Inspiration
Large language models are good at many general tasks, but often see poor performance on specialized tasks. Prompt tuning iterations are time consuming, and fine-tuning is out of reach for a majority of people. Just like models can be prompted with language, we were inspired by the goal of creating specialized models created purely from a problem statement.
What it does
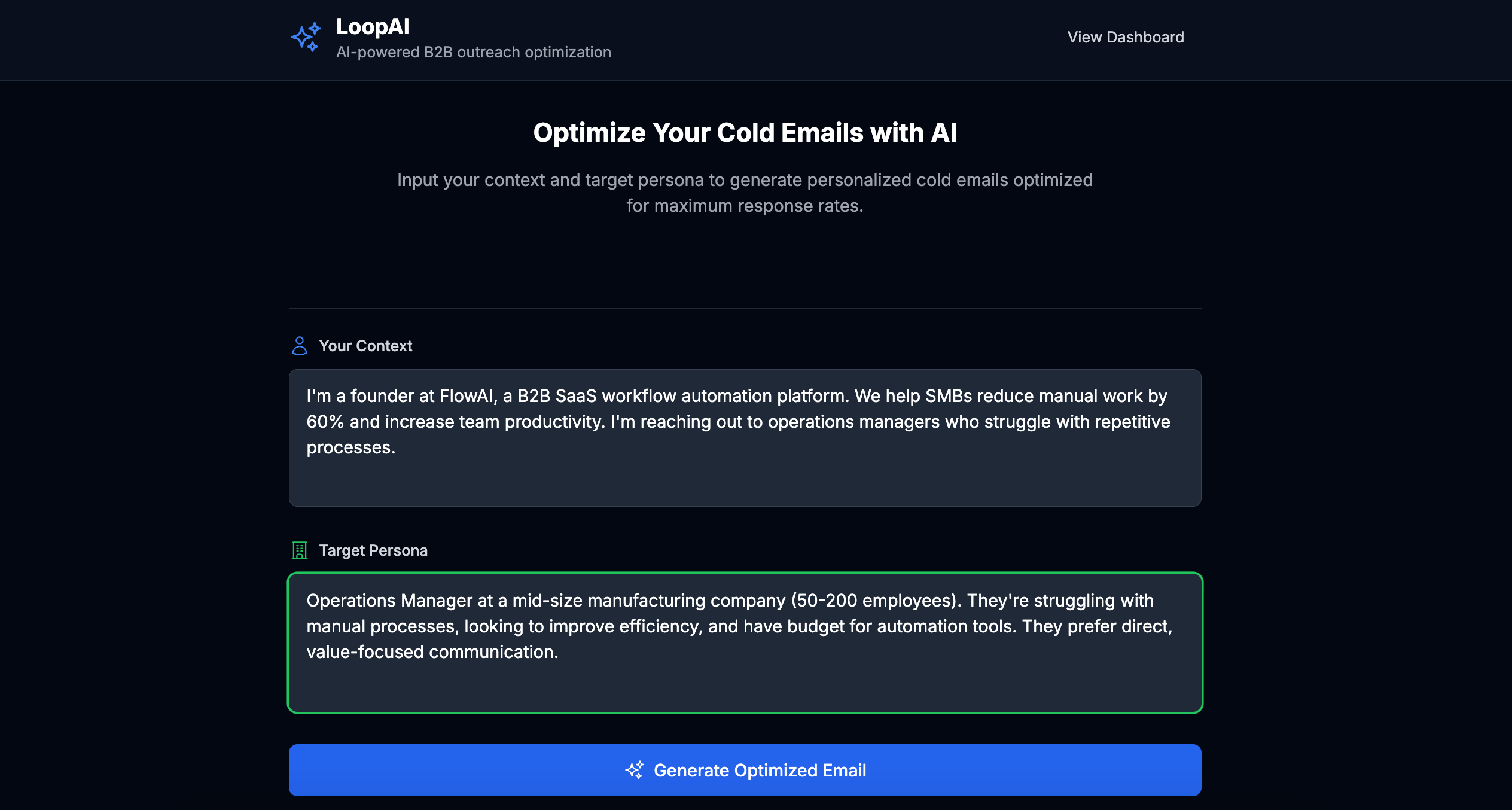
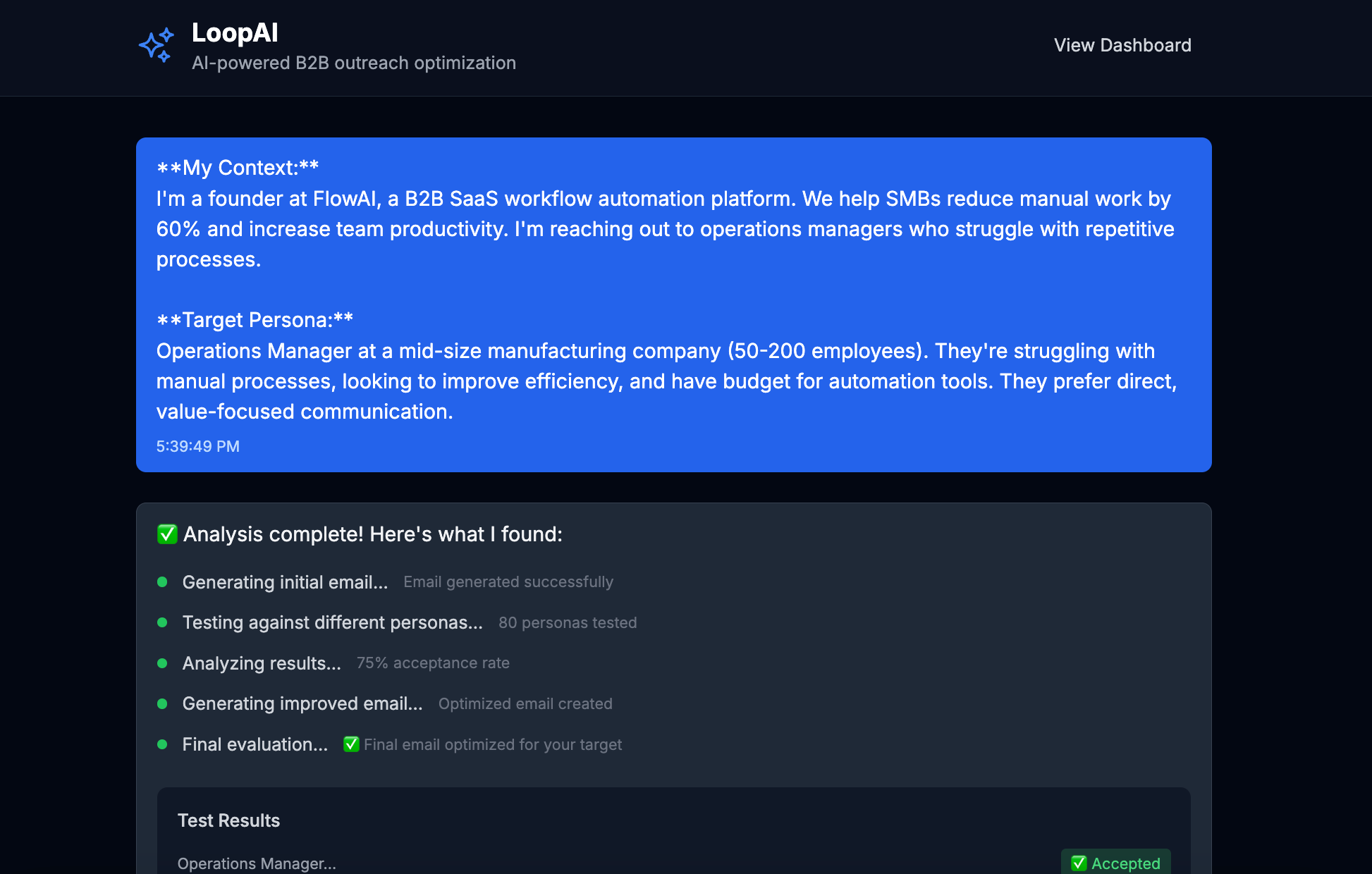
Our platform turns a plain-language problem statement into a production-ready language model, end-to-end. It automatically chooses a strong base model, crafts and refines prompts, fine-tunes on synthetic and real task data, and runs iterative self-evaluation loops until performance surpasses leading public LLMs on your specific task. Once optimized, we host the model behind a simple API and monitor quality and cost, so you get top-tier accuracy at a lower price with zero infrastructure or ML expertise required.
How we built it
We use synthetic data generation and LLM as a judge to create labeled data for the specific task. The key is that the LLM as judge doesn't even need to be 100% aligned with humans - using prompt-iterations, the model just needs to be able to identify potential issues in the model responses and how to remedy them. Additionally, with GRPO (reinforcement learning), our LLM as judge just needs to be able to output relative scores. With this, we can improve our model without expert labels, automating the entire process from problem statement to strong, specialized model.
Challenges we ran into
- How can we align the LLM as a judge to make sure it isn't overly strict or loose with its decisions?
- We couldn't finish fully fine-tuning a model with GRPO in the 6 hour time frame, however we're confident this will work as have been proven by other work.
