💡 Inspiration
We live in an era of "doom-scrolling." Most of us end our days staring at blue light, scrolling through static feeds that keep us awake and anxious. We wanted to invert this relationship with our devices.
Instead of a phone being a source of stimulation, could it be a portal to Hypnagogia—the lucid state between wakefulness and sleep?
We didn't want to build another chatbot or a simple image generator. We wanted to build a sensory engine. We were inspired by the phenomenon of "8D Audio" and ASMR, but we noticed a gap: existing apps rely on pre-recorded loops. They are static. We wanted to create a system that could look at any image or idea—a photo of your childhood home, a generated fantasy world, or a picture of a rainy street—and physically reconstruct the audio of that space around your head. Not just play sounds—move them through 3D space in real time, synchronized to a hypnotic narration that pulls you into the scene.
🥣 What it does
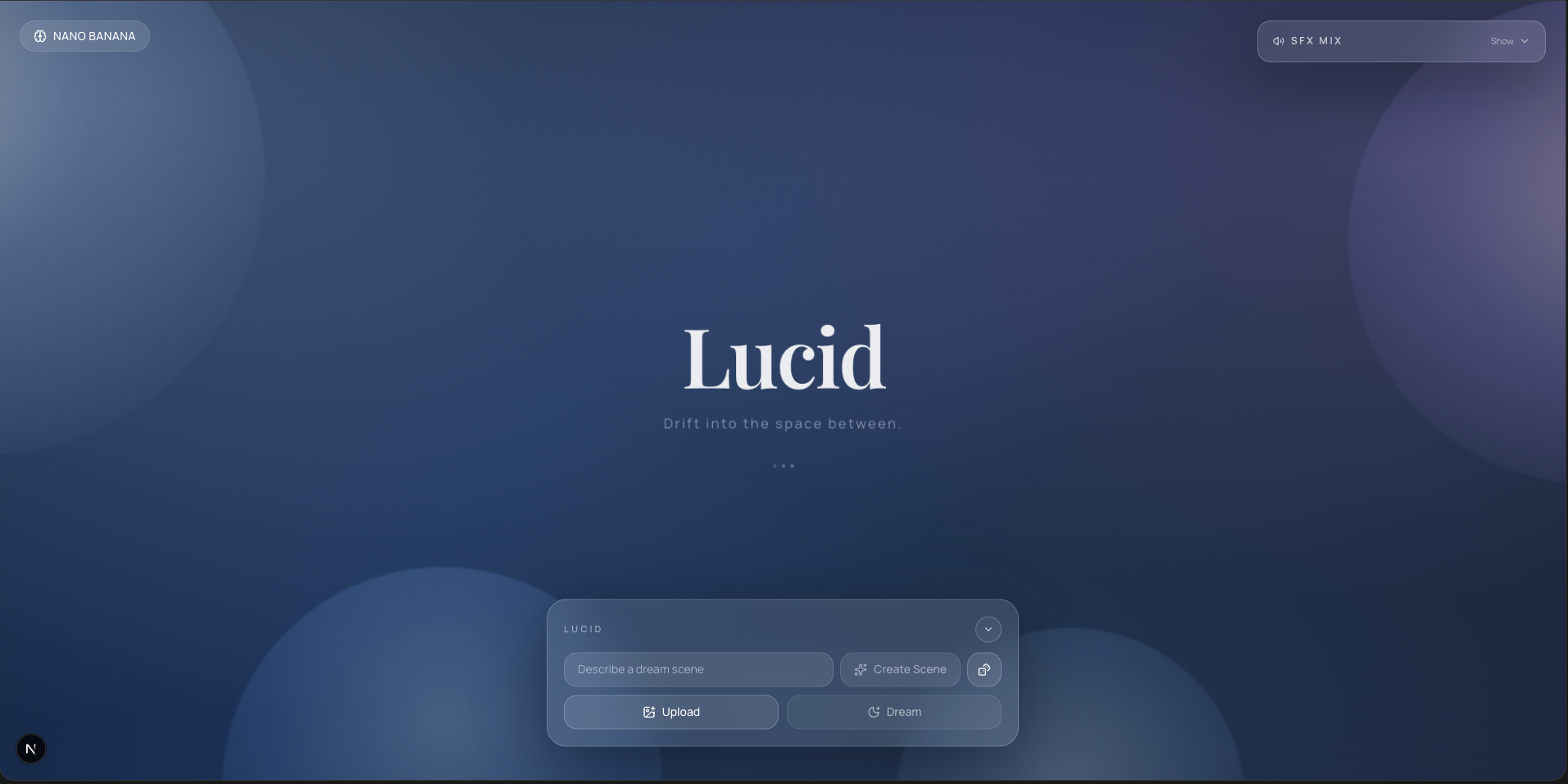
Lucid is an intelligent, multimodal dreamscape generator.
- See: You upload an image or type a scene description to generate a liminal dreamscape using Gemini's native image generation (Nano Banana / Nano Banana Pro). Hit the dice for a random scene.
- Analyze: Gemini 3 Flash analyzes the scene—not just for objects, but for spatial physics, depth, and sound. It produces a timed dream timeline: e.g,. a river flowing on your left from 0–45s, a fire crackling behind you from 10–60s, wind sweeping right-to-left from 20–50s—each with start/end 3D positions so sounds travel through space.
- Synthesize: ElevenLabs generates a hypnotic, second-person ASMR narration (via Multilingual v2) and custom sound effects for each cue (via the Text-to-Sound-Effects API)—all in parallel.
