-
-

Four-step flow: a free-text recommendation becomes a typed Handoff Contract, gets checked against FHIR, then closes or escalates.
-
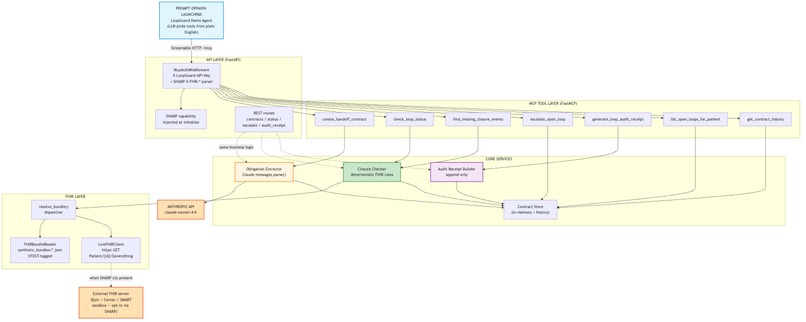
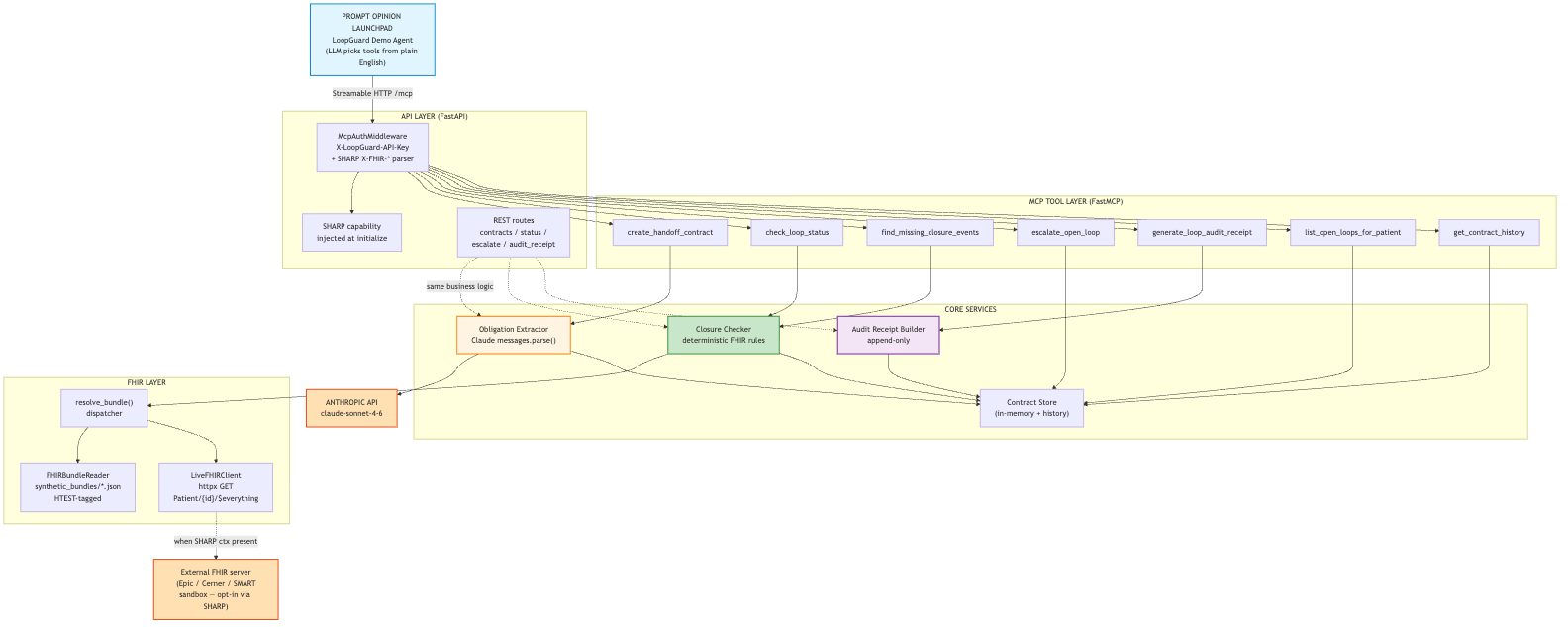
Seven MCP tools over a FastAPI core, a deterministic FHIR closure checker, and a client that toggles synthetic vs. live SMART-on-FHIR.
