-
-
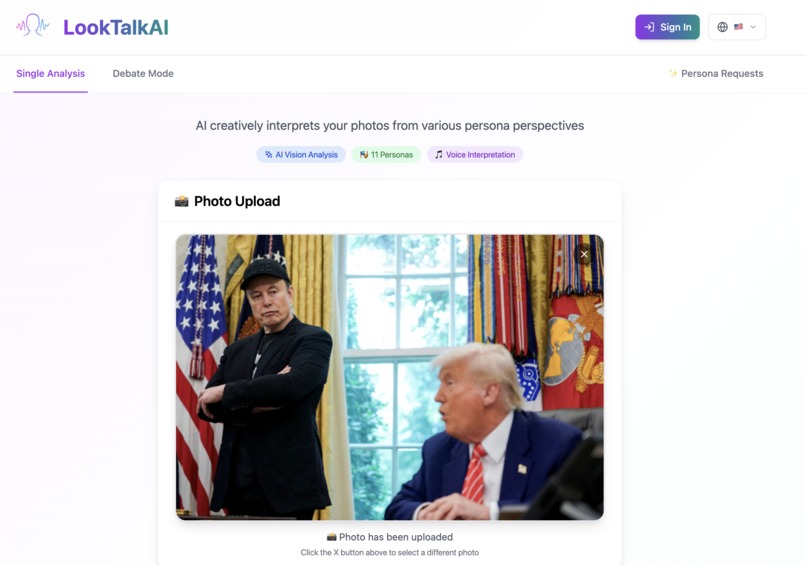
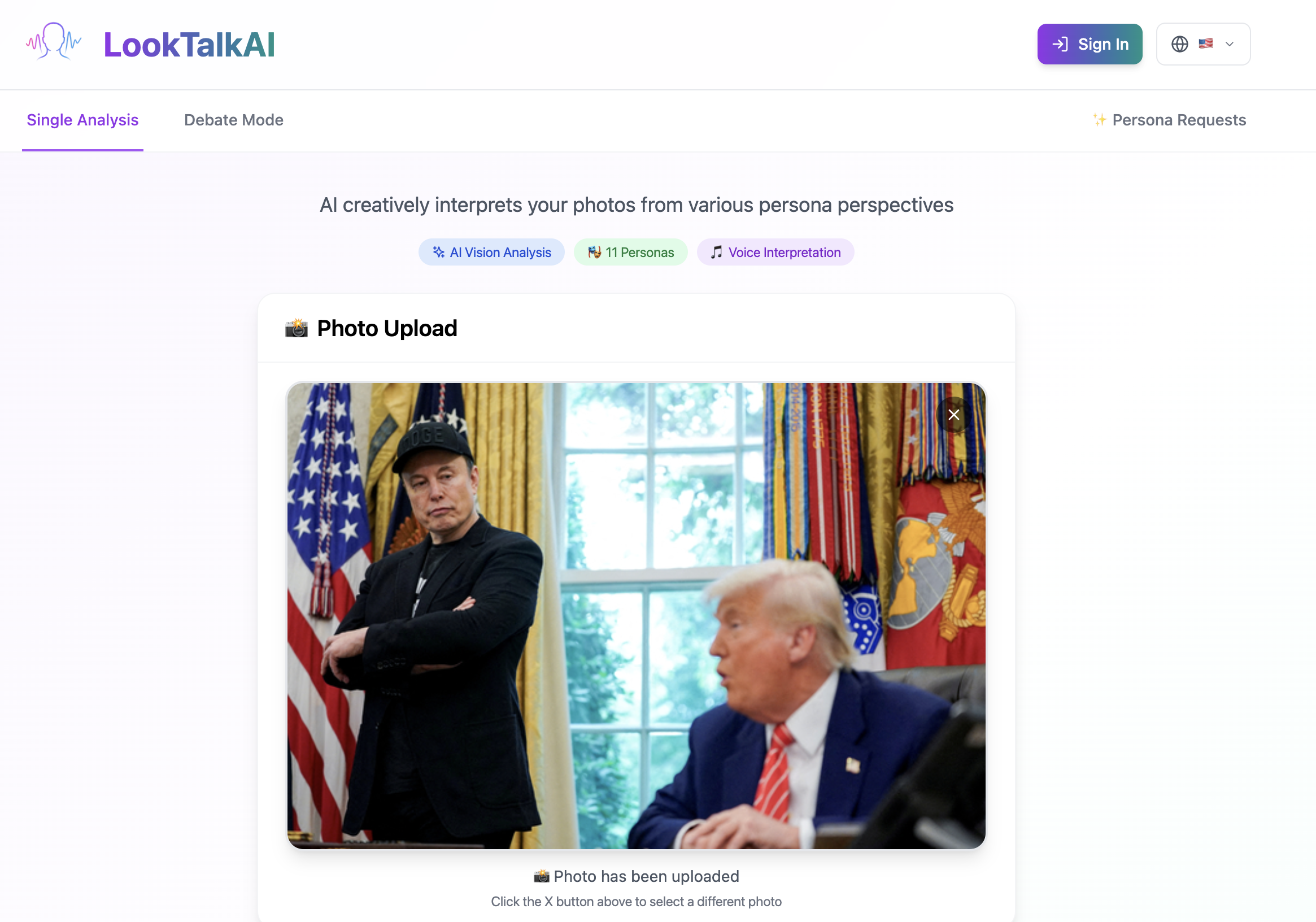
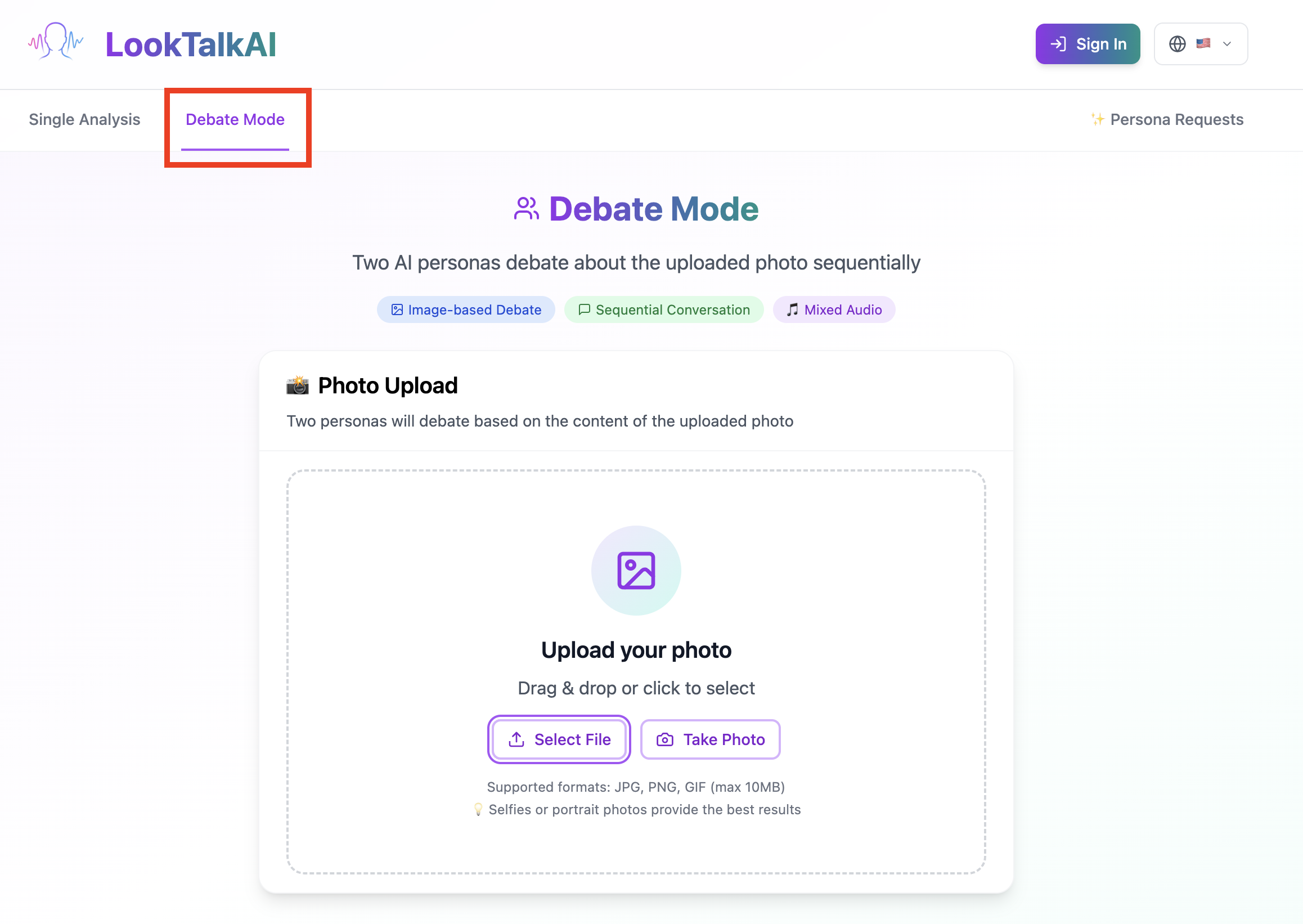
Upload photo
-
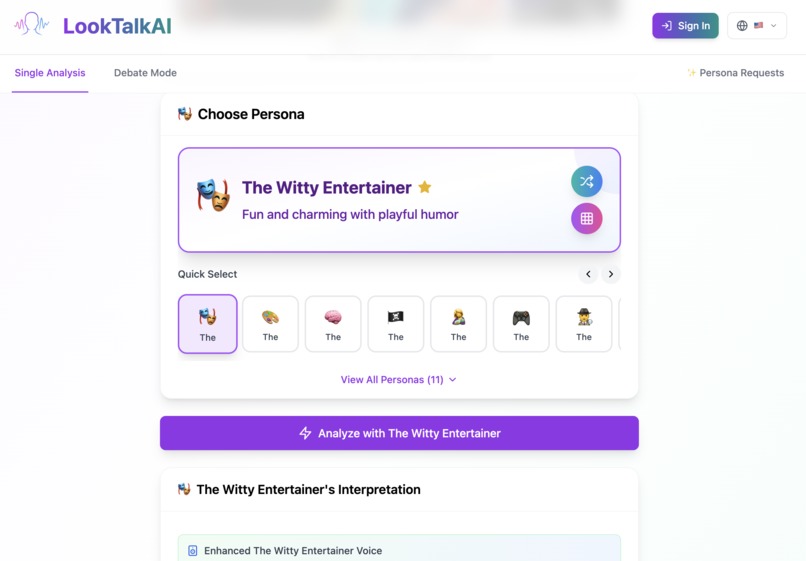
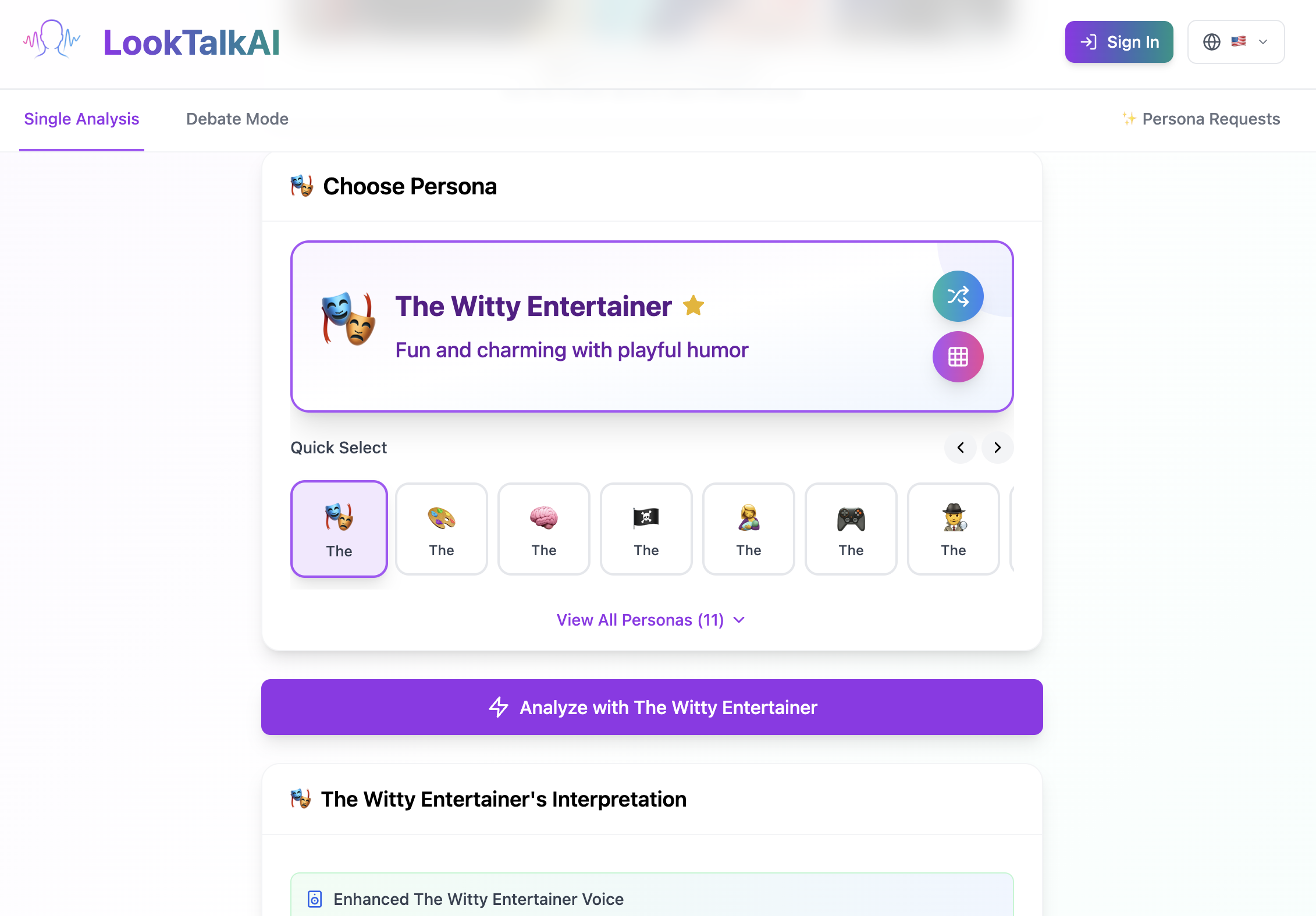
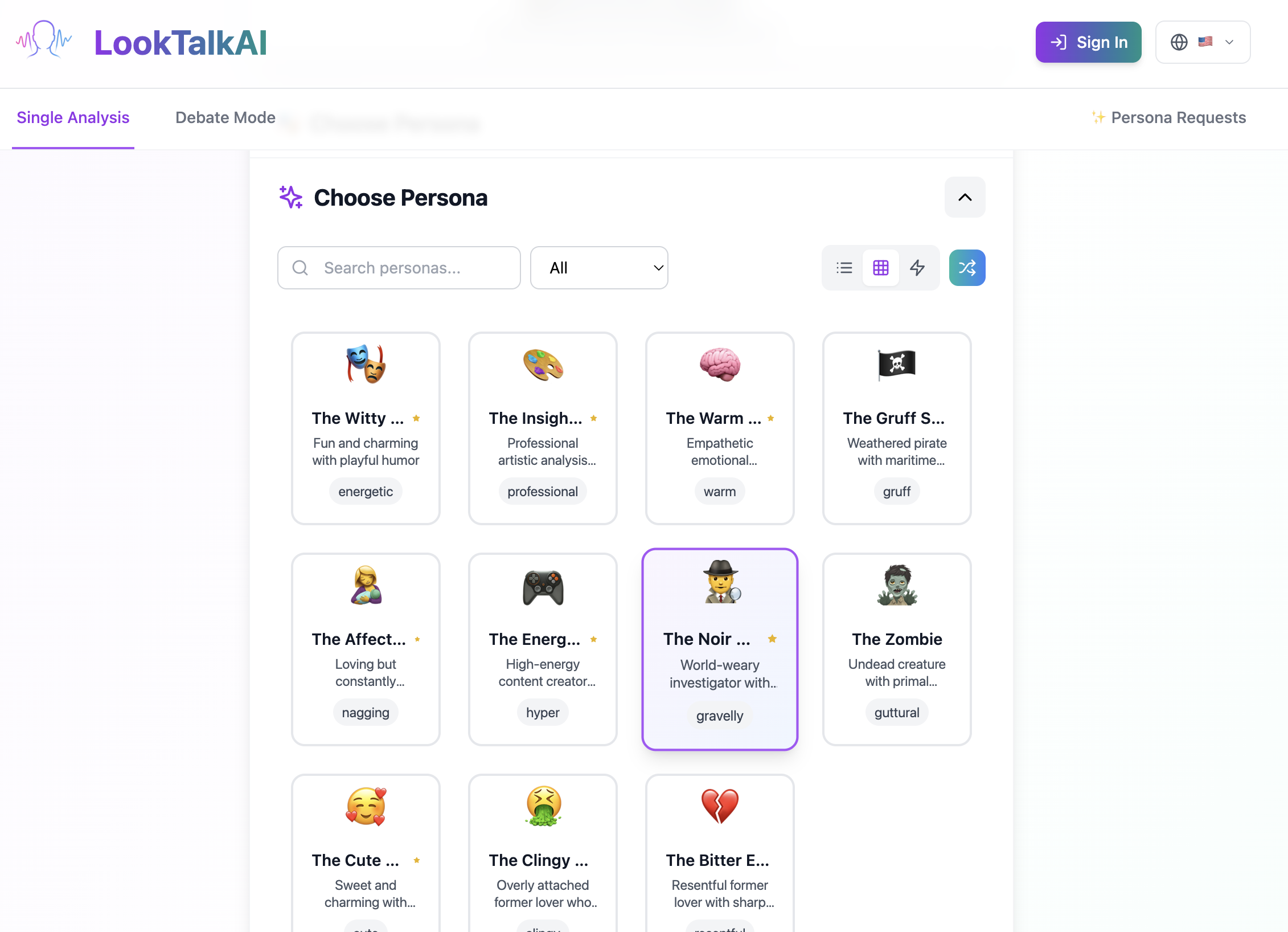
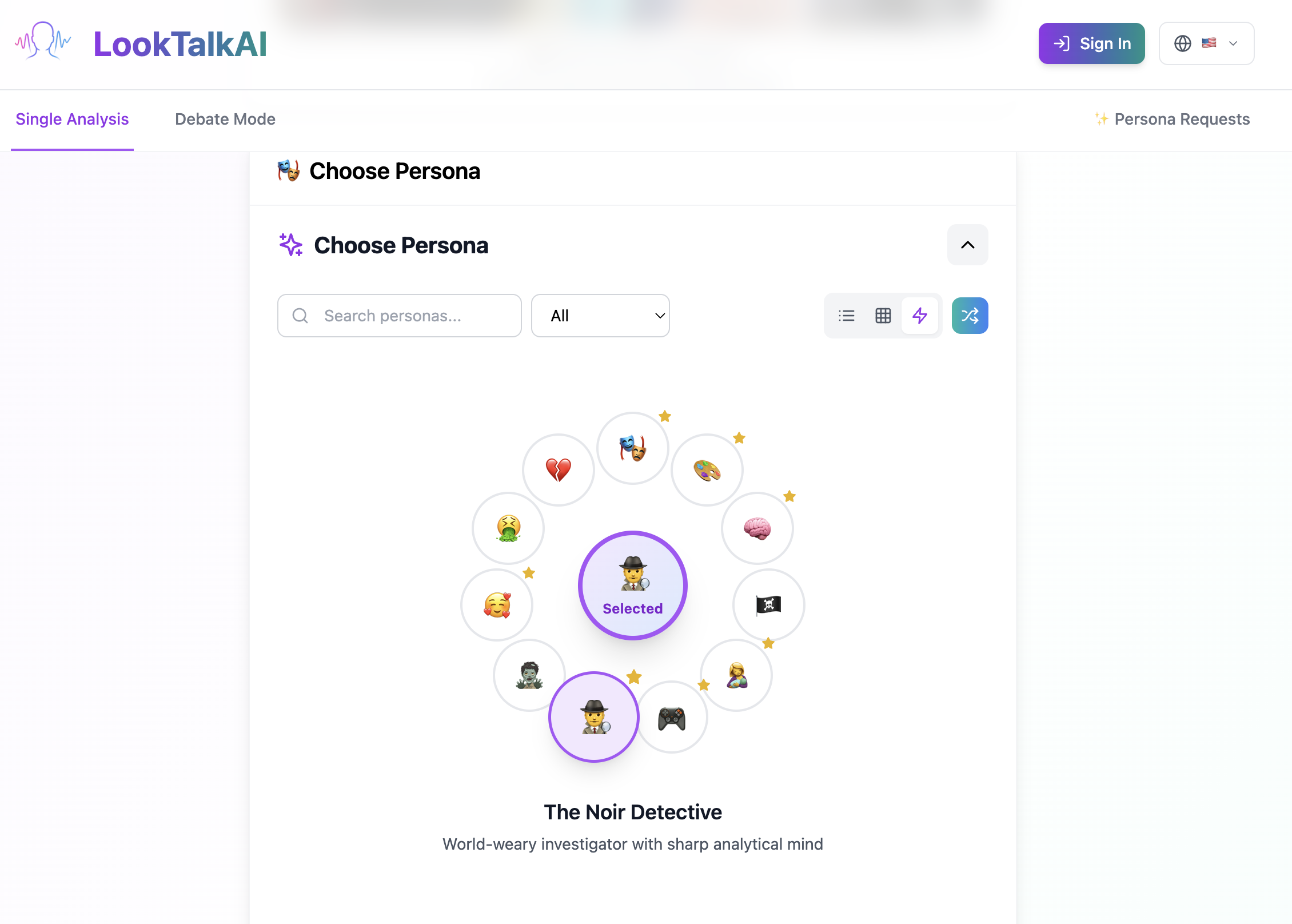
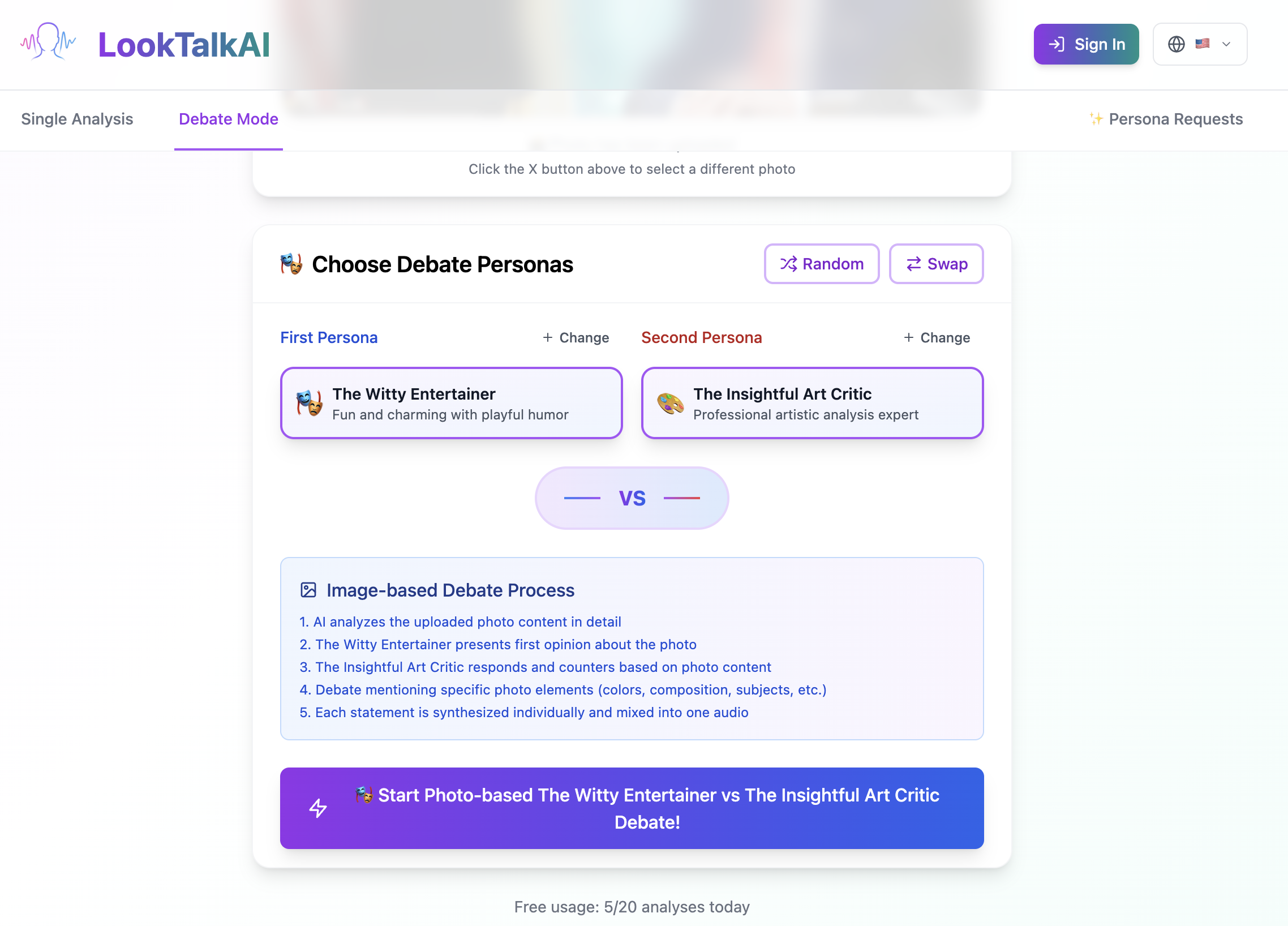
Choose Persona
-
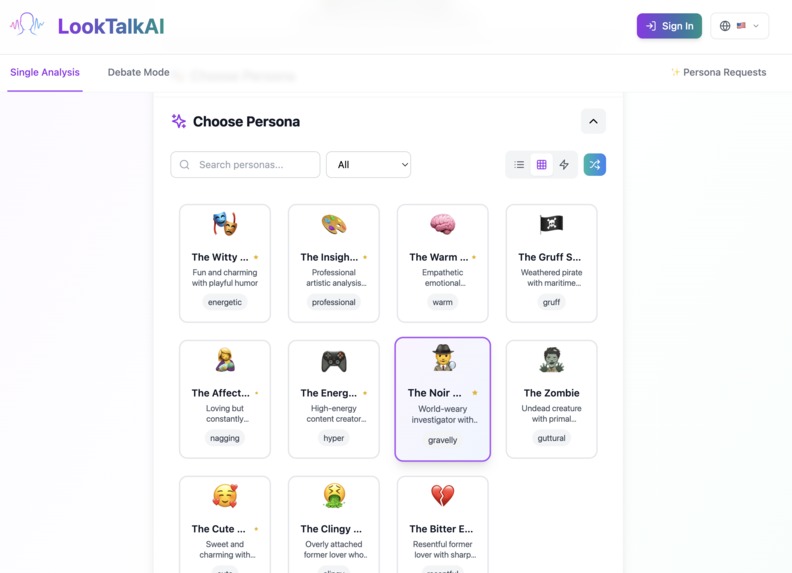
There are many interesting personas
-
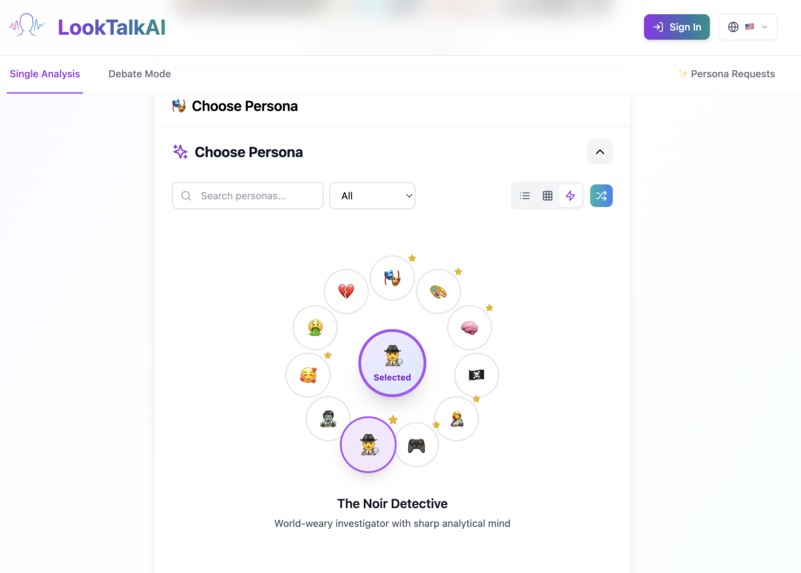
We can search and categorized personas
-
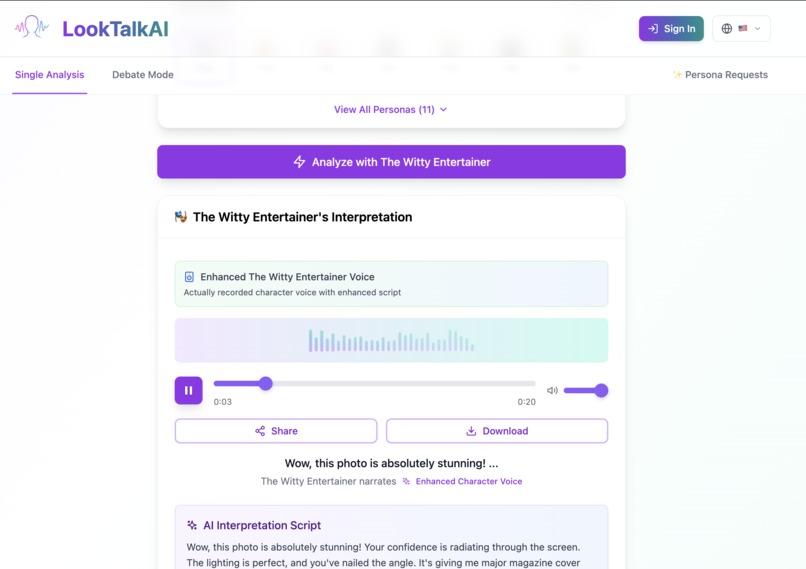
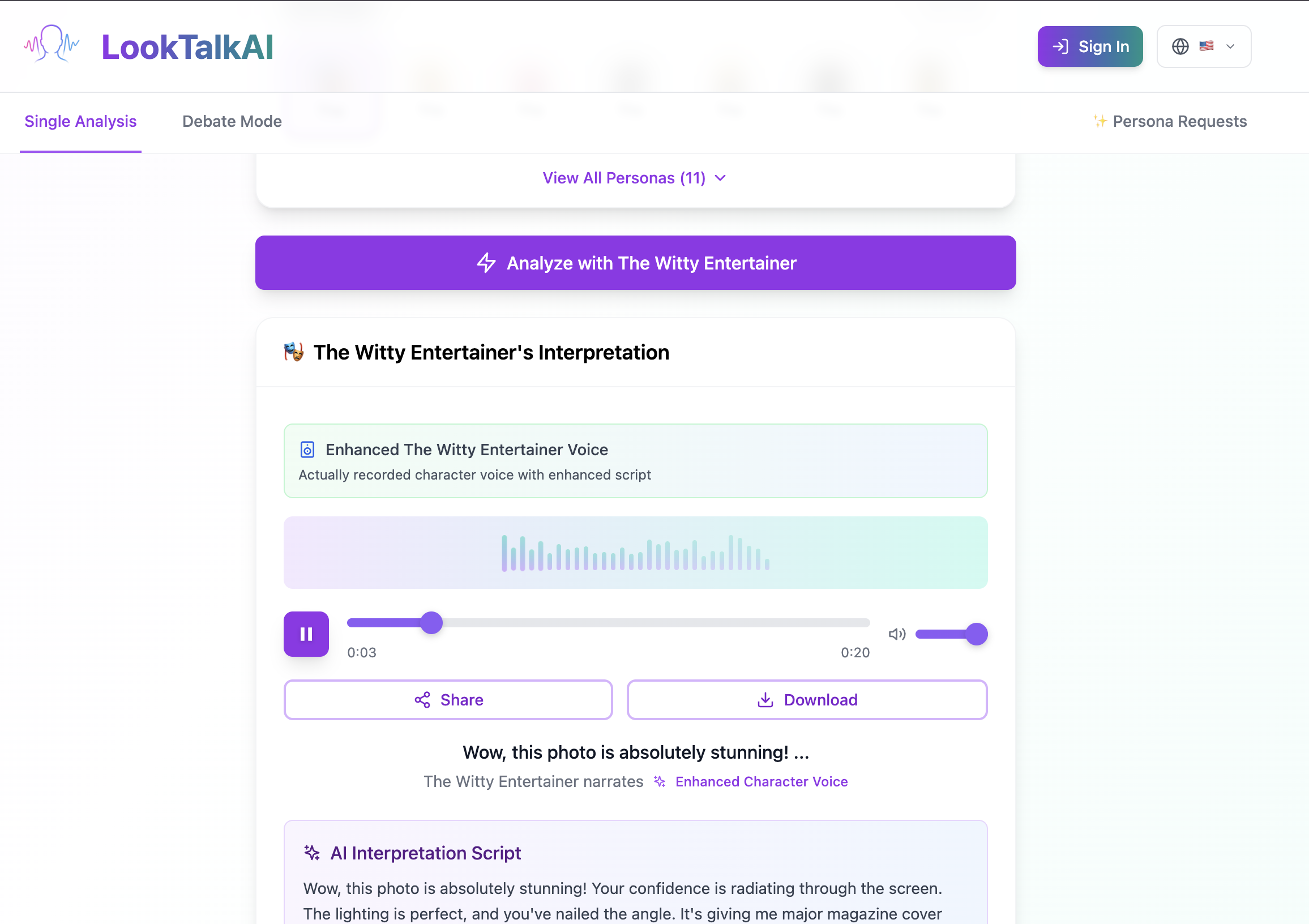
Making Audio
-
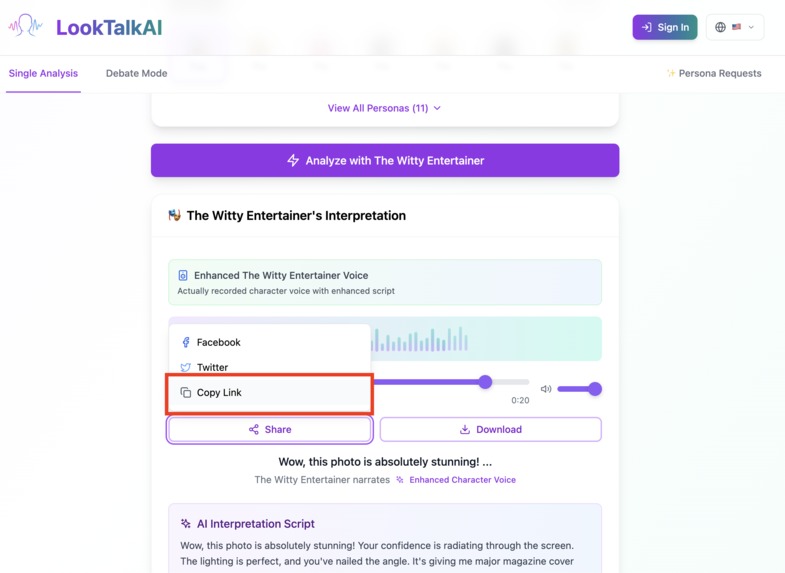
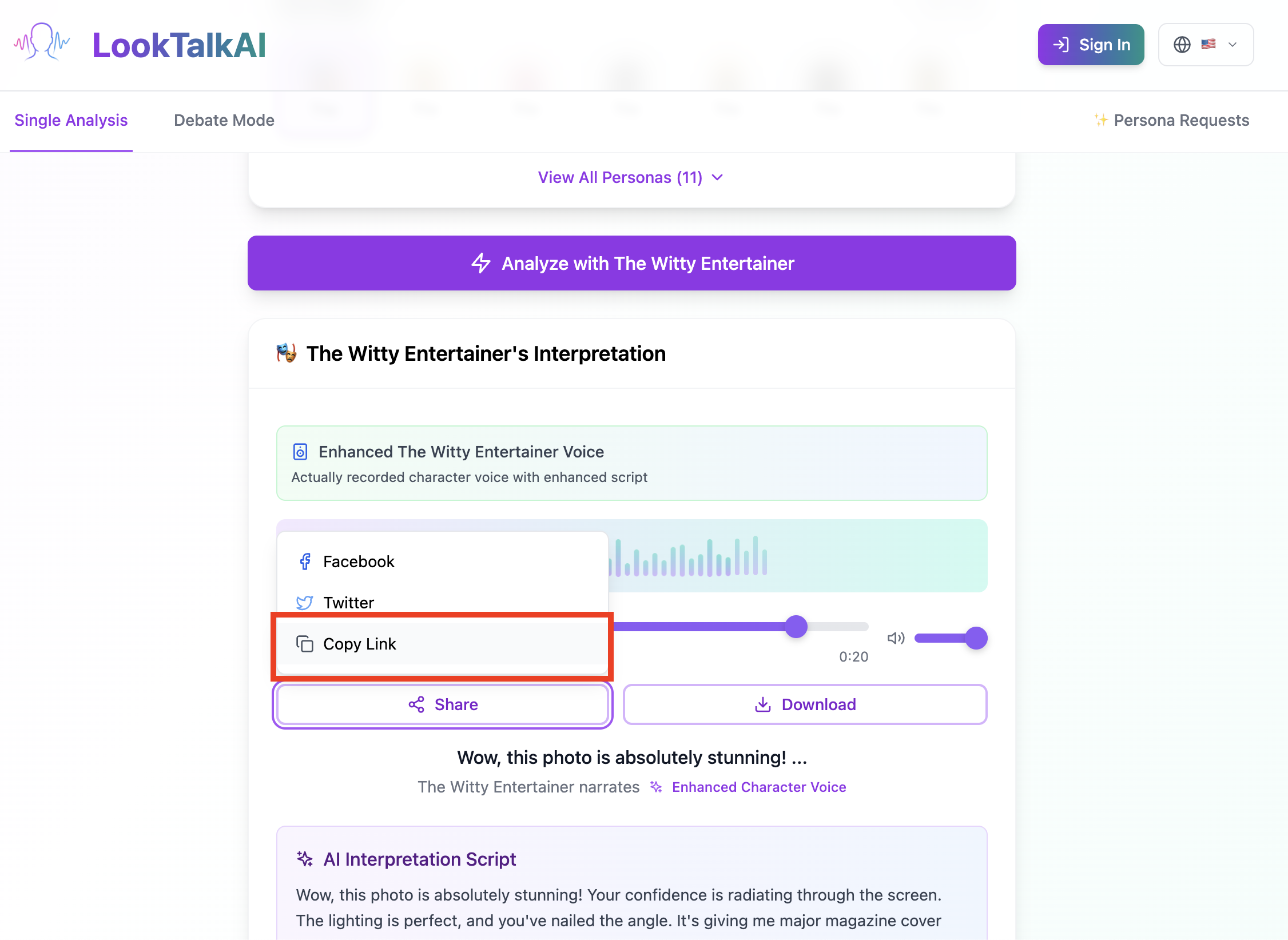
You can share result link to your friend
-
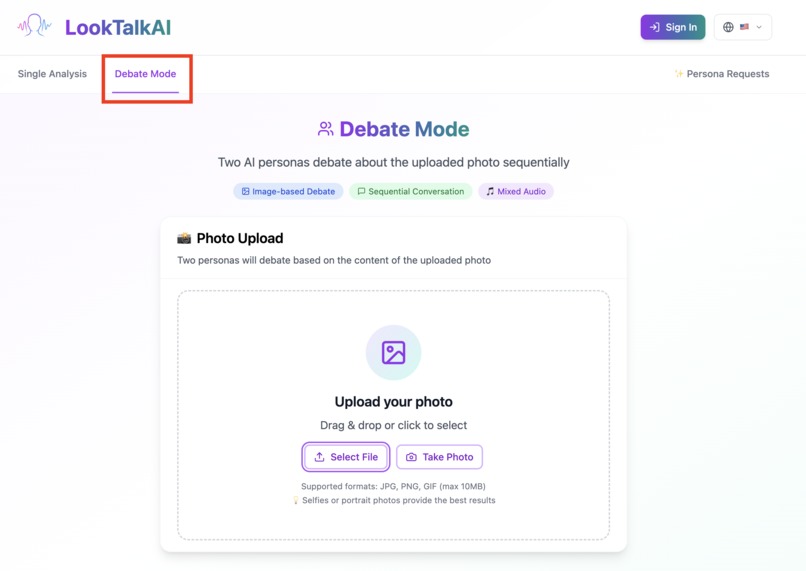
