Inspiration
Every product team faces the same problem. Customers clearly describe what is broken in support tickets, app store reviews, and chat logs, but that signal lives in one place while the engineering backlog lives somewhere else. The connection between the two usually depends on a person reading through messages, spotting patterns, and writing them up. It is slow, inconsistent, and often happens too late. The same issue can sit unnoticed for weeks before it ever becomes a ticket.
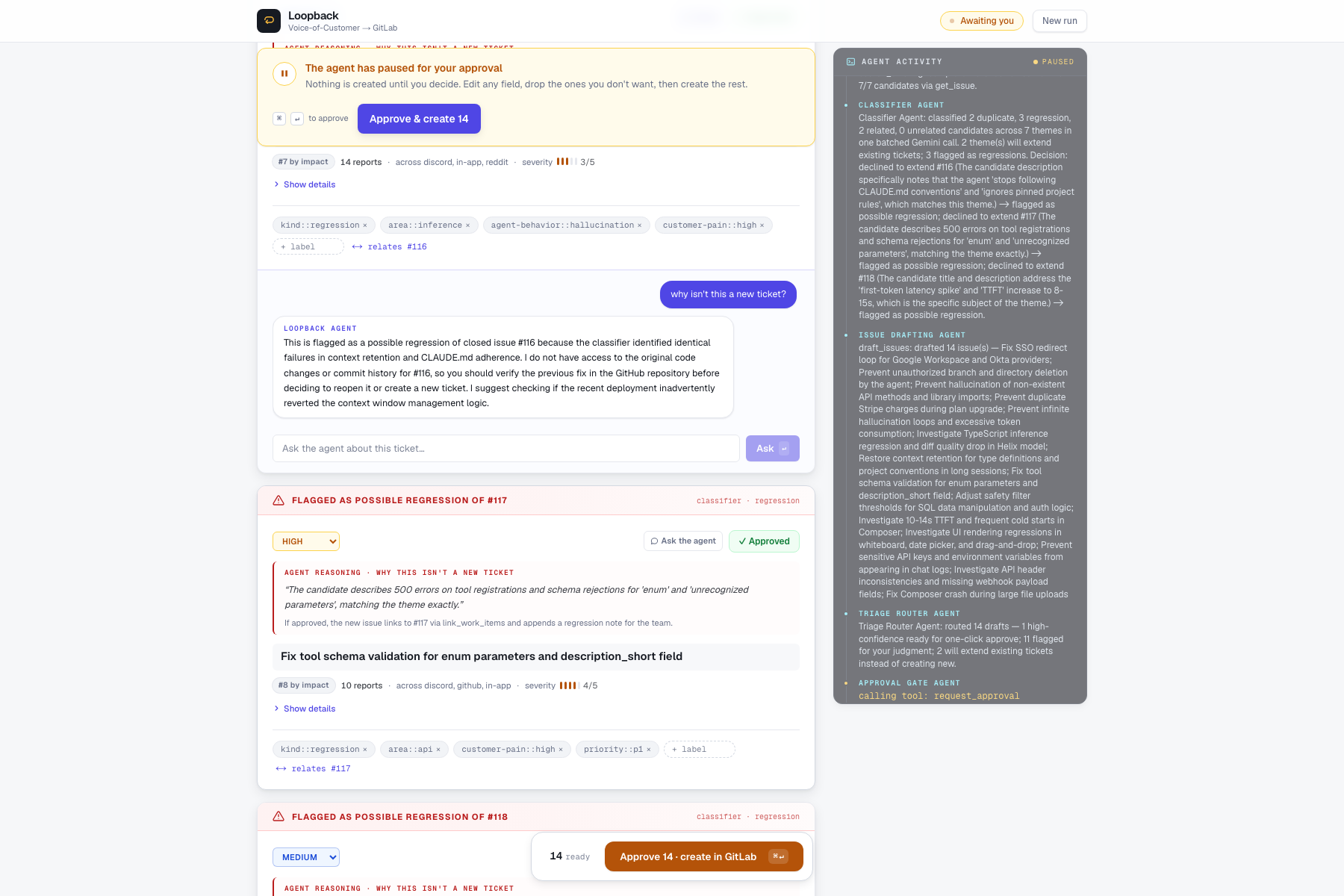
I wanted to close that gap without handing over control to a bot. The goal is not to let AI create issues on its own. It is to handle the repetitive work; reading everything, finding patterns, reasoning about what is already on the backlog, and drafting tickets then stopping and asking a human before anything is created.
