
Lore
GitHub stores your code. Lore stores your reasons.
A harvest-first substrate that captures the why behind every team decision, serves it as long-term memory to whichever agent the team uses, and renders it on a canvas built for the new bottleneck in software engineering: verification.
The Thesis
Devin starts every task with a fresh context window. Windsurf restarts every session. Claude Code starts blind. Cursor reloads its rules per workspace. The most powerful agents in market all share a memory problem — and the solutions in market all require humans to write into them. Devin Knowledge, Cursor rules, CLAUDE.md, Notion ADRs, mem0 facts — every one is a write-tax mechanism. Memory tools fill, then decay, then get abandoned.
That's only half the friction. The harder half:
The biggest bottleneck in agentic coding isn't the implementation. It's the verification.
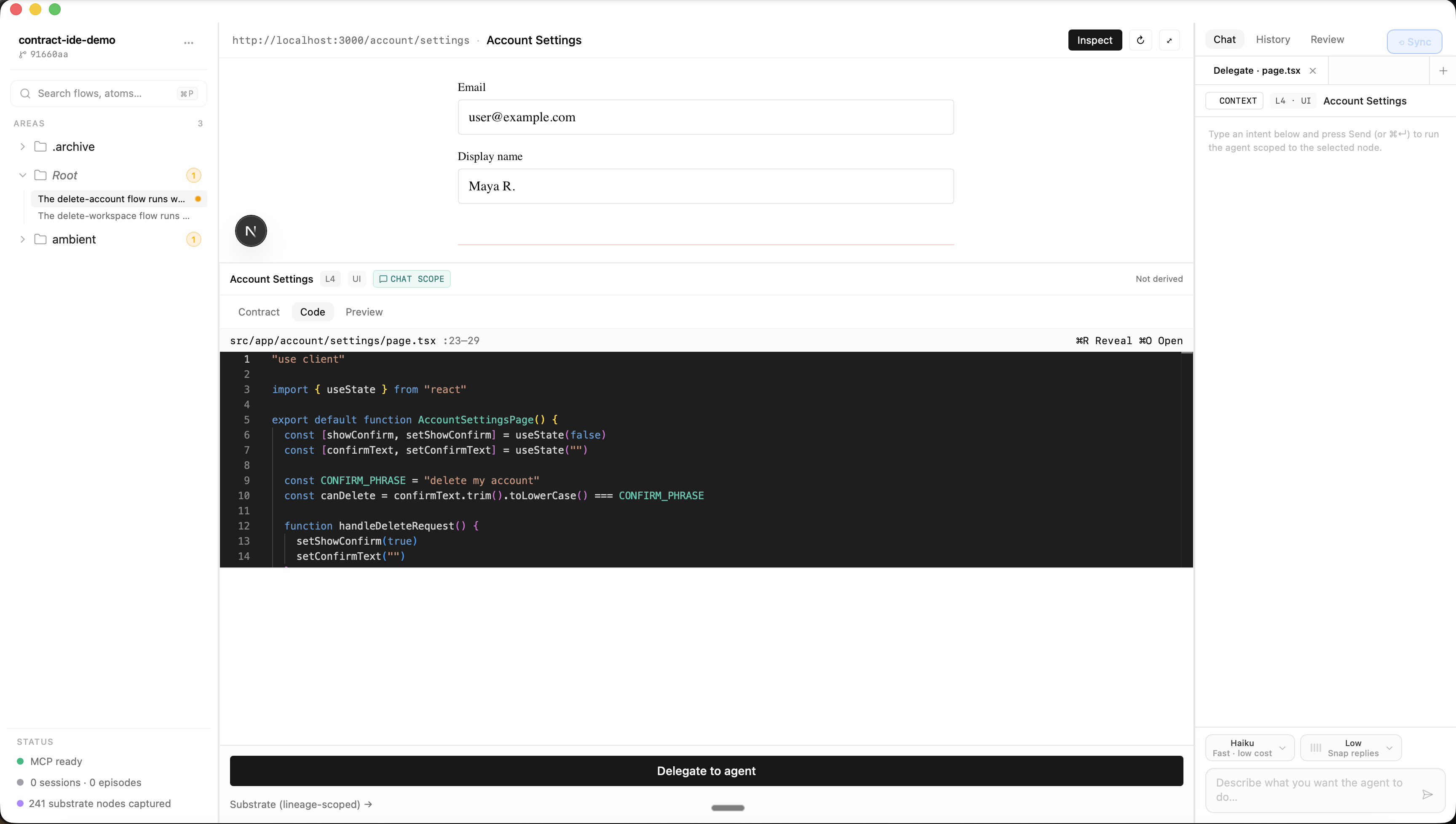
VSCode was designed for humans writing code. File trees, syntax highlighting, autocomplete, LSP, debuggers — every primitive optimized for the developer-as-implementer. In the agent era, agents implement; humans verify. The IDE has nothing to help with "did the agent honor team rules?" / "did it pick reasonable defaults?" / "does this still match our intent?"