You can also select 'debate mode'
-
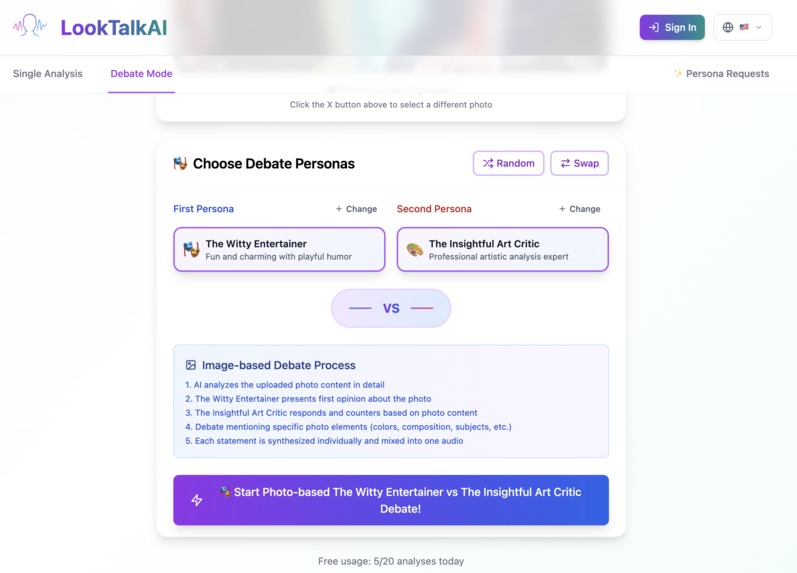
Choose two personas.
-
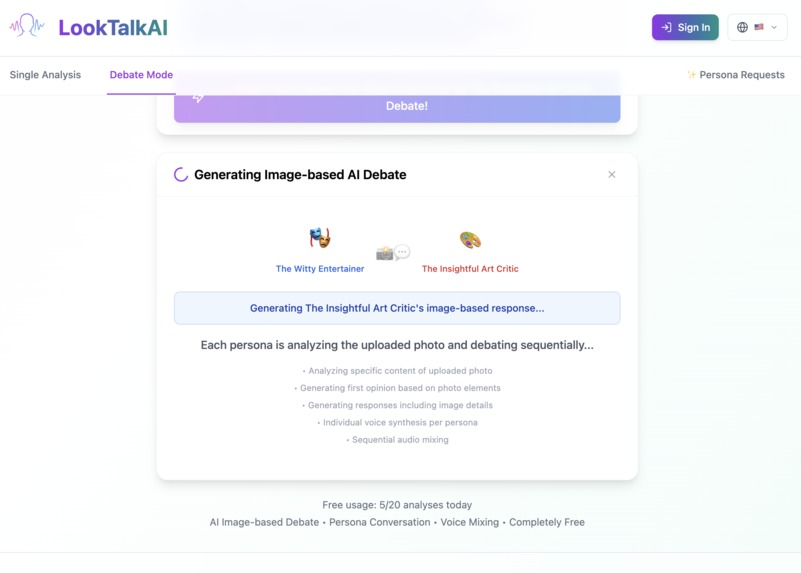
Making Audio
-
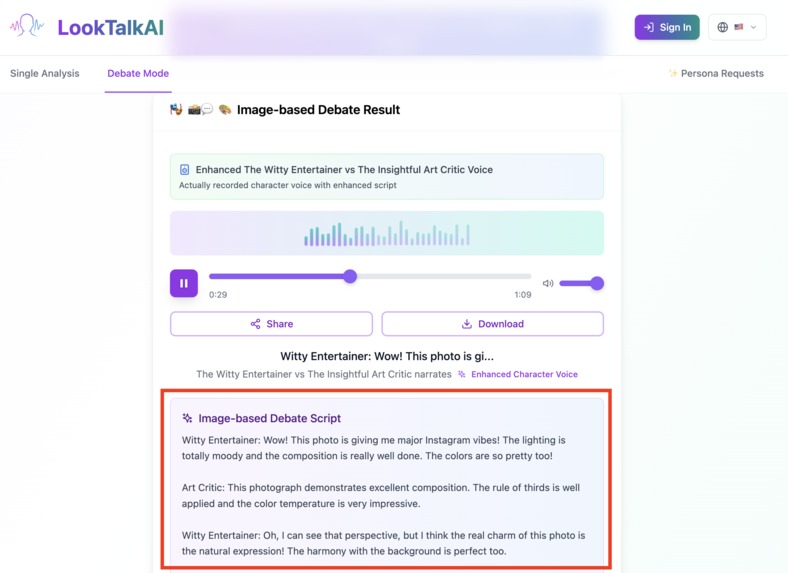
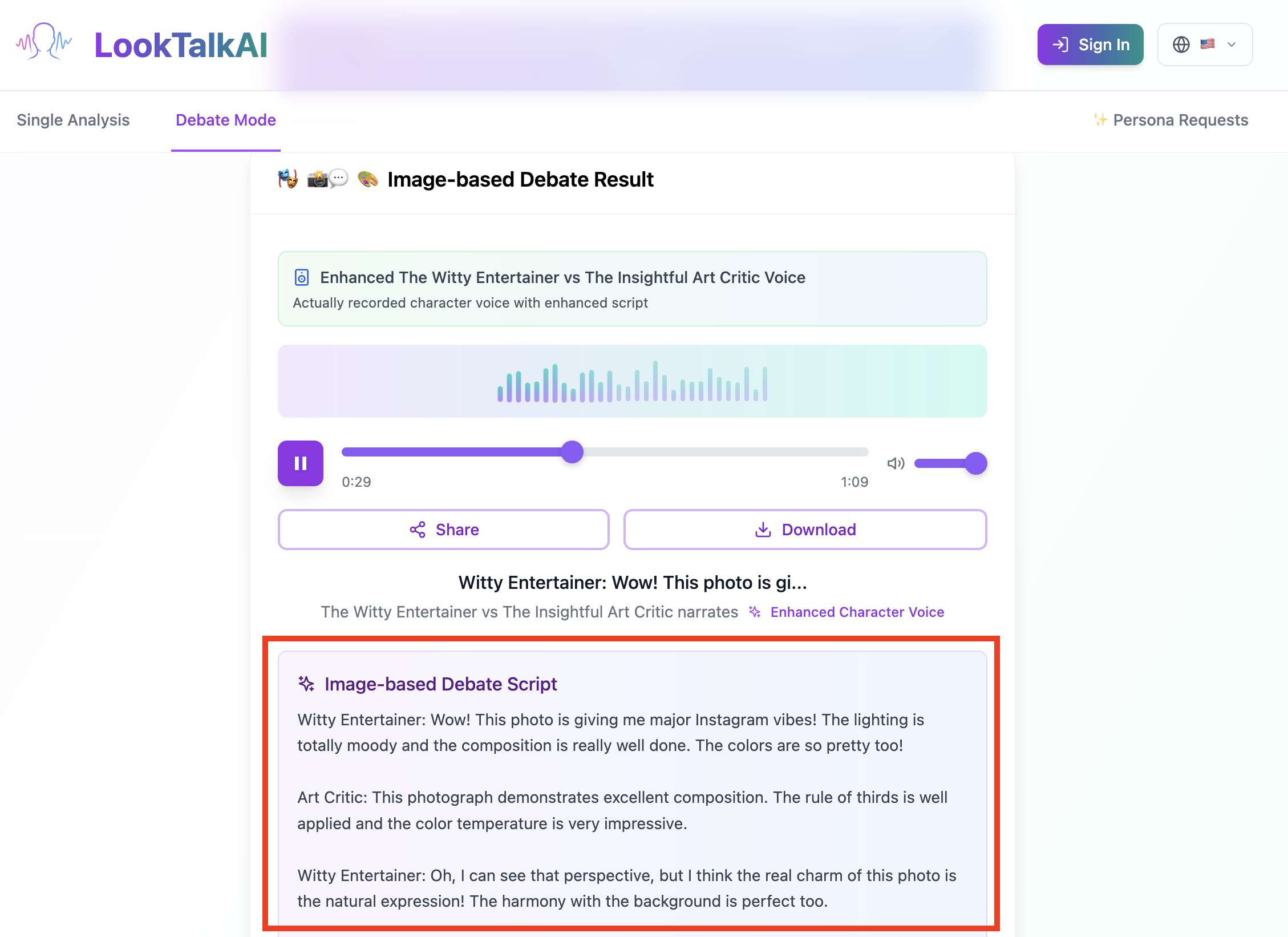
You can hear and read result script! So Funny.
Inspiration
We were inspired by a simple truth: a single picture can spark a thousand different conversations. While a photo itself is static, the stories and interpretations it holds are incredibly dynamic.
In a world saturated with silent images on social media, we wanted to capture the magic of a 'living conversation.' So we asked ourselves a question:
"What if our photos could do more than just talk? What if they could share stories from various perspectives, sometimes even sparking a debate, and bring it all to life in a vivid audio format?"
