
Inspiration
We were frustrated by how unreliable modern voice assistants feel. While testing, Google Maps’ Gemini took over 10 seconds to tell us where the nearest restaurant was. For something that simple, that delay felt unnecessary.
We asked a bigger question:
What happens when communities rely on these systems; during emergencies, in rural areas, or in low-connectivity environments?
If voice assistants are slow, cloud-dependent, and unpredictable, they fail the people who need them most.So we decided to build something local-first, resilient, and efficient.
What it Does
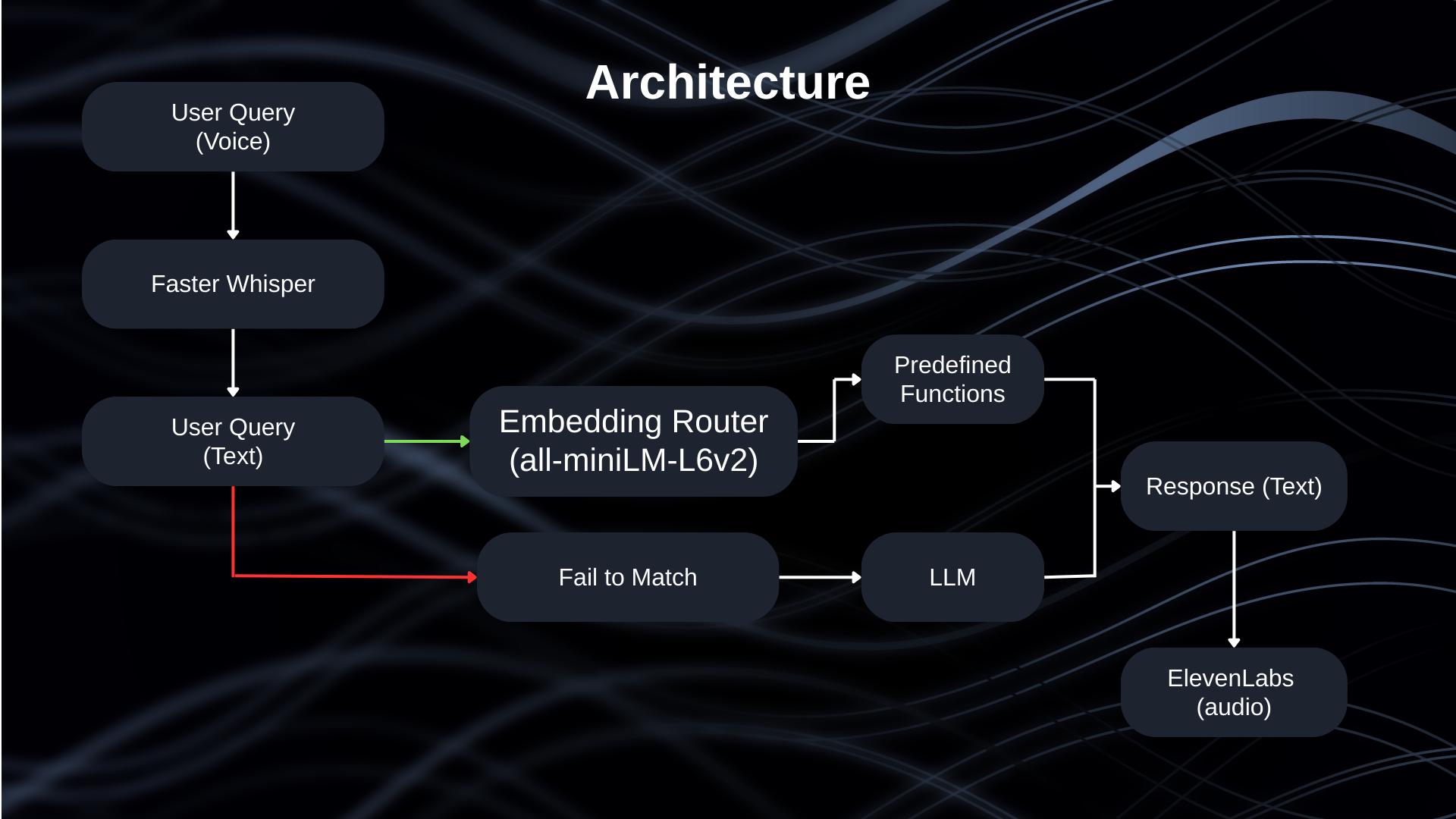
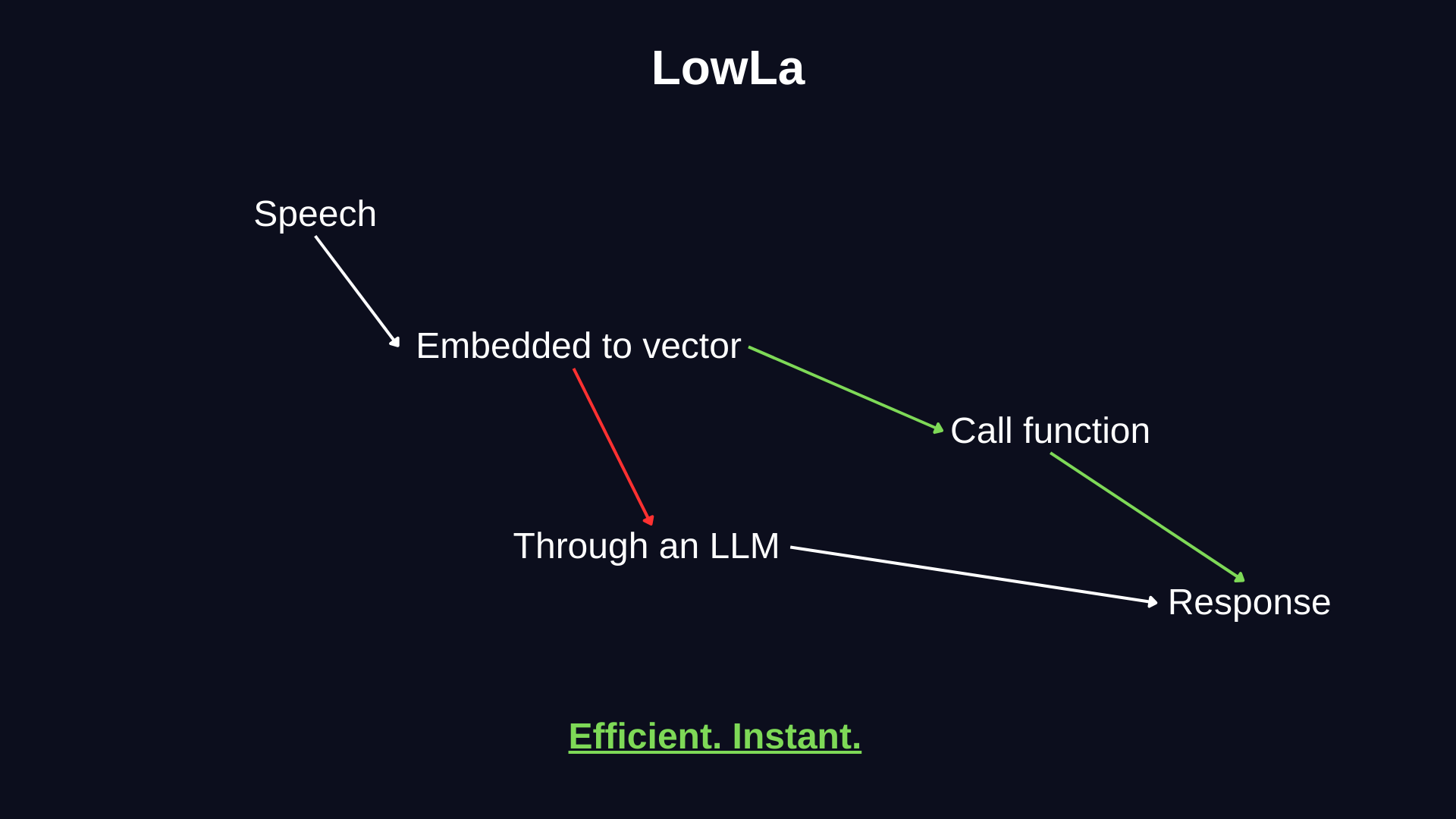
LowLa is a Low-Latency Intent Router for voice assistants.
Instead of sending every command to an LLM, LowLa:
Converts speech to text --> Embeds the command--> Searches a local Chroma vector database --> Executes instantly if there’s a confident match --> Falls back to an LLM only when necessary
In our demo:
Push-to-talk works Vector search via Chroma runs under 500ms LLM fallback works The hybrid system functions live We eliminated the regex layer after discovering that our vector search was fast and reliable enough on its own.
How We Built It
LowLa combines:
Faster Whisper for speech-to-text
Sentence Transformers (MiniLM) for embeddings
ChromaDB for vector search
Node.js for routing logic
Python backend for vector operations
ElevenLabs for text-to-speech
LLM fallback for unknown commands
Challenges We Ran Into
Virtual environment configuration delays
ElevenLabs API credit limitations
Latency tuning and threshold calibration
Keyword collisions in early routing logic
Tight hackathon time constraints
Accomplishments We’re Proud Of
Building a fully functional hybrid voice routing system
Eliminating unnecessary LLM calls for matched intents
Achieving sub-500ms local execution
Successfully running a live demo
Designing an adaptive architecture that improves over time
The biggest moment for us was realizing, "We can actually demo this live."
What We Learned
Retrieval is often more efficient than generation
Embeddings are incredibly powerful for flexible matching
Vector databases scale better than we expected
Latency matters more than model size
Integration across systems is harder than building individual components
Hybrid AI systems are more practical than purely LLM-based systems
We shifted from thinking “How do we use an LLM?” to “When do we not need one?”
What’s Next
With more time, we would extend LowLa into:
Predictive intent modeling (begin execution before the user finishes speaking)
Full wake-word integration
Personalized adaptive caching per user, perhaps based on career.
Multi-step and contextual command routing
Edge-device deployment optimization
Our long-term vision is a voice assistant that:
Learns once. Executes forever.
It's time to adopt the voice assistant that grows with you.



Log in or sign up for Devpost to join the conversation.