-
-
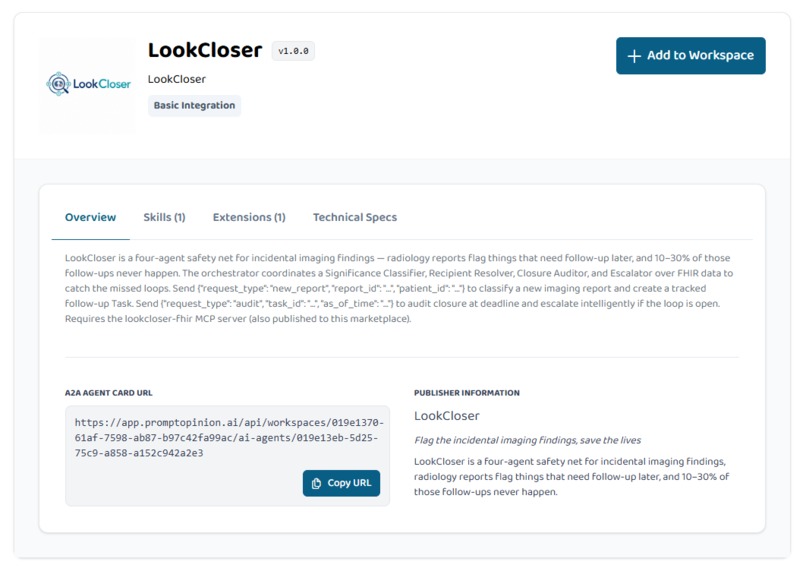
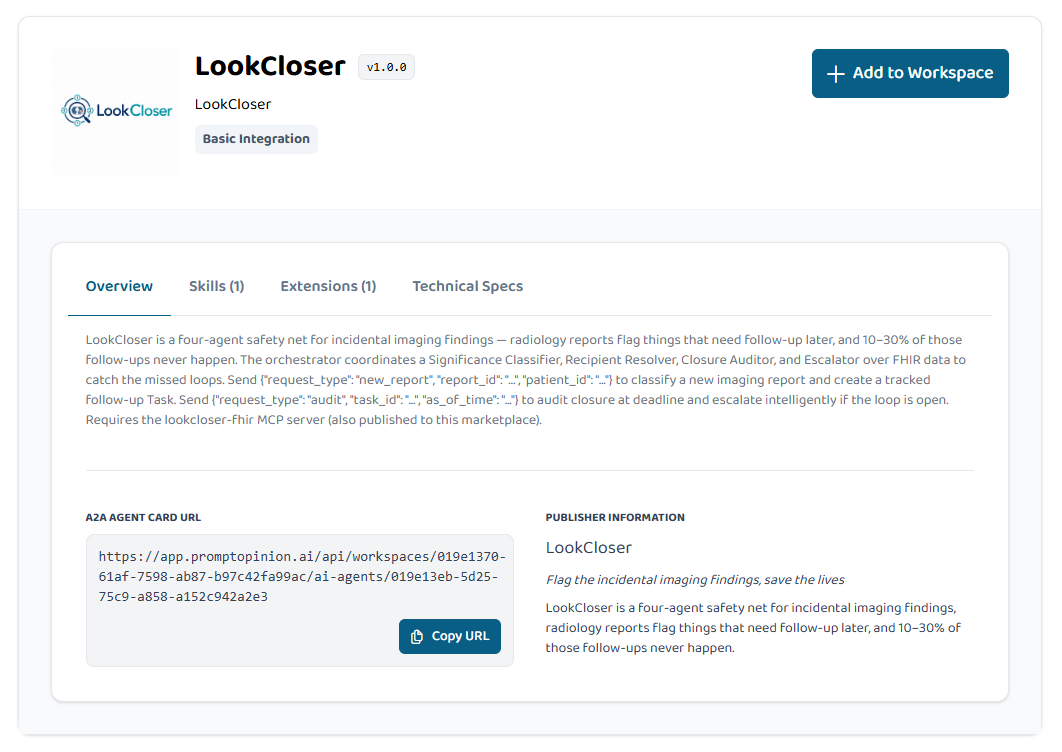
Marketplace A2A Listing
Inspiration
I work shifts in the emergency department. The pattern that won't leave my head: a patient comes in for one thing — a fall, chest pain, a kidney stone — and the imaging report quietly mentions something else. A 1.4 cm adrenal mass. A 6 mm pulmonary nodule. A complex renal cyst. The report ends with "recommend follow-up imaging in 3 to 6 months." The chart is filed. That is the last anyone thinks about it.