Lore is the IDE built for the agent-driven world. Two bottlenecks, one product:
- Compliance — agents need to know team rules and follow them. Harvest-first substrate, MCP-served, contract-scoped retrieval.
- Verification — humans need to see what agents decided in product language, against team rules. Canvas as the agent-decision verification surface.
GitHub stores your code. Lore stores your reasons. Lore is also where the team verifies whether the agent's work matches the reasons.
What Lore Does
Three things continuously, with no engineer authoring step:
- Capture (zero write tax) — Rust
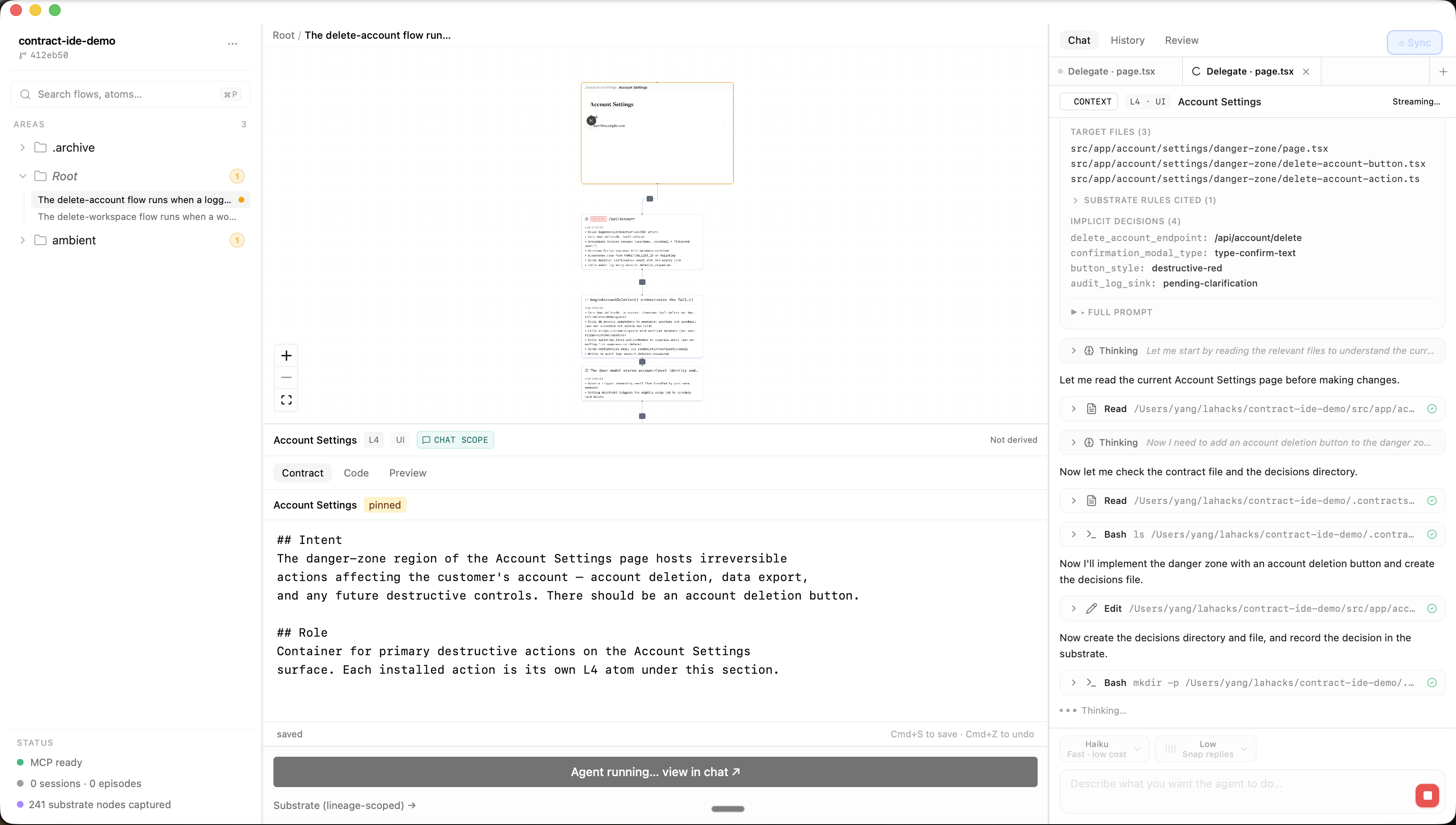
notifywatcher tails Claude Code's JSONL session files. A single LLM extraction prompt with structured output writes typed nodes (constraint,decision,open_question,attempt) to a SQLite-backed graph with bitemporal validity. - Retrieve (graph-anchored, contract-scoped) — MCP server. Three-layer composer:
applies_whensemantic match → graph-edge scope filter → LLM re-rank. Sub-second p95 at 500-node scale. Detailed below. - Verify (canvas as decision surface) — Every flow renders as a vertical chain of participants: UI screens as live iframes, backend endpoints as Stripe-API-docs-style cards. Click any participant — implicit decisions surface in product language with substrate provenance. Detailed below.
