-
-
Lost & found matching, but the inventory stays private
-
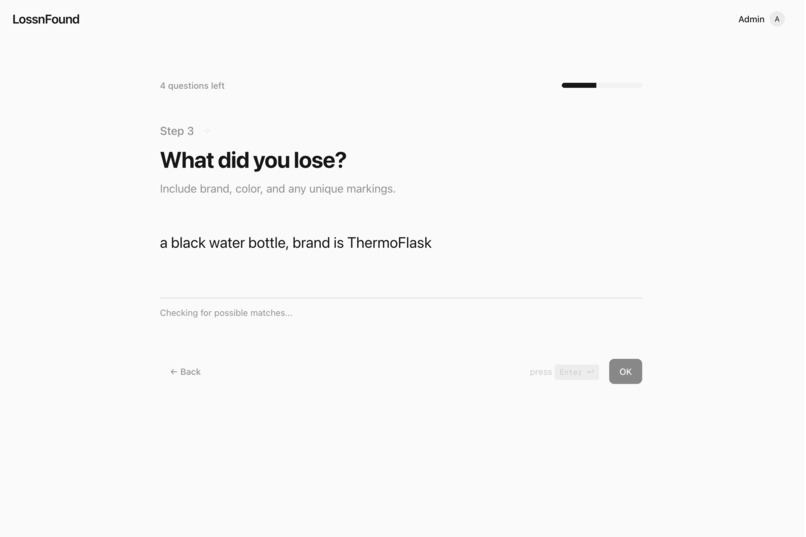
Report what you lost — one question at a time
-
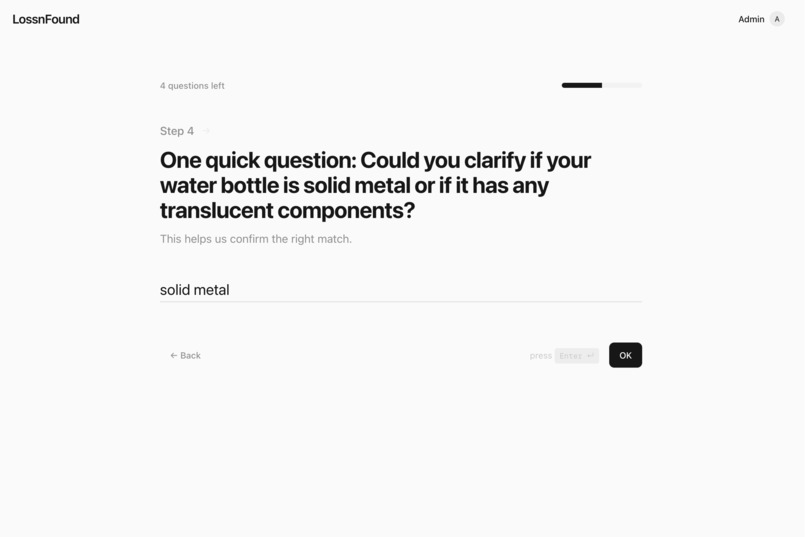
Quick follow-up question from the AI when it’s not sure yet when compared to existing items in the inventory
-
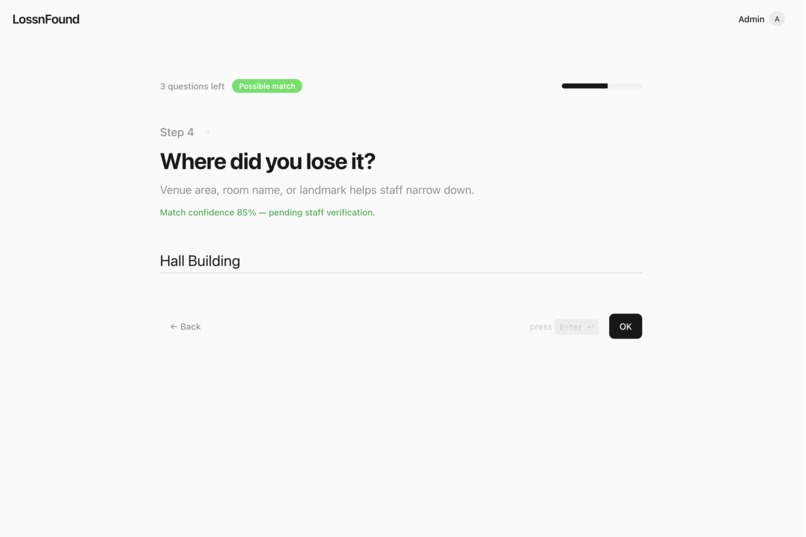
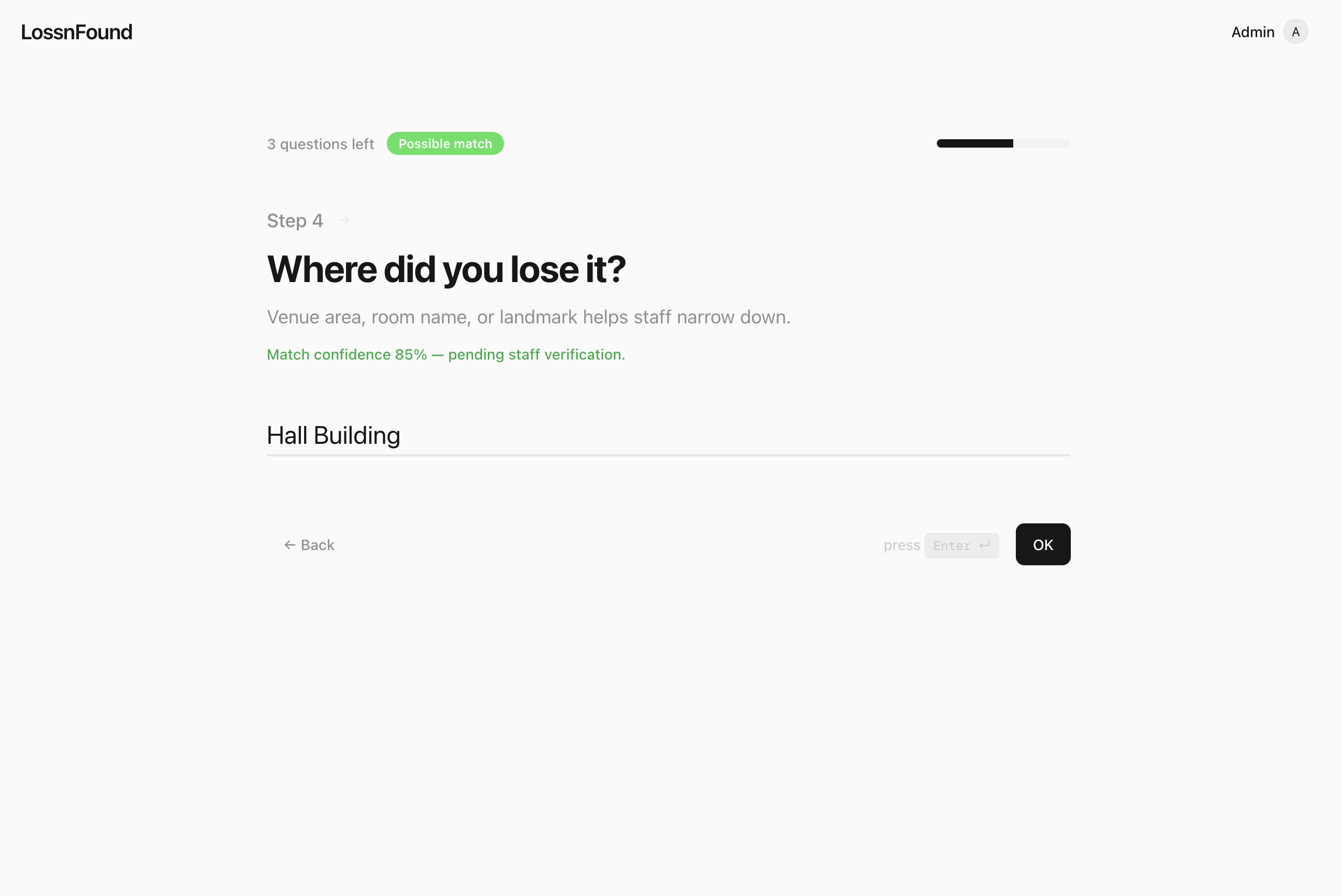
Where did you lose it? This helps the match
-
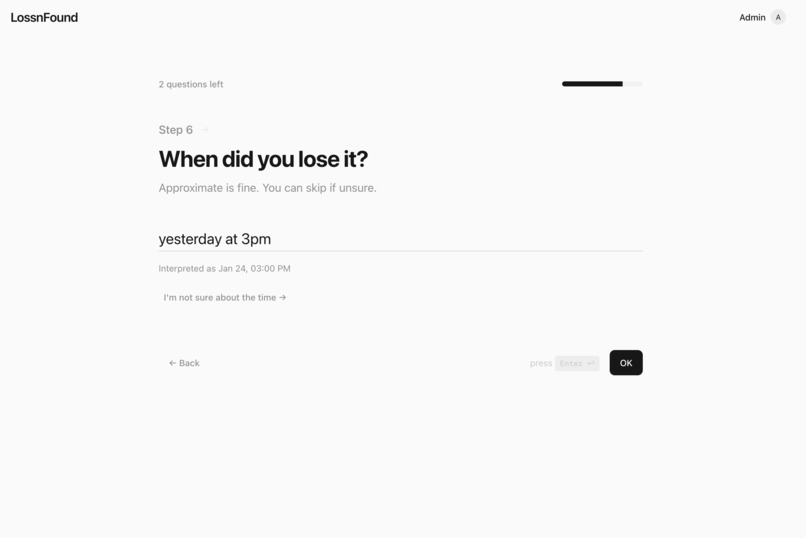
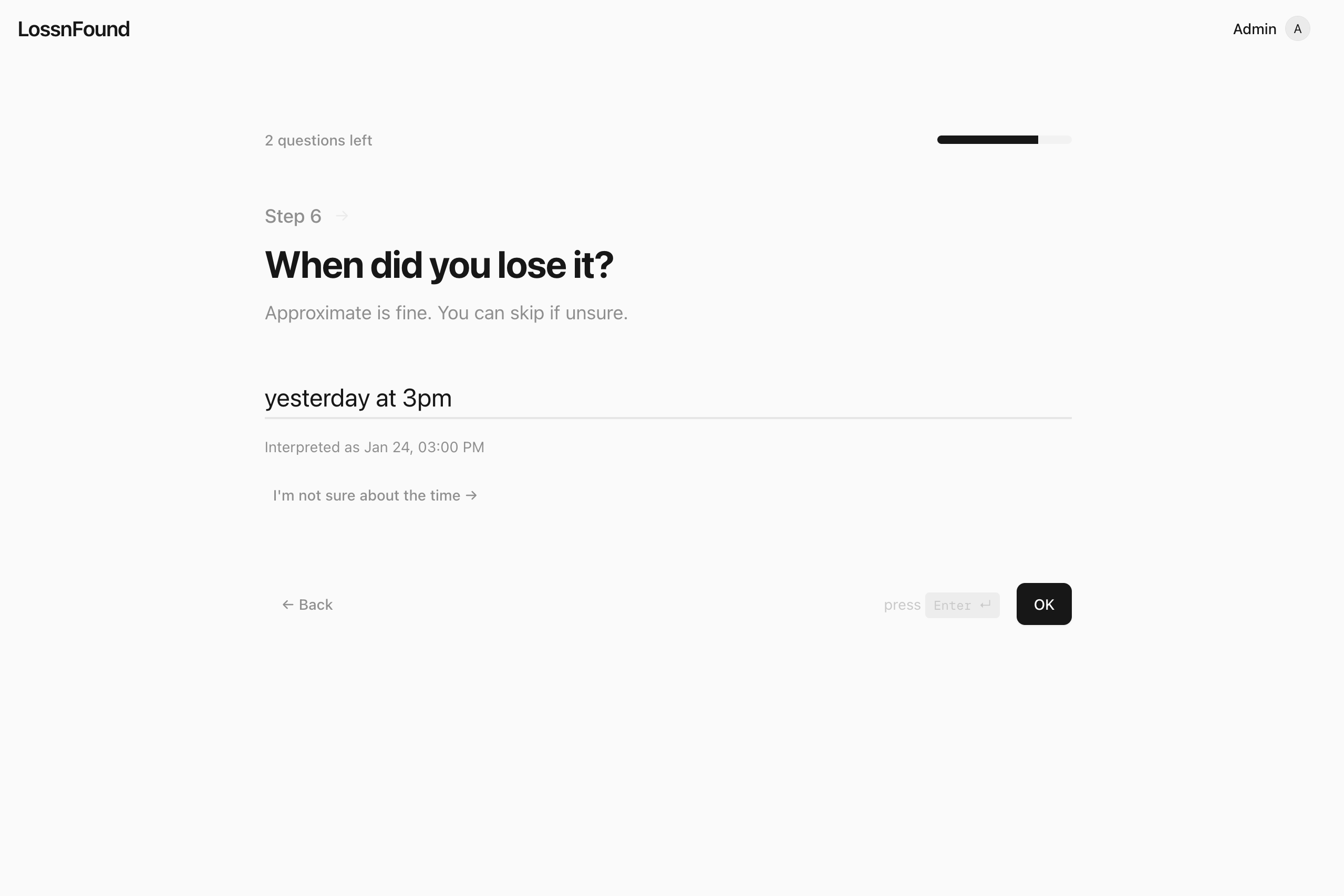
Natural Language date input, parsed intelligently by Gemini
-
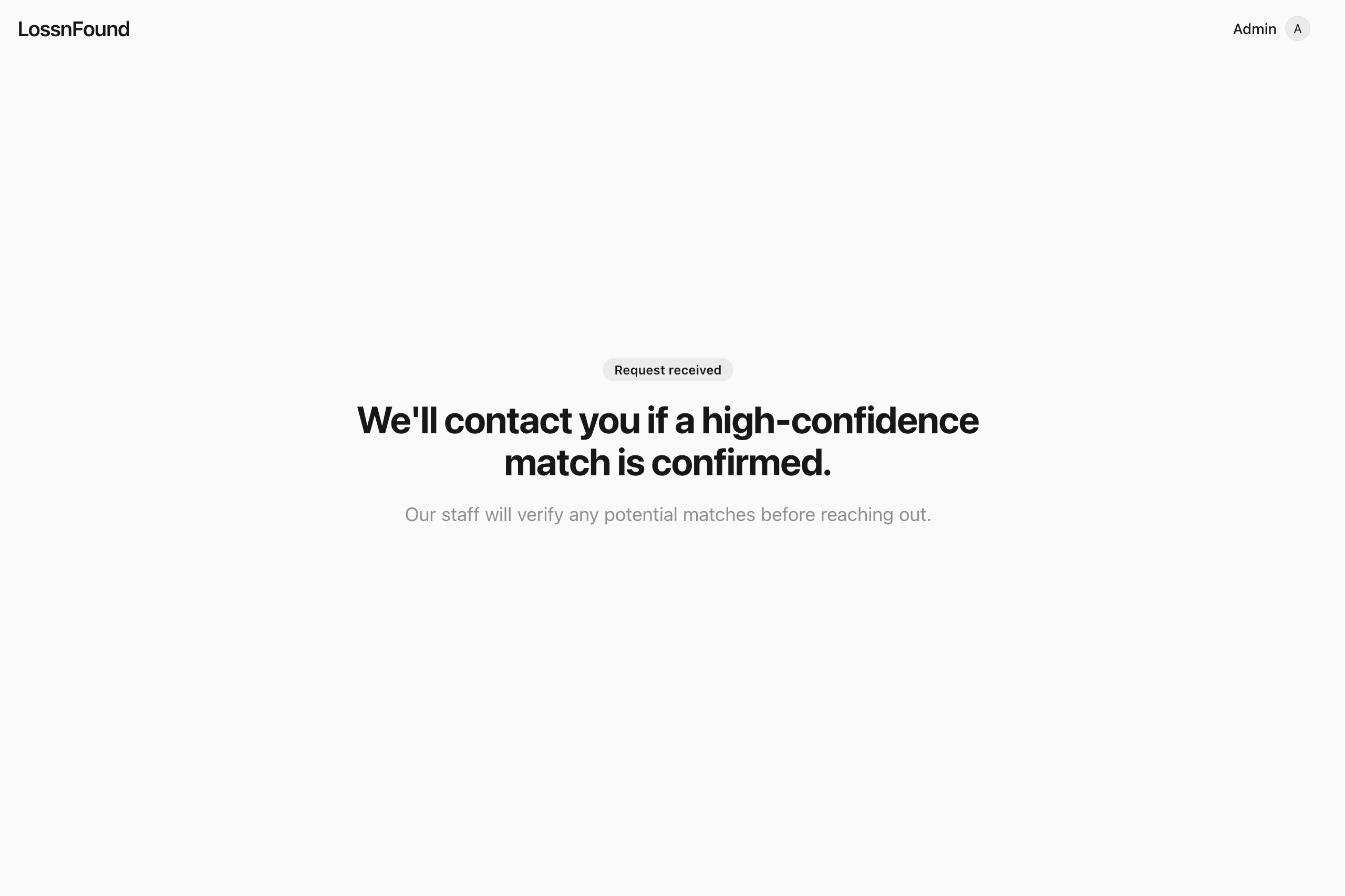
Request submitted, await for response
-
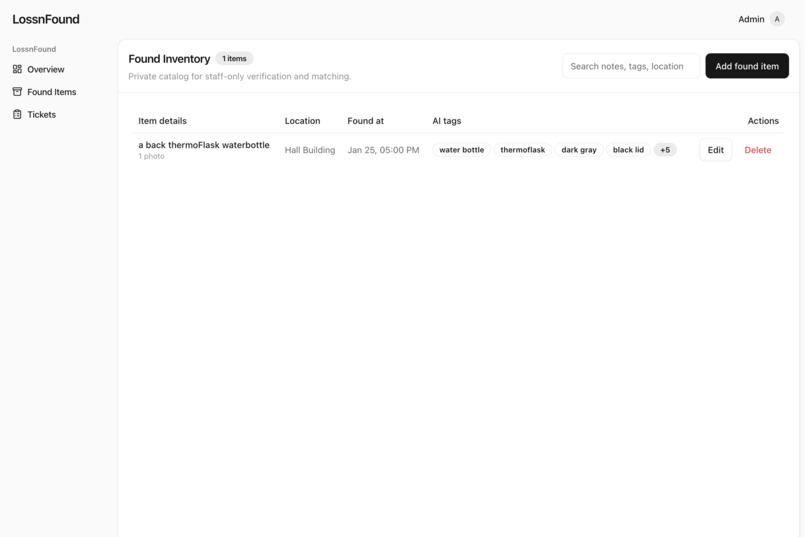