-
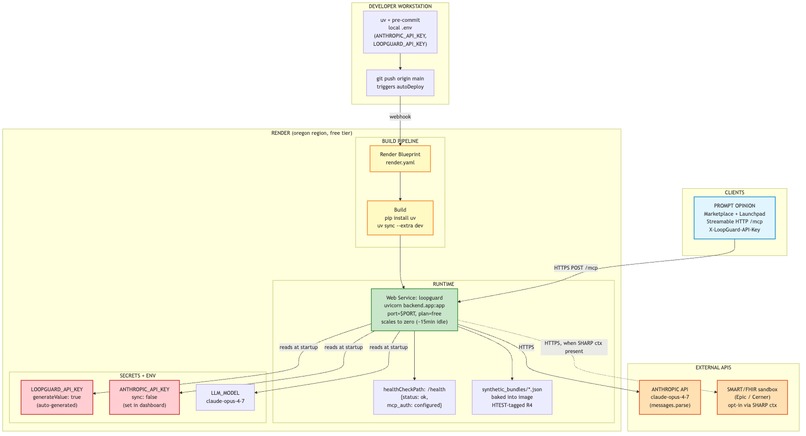
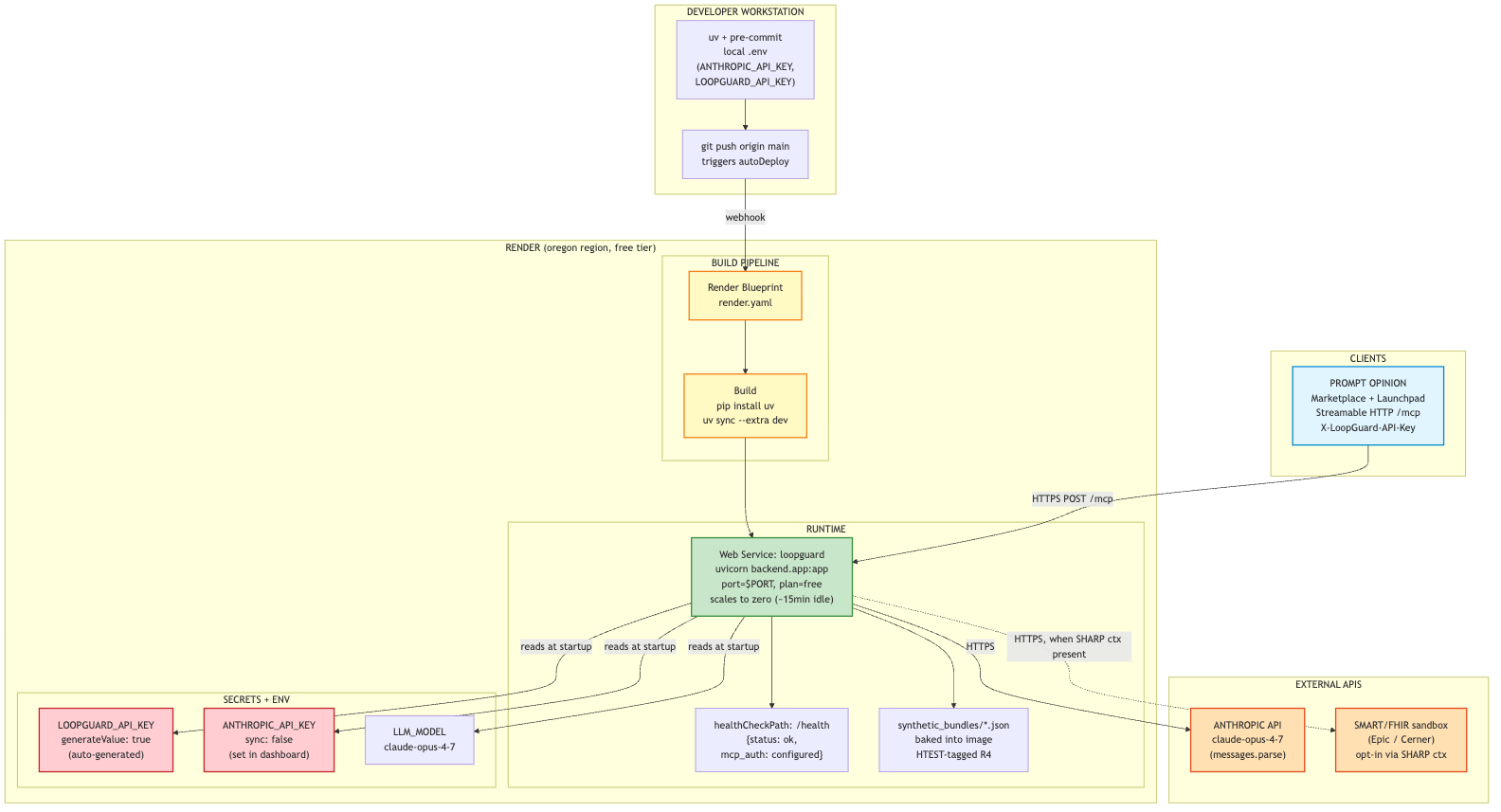
One Render web service auto-deploys from main, reads secrets at startup, serves /mcp to Prompt Opinion, and calls Anthropic over HTTPS.
-
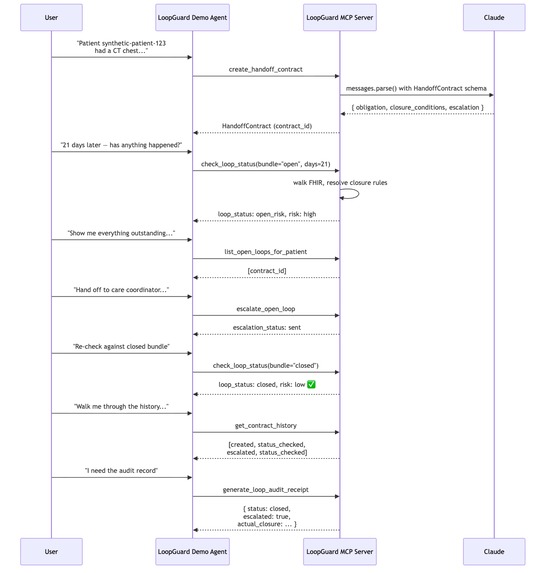
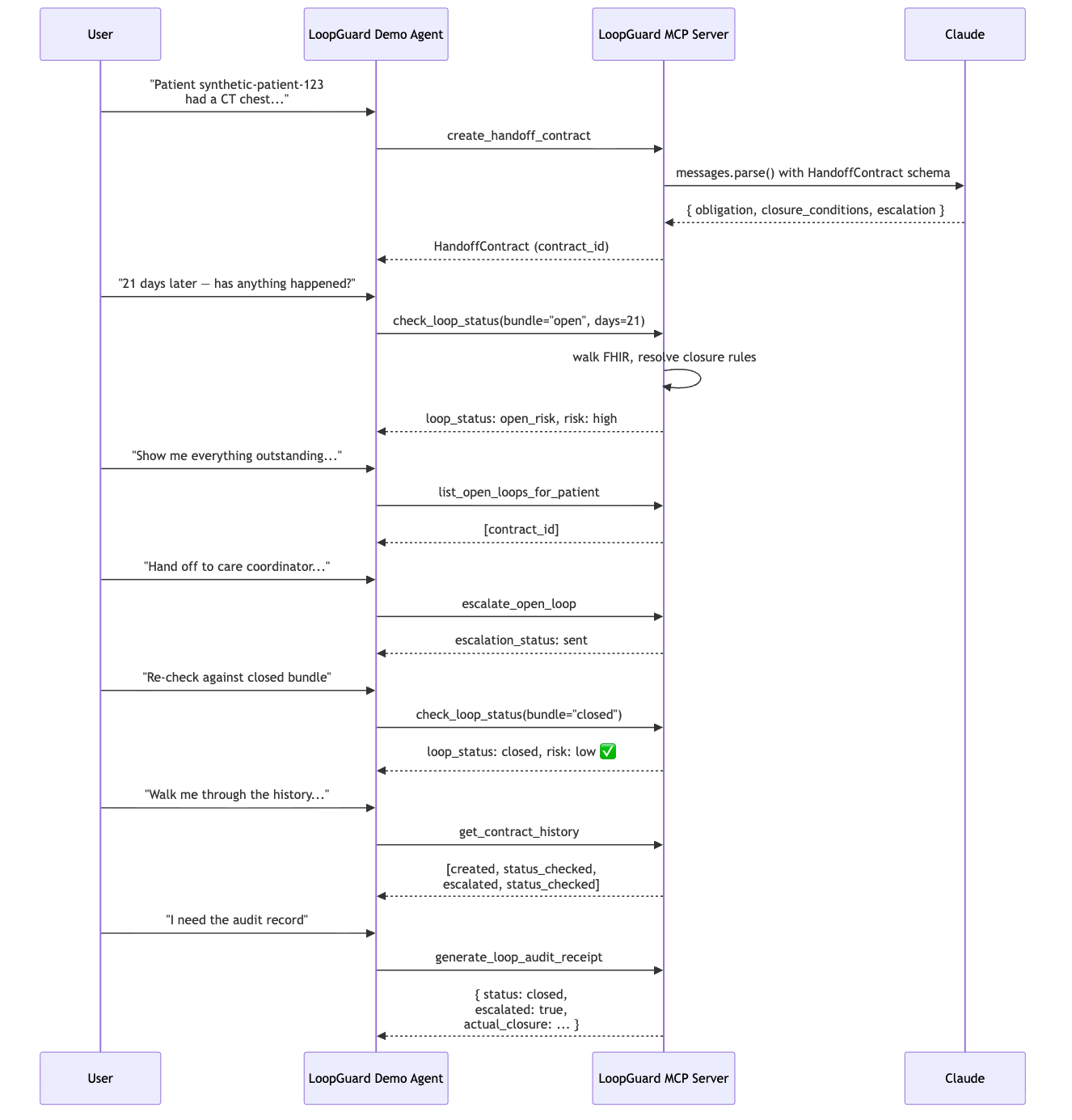
Six plain-English prompts route to the right MCP tool; the loop flips from red "open risk" to green "closed" after the closure bundle.

Inspiration
Too many patients fall through the cracks after an important follow-up is recommended.
A doctor says “see pulmonology in 2 weeks,” or a care team flags an abnormal result, but from there the next step can get lost between people, systems, and handoffs. The recommendation exists, but no one can easily prove whether the follow-up actually happened. That gap is one of the most painful and costly failures in healthcare operations.
We built LoopGuard because that problem becomes even more urgent in the age of AI. More healthcare AI tools will generate more recommendations, faster than ever. But a recommendation only matters if someone owns it, tracks it, and closes the loop. We wanted to build the accountability layer that sits between recommendation and action.
What it does
LoopGuard makes sure important follow-ups in healthcare actually happen.
