-
-

-
Taste profile as established by Lore on gitlab-runner
-
Applying institutional memory to an MR
-
Flagged Components with historical citation
-
Gitaly analysis done by Lore

Inspiration
Watch a GitLab maintainer's review history and you'll see the same thing, merge request after merge request: a link to the styleguide, a correction typed by hand, a rule explained one more time to someone who'd never have found it. Here's the trap — the rule is often written down. It still doesn't transfer. Because knowing a convention and being able to hand someone the rule are different things. Michael Polanyi called it tacit knowledge: we know more than we can tell. A senior maintainer can spot a weak MR title, the wrong file for a handler, an un-idiomatic metric name — instantly — but couldn't always write you the rule. So it lives in their head, and it transfers one tired comment at a time.
That's the real bottleneck between a contributor's first MR and their first merge: not the code, the conventions no one ever fully wrote down.
What if a project's own review history could surface that tacit knowledge and put it to work — greeting every contributor on day one, instead of living only in a maintainer's head?
What it does
Lore turns a project's merge-request review history into explicit, teachable conventions — surfacing the tacit knowledge maintainers enforce but couldn't fully write down. It mines years of reviewer comments to infer the conventions a project actually enforces in practice, then pre-reviews every new MR against them: posting threaded, evidence-backed feedback within minutes of the webhook firing, long before a human maintainer arrives.
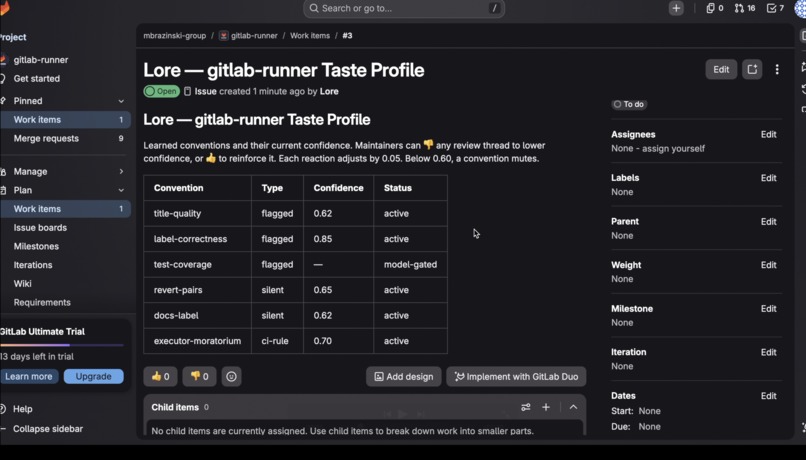
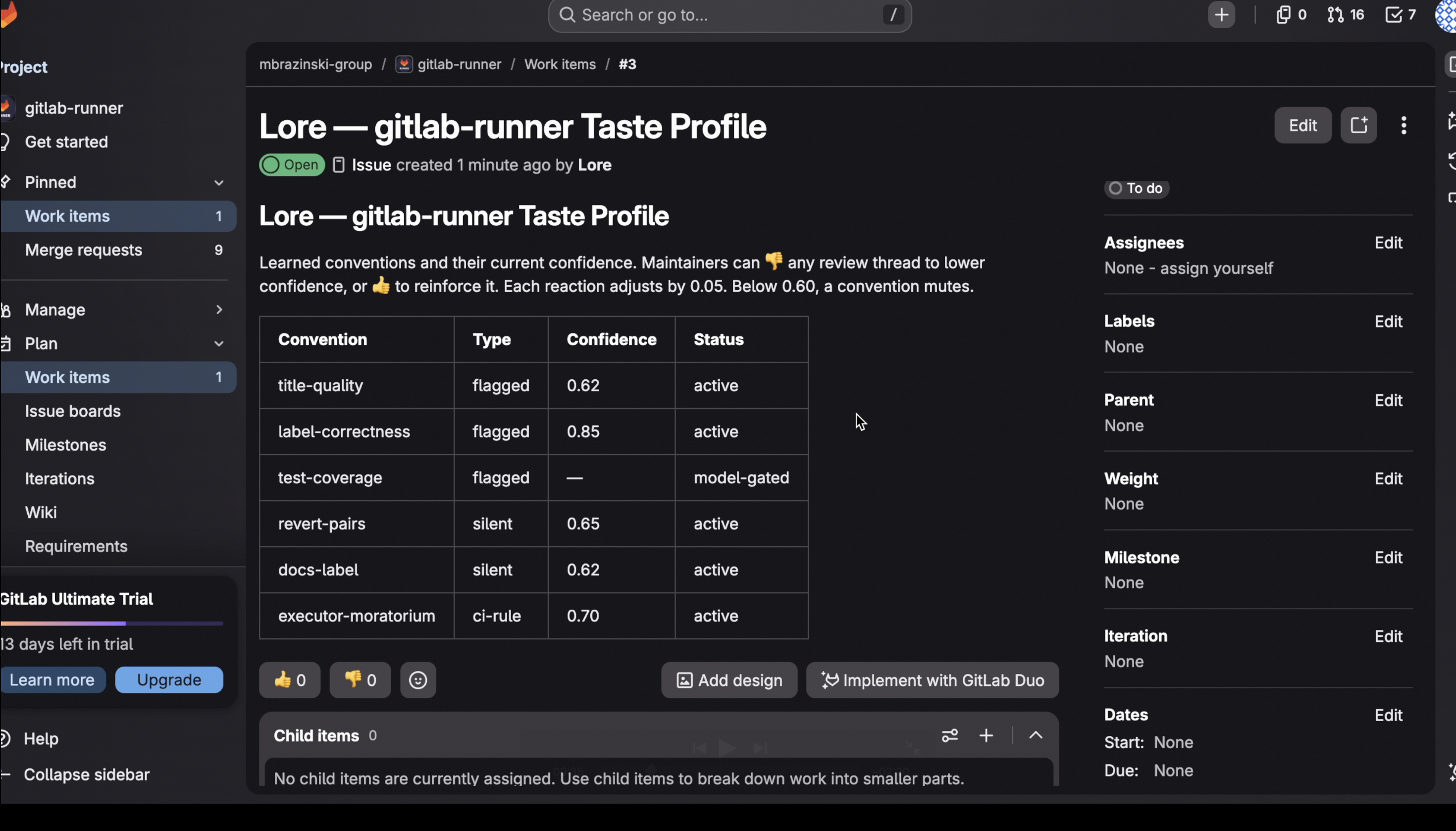
- Discovers conventions from behavior. It mines a project's merged-MR history and extracts the conventions maintainers repeat — each backed by real reviewer quotes with MR attribution. On gitlab-runner: 6 conventions from ~500 MRs.