Sponsor Prize Fit — Measurably More Capable
Identical task, identical model. Vanilla Claude Code as control:
| Lore-equipped | Vanilla Claude Code | |
|---|---|---|
| Tool calls (delete-account) | ~3 | 10 |
| Context read | ~30k tokens | 661k tokens |
| Team rules honored | 5/5 | 1/5 |
| Tool calls (delete-workspace, different surface) | ~2 | 15 |
| Context read | ~25k tokens | 743k tokens |
| Team rules honored | 6/6 | 0/5 |
Not a one-shot benchmark — a structural property. Substrate compounds across tasks; vanilla restarts every time.
The qualitative proof: a PM types one sentence in the Inspector chat — "destructive primary actions use #FF0000." The distiller captures it as a portable team rule. Hours later, on a different machine, a different agent, on a different task (delete-workspace, not delete-account) renders the new button in exact #FF0000 with no second prompt. The substrate carried the value across machines, sessions, agents, and surfaces. One sentence captured. Every future destructive action shaped.
Hits four of five sponsor-prize directions: smarter context retrieval, better verification, agent integrations, eliminating professional toil.
Why This Matters for Cognition
For Devin: Knowledge today is a write-tax UI — engineers configure facts, Devin reads them at task start. Sparse, flat, no scope. Lore plugs into Devin via MCP (already shipped), populates from real Claude Code sessions on team machines (engineers don't author), and returns surface-scoped constraints in <300ms. Devin's task-start latency drops; rule density grows passively.
For Windsurf: Cascade has session-scoped, per-machine memory. MCP-pluggable. Lore turns Cascade's per-session inferences into team-level memory queryable from any session, on any machine, by any agent.
For Cognition's roadmap: Lore is also a paradigm Knowledge could adopt natively — harvest-first capture, typed-node retrieval, intent-level supersession (a structural capability no fact-store has). Every piece is built and inspectable.
Technical Depth, Part 1: Retrieval Quality
The hardest problem in the project, and where most memory systems break.
Why naïve embedding similarity fails. claude-mem, Graphiti's entity layer, mem0, most "long-term memory for LLMs" libraries embed chat turns and cosine-match on query. Three structural failure modes: (1) topic match, not applicability — returns turns mentioning "delete" instead of rules that fire on deletion; (2) no scope — a rule on Account.Profile fires randomly on Account.DangerZone; (3) no supersession — replaced rules still surface.
The Lore composer pipeline. Three layers, each addressing one failure:
Layer 1 — applies_when match
Each rule carries a structured `applies_when` clause
("an account-shaped record is being deleted, anonymized, or
irrevocably deactivated"). Embed the contract's `## Intent`.
Cosine-match against `applies_when` embeddings (NOT rule text).
→ Top-50 candidates.
Layer 2 — graph-edge scope filter
Walk graph edges from the contract's lineage:
parents, siblings, references.
Filter the 50 candidates to those reachable.
→ Top-15.
Layer 3 — LLM re-rank
Feed contract body + 15 candidates into Claude Sonnet.
Re-rank with the contract as grounding context.
Return top-K with citations to source sessions.