The Joint Commission has flagged closed-loop communication of test results among its top patient-safety priorities for years. ECRI lists it on its annual Top 10 Patient Safety Concerns. The published miss rate for incidental findings — depending on the study and the finding type — runs from 10% to 30%. Real cancers diagnosed late. Real malpractice settlements. The cause isn't negligence. The cause is that no clinician's job is to check whether the loop closed.
LookCloser is that someone.
What it does
Four AI agents coordinate to close the follow-up loop on incidental imaging findings:
- Significance Classifier reads new imaging reports as they're filed and identifies findings that need follow-up beyond the index encounter — distinguishing the splenic contusion that prompted the CT (being addressed) from the adrenal mass it incidentally found (not).
- Recipient Resolver decides which clinician on the patient's care team should own the follow-up, and creates a tracked
Taskin FHIR with a deadline and a structured recommendation. - Closure Auditor wakes up at the deadline, reads visit notes that have happened since the finding, checks the order trail, and reasons about whether the recommendation was actually addressed — not just whether an appointment happened.
- Escalator decides how to escalate when the audit finds an open loop. Crucially, it doesn't resend the alert that already failed; it reads the patient's upcoming visits and picks a more effective channel — attaching the recommendation to a planned ortho follow-up, CC'ing the original radiologist, escalating to leadership only when warranted.
All four agents share one MCP server that exposes the FHIR tools they need to read the chart and track tasks — the substrate, not the protagonist.
What this isn't, and what it pays attention to
Catching every incidental finding isn't unambiguously good. The literature on this is mature and uncomfortable:
- The cascade effect. A single 1.4 cm adrenal mass becomes a dedicated CT, then an MRI, then biochemical workup, then sometimes a biopsy or even adrenalectomy — for a lesion that, on the population level, is most often benign. Each downstream test carries its own radiation, cost, and procedural risk. The intervention can be more harmful than the condition.
- Psychological harm. Patients told "we found something, we'd like to image it again in three months" live with that sentence for three months. The anxiety is real, measurable, and sometimes worse than the finding deserves.
- Overdiagnosis and overtreatment. Many incidentalomas — small thyroid nodules, low-attenuation adrenal lesions, simple renal cysts, indeterminate pulmonary micronodules — are biologically indolent. Detecting them earlier doesn't change outcomes; it just creates more medicine.
- Clinical uncertainty. Guidelines exist for the well-studied finding types (Fleischner for pulmonary nodules, AACE/ESE for adrenal). For the long tail, the evidence is thin and clinicians reasonably disagree.
- Insurance and life implications. A documented finding — even if ultimately benign — can affect insurability, prior-authorization friction, and how future imaging is coded.
LookCloser doesn't escape these tradeoffs. It does try not to make them worse:
The system respects what the radiologist actually wrote. If the report says "likely benign cyst, no further imaging required," the Classifier doesn't flag it. The system doesn't substitute its own clinical threshold for the radiologist's. It operationalizes the recommendation that's already there.
The system closes loops silently when they're closed. The Auditor's most common output, in production, would be loop_closed — not an alert. Every silent closure is a notification the clinician didn't have to triage. The negative-control demo patient (Hari, with the properly-followed pulmonary nodule) exists to show this.
The system never contacts the patient. Anxiety is mediated by the clinician who chooses how and when to discuss findings. Bypassing that judgment would compound the harm the system claims to address.
The system draws the line at notification, not action. It surfaces a recommendation to a clinician with reasoning attached. It does not order tests, place referrals, or escalate to leadership autonomously. Every cascade decision remains a human decision.
What LookCloser cannot solve — and shouldn't pretend to — is whether the original recommendation was the right one. If a radiologist over-flags small adrenal lesions, LookCloser will faithfully track the loop on a workup that arguably shouldn't have been recommended. The real answer to overdiagnosis lives upstream, in the radiology guidance itself; downstream tools like this one inherit the upstream calibration. We can be honest about that.
What I learned
Most healthcare AI demos use the LLM for one thing — generating a letter, classifying a record, summarizing notes. The multi-agent framing is often theatrical: one agent in a trench coat. LookCloser is genuinely multi-shape because each agent operates on different data and at different times. The Classifier reads radiology prose the moment a report is filed. The Auditor reads visit-note prose four weeks later. The Escalator reads scheduling data the instant the audit comes back open. They can't be collapsed into one agent because they don't run at the same time — and that temporal separation is the whole point.