- Reviews in real time. A GitLab webhook triggers a review; resolvable discussion threads appear on the MR within minutes.
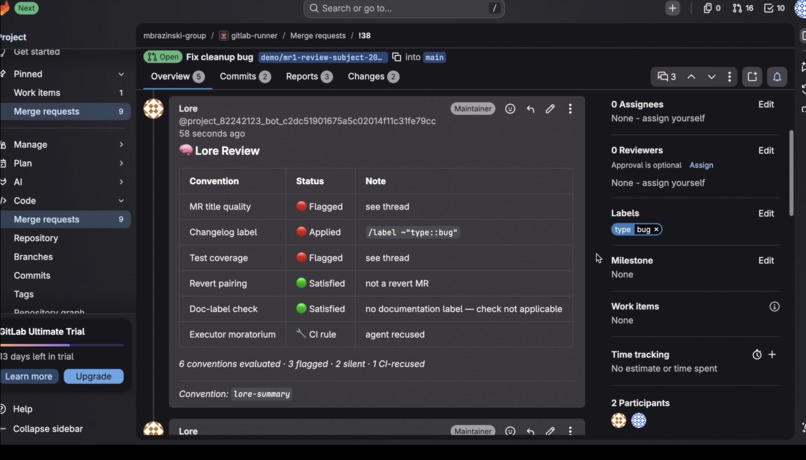
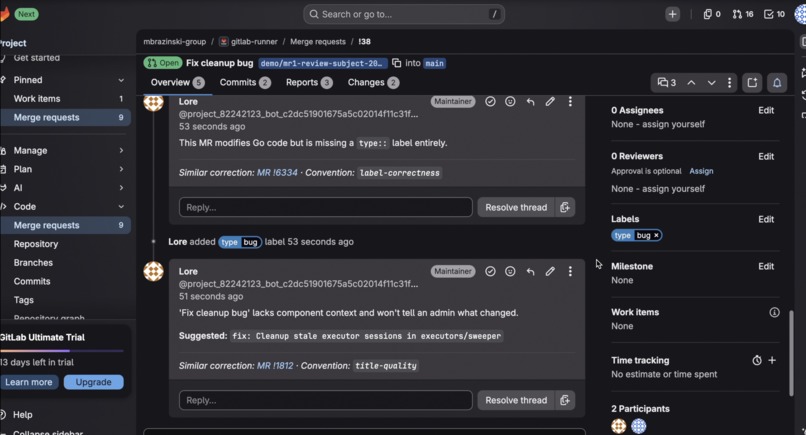
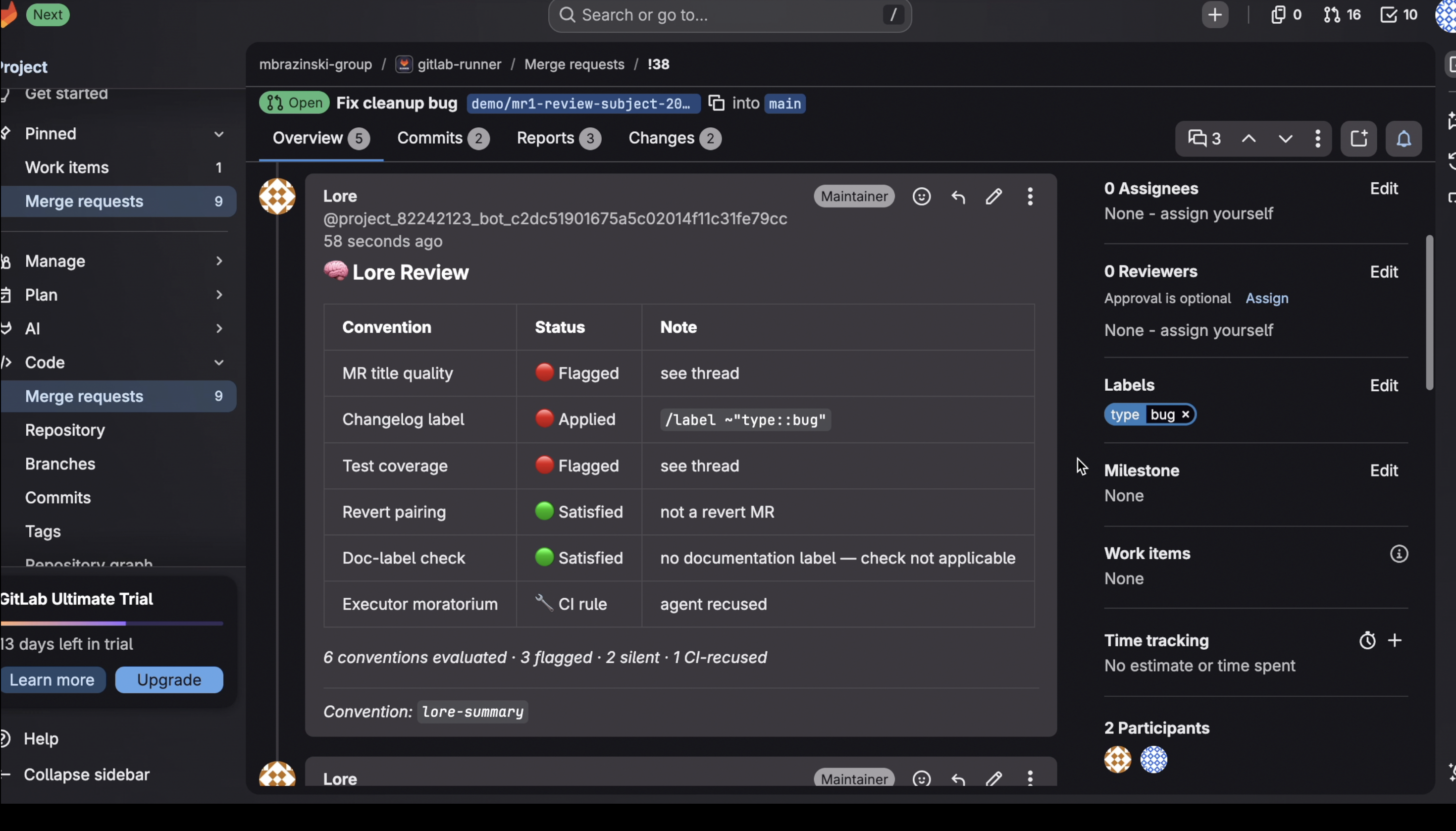
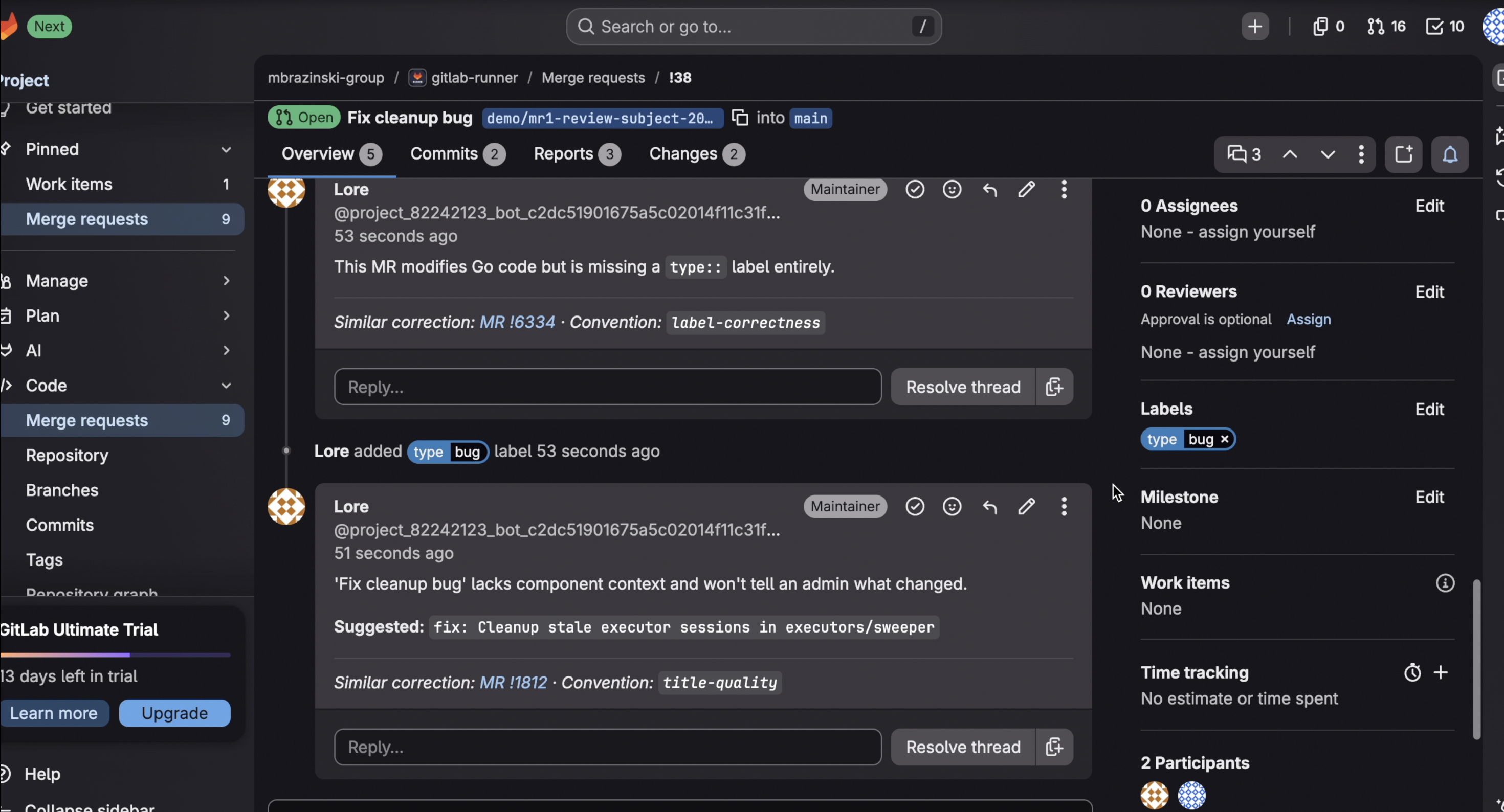
- Acts three ways, always with evidence. It flags judgment calls (a weak title) as discussion threads, applies mechanical fixes (a missing label, via quick-action), and recuses on rules it shouldn't own — posting a recommended CI gate instead of ruling. Every action cites the real historical MR behind it.