Each layer earns its place: Layer 1 catches "what does this rule fire on?" — rules don't always talk about what they apply to (a rule about "soft-delete with 30-day grace" applies to any deletion). Layer 2 catches the cross-surface case — a rule on Account.Delete should fire on Workspace.Delete if the parent contract abstracts both; the graph encodes this, embeddings can't. Layer 3 catches semantic nuance the first two miss.
Failure modes engineered around:
- Priority-keyword red herrings. A rule mentions "compliance" because it was about compliance. Active priority shifts to
speed-first. Naïve supersession says "rule is fine, no compliance keyword in the new priority" — wrong, the rule was derived under compliance, and the priority shift is what should flag it. Fix: the supersession judge reads the rule's justification against the new priority's description, not keywords. Three rounds of prompt iteration before adversarial fixtures hit 9/10 exact match. - Sibling-scope leakage. Layer 2's graph filter uses parent-of edges as primary; siblings only via explicit
referencesedges. - Supersession at insert and query time. Every insert runs an invalidation prompt against existing nodes with overlapping
applies_when(no near-duplicates). Bitemporal validity (valid_from,invalidated_at) scopes retrieval to currently-valid rules at query time (no stale surfacing).
Validation: 4/4 hit rate, 0 false positives on 14 constraints distilled from 2 real Claude Code sessions. 9/10 exact match on adversarial supersession fixtures with priority-keyword red-herrings. Sub-second p95 retrieval at 500-node scale, prompt-cache hit rate >85%.
Technical Depth, Part 2: Rule Quality (What Even Counts as a Rule?)
If retrieval is the hardest problem, this is the most-overlooked one. Most content in a Claude Code session is not a rule. Get this wrong and the substrate fills with noise; retrieval degrades; engineers stop trusting the layer.
What gets rejected: orientation Q&A ("where's auth?"), session recap ("so we've added the button..."), conversational meta ("got it"), one-off task instructions ("delete tmp/scratch.md"), demo logistics, exploratory tool calls.
What a rule must be:
- Portable — applies beyond the originating session
- Net-new — not already represented via overlapping
applies_when - Project-relevant — about how this codebase/team operates, not general programming
- Verifiable — has an
applies_whenmatchable against future tasks - Justified — has a reason or origin story (a rule without a why doesn't survive a priority shift)
These five criteria are encoded directly into the distiller's extraction prompt as a portability_check field on every candidate. The model is forced to triage before emitting.
Two extraction modes, one prompt. Explicit rules ("always use fetchWithAuth") and inferred rules from bug-fix patterns ("the bug was empty-string FK → constraint: coerce to NULL") run through the same extraction pipeline. The distinction is captured in a confidence field (explicit | inferred), not by running separate prompts. Earlier prototypes split extract and filter into two prompts; the model would emit a rule then explain it away in the filter pass, losing signal. Single-prompt structured-output forces commitment in one pass.
The promotion path — substrate compounds two ways. Substrate grows from explicit team conversations (the Feb-2026 deletion-incident thread → 5 rules) AND from agent defaults the team chose to keep (24h email-link timeout — implicit on first task, reviewer accepts, becomes a substrate rule on every future destructive action). Auto-promoting every default would fill the substrate with noise; never promoting would leave it stuck at explicit-rule density. Human judgment in the loop is what makes the substrate compound usefully.
Validation: Hand-reviewed all 14 distilled constraints from 2 real Claude Code sessions. Every one met all five criteria. Zero session-specific recap. Zero orientation Q&A. The 4/4 retrieval hit rate is only achievable when rule quality is high — noisy substrate degrades retrieval immediately.
Technical Depth, Part 3: The Verification Surface
The compliance side (Parts 1 and 2) makes the agent better. Verification is the human side — the part of the IDE that didn't exist because no IDE was built around the agent-era bottleneck.
Why a visual surface. After an agent finishes, reviewers ask five questions: Did it honor team rules? Did it pick reasonable defaults? Does it still match intent? Did a priority shift invalidate something? Why was this decision made? A diff doesn't answer any of these. A chat history doesn't either. A flat sidebar loses spatial context. The canvas is the medium that fits all five.