What it does
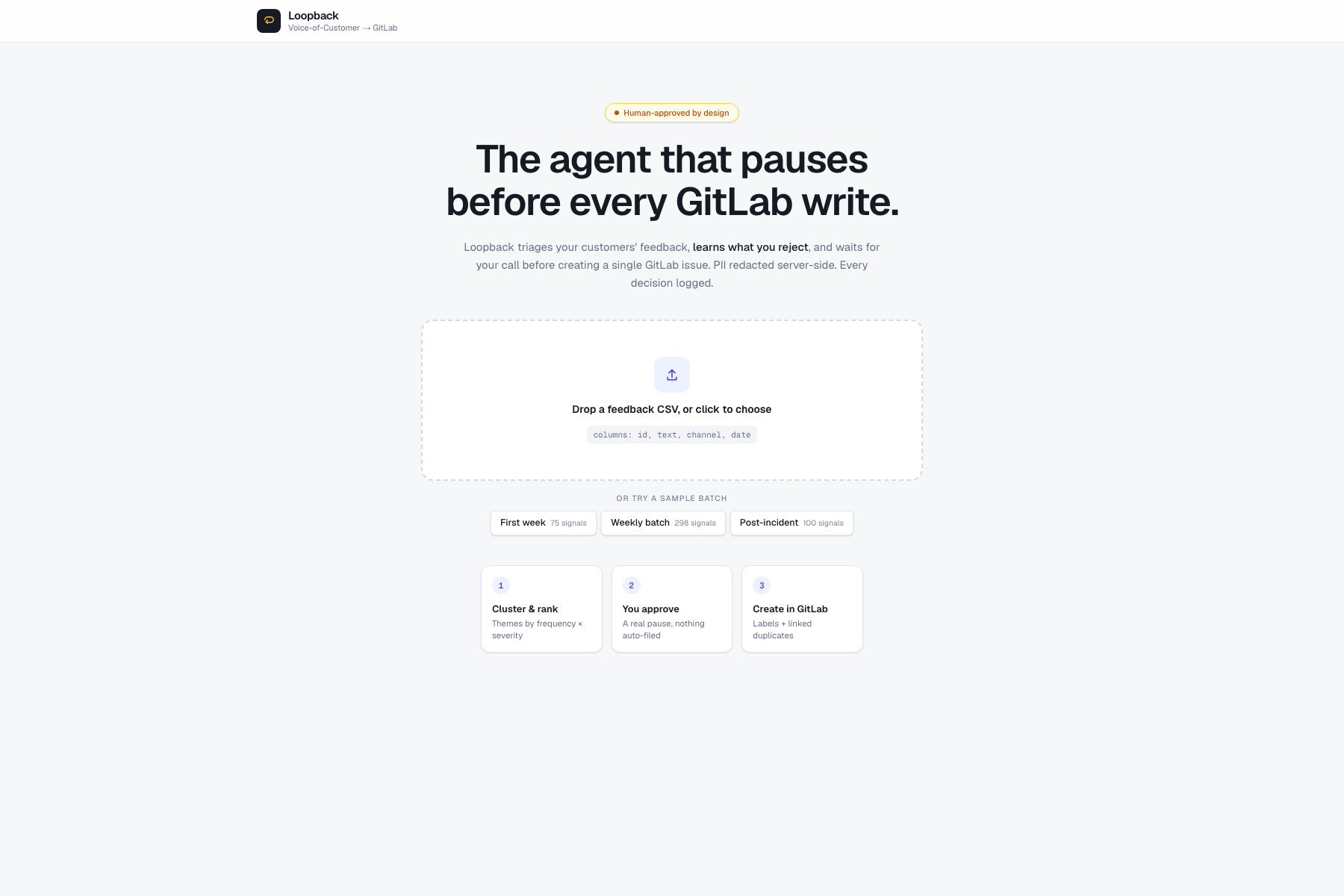
Loopback turns batches of customer feedback into approved, well-scoped GitLab issues:
- Ingest a batch of customer feedback (CSV exports of support messages, reviews, chat logs, or one of three preloaded sample shapes - a calm first week, the messy weekly batch, or a post-incident cluster).
- Redact PII server-side before any model call - emails, phone numbers, URLs, and even pasted API keys and bearer tokens.