- Remembers corrections. When a maintainer dismisses a flag, Lore stores that correction and recalls it on similar future MRs — and a single 👎 lowers a convention's confidence until, past a threshold, it goes quiet.
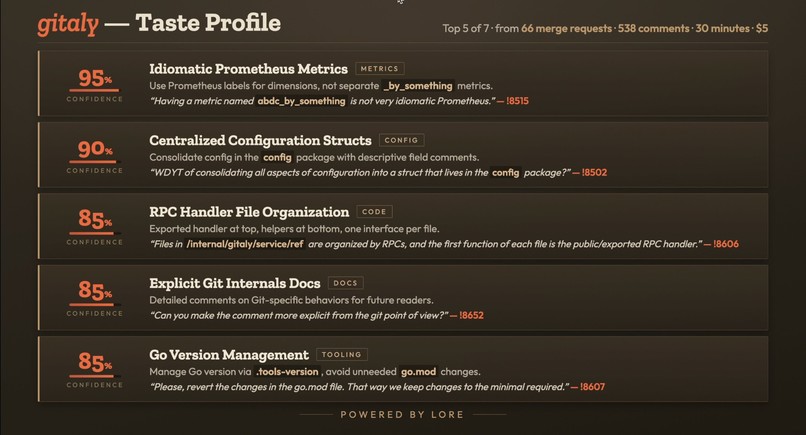
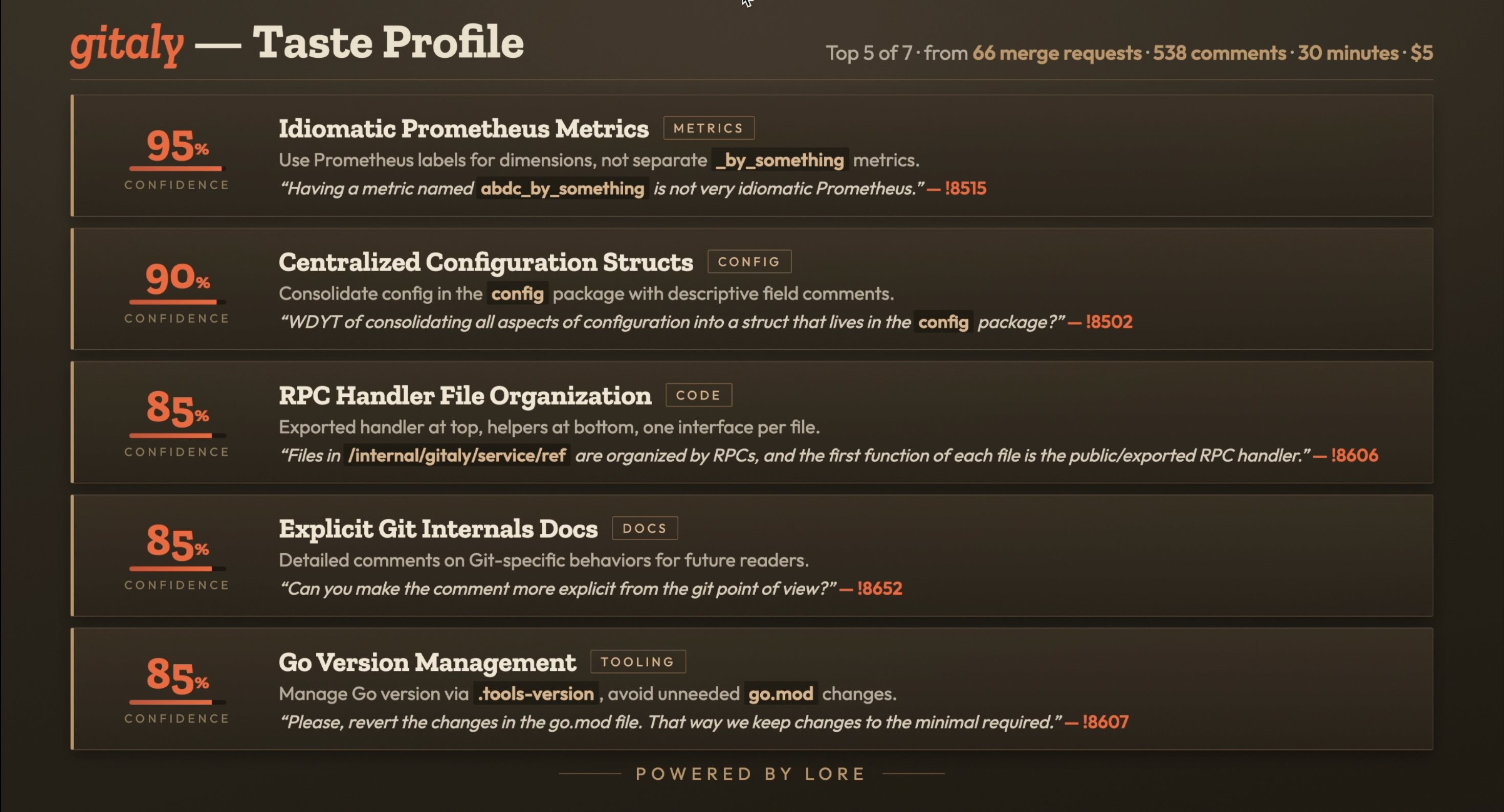
- Generalizes across projects. Pointed at gitaly — a codebase it had never seen — it surfaced 7 conventions from 66 MRs of history, in about 30 minutes for roughly $5. Any project with a review history has conventions like these; that run is the entire cost of onboarding one. Contributors on convention-relevant MRs waited a median of ~33 hours for their first correction comment; Lore delivers the same feedback in ~25 seconds.
Try it out
Everything here is reproducible — the same harness that produced the numbers above.
- Code:
gitlab.com/mbrazinski-group/lore— theagent/,scripts/,docs/, and the 191-test suite referenced throughout this write-up (MIT licensed). - Live demo project:
gitlab.com/mbrazinski-group/gitlab-runner— open MR #38 to see Lore flag a title, apply a label, flag a missing test, and recuse on a CI-tier convention; open MR #39 to see it post an all-clear on a clean MR. The taste-profile Issue lists all six learned conventions with their confidence values. - Reproduce convention discovery: run
scripts/discover_conventions.pyagainst a project's merged MRs to regenerate the HTML convention dashboard — 6 conventions for gitlab-runner, 7 for gitaly — each row linking the real reviewer quotes it was inferred from. - Reproduce the eval numbers: run
scripts/eval_harness.py --mode baselineto regenerate the flag-everything baseline, then score the endpoint against the 96-MR hand-labeled holdout — the title-quality 0.667 / 0.857 and the 87 → 3 reduction. - Verify a learned convention against real history: the gitaly rule "use Prometheus metric labels for dimensions rather than appending
_by_somethingto the metric name" is backed by the verbatim reviewer quote in gitaly MR !8515 — open it and compare. - Read the core insight:
docs/graduation-insight.md(the three-tier, explicit-to-tacit taxonomy) anddocs/adr-003-async-webhook.md(the Cloud Tasks async trampoline). - Watch it run: the demo video shows a live webhook-to-threads review end to end.
How we built it
