Inspiration
Have you ever signed up for a newsletter or an opportunity notification and gotten bombarded with an insane amount of notifications, most of which weren’t even relevant to you? That’s the experience that started this project. Every alert tool we’ve ever used, from Google Alerts to keyword bots to price trackers, is built to notify you about everything, because more notifications means more engagement for whoever built them. None of them are actually built to find the right fit for you specifically. We kept hitting this same wall across every version of our idea (scholarships, social media, events) and realized the domain was never the problem; the bombardment was. So we built Lookout to solve it directly: an agent that stays on continuously and notifies you only when it finds the best fit, not everything that merely matches.
What it does
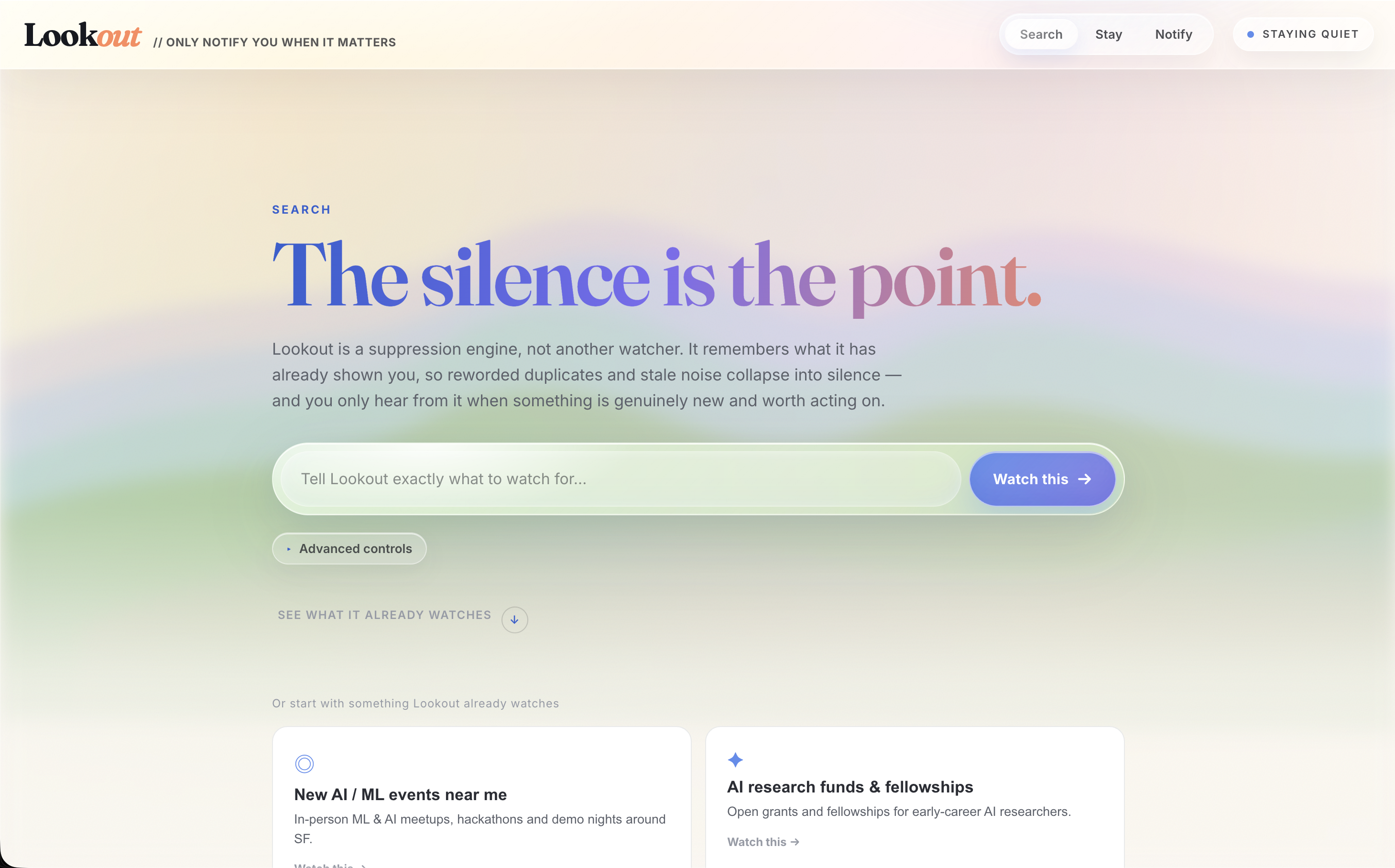
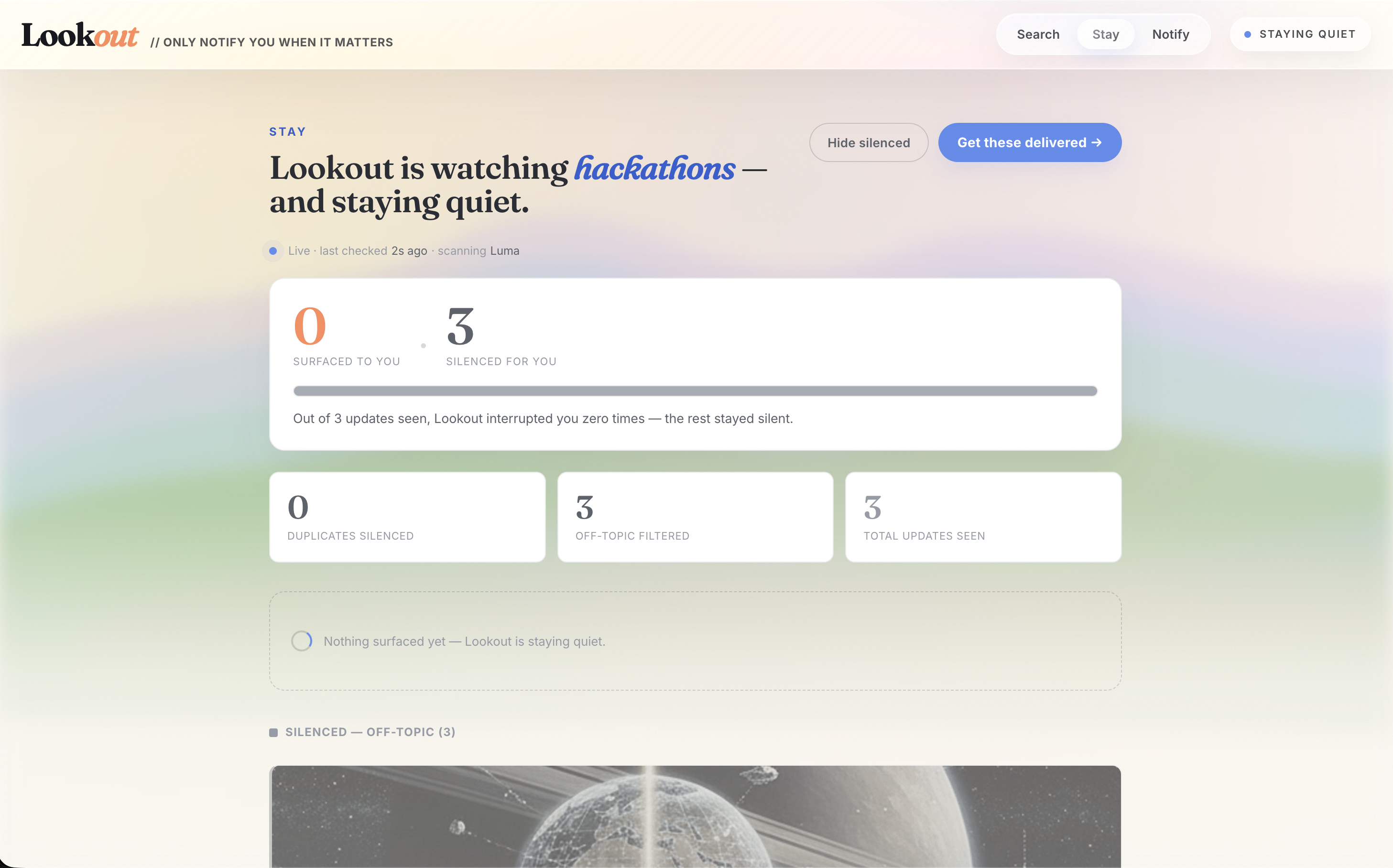
Lookout follows a simple concept: Search + Stay + Notify. It searches continuously-updating sources for what you actually care about, stays on around the clock so nothing slips by, and notifies you only when it finds the right fit, not every match, every keyword hit, or every reworded repost. For every candidate it finds, it asks: have I effectively shown this to you before, and is this genuinely the best fit? It only notifies you when both answers clear the bar. The result is an agent that gets quieter and sharper the longer it runs, instead of bombarding you the way a newsletter or keyword alert does.