One substrate, five surfaces — the Figma move for engineering. Same substrate, different views per role:
| Role | Surface | What they do |
|---|---|---|
| Developer | Inspector + Canvas + Monaco | Verify output, narrow constraints, accept or promote implicit decisions |
| PM | Copy Mode pill (atoms only, no code) | Edit intent in product language, never sees TypeScript |
| Designer | L3 trigger view (rendered iframe) | See the actual UI with atom chips overlaid; design tokens next to components |
| Reviewer | Right-sidebar Review tab (PR-shaped) | Walk the chain top-to-bottom, click [source] for citations, flag intent drift |
| New hire | ⌘P semantic search by intent |
Onboard by reading 500 distilled decisions, not 50,000 lines of code |
Figma unified the design conversation by putting it on one canvas; Lore unifies the engineering verification conversation the same way.
The rendering — flow as caller's medium. Every flow renders as a vertical chain:
[ Account Settings — rendered iframe ]
│ click → POST { confirmation_token }
▼
[ POST /api/account/delete — endpoint card ]
│ beginAccountDeletion({ userId, token })
▼
[ beginAccountDeletion — lib card ]
│ { userId, deletedAt, graceEnd }
▼
[ db.user.update — data card ]
...
UI screens render as live iframes (literally the dev server, atom chips overlaid via a custom Babel/SWC plugin that injects data-contract-uuid markers from .contracts/*.md frontmatter at build time — zero source pollution). Backend endpoints render as Stripe-API-docs-style cards with method-colored badges, request/response schemas, side-effect lists. Edges between participants carry call-shape — {userId} → {deletionId, gracePeriodEnds} — so the canvas teaches the caller's mental model on the way down. Each role sees what they care about in their native medium; developers flip to Monaco when they want code, but they call it up — code is no longer the foreground.
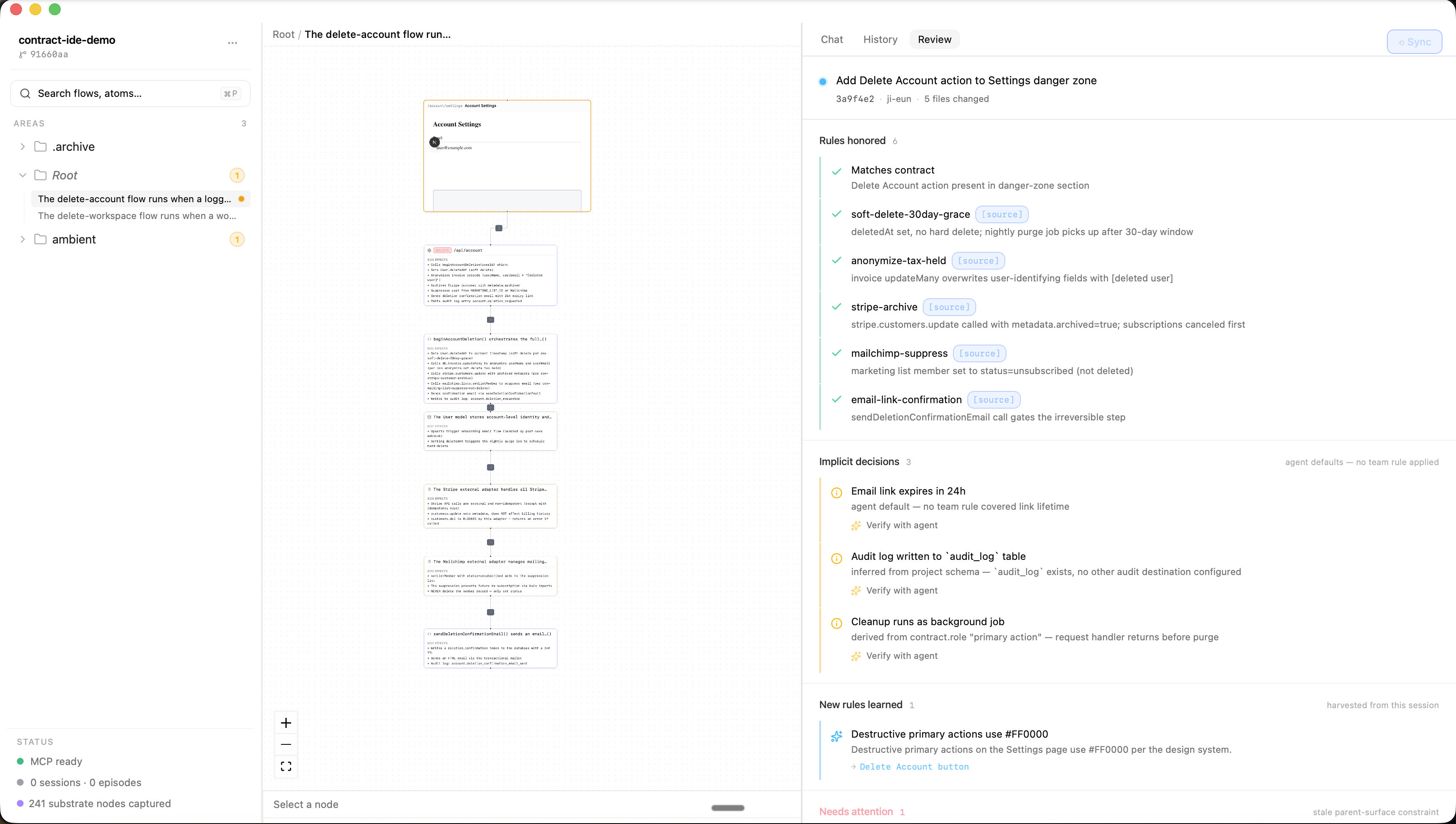
The Review tab — PR review by intent. When the reviewer pulls incoming changes, the right sidebar hydrates a PR-shaped review surface:
- Header — commit metadata
- What rules were honored — ✓ rows for every substrate rule respected, each with
[source]citation pills - Implicit decisions surfaced —
ℹrows for every default the agent chose where no team rule covered. Each has an inline "Verify with agent" textarea — reviewer types "show me where the agent set this and why", the row expands inline with a streaming agent response containing code citations and reasoning. Verification becomes conversation, not a binary read. - Needs attention —
⚠orange-flag rows for intent-drift
Two clicks investigate any decision. [source] opens Monaco in the center pane and halos the participant on the canvas. The Review tab never closes.
