-
-
Project Architecture
-
Demo Culture
-
Demo Grammar
-
Demo Pronunciation
LoLA — Loka Learning Avatar
Adaptive language coaching powered by Gemini 2.5 Flash Native Audio. Every learner gets a unique AI coaching personality. Two people can make the same mistake and receive visibly different coaching.
Inspiration
Japan and Korea spend billions on English learning every year, yet they consistently rank near the bottom of global English proficiency indexes. In the 2024 EF English Proficiency Index, Japan placed 87th and Korea 49th out of 113 countries. The gap is not a lack of practice material — apps, tutors, and conversation partners are everywhere. The gap is a lack of coaching that adapts to how each individual brain learns.
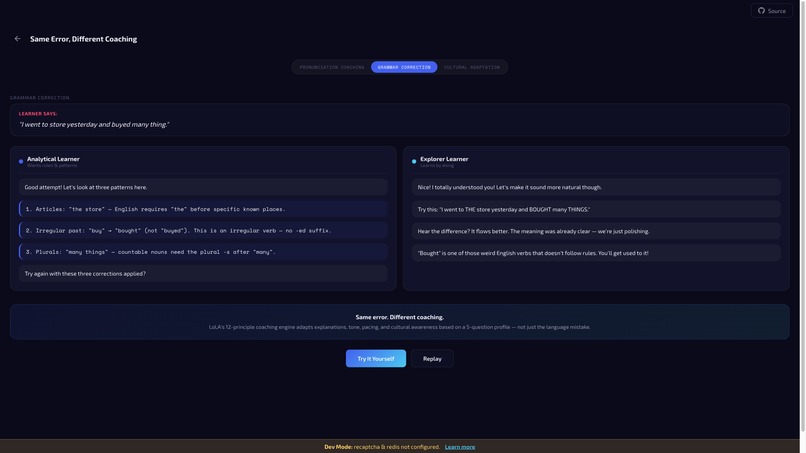
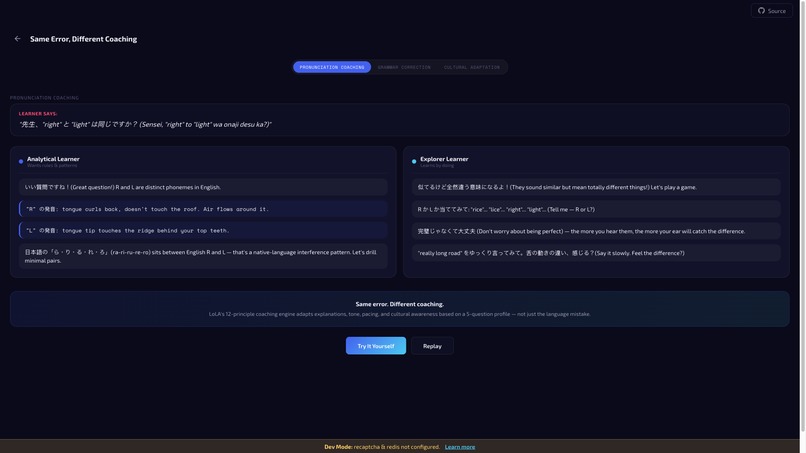
A shy, analytical learner who needs to understand grammar rules before speaking requires fundamentally different coaching than an outgoing explorer who learns by jumping in and making mistakes. Every AI language tutor on the market today gives the same correction to both. That is tutoring, not coaching.
Neurolanguage coaching research shows that matching coaching approach to learner psychology produces faster acquisition and better retention. But a human neurolanguage coach charges $100-200/hour. Most learners will never access one. LoLA exists to close that gap — making adaptive, personality-informed coaching accessible to anyone with a microphone and a browser.
What it does
30-Second Onboarding
When a learner starts LoLA, they answer five personality questions — not language level questions:
- Error Response — Understand why it happened, feel reassured that mistakes are normal, or just get the correction and move on?
- Learning Preference — See rules first, jump in and figure it out, or learn through realistic social scenarios?
- Motivation Driver — Measurable progress metrics, emotional encouragement, or real-world applications?
- Pacing — Time to think, or fast-paced back-and-forth?
- Instruction Depth — Thorough one-concept-at-a-time explanations, light corrections that maintain flow, or new concepts connected to existing knowledge?
Five answers map to five coaching dimensions. Each dimension has two or three possible values. Together they form a unique coaching profile.