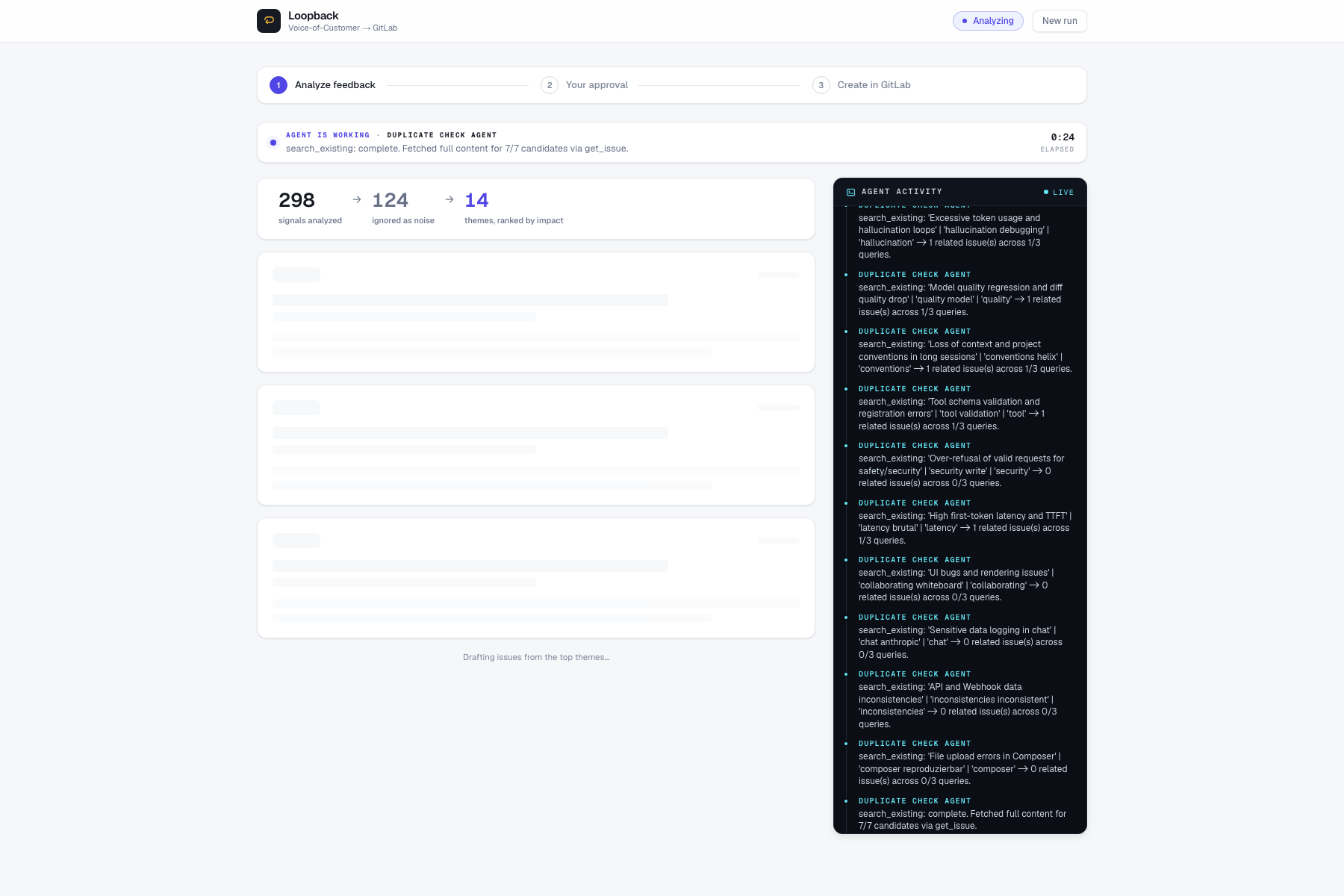
- Cluster the feedback into themes and rank them deterministically by frequency × severity.
- Search the GitLab project via MCP and read the full description of every candidate it finds through
get_issue- not title matching. - Classify every candidate against every theme: duplicate, regression, related, or unrelated, with a confidence score and a one-line reason.