- Orchestrate: The core magic. Lucid's custom timeline engine, built on the Web Audio API with HRTF PannerNodes, renders a real-time binaural 3D soundstage. Sounds don't just play—they move. A car passes from your left ear, through center, to your right. Rain drifts. Wind sweeps. Every sound fades in and out on its own envelope, and the entire soundscape is synchronized to the narrator's playback position.
⚙️ How we built it
The architecture relies on a high-velocity stack: Next.js, React 19, TypeScript, Tailwind CSS, Framer Motion, and Zustand for state management.
The Intelligence Layer (Gemini 3 Flash)
We chose Gemini 3 Flash for its speed and multimodal capabilities. Using strict JSON schema mode, Gemini analyzes the uploaded/generated image and outputs a structured dream object containing:
- A narrative: a short, second-person, hypnotic ASMR script.
- A timeline: 2–5 spatial sound cues, each with a text prompt (for SFX generation), start/end times, fade-in/fade-out durations, volume, loop behavior, and start and end 3D positions enabling sound movement over time.
The Image Layer (Gemini Native Image Generation)
Users can type a scene prompt or hit randomize. We use Gemini 2.5 Flash Image (Nano Banana) or Gemini 3 Pro Image Preview (Nano Banana Pro) through OpenRouter to generate surreal, first-person, liminal dreamscapes. The high-res toggle lets users choose between speed/cost and quality.
The Audio Engine (Web Audio API & HRTF)
This was the hardest technical challenge. We couldn't just use stereo panning—we needed true 3D spatial audio. We built a custom timeline engine from scratch:
- Each sound effect is routed through its own HRTF PannerNode, which models how sound waves physically interact with the shape of the human ear to create phantom 3D positioning.
- A requestAnimationFrame loop runs continuously during playback, reading the narrator's current time, mapping it to the timeline, and for each cue: computing a fade envelope, interpolating between start and end 3D positions via lerp, and updating the PannerNode coordinates—every frame.
- The narrator sits in the center channel so it feels intimate and close, while the environmental sounds swirl around the listener's head.
- All audio (narrator + all SFX) is generated in parallel, preloaded into blob URLs, and wired into a Web Audio graph of source → panner → gain → master gain → destination.
The Voice & Sound Effects (ElevenLabs)
ElevenLabs Multilingual v2 generates the Dream Guide narration with tuned voice settings for a calm, ASMR whisper. Each of Gemini's sound cue prompts is sent to the ElevenLabs Text-to-Sound-Effects API to generate custom audio—looping ambient textures or one-shot effects.
🧠 Challenges we ran into
- Building a timeline engine from scratch. No library exists for "play 5 spatial audio tracks, each fading in and out on their own schedule, while moving through 3D space, all synced to a narrator." We had to build the entire orchestration layer on top of raw Web Audio API and requestAnimationFrame.
- Getting Gemini to output reliable structured JSON. Even with strict JSON schema enforcement, the model occasionally produced invalid output. We implemented a retry loop (up to 3 attempts) with full validation and clamping of every field to ensure the outputs are parsed properly.
- Smooth fade envelopes. Without proper fades, sounds pop in and out jarringly—the opposite of dreamy. We implemented per-cue envelope computation with configurable fade-in/fade-out durations, clamped to never exceed half the cue's total duration.
🏅 Accomplishments that we're proud of
- It's not a wrapper. We didn't just wrap an API. We built a custom Spatial Audio Timeline Engine in the browser—position interpolation, fade envelopes, narrator-synced playback, and a full Web Audio node graph, all from scratch.
- The Vibe. The first time we tested it with headphones and heard rain explicitly hitting the "window" to our left while a fire crackled behind us, it felt like magic. You genuinely forget you're wearing headphones.
- Sounds that move. Each sound cue has a start and end 3D position. The engine lerps between them every animation frame, so a gust of wind can sweep across your head, or footsteps can walk past you. This isn't static spatial audio, it's animated.
- Real-time SFX Mix panel. Users get per-cue volume sliders so they can boost the rain, dim the fire, and craft their own mix. Master volume control sits on top.
- Adaptive UI. The control panel automatically detects the luminance of the underlying image and switches between light and dark glass themes so it's always readable—no manual toggle needed.
- Parallel generation pipeline. Narrator voice and all sound effects are generated simultaneously via Promise.all, with proper preloading and blob lifecycle management. The whole dream materializes as fast as the slowest API call.
📚 What we learned
- How HRTF spatial audio actually works. Head-Related Transfer Functions model the way sound waves diffract around the human skull and pinnae. The Web Audio PannerNode with HRTF mode does this math for you, but understanding the coordinate system, distance models, and rolloff factors was a deep learning curve.
- Building a real-time audio timeline in the browser. We learned to use requestAnimationFrame to drive a per-frame update loop that computes envelope gains, interpolates 3D positions, and keeps an entire soundscape in sync with a single narrator track.
- Orchestrating multiple AI services into one pipeline. Gemini for vision and structured analysis, ElevenLabs for voice synthesis and sound effect generation. Coordinating these services with proper error handling, retries, and parallel execution taught us a lot about production AI orchestration.
🚀 What's next for Lucid
- Head Tracking: Using the webcam or device gyroscope to track the user's head rotation, so if they turn their head left, the sound of the fire stays fixed in space (creating a VR-like audio experience).
- Mobile App: Turning Lucid into a native mobile experience for bedtime use.
- Multi-Scene Narratives: Generating sequences of connected dreamscapes that flow into each other—a full dream journey, not just a single scene.
- Community Dreamscapes: Letting users save, share, and remix each other's generated dreams.
Built With
- elevenlabs
- gemini
- nextjs
- tailwind
- typescript
- zustand


Log in or sign up for Devpost to join the conversation.