The stack is the part judges expect; the part that actually differentiates Lore is the eval journey that turned a noisy agent into a trustworthy one. So that goes first.
Act 1 — Discovery: learning conventions from review history
Conventions live in reviewer comments, not in any config file — maintainers request the same fixes over and over, and that repetition is the signal. A five-stage pipeline (scripts/discover_conventions.py) turns that repetition into structured rules: extract reviewer comments from merged MRs (with hygiene filters that drop bots, boilerplate, and author replies) → classify each comment with Gemini Flash → cluster them by embedding similarity (gemini-embedding-001, cosine 0.75) → synthesize each cluster into a candidate convention with Gemini 3.1 Pro → report as an HTML dashboard.
Run against gitlab-runner's history (~500 MRs), it produced six conventions. The strongest signal was raw repetition: the documentation styleguide correction appeared on 14 distinct merge requests across five years, from four different maintainers; test-coverage requests on 10 MRs spanning 2020–2026. Run against gitaly — a project it had never seen — it produced seven, including "Use Prometheus metric labels for dimensions rather than appending _by_something to the metric name," backed by the verbatim reviewer quote "Having a metric named something like abdc_by_something is not very idiomatic Prometheus" from MR !8515. Every convention cites the MRs its evidence came from. That gitaly run took about 30 minutes and ~$5.
Act 2 — The eval journey (this is the centerpiece)
The first working agent flagged everything: 147 false positives across the 96-MR holdout, spread over all six conventions. It was technically functional and completely untrustworthy — and in code review, false positives erode trust faster than false negatives ever do. So we built an eval harness (scripts/eval_harness.py) that scores precision and recall per convention against 96 hand-labeled holdout MRs, and then drove the false-positive rate down by measurement, not by vibes.
We focused the headline on the convention that matters most and is hardest to get right: title quality — the judgment call a human actually argues about.
Stage 1 — five prompt variants on a 25-MR subset. A two-pass reasoning structure generalized best. The agent stopped pattern-matching keywords and started reasoning about intent.