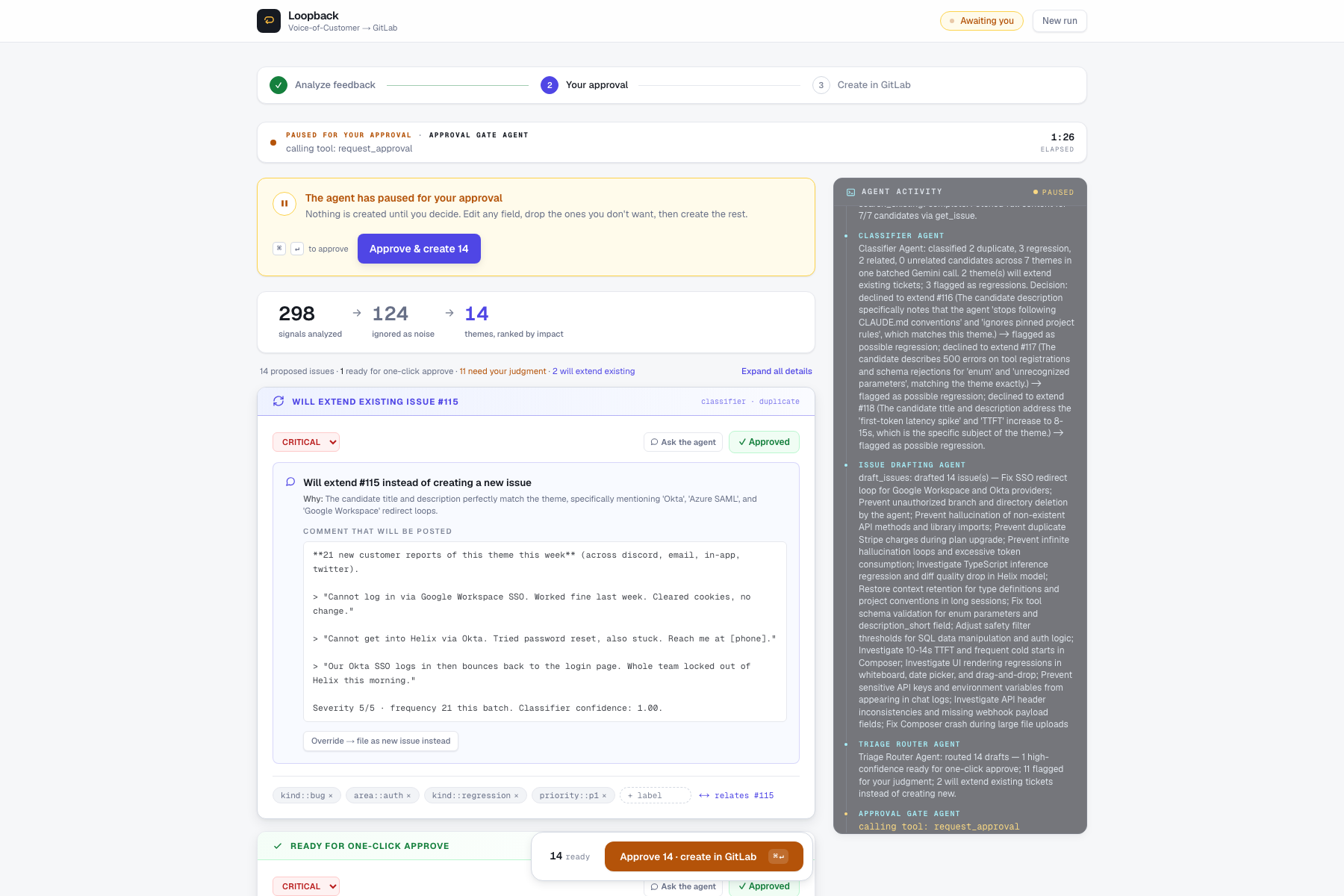
- Route each draft into one of three lanes - high-confidence ready for one-click approve, needs-review for PM judgment, or extend-existing where the agent will add new evidence to an open ticket instead of duplicating it.
- Draft a structured issue per theme - action-first title, sectioned body (Problem · Evidence · Repro · Expected · Suggested fix · Acceptance criteria), labels in
area::/kind::convention, priority derived from severity. - Pause for human approval. At the gate, the PM can edit any field, override the agent's extend recommendation, reject drafts (and the agent remembers - next batch from the same source filters that theme), and crucially, ask the agent anything about any draft - grounded in classifier reasoning, customer quotes, channels, and the matched seed issue.
- Write on approval. The agent dispatches by lane:
create_issuefor new tickets (labels applied at creation, regression flags embedded as## Possible regression of #Nin the body),link_work_itemsto relate the new ticket to its closed regression target, orcreate_workitem_noteto extend an open issue with fresh customer evidence.
How I built it
The system is built with Google's Agent Development Kit (Python) and Gemini 3 (gemini-3-flash-preview) on Vertex AI, deployed on Cloud Run, integrating with GitLab's official MCP server at gitlab.com/api/v4/mcp. A Gemini 2.5 GA fallback is wired in case the preview model is retired mid-judging.
