
ThriftCycle started with a pretty simple observation: donated goods do not become useful the moment they hit a donation center. There is a messy, human, operational stretch in the middle where items get sorted, priced, routed, tagged, reprocessed, salvaged, or discarded. That middle layer matters a lot, and it is easy to overlook because most people only see the beginning and the end. We only see someone donating a bag, or something on a shelf with a price tag. We don't see the dozens of tiny decisions in between.
For the George Hacks Goodwill track, we kept coming back to that gap. A lot of ideas around donation tech sound good in theory, but they either start too early, like donor-facing apps, or too late, like sales analytics after the item is already on the floor. We wanted to work on the point where staff actually need help: when an item is in front of them, time is limited, and a decision has to be made. That became the heart of the project.
So we built ThriftCycle, a Goodwill operations demo that helps staff classify donated items, recommend a route, generate tag metadata, track Gaylords and containers, and update a manager dashboard with downstream operational signals. The goal was not to replace employees or pretend that one model can run a store. The goal was to make existing decisions faster, clearer, and easier to measure.
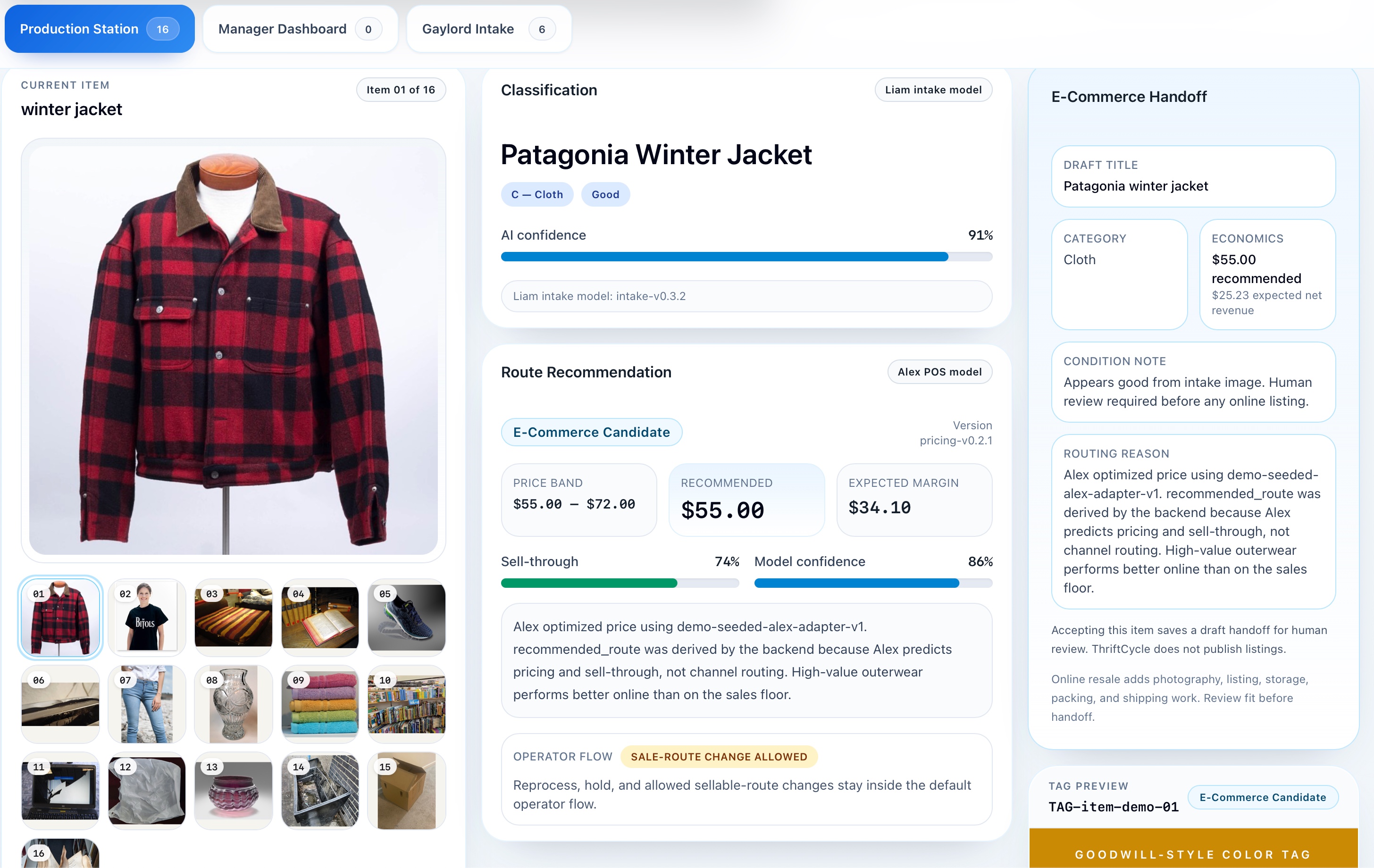
At the center of the experience is the production workflow. A staff member selects a demo item, the system classifies it, estimates price and channel economics, applies routing rules, and generates a recommendation for what should happen next. From there, the item can be accepted and persisted, and that action updates container fullness and dashboard metrics. That part was important to us because we did not want a dead-end classifier. We wanted the output to actually change the state of the system.
The project ended up with three connected surfaces. The first is the Production Station, where intake classification, pricing support, routing, and acceptance happen. The second is Gaylord Intake, where container-level tracking gives the physical workflow a digital trail. The third is the Manager Dashboard, which translates item-level decisions into staffing, pickup, revenue, and diversion signals. That combination let us tell one coherent story instead of building a bunch of disconnected features.
