
Inspiration
We kept hitting the same wall in every system we built: you can't safely ask "what if?" Want to test a different decision, a different event, a different past? You fork the data, replay everything, and pray it's deterministic. The realization that started Loom: a database isn't where you store the world after you compute it somewhere else — the database can be the world. If the world lives in the database, then "what if?" stops being a re-run and becomes a row you insert.
What it does
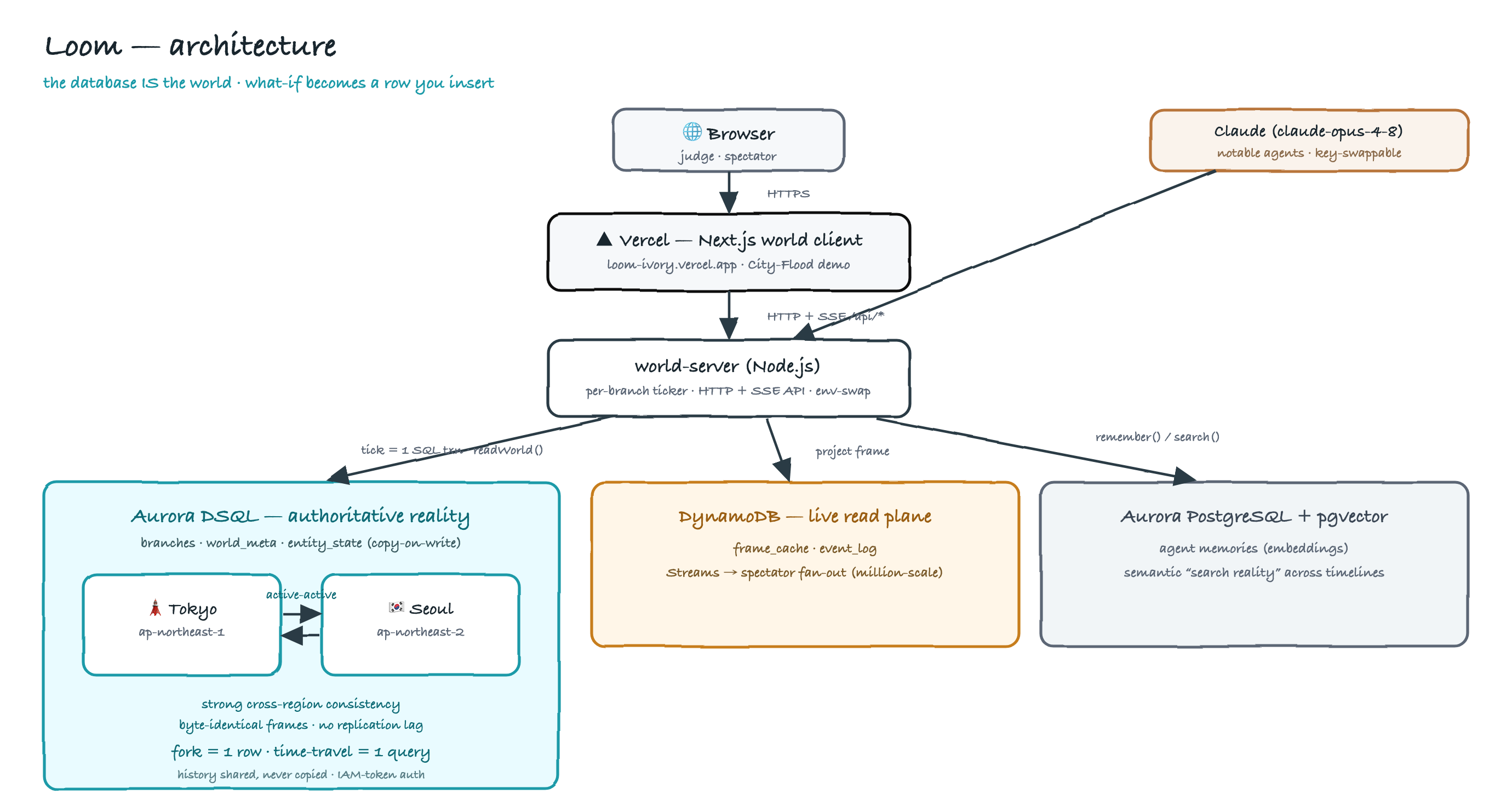
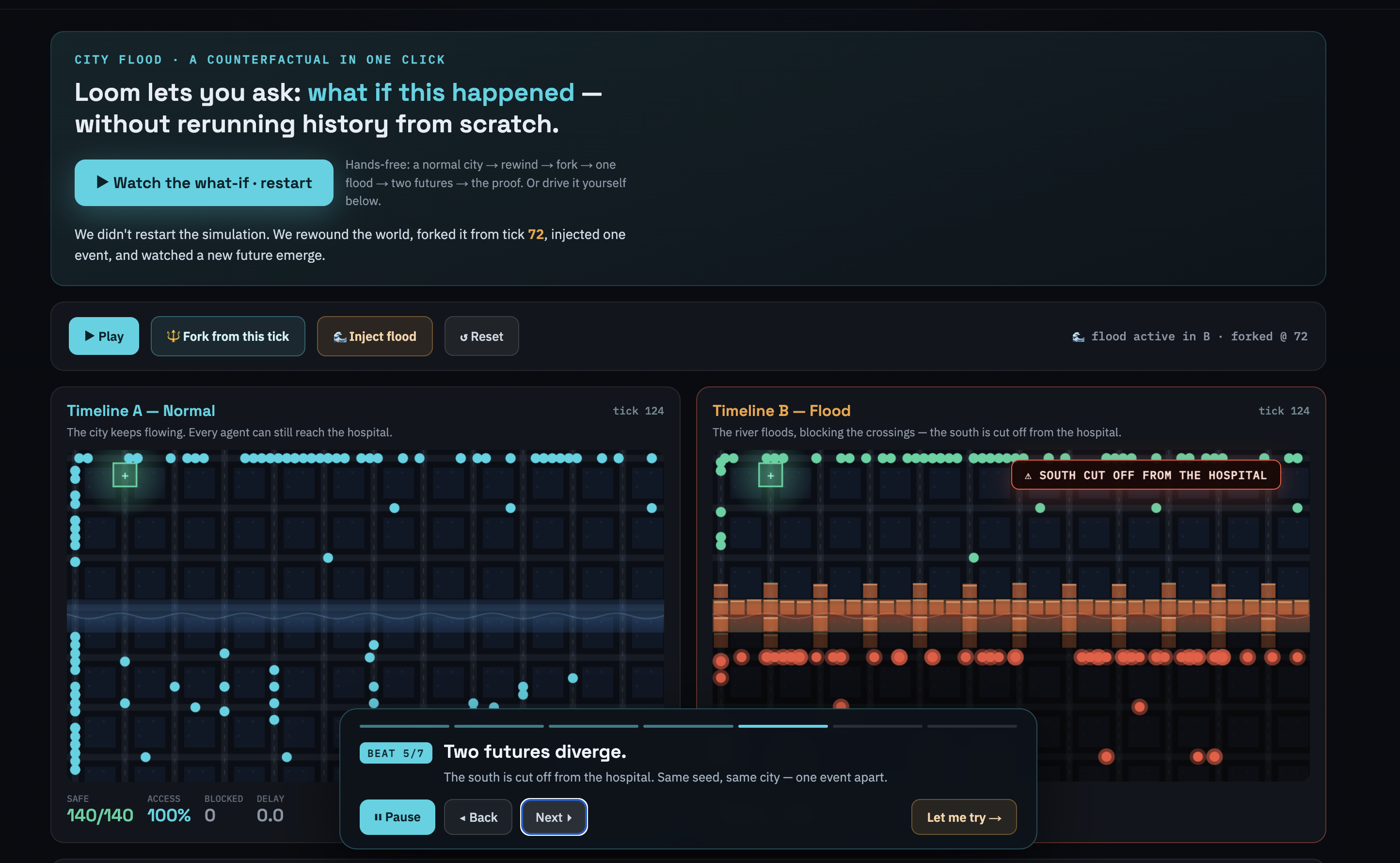
Loom runs a deterministic simulation whose entire authoritative reality lives in Aurora DSQL. Each tick is one SQL transaction. You can scrub to any past moment — that's just a read at a smaller tick. And you can fork the universe into a parallel timeline that shares all of its history and diverges only where you change something. The demo makes it concrete: a city of agents flowing to a hospital. Rewind, fork from an earlier moment, inject one flood, and watch Timeline B's south get cut off — resource access drops from 100% to 57% — while Timeline A is untouched. Two regions (Tokyo and Seoul) read the byte-identical world. We never reran history.
