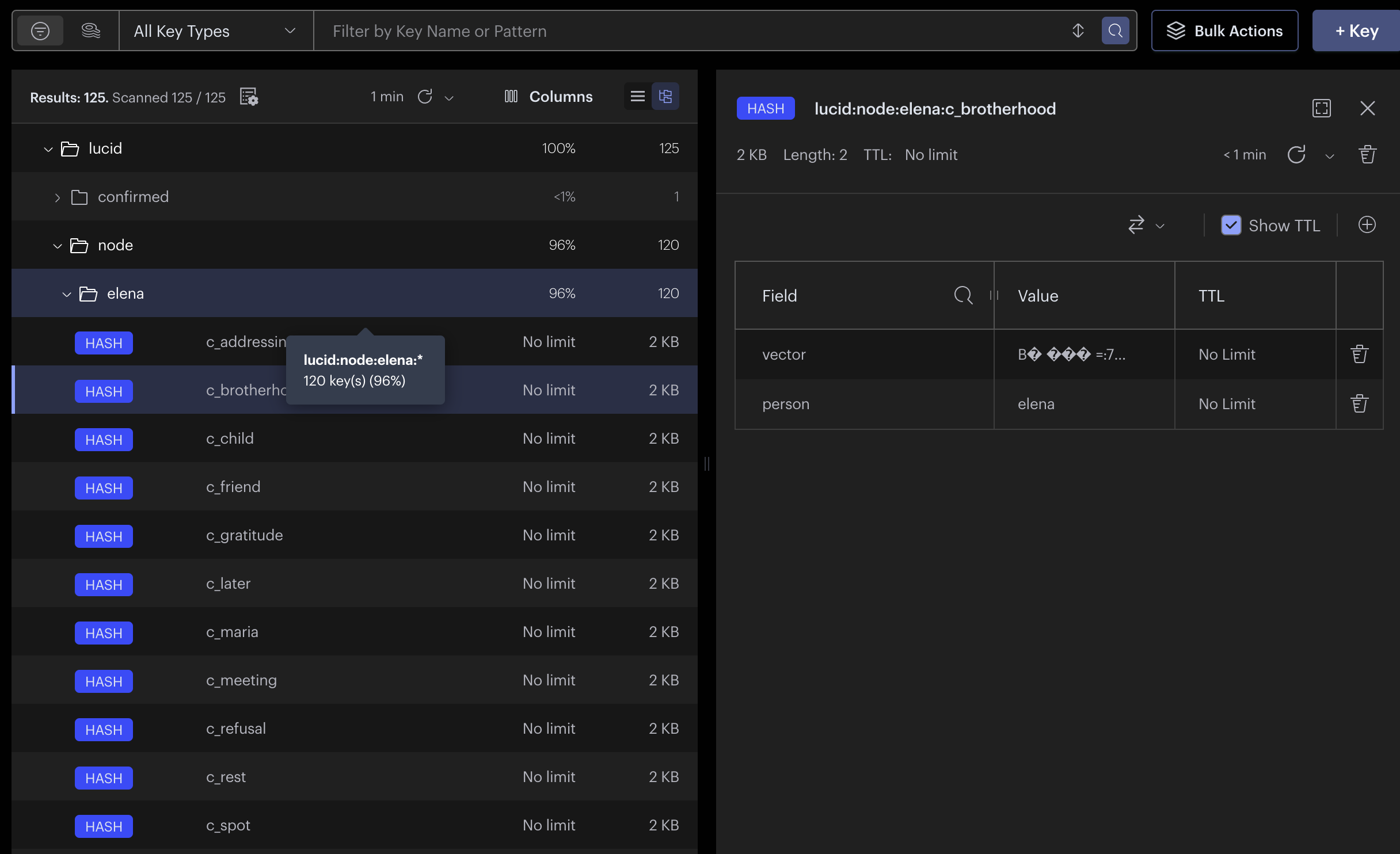
Redis Database Vector Index
Inspiration
An estimated five million Americans and nearly a hundred million people worldwide cannot rely on their own voice, from ALS, stroke, autism, or cerebral palsy. The cruelest part of conditions like aphasia is that the person knows exactly what they want to say but cannot get the words out, and today's tools are slow and robotic. We wanted to build something that knows the person and gives them their own voice back.