Stage 2 — the full 96-MR holdout, and the insight that mattered most. No prompt rewrite could fix test-coverage false positives, because the model was guessing whether a test file existed — the diff doesn't show the rest of the package. The fix wasn't a better prompt; it was better input. We built a context enricher that fetches the directory's file tree so the agent can verify test-file existence instead of guessing. Input beats prompting — when the model is guessing, give it the fact, don't coax it. (This principle later survived a humbling test of its own; see Challenges.)
Stage 3 — Gemini 3.1 Pro, and a humbling discovery. On the stronger model, several title-quality "false positives" turned out to be genuine violations the maintainer simply never bothered to correct — the agent was right and our ground truth was wrong. We chose to keep the stricter, pre-audit ground truth as our published baseline rather than reclassify in our own favor (see Challenges).
The Precision Sprint. Two final changes: a SCREEN→CONFIRM two-pass detection prompt (a fast binary screen, then a defect-classification confirm) and temperature 0.2. Temperature was the single biggest lever on consistency — it collapsed run-to-run flag variance from wildly unstable to nearly fixed. Classification is not a place you want creativity.
The result, on title-quality: a naive flag-everything baseline produces 87 false positives. After eight measured variants and the sprint: three. Precision climbed from 0.09 to 0.67, recall 0.857 — from 87 to 3, a ≈29× reduction, every step falsifiable against a committed baseline you can regenerate with one command. And it isn't a one-run artifact: a separate, clean 96-MR evaluation — each MR scored exactly once — reproduces that headline exactly against the published ground truth.
We hold the other conventions to the same honesty. Label-correctness, reframed from the subjective "is the label correct?" to the mechanical "is a type:: label present?", lands at precision 0.500, recall 0.800 — and we publish that modest number rather than a flattering one. When we dug into its false positives, most traced to the agent over-generalizing from a single historical example; naming that limitation is more useful than hiding it.
The journey, in three numbers:
| Change | Metric | Result |
|---|---|---|
| Full pipeline (8 prompt variants → input enrichment → SCREEN→CONFIRM sprint) | Title-quality false positives | 87 → 3 (≈29×) |
| Temperature 0.2 | Run-to-run flag variance | wildly unstable → nearly fixed |
| A single maintainer 👎 | Convention confidence | 0.62 → 0.57, muted below 0.60 |
Final per-convention results (stricter pre-audit ground truth, published as primary):
| Convention | Tier | Precision | Recall | Note |
|---|---|---|---|---|
| Title quality | Judgment (tacit) | 0.667 | 0.857 | 3 false positives — down from 87 |
| Label correctness | Mechanical | 0.500 | 0.800 | Reframed to "is a type:: label present?" — the honest number, not a flattering one |
| Test coverage | Structural | — | — | Correctly silent — 0 structural violations in the 96-MR holdout |
Act 3 — The graduation insight
Running those evals revealed something we didn't design — we discovered it. Conventions sort into three tiers, and the tier dictates how much LLM a convention actually needs:
| Tier | Example | What it actually needs | Where it belongs |
|---|---|---|---|
| Mechanical (explicit) | Is a type:: label present? |
A set intersection — the LLM adds variance, not accuracy | Graduates into CI |
| Structural | Does new code have a test file? | Repository context — tool augmentation, not prompt engineering (the file-tree injection that beat every prompt rewrite) | Agent + tools |
| Judgment (tacit) | Is this title changelog-quality? | Irreducibly subjective reasoning — humans argue the borderline cases too | The LLM — where the ≈29× lives |
The payoff is a cost curve that bends down: as mechanical conventions are identified, they graduate out of the model and into CI rules, so per-review LLM cost falls as a project matures. The agent's deepest judgment isn't whether a convention is violated — it's which tier a convention belongs to. The strongest-mined convention in our corpus — documentation styleguide, appearing on 14 MRs across five years — is one Lore deliberately keeps silent, because it's mechanical. The mining proved the rule exists; the tier framework proved it doesn't need the LLM.
This is the tacit-knowledge thesis in miniature: the tiers are an explicit-to-tacit spectrum. A mechanical convention can be codified — so it graduates to a CI check. A judgment convention (is this title changelog-quality?) resists articulation; it stays tacit, and that's exactly where Lore earns its keep. Lore enforces what a maintainer could never quite write down, and hands off what they could. (Written up in full: docs/graduation-insight.md.)
