-

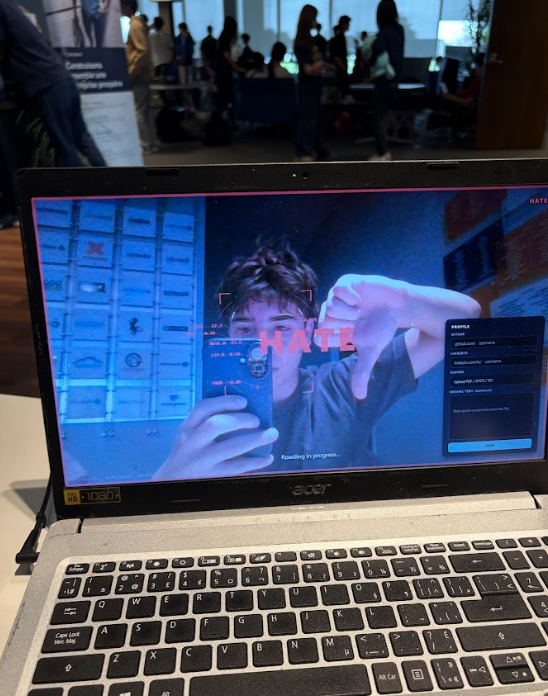
facial features being scanned through open cv
-
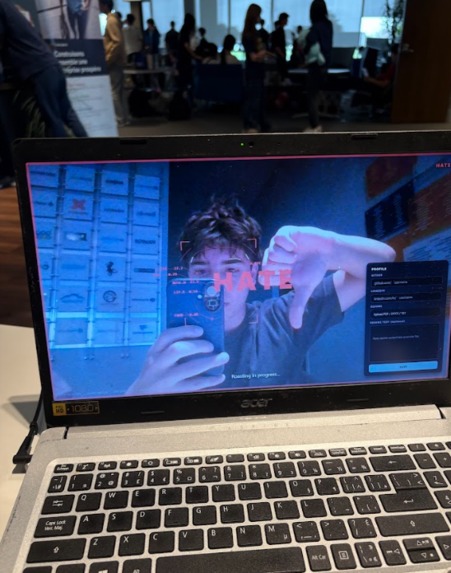
ENTERING HATE MODE
-
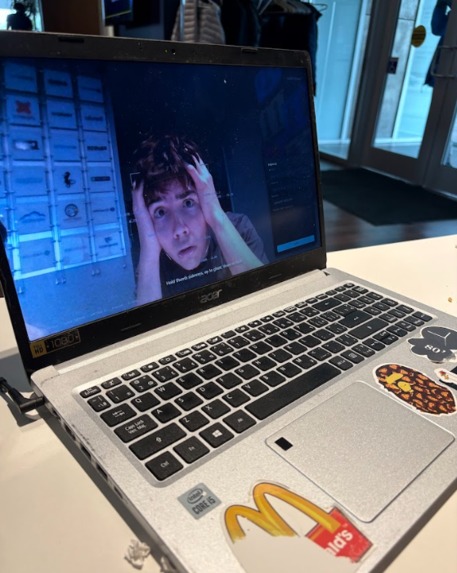
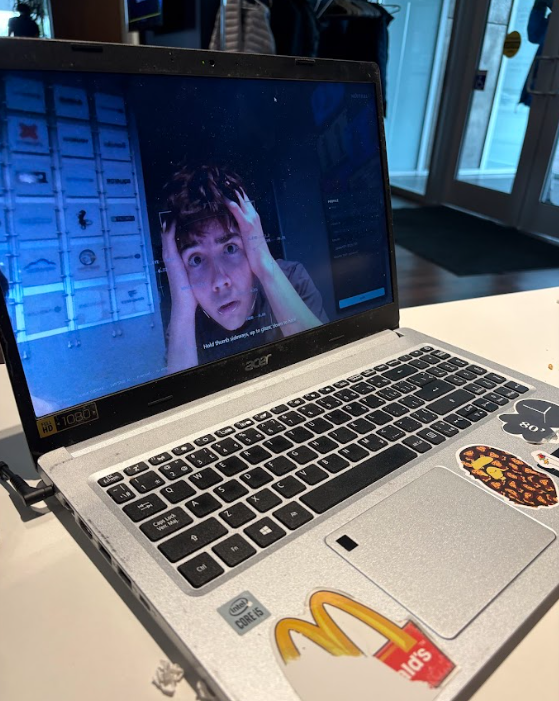
Man can't believe what he's hearing he's being roasted
-

Man LOVES what he's hearing, he's being glazed!


Inspiration
What it does
How we built it
PyQt6 for the desktop GUI and video loop OpenCV + MediaPipe for real-time face detection, facial landmark analysis (jaw width, symmetry, FWHR), emotion detection, and hand gesture recognition Grok (xAI) as the LLM — we send it a Base64-encoded face crop, extracted facial metrics, scraped profile data, and a system prompt tuned for each mode ElevenLabs for text-to-speech so the roast is delivered out loud GitHub REST API and Piloterr for scraping GitHub repos/stats and LinkedIn profiles in background threads PyPDF2 / python-docx to parse uploaded resumes A local JSON cache so profile data is only scraped once and reused across sessions
Challenges we ran into
Getting MediaPipe gesture recognition and face landmark detection to run simultaneously in real time without tangling threads or dropping frames took significant tuning. LinkedIn has no public API — scraping it reliably required routing through a third-party service and handling all the edge cases when profiles are private or incomplete. Prompt engineering for the roasts was harder than expected. Early versions were either too generic (ignoring the face data) or too mean-spirited without wit. Getting the balance of clever, specific, and funny required a lot of iteration on the system prompts. Syncing the ElevenLabs audio playback with the streaming LLM response without blocking the UI thread.
Accomplishments that we're proud of
The roasts are actually funny. Watching someone's face fall when the AI calls out their 47 half-finished GitHub repos alongside their jaw-to-forehead ratio is a genuinely great moment. The gesture-based mode switching feels natural — thumb up, thumb down, two thumbs down for chaos mode. No menus, no buttons. The full pipeline — face on camera → profile scrape → AI generation → voice playback — runs end to end in a few seconds. The caching system means repeat sessions are fast and the app doesn't hammer APIs unnecessarily.
What we learned
Multimodal prompts (image + structured text + profile data) produce dramatically more specific and entertaining outputs than text-only prompts. Real-time CV pipelines and UI responsiveness require careful threading discipline — PyQt signals/slots saved us from a lot of deadlock pain. ElevenLabs quality makes a huge difference in how a roast lands. Text on a screen is fine; hearing it spoken is brutal in the best way.
What's next for Love2Hate
Web version so it works without a local install — bring it to parties, events, and hackathon demos without setup friction Leaderboard / shareable clips so roasts can be posted and voted on More modes — a job interview simulator, a dating profile reviewer, a "LinkedIn influencer" voice Group roasts — detect multiple faces and generate a roast of the whole room at once Custom voice cloning so the roast comes from someone the target knows

Log in or sign up for Devpost to join the conversation.