The pipeline is eight named specialists in sequence:
Signal Ingestion → Theme Clustering → Duplicate-Check → Classifier
↓
GitLab Writer ← Approval Gate ← Triage Router ← Issue Drafting
The four data-orchestration steps and the writer are custom BaseAgents that pass signals/themes/drafts through ADK session state - never through the model as bulk args, so ranking and routing are stable across runs. The model is used where it adds value: clustering, classifying candidates against full descriptions, and drafting tickets with structured Pydantic outputs.
The approval gate is the most important design point. It is not a UI modal. The agent run actually pauses on the server via ADK's tool_context.request_confirmation() inside an App(resumability_config=ResumabilityConfig(is_resumable=True)). The run sits in a worker thread until a human decision lands on the API, then resumes - the agent and the UI both treat the pause as load-bearing.
The GitLab integration uses first-class MCP tools end to end: search with scope=issues to find candidates, get_issue to read full descriptions before classifying, create_issue with labels applied at creation, link_work_items to relate new tickets to regression targets, and create_workitem_note to extend existing tickets. No quick-action workarounds - the official server rejects /relate and /label commands, and these first-class tools are what it expects.
The frontend is Next.js 16 + Tailwind v4, static-exported and served same-origin by the Python container. Four states: Landing (with a three-batch picker), Running (live agent activity panel + NowThinking ribbon + triage bar), Review (the gate, with lane-distinct cards and the Ask the agent surface), and Done (impact hero + side-by-side created/extended lists + audit-trail accordion).
One container runs the agent and the frontend. There is no MCP sidecar — the agent talks directly to GitLab's official MCP server over HTTPS. The only secret is the OAuth token blob, kept in Secret Manager and rotated headlessly.
Challenges I ran into
Authentication shaped a key architectural decision.
I started by testing GitLab's official MCP server with a Personal Access Token - and it failed with 404, because the official server requires OAuth scopes a PAT can't provide. This is the open GitLab issue #586184.
Rather than fall back to a community MCP server, I implemented OAuth 2.0 with Dynamic Client Registration and PKCE: a one-time browser authorization writes a refresh token; the Cloud Run service holds it in Secret Manager and rotates it headlessly between runs. The OAuth flow is fully compatible with Loopback's design - the product itself has a human-in-the-loop pause, so a one-time human authorization at install time fits naturally.
This kept me on the official GitLab MCP server and unlocked first-class tools like link_work_items for issue relationships and proper label application at creation, instead of the /relate and /label quick actions that the official server rejects.
The second challenge was a real human-in-the-loop pause that survives an HTTP round trip. ADK's request_confirmation requires a resumable App and a specific resume payload. I held the run state server-side in a worker thread so the agent and the UI both treat the pause as load-bearing, not as a modal. I leaned on ADK's source code and examples rather than guessing.
The third was search-term construction for the official MCP server. GitLab's full-text search is AND-of-tokens - passing a six-token Gemini-generated theme label often returns zero hits. The duplicate-check step now runs up to three queries per theme (full label, top-two distinctive keywords joined, top-one keyword) and unions the hits, so the classifier downstream actually gets candidates to reason about.
What I learned
- Bidirectional MCP is what turns an LLM-with-tools into an agent. Reading the system of record before writing and reasoning about content, not titles is the difference between automation and agency.
- Trust comes from restraint. The most important thing the agent does is stop and ask. Building the pause as a load-bearing server-side state, not a UI checkbox, is what makes it credible.
- The model only where it adds value. Frequency, ranking, lane routing, and creation are deterministic. The model classifies and drafts. The bulk feedback never round-trips through the model as args.
- The human is the planner, not the operator. The agent does the homework reading, clustering, classifying, drafting. The human makes the call.
