-
-
Website
Loomo: AI Screen Navigation Assistant
Demo Video
https://www.loom.com/share/4fd5657988ae4704ad998d796b6d7876
Inspiration
AI should help you learn how to do things, not just do them for you.
What It Does
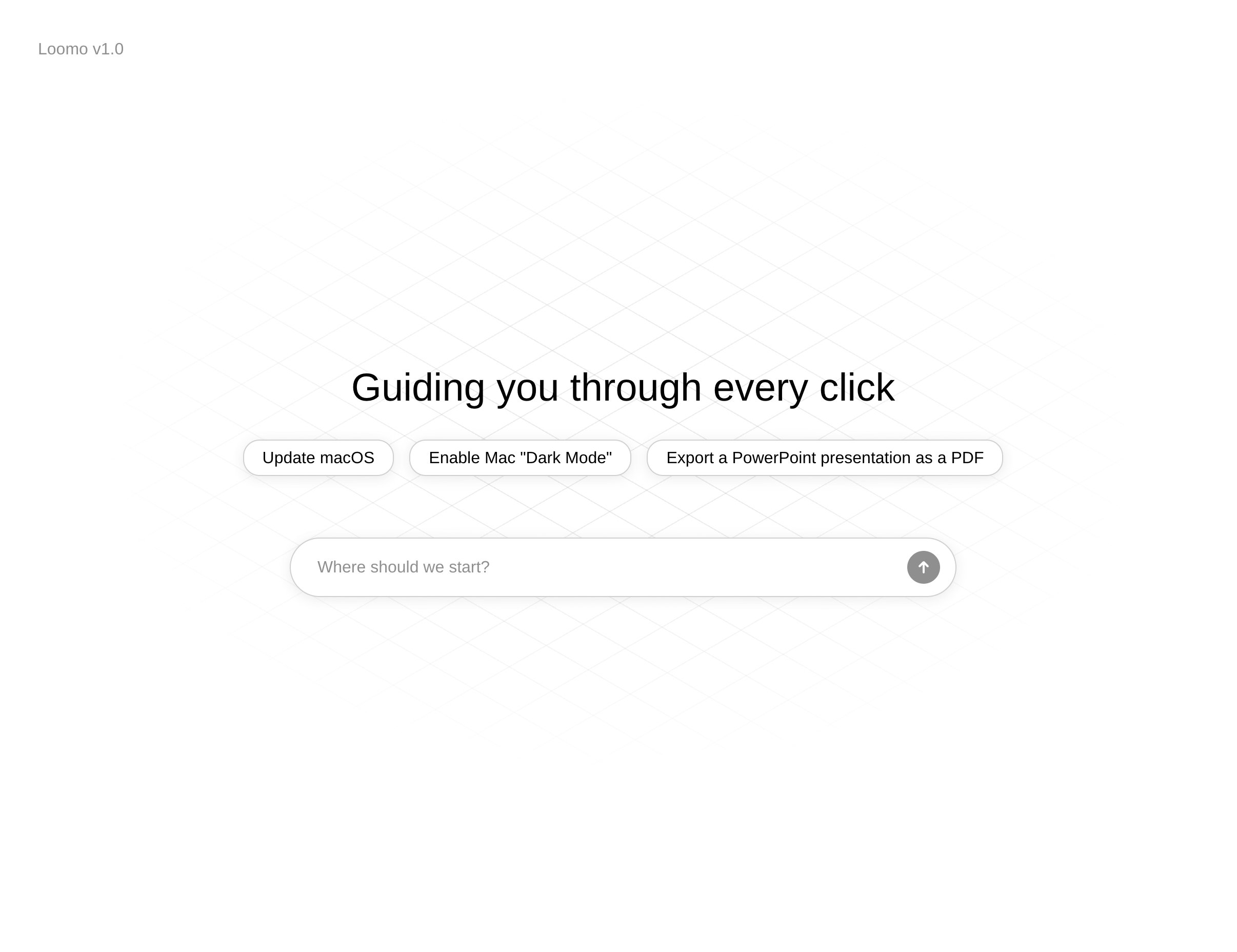
Loomo is an AI screen navigation assistant designed for people who aren't tech savvy. It guides users through computer tasks with step by step instructions displayed in a floating window alongside their screen.
How It Works
- The user describes their goal (e.g., "Update macOS").
- GPT-5.2 generates the first instruction without even seeing the screen.
- The user shares their screen via the browser API.
- Loomo displays specific, actionable instructions with visual guidance.
- The user completes each step and clicks "Done".
- AI captures a screenshot, verifies completion, and provides the next step.
- This process repeats until the task is complete.
Each instruction is precise: not “Go to System Settings,” but “Click the Apple menu icon in the top-left corner.” Previous steps collapse below the current one, creating a visual progress tracker.
How I Built It
The interface was designed in Figma with a clean, minimal style that wouldn’t intimidate non-technical users. The floating instruction window uses the Document Picture-in-Picture API to stay visible while users work.
Architecture
Loomo uses a three model AI architecture:
- GPT-5.2 – Primary reasoning engine that generates instructions.
- Gemini 3 Flash – Verifies step completion by comparing before-and-after screenshots.
- Qwen3-VL – Determines the exact coordinates of UI elements for visual guidance.
Each model works synchronously: GPT provides the “what”, Gemini confirms “did it happen?”, and Qwen specifies “where exactly.”
Built With
- canvas-api
- google-gemini-3-flash
- javascript
- openai-gpt-5.2
- openrouter-api
- picture-in-picture
- qwen3-vl
- react
- screen-capture-api
- vite
- zustand


Log in or sign up for Devpost to join the conversation.