When a care team or AI system recommends a next step, LoopGuard turns that into a tracked follow-up with a clear owner, due date, and expected outcome. It then checks whether the follow-up was completed, identifies what is still missing, and escalates when a patient may be at risk of being overlooked.
In simple terms, LoopGuard answers three questions:
- What needs to happen next?
- Did it actually happen?
- If not, who needs to act now?
Under the hood, LoopGuard is an MCP server with seven tools. Other healthcare AI agents on Prompt Opinion, from radiology and lab review to discharge planning and prior authorization, can call those tools through one integration to make their recommendations accountable. It is not trying to replace clinicians or give medical advice. Its job is to make care coordination safer, more visible, and more accountable.
How we built it
We built LoopGuard as an MCP-powered healthcare workflow product that other AI tools can call when they need follow-up accountability.
We used Claude to interpret plain-English recommendations and turn them into structured next steps with closure conditions, due dates, and owners. From there, LoopGuard checks healthcare data in FHIR format to see whether the expected action actually happened, such as an appointment being booked, a task being completed, or outreach being documented. If the loop is still open, LoopGuard can flag the risk, surface what is missing, and generate an audit trail of what happened.
The server is SHARP-on-MCP compliant, so Prompt Opinion can pass us FHIR access tokens at request time. We also wired a live SMART-on-FHIR client so the same closure rules can work against real EHR data when available. For the demo, we used synthetic data only and built three end-to-end patient scenarios: a suspicious lung nodule, critical hyperkalemia, and postpartum hypertension.
Challenges we ran into
The biggest challenge was balancing flexibility with trust.
AI is very good at understanding messy human language, but healthcare follow-up is too important to leave entirely to a black box. We had to design the product so AI could help interpret recommendations, while the actual follow-up verification stayed clear, structured, and explainable.
Another challenge was making the project feel like a real product instead of just a technical demo. We spent a lot of time simplifying the experience so the core story was easy to understand: a recommendation was made, the loop stayed open, LoopGuard caught it, and the loop was eventually closed.
We also worked within hackathon constraints, including synthetic-data-only requirements and a short demo format, while still building something that reflects a real healthcare workflow problem.
Accomplishments that we're proud of
We are proud that LoopGuard feels like a real product with a clear job to do.
We built a working system that can:
- capture a recommended follow-up,
- track whether it happened,
- flag when it is overdue,
- escalate when action is needed,
- and create a clear audit record of the full chain of events.
All of this is backed by 120 automated tests, strict type checking, and three end-to-end patient scenarios that exercise different closure shapes: appointment-based, task-based, and communication-based. The product was verified live in Prompt Opinion, supports seven MCP tools, and includes a live SMART-on-FHIR path for production readiness.
We are also proud that LoopGuard was designed to compose with, not compete against, other healthcare agents on the marketplace. We are not the next clinical decision support tool. We are the accountability layer that makes sure important follow-ups do not disappear. Most importantly, we built something that does not just generate another recommendation. It creates accountability around whether care actually moved forward.
What we learned
We learned that one of the best uses of AI in healthcare is not just generating answers, but making workflows more reliable.
We also learned that trust comes from visibility. In a setting like healthcare, it is not enough for a system to say “this looks done.” People need to know what was expected, what happened, what is still missing, and who owns the next step.
Most of all, we learned that a strong healthcare AI product should fit into real work. The most valuable thing we could build was not another assistant talking to a user. It was a layer that helps teams avoid missed follow-ups and protect patients from being forgotten.
What's next for LoopGuard
Next, we want to move LoopGuard from a hackathon prototype toward a production-ready care coordination product.
That means connecting it more deeply to live healthcare systems, adding durable storage, improving operational visibility for care teams, expanding the types of follow-ups it can monitor, and integrating escalation into the channels real teams already use.
Longer term, we see LoopGuard becoming a shared accountability layer for healthcare AI: whenever a recommendation creates a real-world obligation, LoopGuard helps make sure that obligation does not disappear.



Log in or sign up for Devpost to join the conversation.