That very question was the seed from which LookTalkAI grew.
What it does
A user uploads any photo and then selects from a cast of unique and surprising AI personas. Forget boring analysts—you can choose characters like 'The Witty Entertainer,' 'The Energetic Streamer,' or even 'The Bitter Ex-Girlfriend.'
Our platform then generates a short audio clip where these chosen personas analyze, interpret, and converse about the image, all from their distinct—and often hilarious—points of view.
This one-of-a-kind audio story can be easily shared with friends via a simple link, turning an ordinary picture into a truly unique and fun social experience.
How we built it
LookTalkAI is built on a modern and efficient technology stack.
Frontend: The frontend is built on React.js with Vite, ensuring incredibly fast development and build speeds. We also implemented it as a PWA (Progressive Web App), allowing users to install it like a native app for a smooth and accessible experience.
Backend: We utilized Supabase for our backend and database. Its real-time database and built-in authentication features allowed for rapid and stable development without the need for complex server management.
Artificial Intelligence (AI):
- Dialogue Generation: For the core of our service—image analysis and dialogue generation—we chose Google's Gemini Flash model. It was the optimal choice when considering all aspects: fast response times, high accuracy, and cost-effectiveness.
- TTS (Text-to-Speech): To bring the personas to life, we used the Voice Design API from ElevenLabs. This enabled us to custom-design unique, one-of-a-kind voices that match each persona's personality, maximizing user immersion.
Challenges we ran into
Throughout the project, we faced several key technical and user experience (UX) challenges.
Stable Multi-Persona Audio Synthesis: Our biggest technical challenge was enabling multiple AI personas to converse naturally and then reliably synthesizing that entire conversation into a single audio file. We dedicated significant effort to optimizing the AI and TTS pipeline to ensure the different voices stitched together seamlessly without delays or errors.