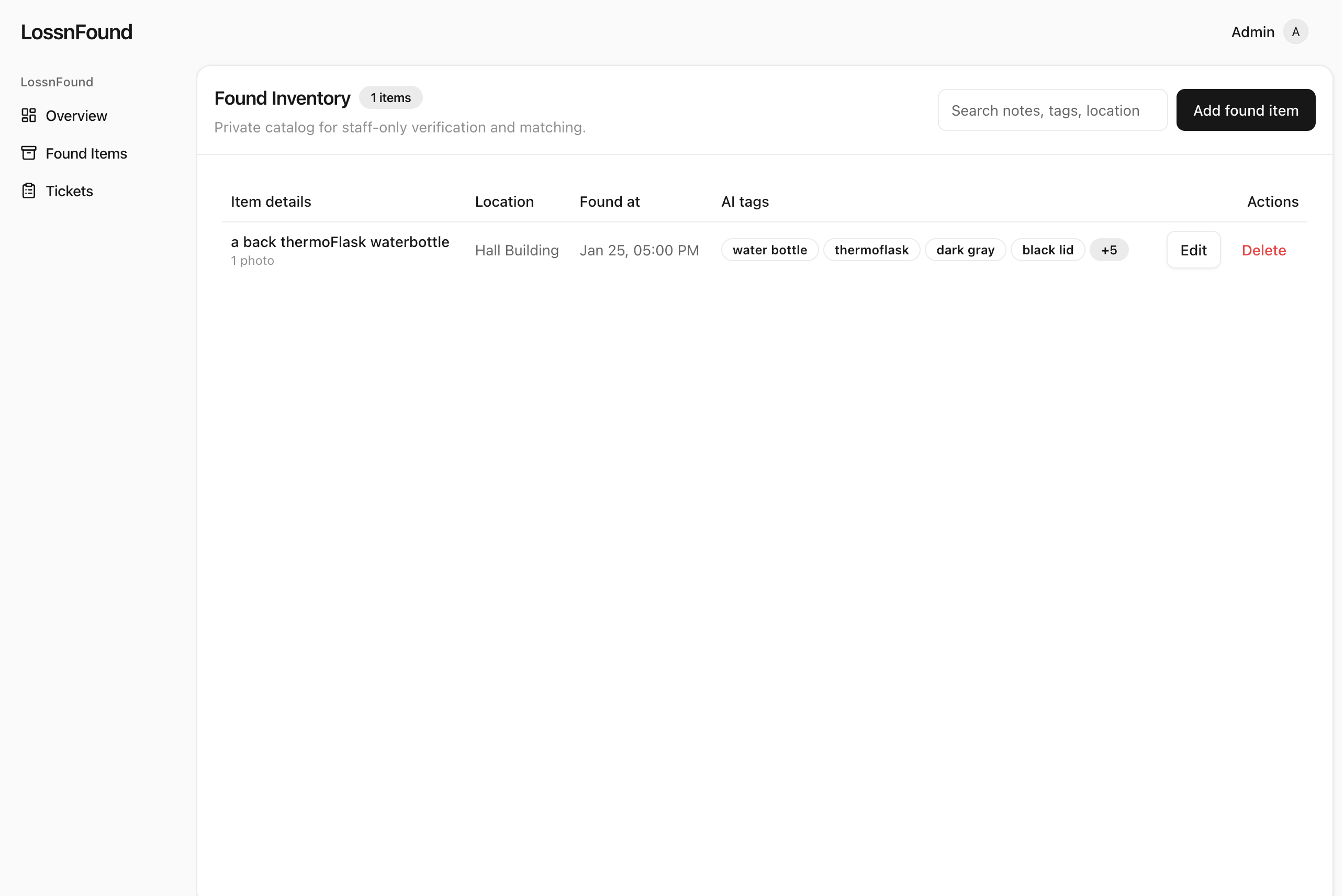
Admin view: the full list of found items.
-
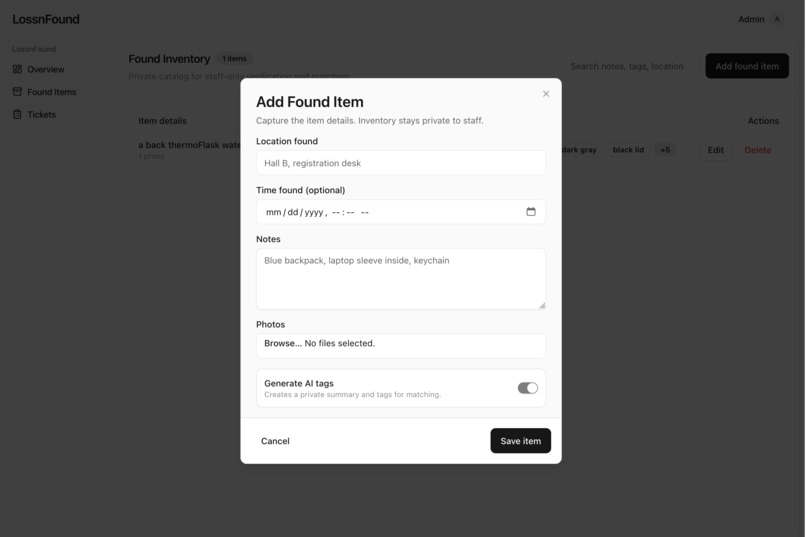
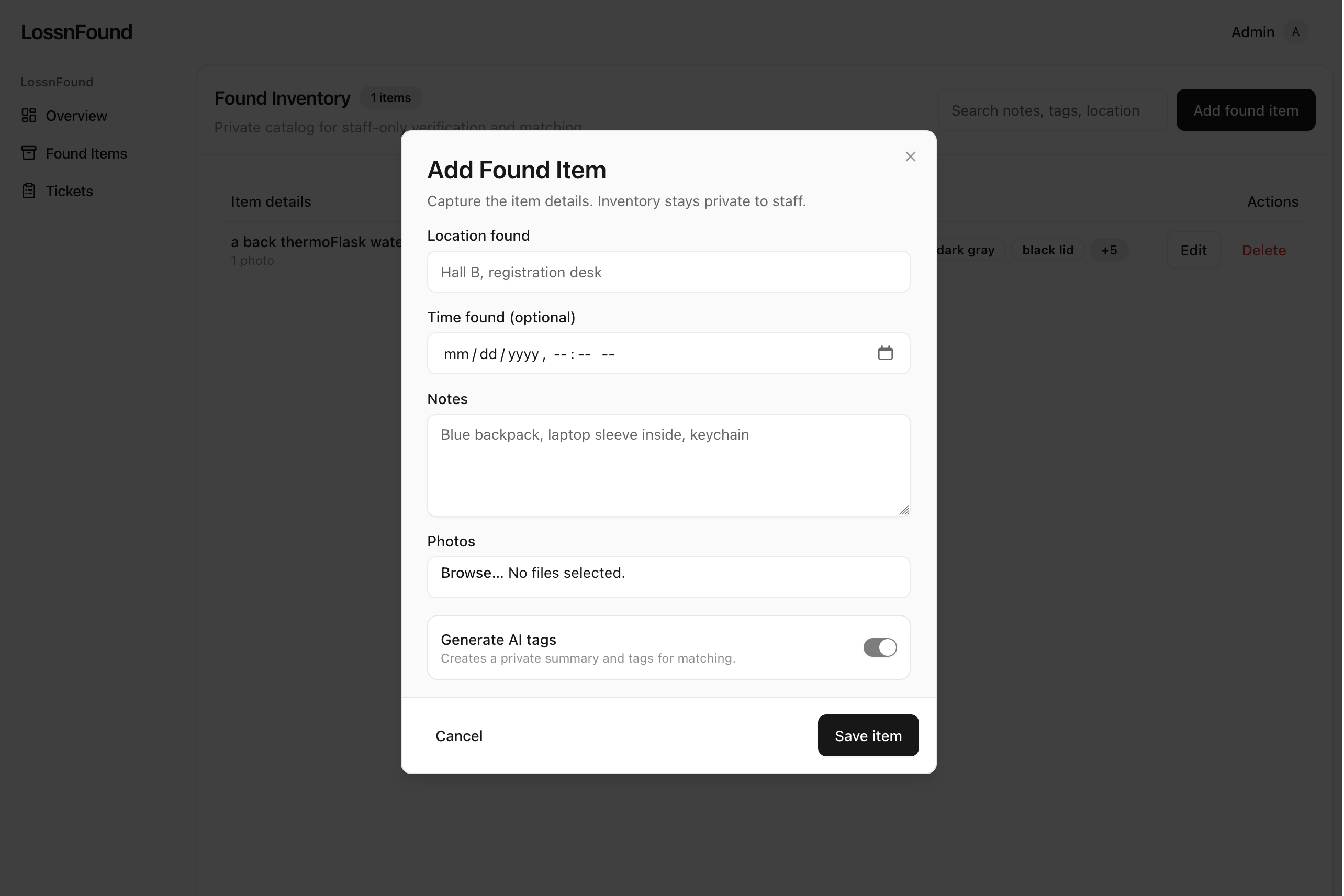
Admins add a found item, AI fills in tags/details
-
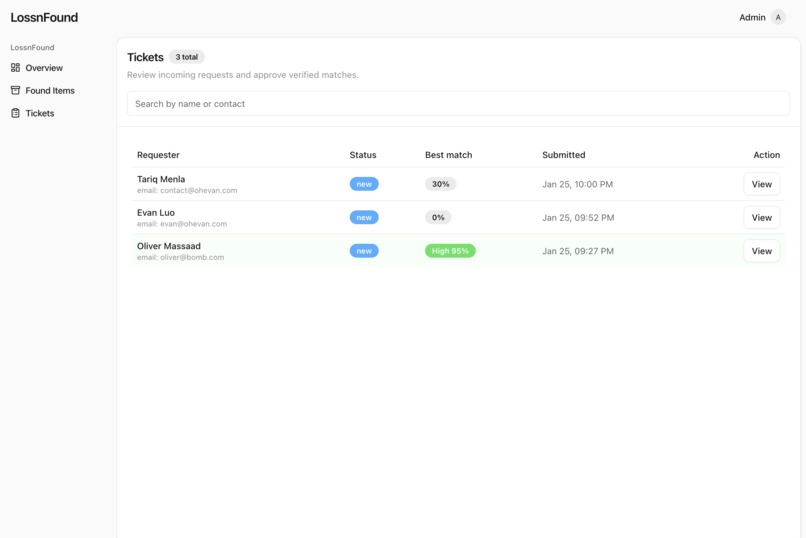
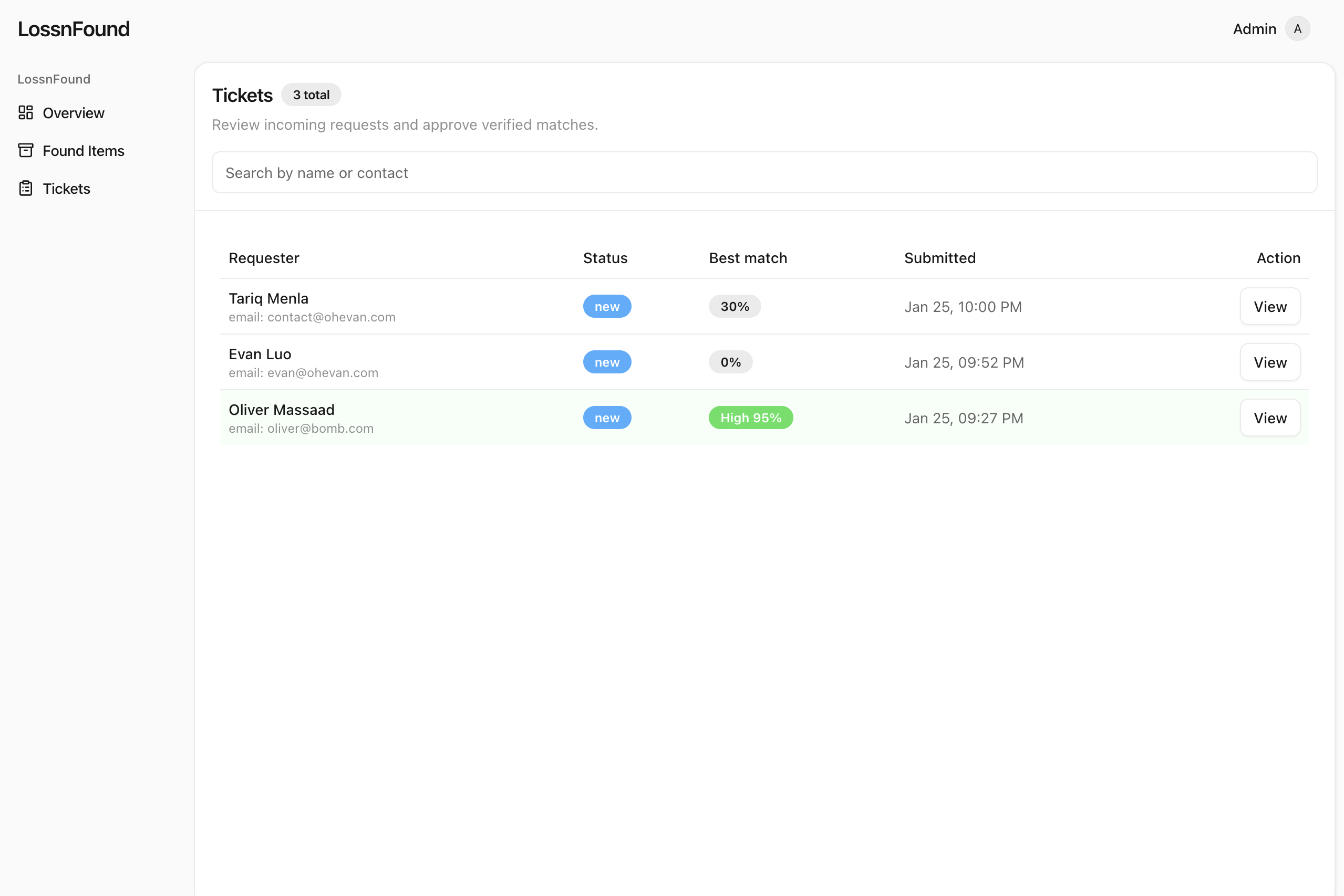
Admin: new tickets with the best match score next to each one
-
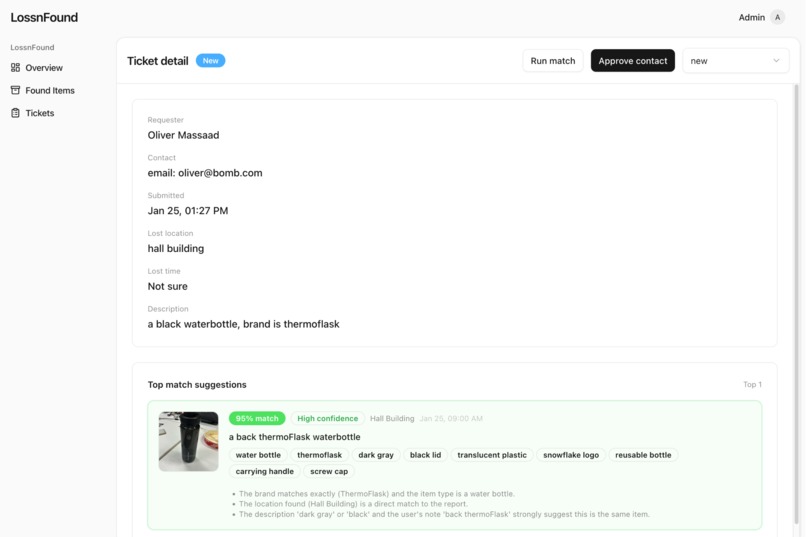
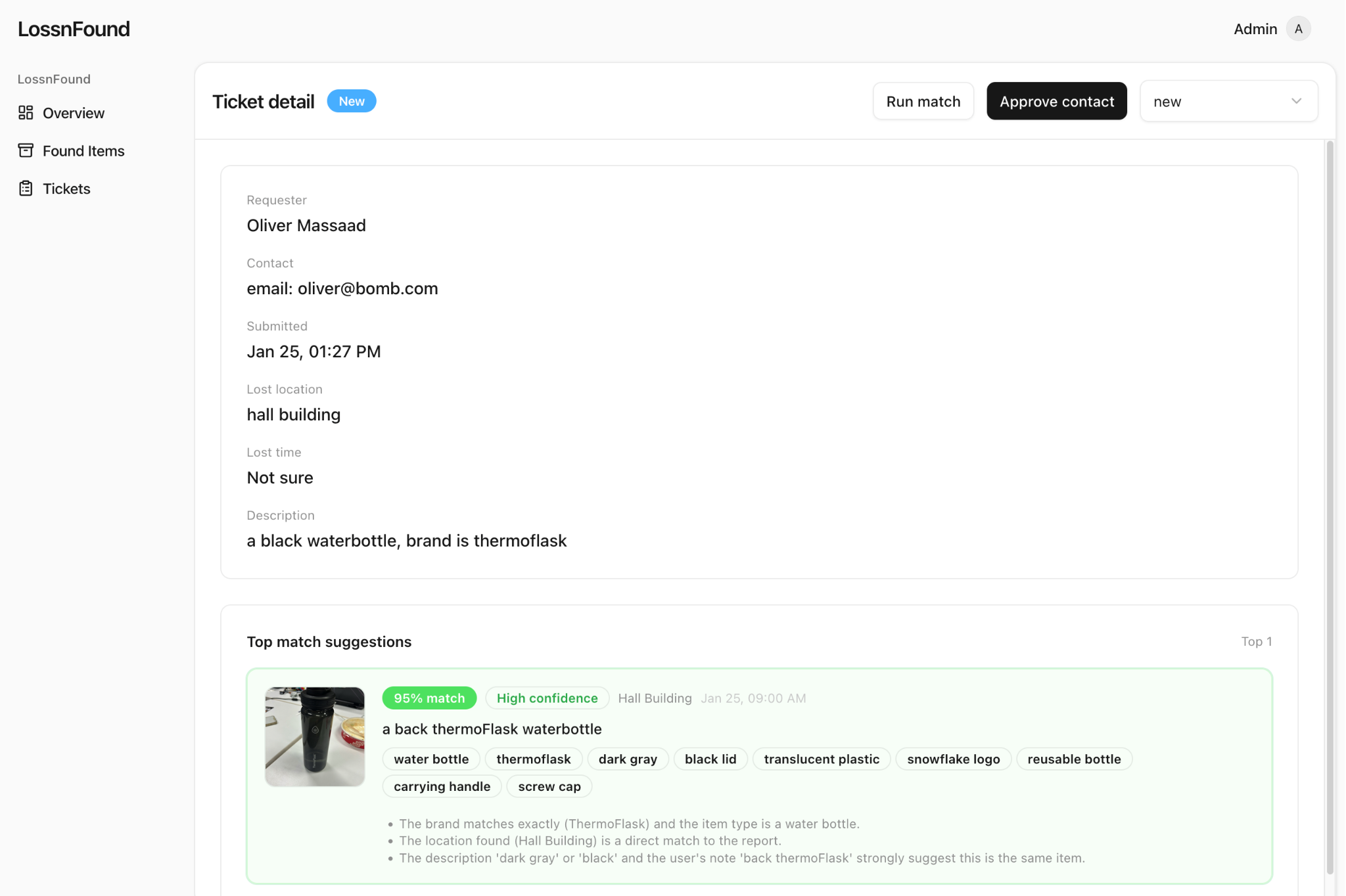
Admin opens a ticket and you get the top match with the photo, tags, and why it thinks it’s a match, can approve match

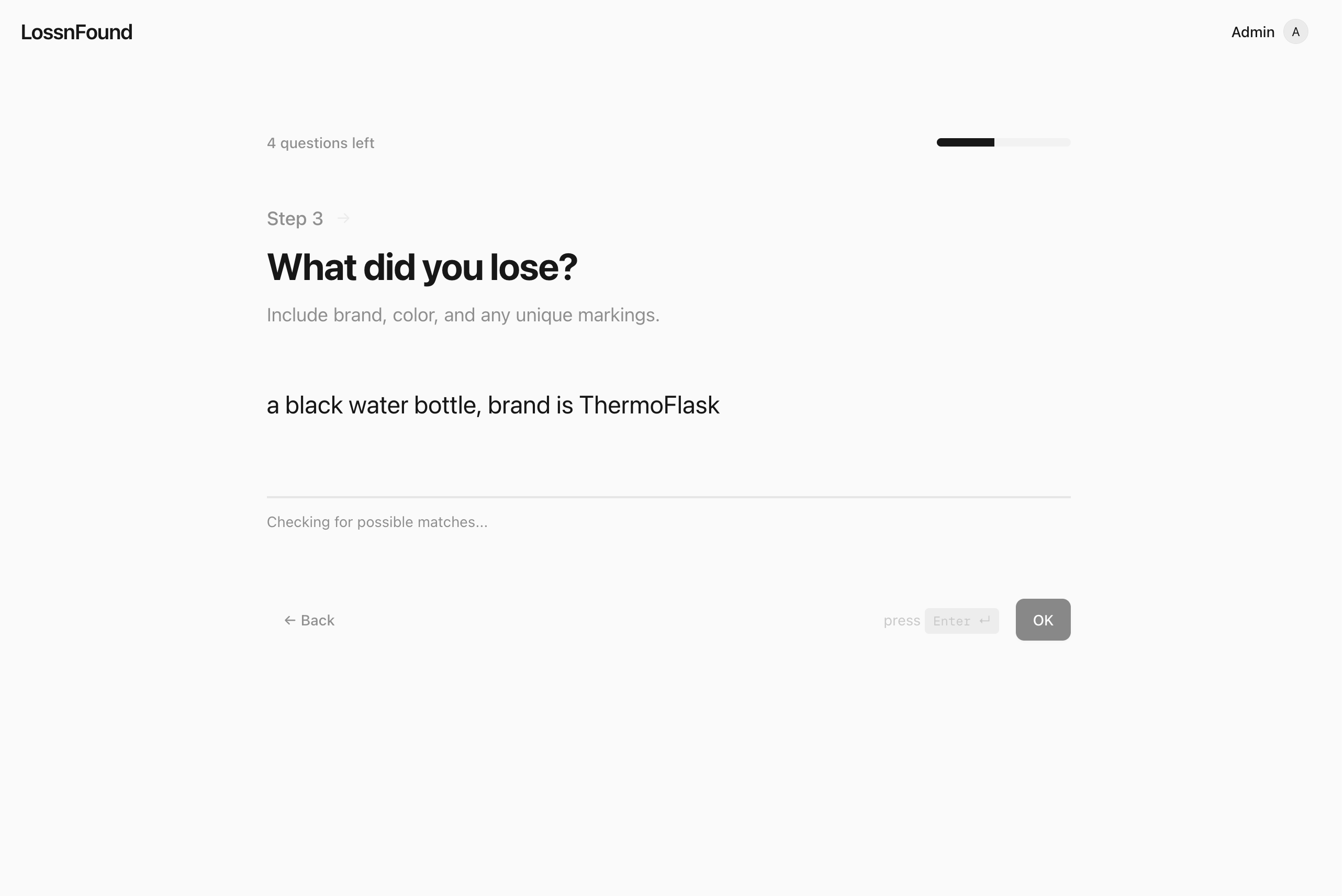
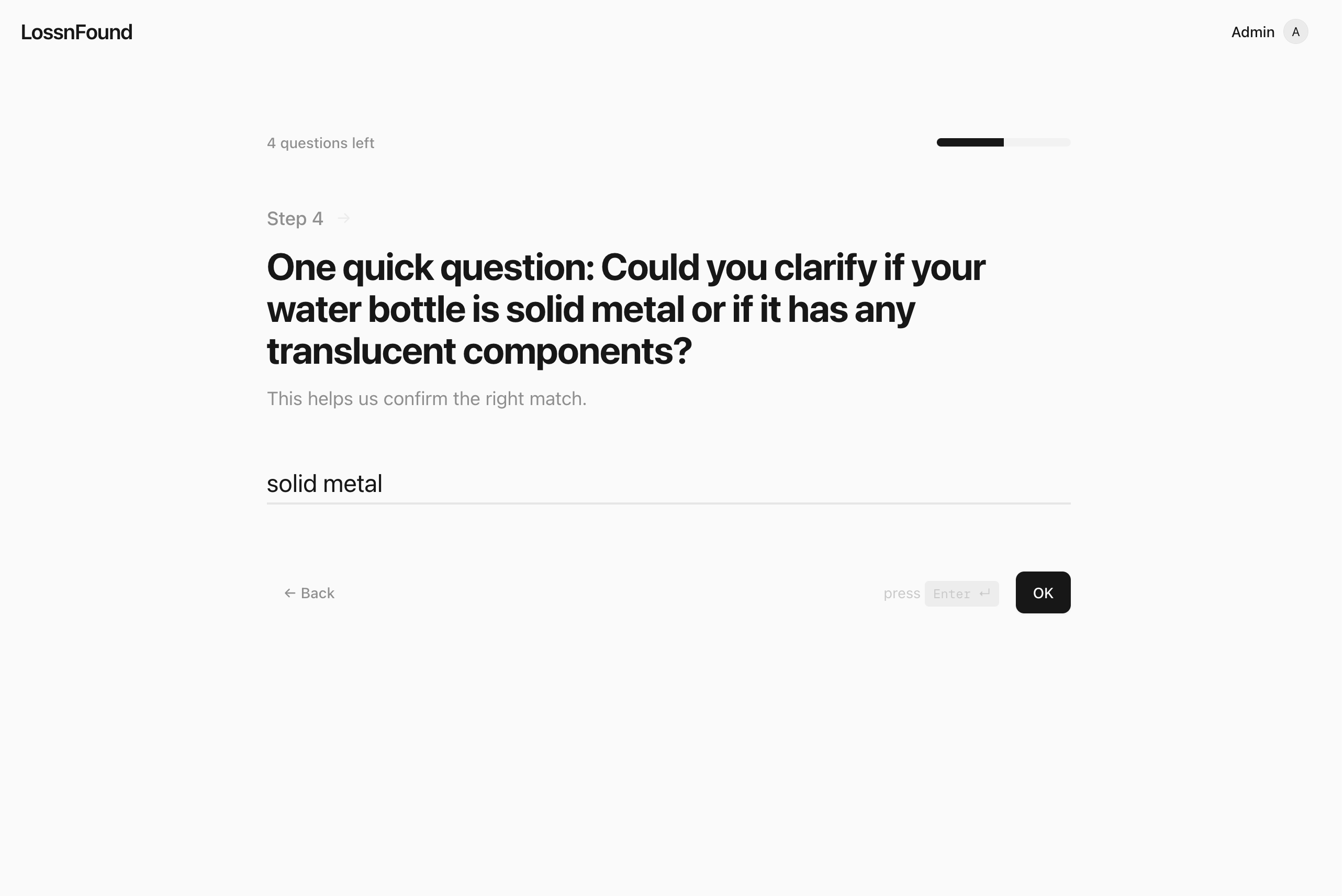
Inspiration
Lost & found at big events is way harder than it should be.
