Lst & Fnd - AI-Powered Campus Lost & Found
Inspiration
Ever lost your phone on campus? Or your student ID? We have. And the "solution" is always the same: run around to different buildings, fill out paper forms, check bulletin boards, and basically just hope someone found it and turned it in.
This is broken.
In 2025, we have AI that can understand images and text. Why are we still using paper forms and bulletin boards for something so important? We decided to fix this problem the way it should be fixed - with actual working AI that matches what you lost to what's been found.
What It Does
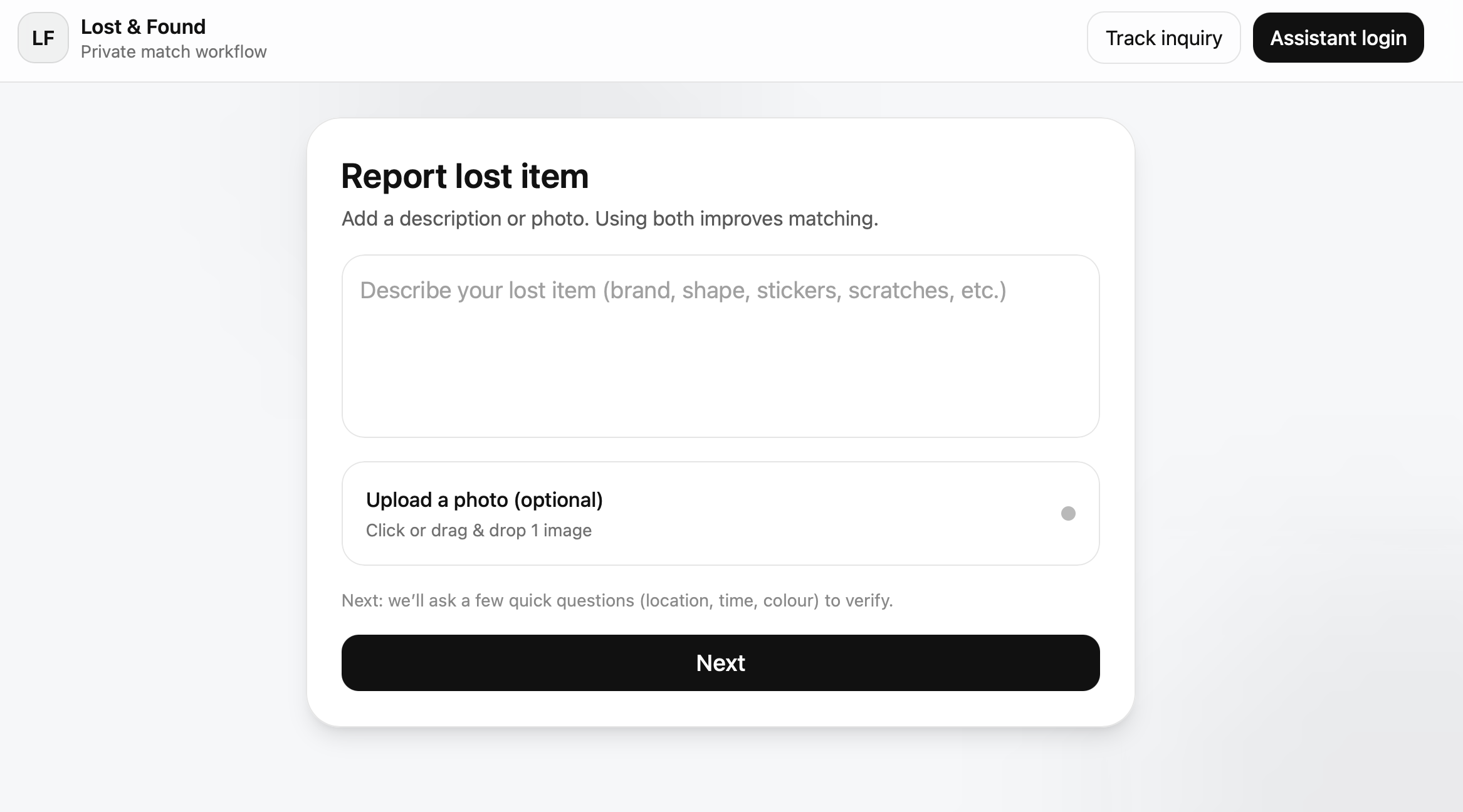
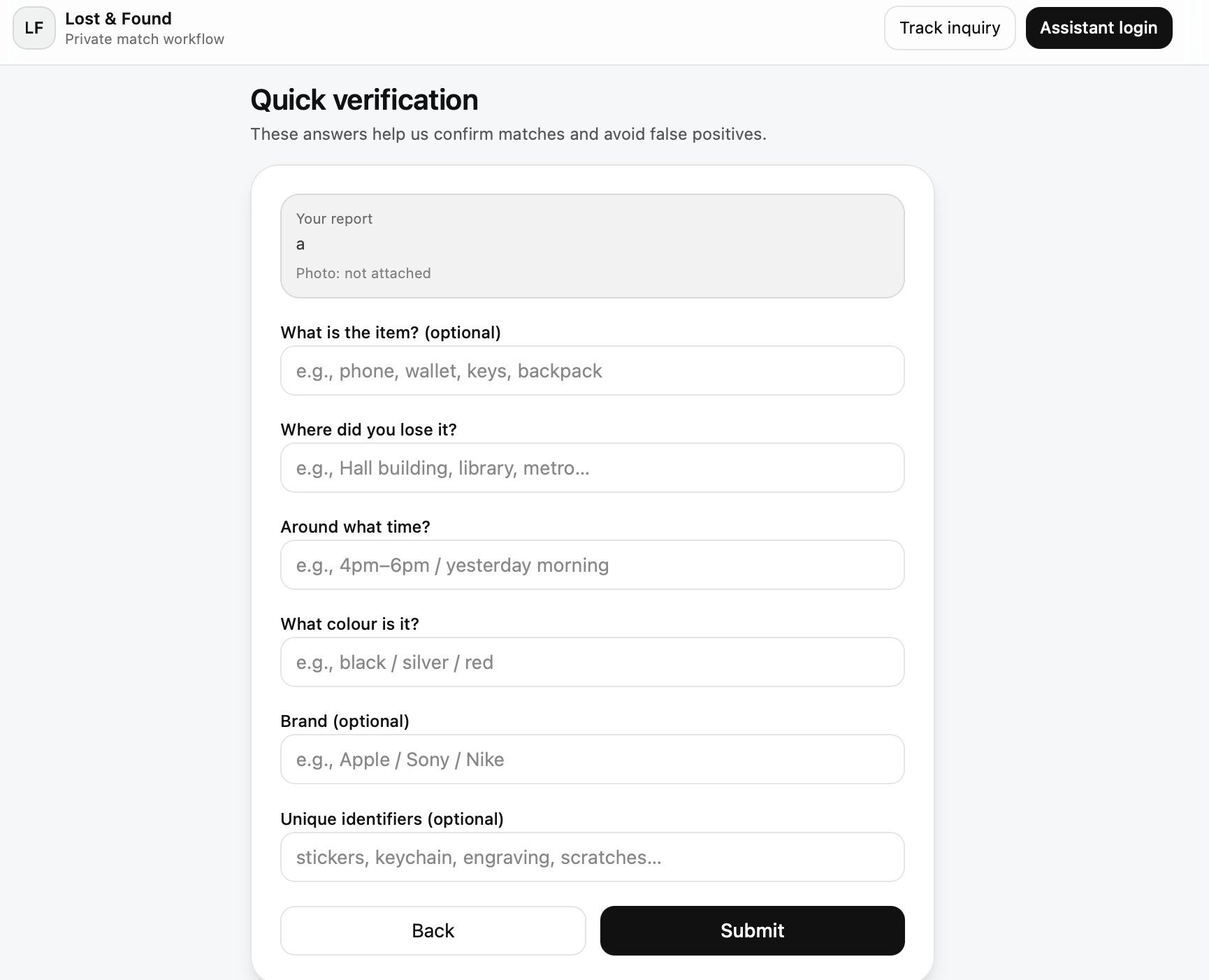
For Students:
- Snap a photo or describe what you lost
- Answer a few quick questions (where you think you lost it, when, what color)
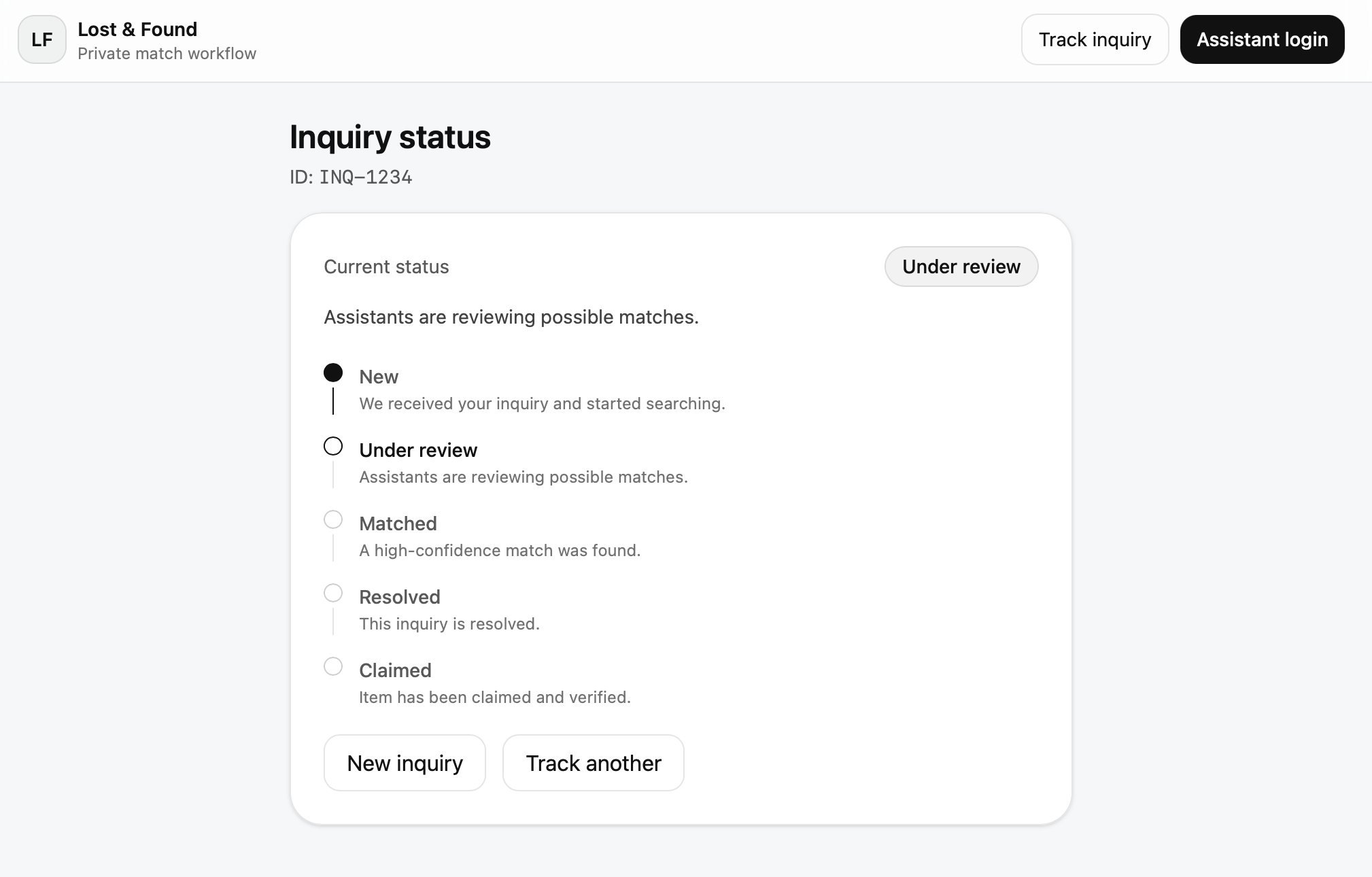
- Get a confirmation and track your inquiry status
- We'll show you matches that actually make sense (not just keyword matches)
For Campus Staff:
- Login to a simple dashboard
- Add found items with photos and details
- Review and approve matches when students report lost items
- Manage the whole lost & found process digitally
The Magic: Our AI doesn't just match keywords. It understands meaning. A photo of a "blue backpack with black straps" will match a text description of "blue bag with black handles" because the CLIP model understands they're the same thing.
