Inspiration
Modern SRE (Site Reliability Engineering) systems repeatedly fail in the same ways. Engineers often debug incidents like “database is slow” or “latency spike” by trying similar steps over and over again, many of which fail silently.
We were inspired by a simple question:
What if an AI agent could actually remember its past mistakes and improve over time like a human engineer?
That idea led to Loopback, a self-improving SRE agent that turns every incident into long-term memory using MongoDB.
What it does
Loopback is an AI-powered incident response agent that learns from its mistakes.
When an incident occurs (e.g., “Database is slow”), the agent:
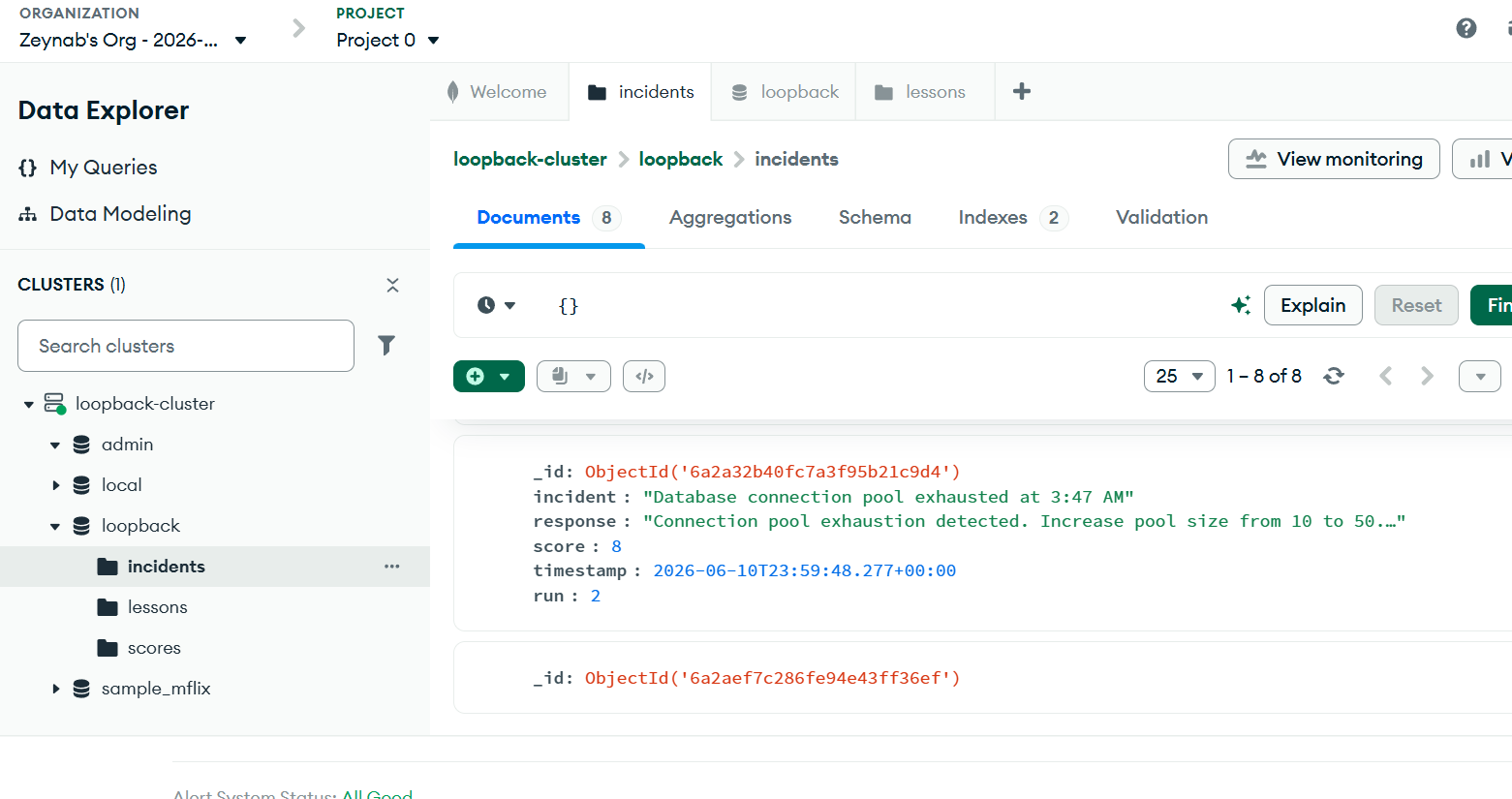
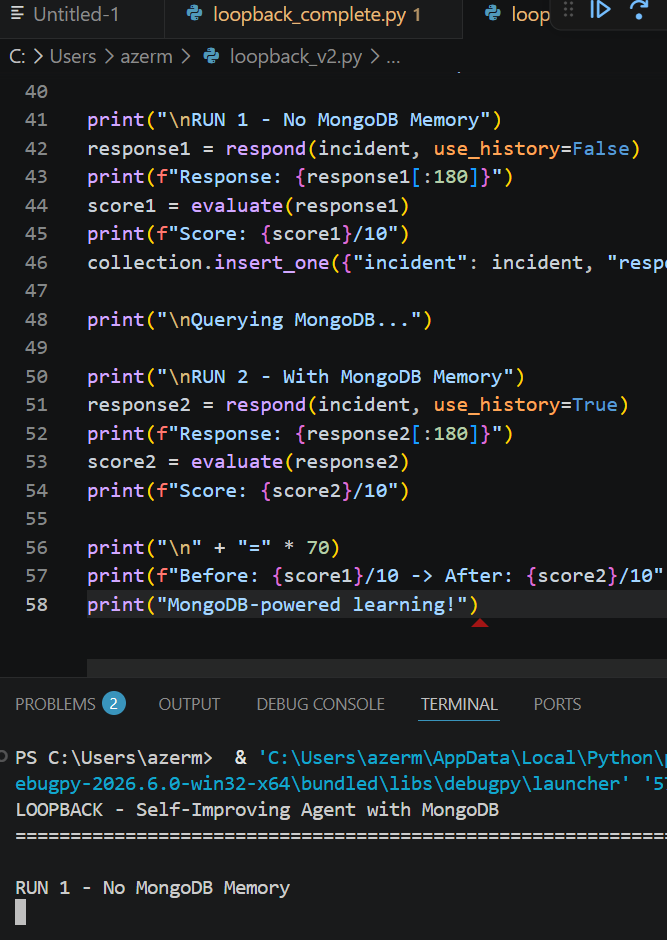
Generates a diagnosis and response Receives a score (e.g., 3/10 if incorrect) Stores the incident, response, and score in MongoDB Retrieves past similar failures on future incidents Uses that memory to improve its next response (e.g., 8/10)
Over time, the system becomes smarter, not by retraining models, but by learning from persistent memory.
How we built it
Loopback is built using:
Google Cloud Agent Builder for the Gemini-powered agent orchestration MongoDB Atlas as the persistent memory layer MongoDB MCP Server to expose database operations as tools Cloud Run to deploy the MCP server Node.js-based tool calling between agent and MCP Architecture
Incident → Gemini Agent → MCP Tools → MongoDB Atlas ↓ Retrieve past failures + store new ones
We implemented a tool-based memory system where the agent can:
Query past incidents Retrieve similar failures Store new attempts Update performance scores
This enables a true feedback loop architecture rather than static RAG.
Challenges we ran into
- MCP integration complexity
Initially, we tried using MongoDB Atlas as a knowledge base inside Agent Builder, but that did not satisfy the hackathon requirements.
We had to migrate to the MongoDB MCP Server approach, which required deploying a separate tool layer on Cloud Run.
- Memory design
Designing the schema for “learning” was non-trivial. We had to ensure each record captured:
incident type agent response score timestamp improvement signal
This was essential to allow retrieval of past failures in context.
- Making improvement measurable
We needed a way to show learning clearly in the demo. We solved this by simulating scoring (3/10 → 8/10) and showing how prior failures directly influenced better responses.
What we learned
MCP is powerful because it turns databases into active tools, not passive storage Memory is more important than model size for many real-world agent systems “Agent improvement” must be observable and measurable, not abstract Cloud Run + MCP is a clean pattern for tool-augmented AI systems
Built With
- express.js
- gemini-api
- google-cloud-vertex-ai
- mongodb-atlas
- node.js
- python

Log in or sign up for Devpost to join the conversation.