How we built it
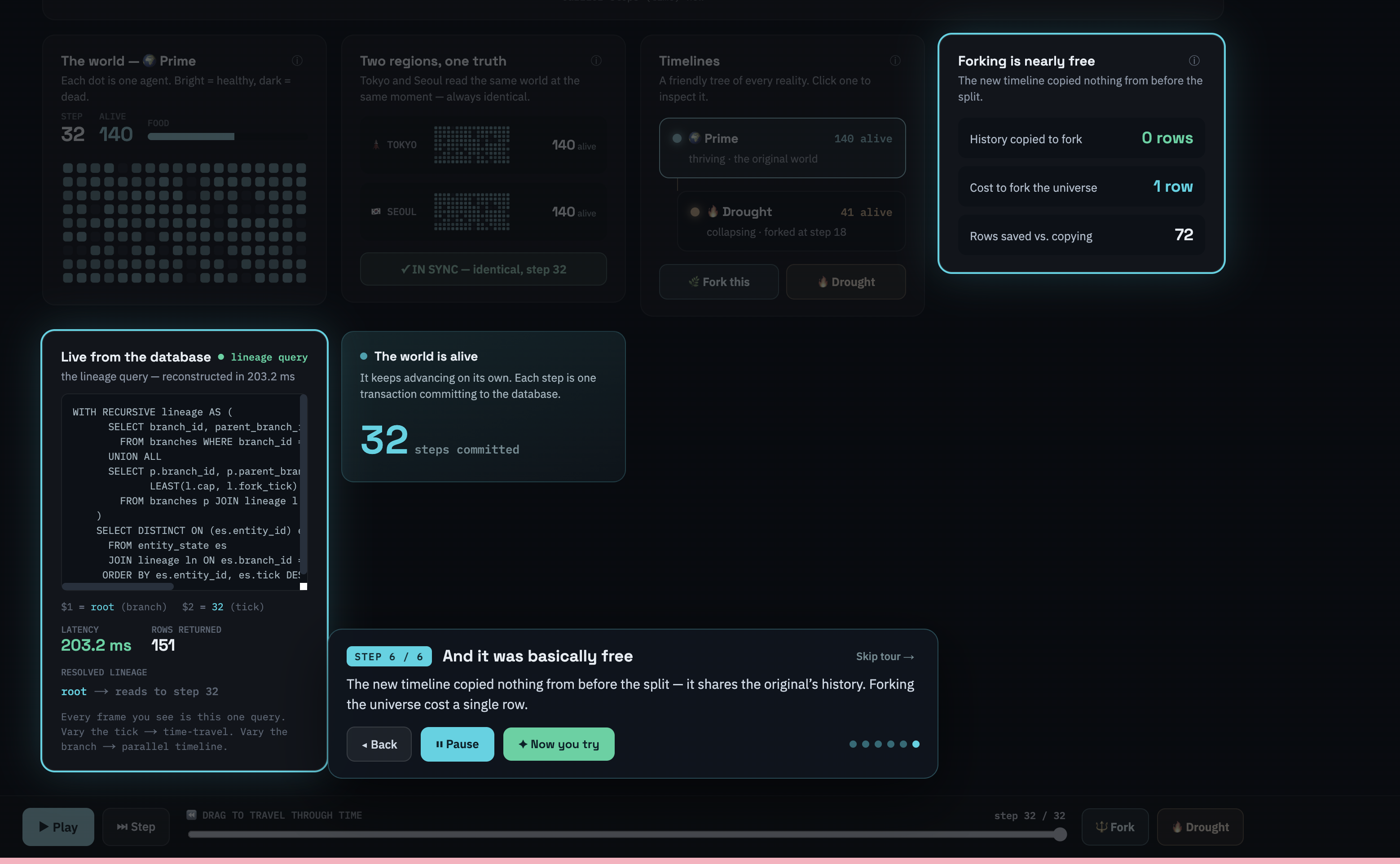
The core is a copy-on-write, branch-versioned table entity_state(branch_id, entity_id, tick, state) plus a tiny branches(branch_id, parent_branch_id, fork_tick) tree. The whole engine is one WITH RECURSIVE lineage query that walks a branch to its ancestors and caps each ancestor's contribution at the child's fork point — so the same query does both time-travel (vary the tick) and branching (vary the branch). Forking is a single INSERT. We ran it on a real multi-region Aurora DSQL cluster (Tokyo and Seoul, active-active, IAM-token auth). A DynamoDB read plane (frame_cache + event_log, Streams) is the spectator fan-out path; Aurora PostgreSQL + pgvector stores agent memories for semantic search. The frontend is Next.js + TypeScript on Vercel.
Challenges we ran into
DSQL is Postgres-wire-compatible but not Postgres. It rejects DESC in index keys, uses optimistic concurrency (commit conflicts are SQLSTATE 40001, not blocking locks), and caps transactions near 10k rows. The big one: reconstructing a frame after a long history got slow because every tick wrote a full frame. The fix was the unlock — write only the entities that changed each tick (copy-on-write within a branch). A stable 10,000-agent world then writes about 1 row per tick instead of 10,000, and reconstruction stays around 8 ms. Cross-Pacific latency from a laptop to DSQL was real, and we kept the numbers honest rather than hiding it.
Accomplishments that we're proud of
The proofs are real and reproducible from the repo. A forked timeline stores 0 rows before its fork tick yet reconstructs its parent's full history. With 10,000 agents: about 120 ms to seed, ~1 row/tick at steady state, any tick rebuilt in ~8 ms, and 110,079 rows hold two full 10,000-agent universes versus ~1.22M if materialized — 91% less. And Tokyo and Seoul return byte-identical frames, with a fork written in one region instantly visible in the other.
What we learned
Two things. First, copy-on-write within a branch — not just across forks — is what makes huge worlds and long histories cheap; divergence becomes the only thing that costs storage. Second, DSQL's strong cross-region consistency isn't a feature you bolt on — it is the product here: it's the only reason two continents can agree on a forkable, rewindable world with no replication-lag window.
What's next
Snapshots every K ticks to bound reconstruction on very long histories; promoting the "notable agent" decisions from a deterministic council to live Claude calls (already key-swappable); and the real applications this substrate enables — digital twins, scenario modeling, and backtesting where "what if?" is a row you insert.
Built With
- amazon-dynamodb
- amazon-web-services
- aurora-dsql
- aurora-postgresql
- next.js
- node.js
- pgvector
- postgresql
- react
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.