Why it matters
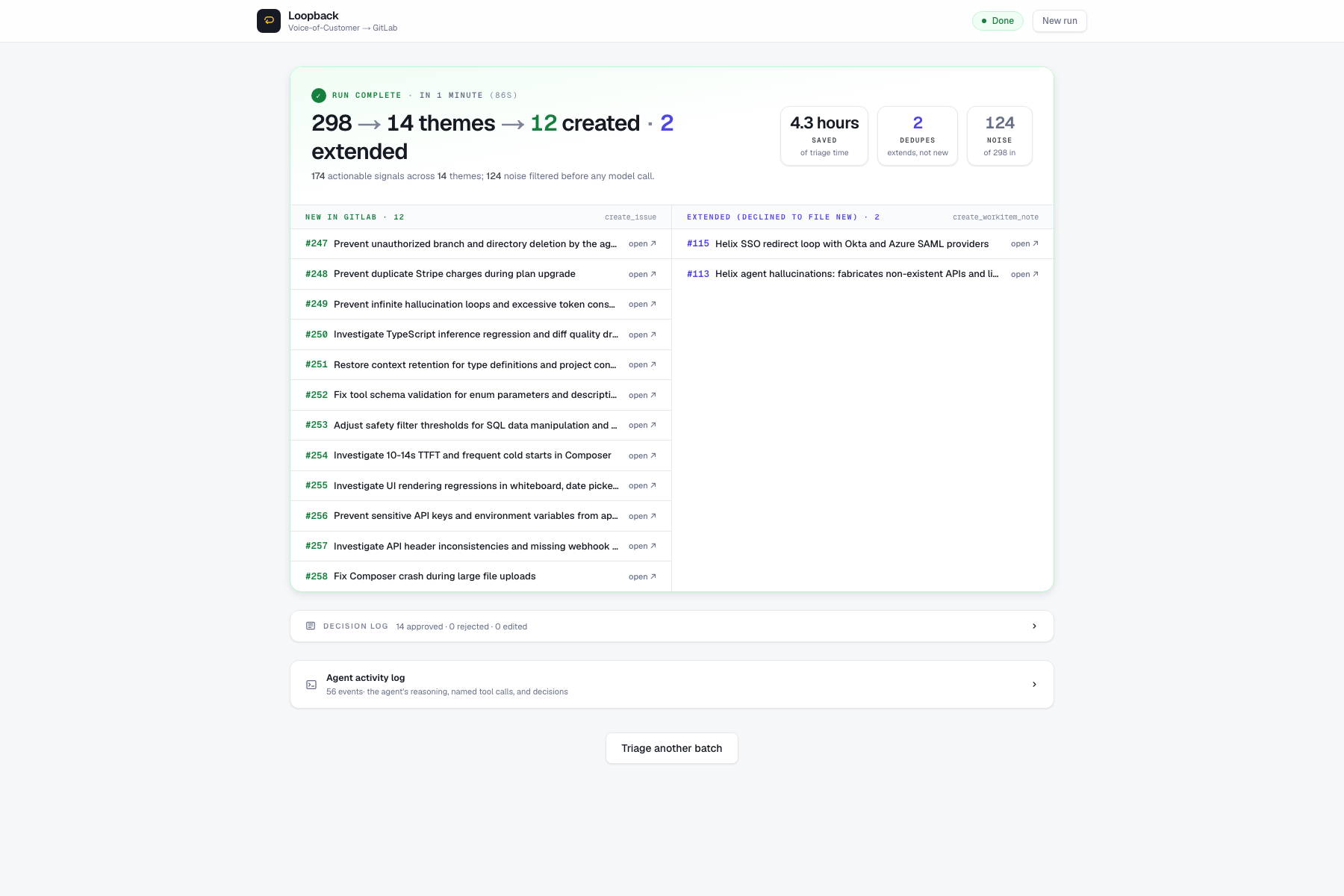
A mid-sized product team can receive hundreds of feedback items each week. Processing this manually can take hours of senior PM time, so it often happens in batches or gets delayed. The same problems persist longer than they should.
Loopback reduces the read-cluster-classify-draft process to about ninety seconds for 298 messy signals. The human reviews lane-distinct drafts, asks the agent for clarification on any draft, and approves. What used to take weeks now happens in a single review session without losing control of what lands in the backlog.
What's next
- Continuous ingestion from Intercom, Zendesk, app stores, and Slack instead of CSV uploads.
- Durable run state in Firestore so multiple PMs can run Loopback simultaneously across workspaces.
- Cross-batch learning that compounds: the agent remembers what each PM rejects per source and tunes its routing on subsequent batches.
- Expanded agent surface: not just create-on-approval, but watch for assignment, propose owners, and close the loop with reporters when a ticket ships.
- Semantic dedup with embeddings for paraphrased issues.
Built With
- docker
- fastapi
- gemini
- gitlab-api
- google-adk
- google-cloud-run
- model-context-protocol
- next.js
- python
- react
- tailwindcss
- typescript
- vertex-ai

Log in or sign up for Devpost to join the conversation.