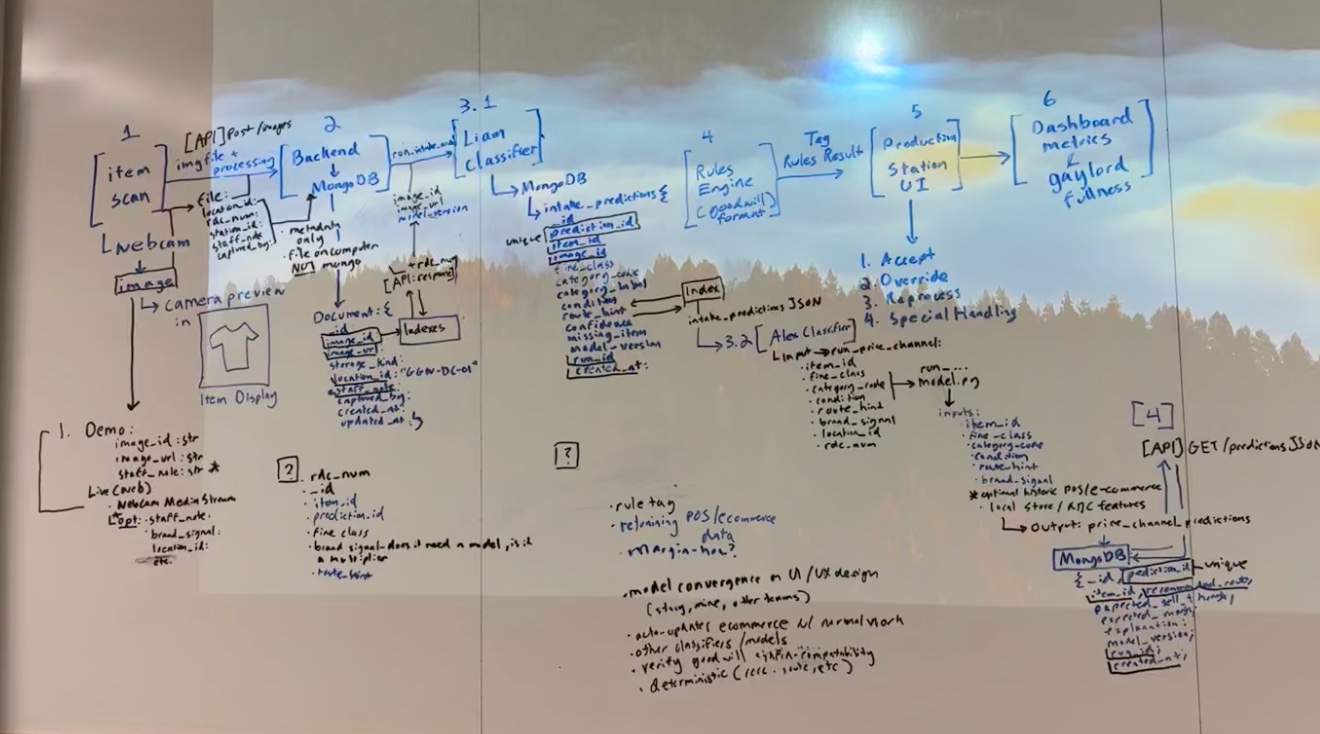
From a technical standpoint, we built the frontend in React, TypeScript, Vite, and Tailwind, with charts and UI primitives to make the operations flow readable and demoable. On the backend, we used FastAPI with MongoDB for persistence. We also split the AI-ish parts into two focused model surfaces. One path handles intake classification, based on Liam's normalized vision adapter. The other handles price and channel economics through Alex's pricing adapter. Final routing is not handed off blindly to a model. It is resolved through a rules layer, because operational policy should be explicit and inspectable.
That architecture mattered to us. We did not want to build a black box that spits out a confident answer and calls it done. In a real setting, an item's route is not just a prediction problem. It is a decision problem with cost, labor, safety, and downstream consequences.
One of the most important build decisions was keeping the demo grounded in what actually works in the repo today. We have a real frontend, a real FastAPI backend, Mongo-backed persistence, route evaluation, dashboard recomputation, and model adapters. At the same time, we were careful not to fake production readiness. The intake path for the final demo uses seeded demo items by image_id so the judging flow stays stable. That was a deliberate choice. We would rather be honest and reliable than pretend we solved live production image ingestion in one weekend.
The hardest challenge was scope. Goodwill's problem space is huge. Donation guidance, store operations, pricing, transportation, e-commerce, salvage, recycling, staffing, and reporting could each be their own project. We had to keep cutting back until the project had a clear wedge: make the production decision layer smarter, then show how that improves the rest of the flow.
Another challenge was deciding where models should stop and where rules should take over. It is easy in a hackathon to say "AI decides the route," but that is not actually a strong product decision. We learned quickly that some things are better left deterministic. If an item is unsafe, damaged, or clearly not appropriate for a certain channel, that should not be buried inside a vague confidence score. The system became much stronger once we treated models as structured inputs into a policy layer instead of as final authority.
What we learned from building ThriftCycle was not just how to wire together a frontend, backend, models, and data store. We learned how much product clarity matters when the domain is operational and messy. We learned that "better AI" is usually a weaker answer than "better decision support at the right step." We learned that explainability is not a nice extra in this kind of workflow. It is the difference between something staff can trust and something they will ignore. We also learned how much value comes from being precise about claims. A demo gets stronger, not weaker, when you are clear about what is live, what is deterministic, and what is future work.
The biggest thing we are proud of is that the project does not just classify an item and stop. It connects the classification to a real operational consequence. A tag gets generated. A route gets assigned. A container changes state. A dashboard updates. That made the project feel less like a concept and more like a small but believable piece of infrastructure.


Log in or sign up for Devpost to join the conversation.