If you’ve ever lost something at a hackathon, you know the drill: you describe it to a volunteer, they dig through a pile, and you hope you get lucky. And if the inventory is public, that creates a different problem — it becomes easier for people to guess details and make false claims.
We wanted a system that feels fast for the person who lost something, but keeps the inventory private by default. That’s the whole idea behind lossnfound.
What it does
lossnfound is a private, AI-native lost & found matcher. It has two roles:
- user: submits a lost-item request
- admin: logs found items and reviews matches
On the user side, the experience is Typeform-style: one question per screen, smooth transitions, no clutter. You answer:
- what you lost
- where you lost it
- when you lost it
- optional photo + contact info
On the admin side, staff add found items (photos, location, notes). Then our matching system tries to connect the dots without ever showing the inventory to users.
We score matches like this:
- ≥ 0.8: strong match → sent to admin for verification
- 0.5–0.8: “maybe” → Gemini asks one quick clarification question while the user is still filling the form, we append the answer, then rescore
- < 0.5: no match yet → ticket stays open and we notify if something turns up later
One extra thing that matters in real life: people type dates in messy ways (“yesterday night”, “Friday 2pm”, “Jan 12 after lunch”). We use Gemini for intelligent date parsing so “when it was lost” becomes something the system can actually reason about.
How we built it
We kept the stack simple, modern, and scalable:
- Next.js for the app (client + admin)
- PostgreSQL + Drizzle ORM for the database layer
- better-auth for email/password auth and sessions
- role-based access control using lowercase roles (
user,admin) - Gemini 3 Flash for matching + structured extraction + clarification questions
- Typeform UI/UX patterns for the client flow
- GSAP + motion/react for that smooth “next question” animation feel
- Three.js for extra visual polish (because demos matter)