What it does
Lucid Voice turns two or three tapped words into a full, natural sentence, spoken in a clone of the person's own voice. It is not autocomplete: it understands who they are talking to, so the same words become "sweetie" for a daughter and "mijo" for a grandson, and it learns their style the more they use it. Behind it is a personal "brain," a living model of their world that you can watch think, learn, and grow, and the whole thing runs on-device and offline so their private words never leave their hands.
How we built it
Lucid Voice is local-first. A personal knowledge graph (Kuzu) holds the person's people, routines, and preferences; a hybrid retrieval pipeline traverses that graph and uses a submodular optimization to pick the most relevant facts, which steer a frozen local model (Gemma via MLX on Apple Silicon) to write the candidates. Two learning systems sit on top: the graph reinforces associations the way memory does, and a style model learns the user's phrasing from which suggestions they pick, using the same preference formulation behind RLHF. Voice cloning (XTTS) and speech recognition (Whisper) run on-device too, with Redis for local vector search, Deepgram, Sentry, and Claude Code in the stack, and nothing on the core path touches the internet.
Challenges we ran into
On-device voice cloning sent us down a brutal dependency chain through torchaudio, torchcodec, and FFmpeg. Responses took sixty seconds until we found the model was burning thousands of reasoning tokens we then discarded, and turning that off made it near-instant. We also fixed a race that resurrected stale suggestions against the wrong line of conversation. The hardest part was conceptual: making the system truly understand the person rather than guess, and solving the empty-graph cold-start, which led to the mode where the assistant interviews the user to build their brain.
Accomplishments that we're proud of
We built a complete real-time AI system, graph reasoning, generation, voice cloning, and speech recognition, that runs entirely on a laptop with the internet off, which is rare in a year when capable AI usually means a data center, and it keeps a vulnerable person's words private. We are proud that the context-awareness works, that the same input yields the right different sentence per person, and that the learning is real and visible on screen. And we kept the person in control by always proposing and letting them choose, never speaking for them.
What we learned
We went deep on running large models locally and fast, hybrid graph-and-vector retrieval, optimization, and preference learning. The bigger lesson was that sophistication only matters if people can see it, so we put the reasoning, learning, and growth on screen, and that preserving the user's agency and dignity matters more than any clever trick.
What's next for Lucid Voice
Richer automatic context like identifying who is speaking from their voice, more input methods such as eye-gaze and switch access for later-stage ALS, and real testing with the AAC and disability community and clinicians. Longer term, an opt-in cloud quality tier, deeper personalization as the brain grows, and getting it into the hands of the millions who could use it.
Built With
- anthropic-claude
- apple-silicon
- arize-phoenix
- bge-embeddings
- bge-embeddings-graph-database:-kuzu-vector-search-and-memory:-redis
- claude-code
- coqui-xtts
- deepgram
- fastapi
- faster-whisper
- ffmpeg
- ffmpeg-voice-(api):-deepgram-observability:-sentry-evaluation:-arize-phoenix-platform:-apple-silicon
- framer-motion
- gemma
- git
- github
- javascript
- javascript-frontend:-react
- kuzu
- lm-studio
- local-first
- local-first-/-on-device-tooling:-git
- macos
- mlx
- pydantic
- python
- pytorch
- pytorch-retrieval-and-embeddings:-sentence-transformers
- react
- react-force-graph
- react-force-graph-backend:-fastapi
- redis
- redisearch
- redisearch-voice-(on-device):-coqui-xtts
- sentence-transformers
- sentry
- tailwind-css
- typescript
- uvicorn
- uvicorn-ai-and-local-inference:-claude-code
- vite
- whisper

Log in or sign up for Devpost to join the conversation.