The stack, woven in
┌──────────┐ webhook ┌─────────────────────────────┐
│ GitLab MR│ ───────────► │ FastAPI receiver (Cloud Run)│
└──────────┘ │ enqueue → return 200 fast │
▲ └──────────────┬──────────────┘
REST writes│ async │
• threads │ trampoline ▼
• labels │ ┌───────────┐
• summary │ │Cloud Tasks│
│ └─────┬─────┘
│ /process ▼ (20–25s review)
│ ┌──────────────────────────────┐
└───────────────────── │ Agent — Google ADK │
│ reasoning: Gemini 3.1 Pro │
└──────┬─────────────────┬──────┘
reads via MCP │ │ persists
┌──────────▼─┐ ┌────────▼──────────────┐
│ GitLab MCP │ │ Vertex AI Memory Bank │
│ MR+history │ │ corrections + │
└────────────┘ │ confidence values │
└───────────────────────┘
Secret Manager — stores & rotates the GitLab OAuth credentials
| Layer | Component | Job |
|---|---|---|
| Ingress | FastAPI on Cloud Run | Receives the GitLab webhook, enqueues, returns 200 instantly |
| Queue | Cloud Tasks | Deduplicating async trampoline so a 20–25s review never trips the webhook timeout |
| Reasoning | Google ADK + Gemini 3.1 Pro Preview | Runs the two-pass SCREEN→CONFIRM review and convention reasoning |
| Read | GitLab MCP Server | Two authenticated reads: citation enrichment, label validation |
| Write | GitLab REST | Posts resolvable threads, applies label quick-actions, writes the summary table |
| Memory | Vertex AI Memory Bank | Persists maintainer corrections and the confidence values self-learning updates |
| Secrets | Secret Manager | Stores and rotates the GitLab OAuth credentials |
The agent is built on Google ADK, with Gemini 3.1 Pro Preview (gemini-3.1-pro-preview) as the reasoning engine. A GitLab webhook hits a FastAPI receiver on Cloud Run, which immediately enqueues the work to Cloud Tasks and returns 200 — a deduplicating async trampoline (task ID = event_uuid + mr_iid) so a 20-second review never blocks GitLab's webhook timeout. The diff is fetched over REST so the prompt is fully populated deterministically before the model ever runs.
Three of the layers carry their own story:
Vertex AI Memory Bank — episodic correction memory that changes decisions. When a maintainer dismisses one of Lore's flags, that correction is written to Memory Bank, scoped to the project. Before Lore reviews a new MR, it searches that memory — and if a maintainer previously waved off a similar case, the retrieved correction flows into the prompt as prior-decision context, and the convention's confidence drops below the gate so the flag is suppressed. A retrieved memory changes a live decision. The retrieval is similarity-based, so a dismissal on "Fix cleanup bug" surfaces on a later "Fix config bug" — something a flat lookup table can't do. And only a maintainer's correction becomes a memory (we verify the reactor's project role); a contributor's reply can never poison what Lore learns.
GitLab MCP Server — two authenticated reads in the live review path. The official MCP server provides authenticated access to MR data and history. We use it for two auxiliary reads that run after the model has decided, in the orchestration layer, never touching the detection prompt's inputs: (1) when Lore cites a historical MR, it calls MCP search to fetch that MR's real title, so the thread footer carries a verified quote instead of a bare link; (2) before applying a label, it calls MCP search_labels to confirm the label exists, so Lore never claims to apply a label that silently no-ops. Both fail open — if MCP is unavailable, the review still posts. Writes that the official MCP server doesn't support — resolvable threads, label quick-actions, the summary table — go over REST, because those endpoints don't exist in the MCP toolset.
Secret Manager — credential bootstrap and rotation. The official GitLab MCP server is OAuth-only; a personal access token returns 403. We bootstrap credentials through mcp-remote and store and rotate the OAuth client ID and refresh token in Secret Manager.
Each piece does one job, and the layers never cross — the detection diff stays on REST for determinism, MCP handles auxiliary reads, Memory Bank handles episodic recall, and conventions.json holds the learned confidence dial.
Challenges we ran into
Ground-truth circularity. When the agent found genuine violations the maintainer had never corrected, we could have reclassified them as true positives — and our headline precision would have jumped to 0.89. We didn't. That reclassification depends on our own judgment about what the maintainer "should" have flagged, which is exactly the circularity that makes a number indefensible. We publish the stricter pre-audit ground truth (precision 0.67) and treat the agent-found-extra-violations result as a footnote, not a headline.
The principle was right; the plumbing didn't match it. Late in the build, live verification on a real MR caught that the context enricher had never actually worked in production. It parsed one diff-header format (+++ b/path) while GitLab's webhook emits another (+++ path), so it had been silently returning no repository context — and because the eval harness produced the same header format, the bug was invisible in eval too. We fixed the parser; the agent now reasons about real file trees. On the holdout's test-coverage cases it correctly declines to flag — 4 of 6 add no new exported API (nothing requires a test), and 2 of 6 already ship a *_test.go file. "Context absent → silent" became "context present → judged no violation." The insight held; the wiring finally caught up to it.
Write-only is a trap. Two of our "finished" features turned out to update state that nothing read. The confidence dial was being decremented on a 👎 but the decision gate never consulted it, so "self-learning" moved a number that changed nothing. We wired the stored confidence into the gate: now, when a convention's confidence falls below 0.60, it genuinely goes quiet on the next review. (Memory Bank had the same shape of bug — writing memories nothing retrieved — until we wired its read path, above.) Verifying that a feature runs is not the same as verifying it changes a decision; we learned to test for the second.
The MCP OAuth bridge. The official GitLab MCP server is OAuth-only — a personal access token returns 403. Bootstrapping credentials through mcp-remote and rotating them via Secret Manager was the single fiddliest piece of infrastructure in the build. (The community MCP server only exposes write tools — the wrong direction entirely.)
Cold start and the timeout. A full review runs 20–25 seconds against GitLab's webhook timeout. Cloud Tasks solves it structurally: receive, enqueue, return 200 instantly, and do the real work asynchronously against /process.
Boundary cases are where humans argue too. "Fix yaml config" is genuinely borderline changelog-quality — these are the false positives reviewers disagree about. SCREEN→CONFIRM plus temperature 0.2 mean that at least the agent is consistently wrong about the same edge cases a human would debate, instead of flickering run to run.