We built it in a way that supports infinite horizontal scaling: the app is stateless, the database is central, and matching is run as a clean backend workflow.
Challenges we ran into
- Getting the Typeform-style flow to feel “effortless” while still collecting enough detail to match accurately
- Keeping the privacy story clean: users should feel progress without seeing inventory details
- Making the “one clarification question” flow feel natural instead of annoying
- Turning messy human time inputs into real timestamps (this is harder than it sounds)
- Agentic coding went wrong and we have to refactor a lot of it
Accomplishments that we're proud of
- A private-by-default lost & found flow that makes false claims harder
- A client experience that feels like Typeform, not a boring form
- The “one clarification question → rescore” loop that boosts accuracy without friction
- Intelligent date parsing so tickets are actually searchable and comparable
- A clean role-based admin system with real auth (not just a fake demo login)
- An AI-native architecture where AI isn’t a gimmick — it runs the core workflow
What we learned
- UX matters more than people think. If it feels smooth, people trust it more.
- The best AI features are the ones that reduce user effort, not add to it.
- Dates are chaos. If you want matching to work, you have to normalize time inputs.
- “Privacy by design” makes product decisions easier and the story stronger.
What's next for lossnfound
- Real Google/GitHub OAuth (we show the buttons right now, but didn’t enable the flows)
- Notifications that feel real (email + SMS + admin automation)
- Multi-tenant support so different events can run isolated inventories
- Stronger pickup verification (QR codes, claim codes, audit logs)
- Better analytics for admins (recovery rate, resolution time, hotspots)
Built With
- auth
- better-analytics-for-admins-(recovery-rate
- better-auth
- drizzle-orm
- gemini
- gemini-3-flash
- git
- github
- gsap
- javascript
- motion/react
- next.js
- oauth
- postgresql
- resolution-time
- serverless
- tailwindcss
- three.js
- typescript
- vercel





Log in or sign up for Devpost to join the conversation.