Implementing a Polished PWA Experience: We aimed to transcend the limits of the web with PWA technology to offer native app-level accessibility. Precisely managing Service Workers and optimizing our caching strategy proved to be a complex task.
Designing an Intuitive UX for a Complex Flow: It was crucial to make the multi-step process feel effortless for the user. Hiding the underlying technical complexity required us to create numerous UI prototypes and conduct user testing to achieve the current streamlined flow.
Accomplishments that we're proud of
Creating a New Content Experience: Our proudest accomplishment is successfully proving our hypothesis: that a single, static photo can unlock infinite stories, fun, and at times, profound insight. We have created a new form of content that allows users to experience their own photos in a completely new way.
A Perfect Harmony of Tech and Experience: We are incredibly proud of integrating a complex AI pipeline into a user experience so intuitive that the user is completely unaware of the technology at work. From the moment an image is uploaded to the 'bolt-fast' generation of a vivid audio story, the entire process is designed to be simple and seamless.
What's next for LookTalkAI
The journey for LookTalkAI has just begun. Based on our current 'Image-to-Audio' technology, we have exciting plans to expand into more meaningful and broader domains.
Evolution into a Document Analysis AI: We plan to expand our capabilities beyond single photos to analyze complex documents like PPT presentations and PDFs, evolving LookTalkAI into an 'AI Analysis Assistant.'
Connecting to the Real World (Exhibition Docent): We are envisioning a 'personal audio docent' feature where a user can point their camera at an artwork in a museum, and our AI personas will provide commentary in real-time.
Ultimate Vision (Assistive AI for the Visually Impaired): Our most important long-term goal is to develop this technology into an Assistive AI for the visually impaired. We want LookTalkAI to become another pair of eyes that 'reads' and 'explains' the world, conveying visual information through voice. Through this, we hope to bridge the information gap and contribute to providing equal experiences for everyone.
Built With
- elevenlabs
- gemini
- javascript
- netlifty
- pwa
- react
- supabase
- typescript



Log in or sign up for Devpost to join the conversation.