Accomplishments we're proud of
Technical. A ≈29× false-positive reduction (87 → 3) on the hardest convention, driven entirely by systematic, measured prompt and input engineering. A multi-mode eval harness (baseline → full holdout → model upgrade → recount) that made every change falsifiable against a committed artifact. A discovery pipeline that onboards a brand-new project in ~30 minutes for ~$5. A Memory Bank integration that genuinely changes review decisions, with a maintainer-only poisoning guard. Two authenticated MCP reads in the live path that keep the detection core deterministic. A test suite that grew from ~108 to 191 tests as we hardened each of these. And ~16,000 lines of code built solo — 2,400 lines of deployed runtime backed by 3,500 lines of tests (1.4:1 ratio), with the eval harness and discovery pipeline making up the largest segment.
Impact, from Lore's own data. Of 2,000 reviewer comments across 292 MRs, 421 were convention-corrections — maintainers manually restating the same rules. At a conservative 2–3 minutes each, that's 14–21 hours of repetitive review work; annualized over the recent near-complete window (~290 corrections/year), an estimated 10–15 maintainer-hours per year on one project. Contributors on those MRs waited a median of ~33 hours for their first correction — feedback Lore delivers in ~25 seconds. (Full derivation: docs/impact-estimate.md.)
Product. Every prediction links to a specific MR from the project's own history — and with MCP citation enrichment, that link carries the cited MR's real title, not just an ID. Lore takes three kinds of action — flag a discussion thread, apply a label via quick-action, or recuse to a recommended CI gate — and cites a verified historical MR for each. Self-learning that visibly responds to a single 👎, and episodic memory that recalls a maintainer's correction on the next similar MR. And discrimination as a first-class feature: of six conventions, Lore flags or fixes three, recuses on one, and deliberately stays silent on two. Choosing not to flag is as much the architecture as flagging.
Process. Eval-driven development — no convention shipped without a precision/recall number behind it. Honest numbers published as primary, flattering numbers refused. A live-verification discipline that caught a production bug our eval harness had been blind to. Built solo, with a PM's instinct that the eval narrative is the product story.
What we learned
- The eval is the product. The harness mattered more than the agent. Without a precision number, "improving the prompt" is just superstition.
- Input beats prompting for structural rules. Giving the model the file tree outperformed every prompt rewrite — and the day we verified it live was the day we discovered it had never been wired correctly. Both lessons in one.
- Write-only is a trap. A feature that runs is not a feature that works. Memory Bank and the confidence dial both looked done while changing nothing; "does a retrieved memory change a decision?" is the only test that mattered.
- Not everything needs an LLM. Convention detection has tiers; mechanical checks belong in CI, and the model should graduate out of them over time.
- Ground truth is a moving target. Maintainers don't correct every violation, so "the agent disagrees with the label" sometimes means the agent is right — which is exactly why you don't get to grade your own ground truth.
- Temperature is a classification knob. Determinism is a feature here, not a limitation; 0.2 was the difference between an agent that flickered and one a maintainer could trust. ## What's next
Automatic graduation. The graduation endpoint isn't just identifying which conventions belong in CI — it's generating the linting rule itself, so the convention literally exports itself out of the model. Danger plugins, pre-receive hooks, AST checks — a project's LLM cost decreases as its rules mature.
Convention evolution. Lore mines the past to enforce the future, which means it needs to detect when a project's patterns shift. Periodic re-mining to refresh the convention set ensures Lore doesn't enforce yesterday's architecture against tomorrow's goals.
Transferable memory. Today Lore's correction memory is scoped per project. The next step is letting conventions learned on one project seed review on a similar one — gitaly proved the discovery pipeline generalizes; making the learned memory travel is the follow-on.
Memory Bank ablation. Running the eval with and without Memory Bank context injection to mathematically isolate the precision impact of episodic correction memory — the live round-trip is proven, but the statistical delta is owed.
Re-review reconciliation. Today, re-review is duplicate-safe but not self-cleaning: a stale flagged summary persists after a contributor fixes the issue. Editing the summary in place and resolving threads whose violation is gone, so a corrected MR upgrades to all-clear, is the immediate next feature ticket.
Production hardening. The all-clear comment transitions to GitLab's Commit Status API — a silent pass/fail check that doesn't trigger notification noise. The demo uses a visible comment to prove Lore ran; production uses a quiet signal.
Cross-convention correlation. Maintainers who care about metric naming tend to care about configuration structure — convention clusters that predict what else a reviewer will flag.
Reviewer-specific patterns. Different maintainers enforce different subsets; the memory can be sliced by reviewer.
Beyond MRs. The same tacit-knowledge idea extends to issue triage and CI-pipeline conventions — anywhere a team enforces norms it has never fully written down.
The vision is simple: the tacit knowledge a project runs on shouldn't live and die in its maintainers' heads. It should be surfaced, made teachable, and there to greet every contributor on day one — so the maintainer never re-types what they could never quite write down, and the contributor never waits to hear it.
Built With
- cloud-run
- cloud-tasks
- fastapi
- gemini-pro-3.1-preview
- gitlab-mcp
- google-adk
- python
- secret-manager
- vertex-ai-memory-bank

Log in or sign up for Devpost to join the conversation.