That insight shaped the architecture. It also gave me two visible AI-Factor moments — the Classifier reasoning about what's incidental, and the Auditor reasoning about whether a visit note actually addressed the recommendation. Two load-bearing reasoning steps make the narrative stronger than any single agent's would.
How I built it
The four agents are configured on Prompt Opinion as BYO Agents with A2A enabled and FHIR Context Extension required. Each has a system prompt specifying its clinical reasoning, decision rules, and structured JSON output discipline; each exposes a single skill (classify_imaging_report, resolve_followup_recipient, audit_followup_closure, choose_escalation_channel) so the orchestrator can dispatch correctly. An Orchestrator Agent links all four and chains the two workflow shapes — new_report (Classifier → Resolver) and audit (Auditor → Escalator if open). No agent-layer code; the platform handles A2A routing, SHARP context propagation, and the clinician-facing UI. That's the platform's value proposition, and it held up under deadline pressure.
The agents share one MCP server — lookcloser-fhir, written in Python 3.11 using FastMCP over HAPI FHIR R4 with async httpx and pydantic v2 for validation. Nine tools, deliberately granular: fhir_get_patient_summary, fhir_get_diagnostic_report (with full body text), fhir_search_diagnostic_reports, fhir_get_care_team, fhir_search_service_requests, fhir_search_clinical_notes, fhir_search_encounters, and three Task operations (create, search, update_status). The relevance reasoning lives in the agent prompts; the MCP just returns clean FHIR data with provenance.
Two synthetic patients are seeded as FHIR transaction Bundles for the demo: a 58-year-old post-fall patient with a 1.4 cm adrenal incidentaloma in her CT abdomen report (the open-loop case), and a 62-year-old with a properly-followed pulmonary nodule (the negative-control case demonstrating the system isn't alarmist).
Challenges I ran into
Tightening structured outputs across four agents. Each agent in the chain emits JSON that the next agent consumes — finding_detected flowing into followup_task, audit_result flowing into escalation_directive. Early prompt drafts produced JSON that was almost valid but slipped on edge cases: a missing required field when a report had no explicit recommendation window, free-text caveats leaking outside the JSON envelope, citations occasionally formatted as prose instead of structured arrays. The fix was structural — every agent prompt now ends with an explicit "Output discipline" section that pins the schema and includes a worked example, and the schemas tolerate optional fields rather than requiring everything. The platform's A2A routing then runs without retry loops.
Round-tripping structured data through FHIR Task resources. The Classifier's structured recommendation needs to survive the gap between Resolver creating the Task and Auditor reading it weeks later. I considered three options: storing it in Task.description, in Task.input parameters, or in a custom extension. The extension path won — Task.input requires per-parameter valueX typing that adds friction, and Task.description is meant to be human-readable. A single string-encoded JSON in an extension at a documented namespace URL is clean to write, clean to parse, and standards-compliant.
Decoding heterogeneous FHIR storage. HAPI's public sandbox accepts almost anything and returns it the way it received it. Radiology report bodies might live in presentedForm (base64-encoded attachment), text.div (XHTML narrative), or conclusion (plain string). I built a fallback chain so the Classifier's tool always returns clean text regardless of which path the report originally came in through.
What's next
The architecture is intentionally extensible. The Significance Classifier in this demo handles abdominal incidentalomas, but anyone could publish a domain-specific Classifier — pulmonary, hepatic, breast, thyroid — to the marketplace, and it would slot into the same Resolver/Auditor/Escalator chain without anyone touching the rest of the network. Same logic for an Auditor specialized for chronic-disease panels rather than incidental findings. The Superpower (the MCP) and the workflow shape are reusable; the clinical domain is configurable.
The honest production path runs through real EHR integration rather than the sandbox; through a clinical-leadership-validated deployment with an actual safety officer in the escalation chain; and through prospective measurement of whether the loops actually close more often.
Built With
- a2a
- agent-to-agent
- anthropic-claude
- anyio
- claude-code
- fastmcp
- fhir-r4
- hapi-fhir
- hatchling
- hl7-fhir
- httpx
- mcp
- model-context-protocol
- prompt-opinion
- pydantic
- pytest
- python











Log in or sign up for Devpost to join the conversation.