How We Built It
Frontend (React + Vite): Clean, modern interface that actually works on mobile. Routes for reporting, tracking, admin login, and dashboard. Had to fight with Vite's security settings to get ngrok working - that was fun at 2 AM.
Backend (Go): HTTP API for auth and admin stuff, plus gRPC for the heavy ML lifting. JWT auth to keep the admin dashboard secure. Postgres with pgvector for storing and searching embeddings.
ML (Python + PyTorch): This is where the magic happens. CLIP model running on GPU generates 512-dimensional vectors from images and text. We built both a REST API and a gRPC service because... well, we thought it would be cool to use both.
Database: Postgres + pgvector extension. Stores the embeddings and does similarity search in under a second.
The Glue: Everything talks to everything. Frontend hits the ML API, ML talks to Go backend via gRPC, Go stores vectors in Postgres. We even have a run_all.sh script that starts literally everything - including ngrok for public access.
Challenges We Ran Into
4 Services, 0 Sleep: Coordinating Go backend, Python ML gRPC, Python ML REST API, React frontend, and ngrok was... interesting. Spent way too much time killing processes that were hogging ports.
Node Version Hell: Vite needed Node 20+, but the system had Node 18. Had to upgrade everything mid-hackathon.
ngrok + Vite Security: Vite blocked our ngrok URL for "security reasons." Had to configure allowed hosts and expose everything properly.
gRPC Contract Pain: Our proto definition was too simple. We were returning match results as a comma-separated string because the response type only had success and message fields. Yeah, that's a hack we're not proud of.
Duplicate Detection vs Testing: Our fraud prevention was working too well - it kept blocking our own test submissions because we were using the same images. Had to build switches to disable features during testing.
Accomplishments We're Proud Of
Real AI, Not a Demo: We're actually running CLIP on GPU and getting meaningful similarity scores. This isn't a mockup - it's the real deal.
Vector Search That Works: pgvector similarity search returning results in milliseconds. Seeing your lost item show up as the top match is an incredible feeling.
Complete Admin Workflow: Login, dashboard, add items, review matches. It's a real system, not just a one-trick pony.
Fraud Prevention That Matters: Duplicate detection, rate limiting, content validation. We thought about abuse cases and actually built protections.
One-Command Deploy: ./run_all.sh starts everything. No more "it worked on my machine" - it works on any machine with Docker and Node 20.
What We Learned
Multimodal is the Future: Combining image + text gives so much better results than either alone. Our matches are way more accurate because we're using both.
ML Needs Guardrails: Even in a hackathon project, you need to think about abuse. Spam, duplicates, fake submissions - they'll kill your system if you don't plan for them.
API Design Matters: Our minimal proto response bit us hard. Spending 10 more minutes on the contract would have saved hours of hacking around it.
Modern Tooling is Complicated: Vite, ngrok, CORS, gRPC - so many moving parts. But when it all works together, it's magic.
What's Next
Fix the gRPC Response: Upgrade the proto to return structured match objects instead of comma-separated strings. This is our #1 priority.
Real Notifications: Email/SMS when a match is found. Right now you have to check back, but we want to notify you automatically.
Better Scoring: Combine vector similarity with metadata matching (color, location, time) for even more accurate results.
Mobile Apps: React Native apps for iOS/Android so you can report lost items from anywhere on campus.
Production Deployment: Containerize everything, get a real domain, and deploy this for actual campus use.
Built with passion by students who've lost too many things on campus.
ConUHacks X 2026

Log in or sign up for Devpost to join the conversation.