The orange flag — intent drift made visible. Six visual states with strict precedence (red > orange > amber > gray, plus green and halo). Orange is the unique one. A PR can compile, pass tests, honor every team rule — and still trip an orange flag because it implements a decision under a now-superseded priority. Tests don't catch it. Code review tools don't catch it. The verification surface does. Fact-level memory tools (Graphiti, mem0, Letta, Cognee, MemOS) cannot do this — they have no goal hierarchy.
VSCode is for implementation. Lore is for verification. We didn't replace VSCode — Monaco lives at the center pane, accessible from any decision via two clicks. But the primary surface in Lore is the canvas, because the primary work in Lore is verification. The hierarchy is inverted: code is now a peripheral view called up when needed; the agent's decisions in product language are the foreground. This is the IDE primitive nobody else has shipped.
Originality
Four insights that compound:
- Harvest-first beats write-tax. Every memory tool in market — Devin Knowledge, Cursor rules, CLAUDE.md, Notion ADRs — has a write-tax problem and decays. Inverting it (the team's normal workflow as input pipeline) eliminates the failure mode.
- Contract-anchored retrieval beats embedding similarity. Rules need scope, not just topic match. The graph encodes scope;
applies_whenclauses encode applicability. Cosine over chat history gives "things that look related" — useful for chat search, useless for "rules that apply to this task." - Intent-level supersession is structurally novel. Prior-art survey of every major memory framework explicitly flags this as an open gap. Validated 9/10 against adversarial fixtures with priority-keyword red-herrings.
- The IDE primitive is verification, not implementation. Cursor, Copilot, every agent-IDE in market is positioned as a better way to write code — they're optimizing the wrong bottleneck. Lore is the first IDE built for the new one.
Together they're a category — the IDE for the agent era.
Built With
Frontend: React, TypeScript, Tailwind, shadcn/ui, react-flow, Monaco Editor, Framer Motion
Backend: Tauri 2 (Rust), SQLite (rusqlite), notify (file watcher), reqwest
Agent integration: TypeScript MCP server (@modelcontextprotocol/sdk), Anthropic SDK
LLM: Claude Sonnet for distillation + retrieval re-ranking; prompt-cache-keyed via content hashes
Build tooling: Custom Babel/SWC plugin for data-contract-uuid injection
Layout: dagre with grid fallback; custom virtualization layer over react-flow
Distribution: macOS .app bundle (Tauri-built, universal binary)
VSCode was built for humans writing code. Lore is built for humans verifying what agents write. **GitHub stores your code. Lore stores your reasons.**
Built With
- anthropic
- claude
- deepseek
- devin
- gemma
- tauri
- windsurf


Log in or sign up for Devpost to join the conversation.