Accomplishments that we're proud of
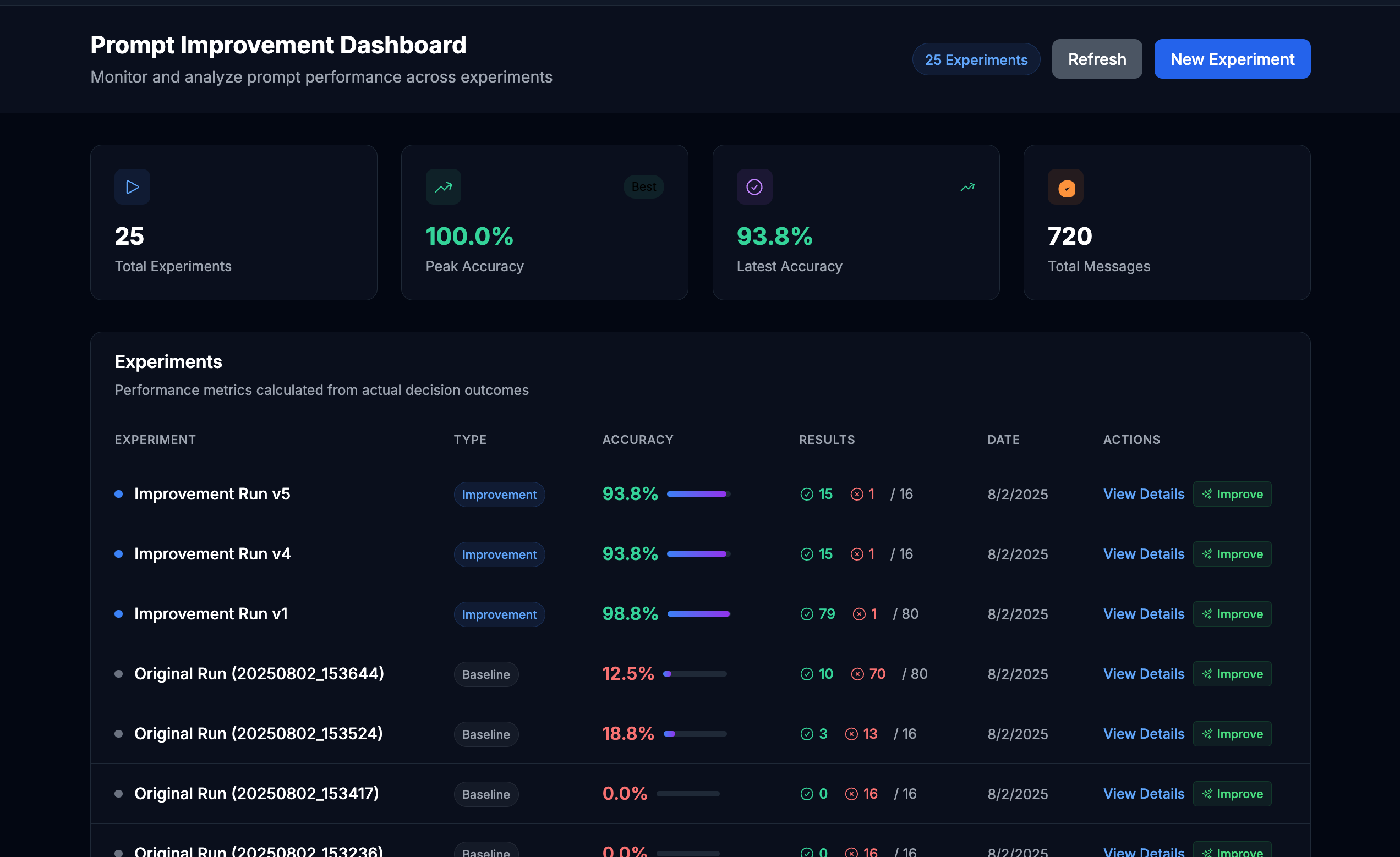
- Building a working system with no labeled data that took a cold email outreach agent from a 6% response rate to x% response rate.
- Aligning well on model training and prompt improvement techniques and end goal to build out this product in just 6 hours.
What we learned
- Simple prompt optimization leads to significant improvements. When you use a language model to analyze labeled data and see what mistakes the model is making, it's able to improve the prompts which leads to very real accuracy gains.
What's next for LoopAI
- Continuing to improve out model improvement workflow and making things completely automated.
Loom Video: https://www.loom.com/share/e9addd0cb6c44f0d96dbca733abd157b?sid=5382d066-323a-4117-98c4-eb229cab8004
Built With
- anthropic
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.