How we built it
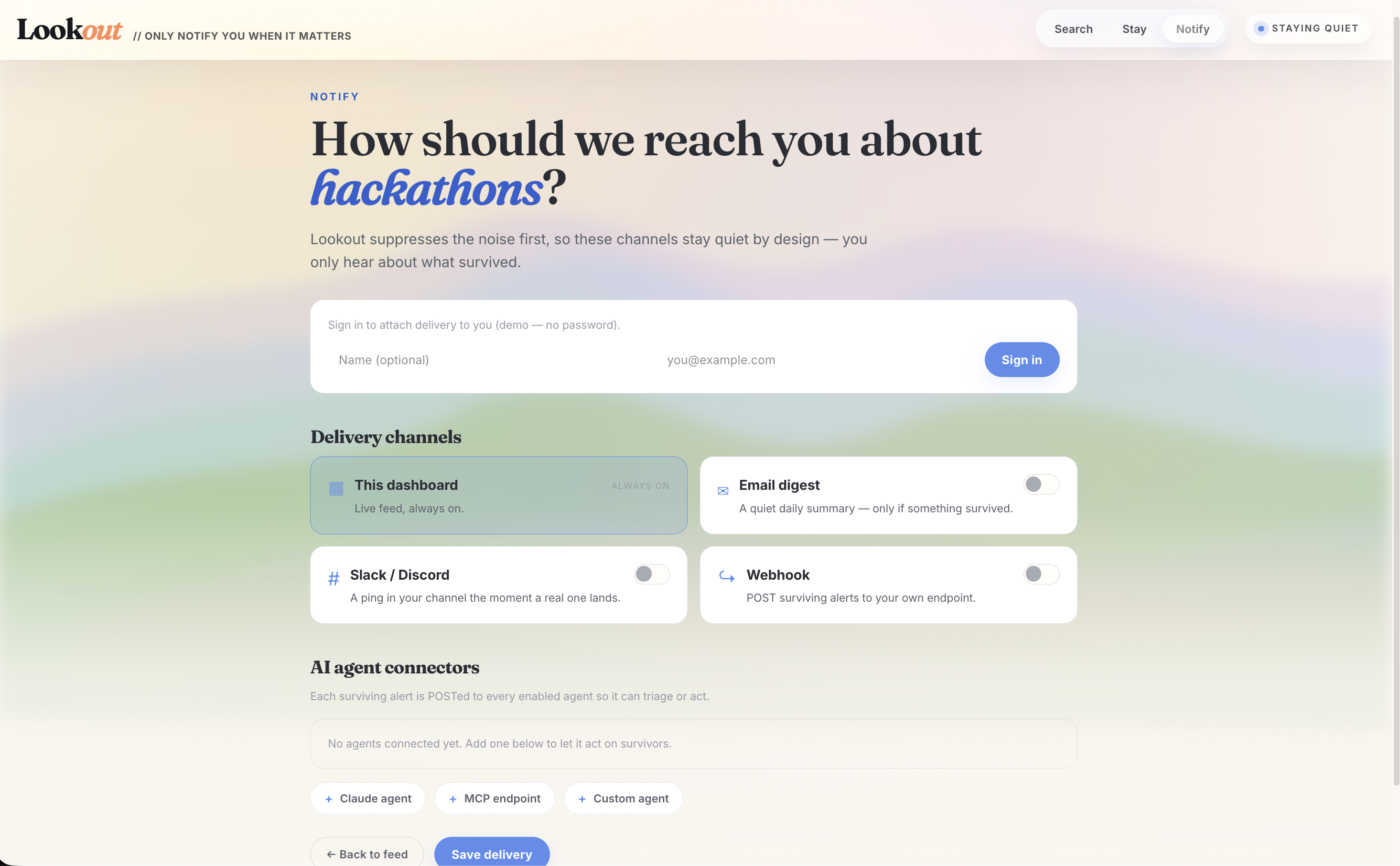
We structured the build around the three parts of Search + Stay + Notify: • Search >> Browserbase powers the web-watching / fetch layer that searches continuously-updating sources for new candidates. • Search >> Anthropic API generates embeddings and judges relevance — ‘is this actually the right fit?’ • Stay >> Redis (RediSearch) is what lets Lookout stay on indefinitely without bombarding you: every notification is stored as a vector, and hybrid KNN queries check new candidates against notification history for semantic duplicates. This is the core engine, not a caching layer. • Notify >> WebSocket pushes only the notifications that survive the fit check, in real time, to a live dashboard. • Sentry provides observability and error monitoring across the live pipeline.
Challenges we ran into
The hardest problem was tuning the semantic similarity threshold for deduplication under a live stream, tight enough to catch a reworded duplicate of the same posting, loose enough to never suppress something genuinely new. That threshold IS the product: too loose and we’re just another alert tool again; too tight and we miss real updates. We also had to make sure our pitch led with the suppression mechanism rather than the watching mechanism: ‘we watch things’ is generic, ‘we know when not to notify you’ is not.
Accomplishments that we're proud of
The fit-finding actually works, we can show it live, staying silent on a reworded duplicate and then notifying instantly when a genuinely better fit appears. We used Redis well beyond caching, making vector search and agent memory the literal engine behind ‘Stay’, the part that lets Lookout run continuously without bombarding the user. And we landed on a concept, Search + Stay + Notify, that’s simple enough to explain in one breath but backed by real architecture.
What we learned
The mechanism mattered more than the domain. Every alert tool we looked at, regardless of what it monitored, shared the same structural flaw: no memory, no concept of redundancy, built to maximize interruptions because that’s how engagement is measured. Once we saw that pattern, the product became obvious. We also learned how much Redis can do as a real-time context engine, vector search and agent memory turned a noisy keyword-bot concept into something that genuinely judges what it’s already seen.
What's next for Lookout
Per-user feedback: letting users thumbs-down a notification to tune their personal similarity threshold, turning suppression into a truly learned, personalized model. Longer-term, the same engine extends to any changing source; status pages, filings, restocks, and eventually the informal channels (Reddit, Discord, official platform APIs) where information often surfaces first, with the suppression engine as the constant.
Built With
- arize
- browserbase
- claude
- css
- devin
- html
- javascript
- netplify
- python
- redis
- sentry
- vite

")
")
Log in or sign up for Devpost to join the conversation.