The Coaching Engine
The coaching profile feeds into a system instruction generator that combines three layers:
12 neurolinguistic coaching principles — Growth Mindset Activation, Rapport & Anchoring, Emotional State Management, Cognitive Load Management, Spacing & Interleaving, Retrieval Practice, Sensory Engagement, Positive Framing, Autonomy & Choice, Progressive Challenge, VAK Adaptation, and Meta-Model Questioning. Each grounded in peer-reviewed research (Dweck, Sweller, Vygotsky, Roediger, Bandler & Grinder, and others). The engine selects the top 6 principles ranked by relevance to the learner's profile, with weighted scoring across all five dimensions.
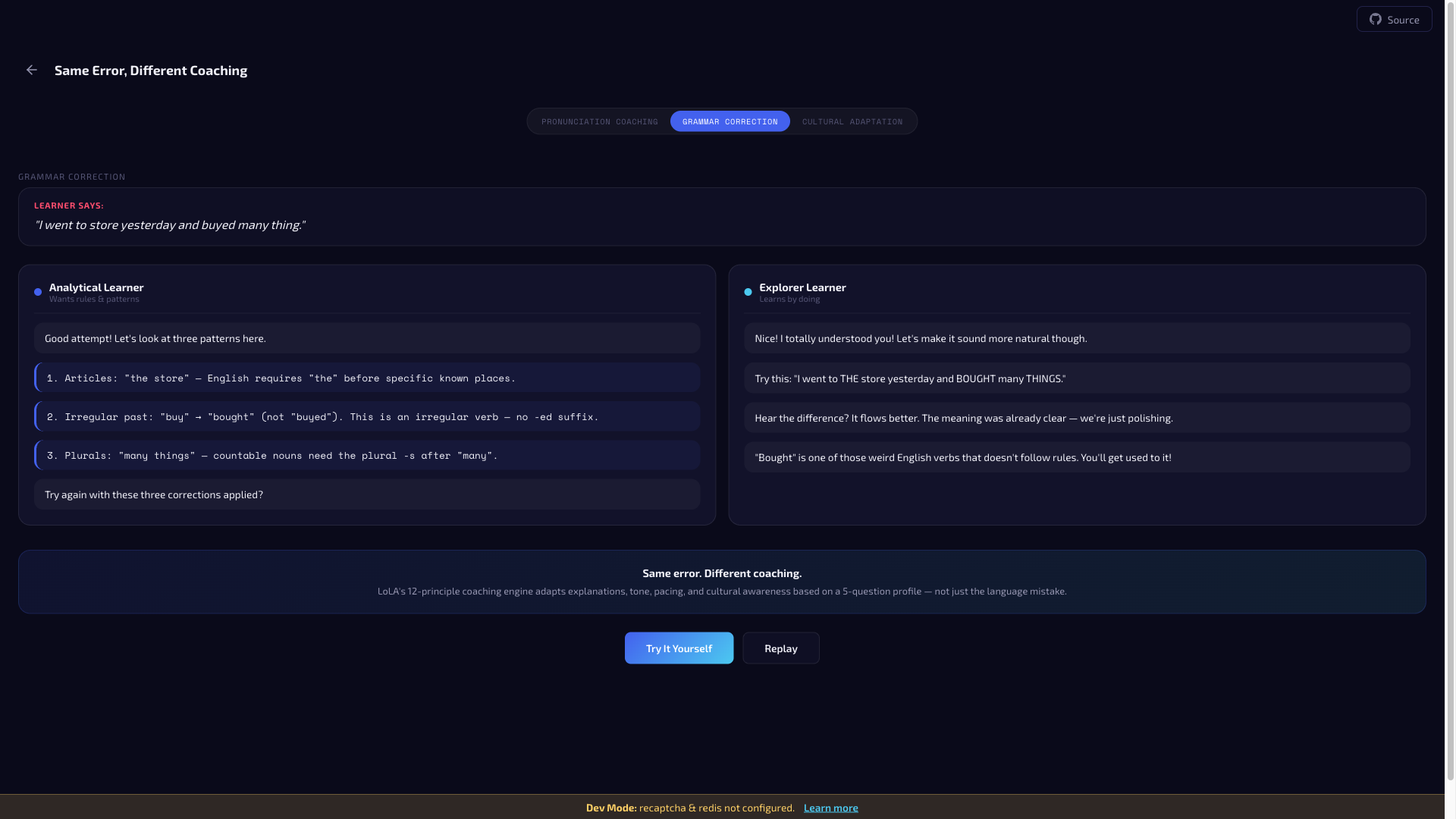
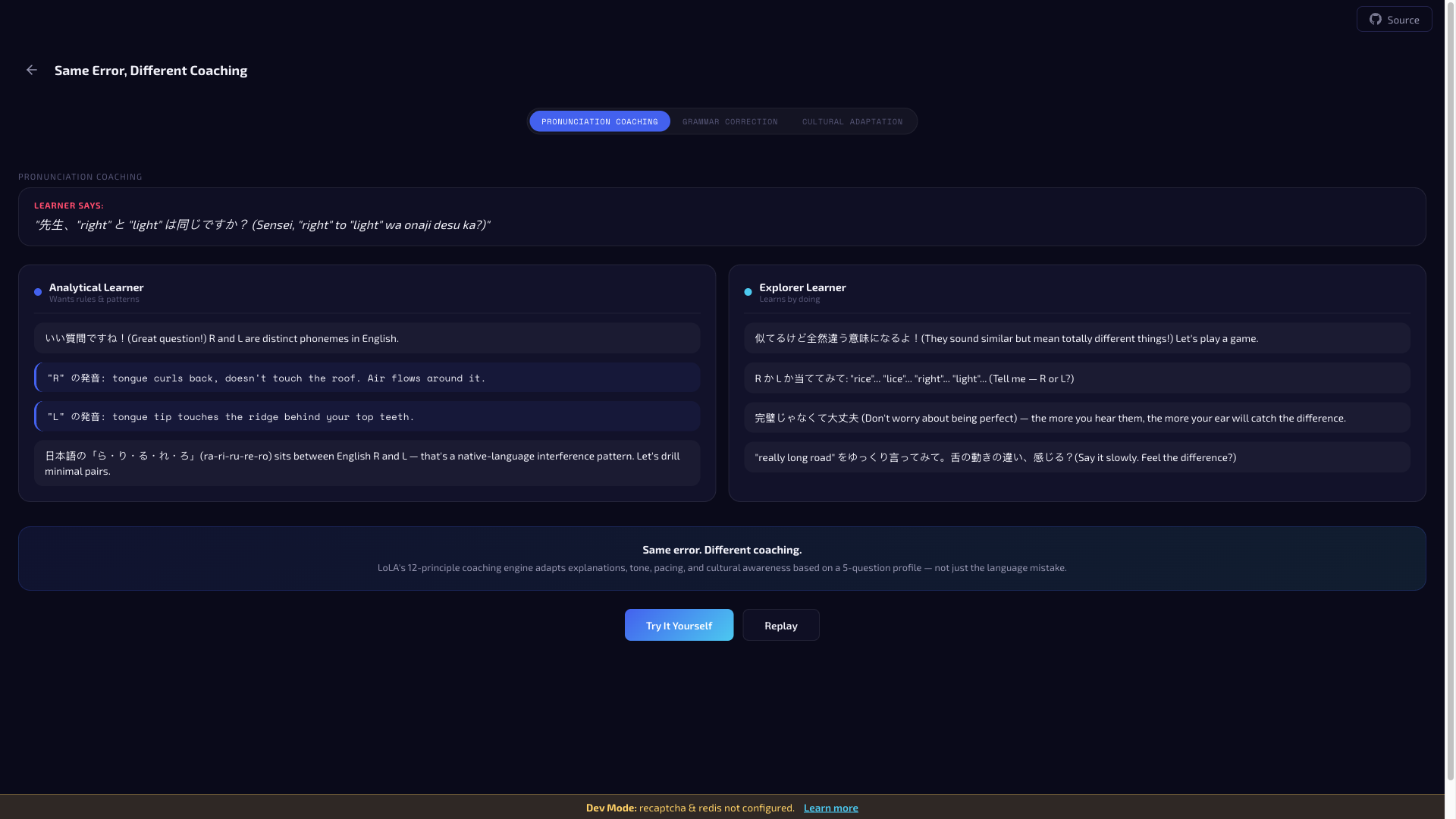
L1 interference patterns — Language-specific error patterns the coach watches for. Japanese speakers: article usage, pluralization, L/R distinction. Korean speakers: tense consistency, subject-verb agreement, relative clauses. English speakers learning Japanese: particle usage, verb conjugation, politeness levels. Structured data, not ad hoc prompt snippets.
Profile-driven coaching style — The system instruction describes how to coach this learner: error response style, emotional approach, pacing, and explanation depth. An "analytical" learner gets calm, measured corrections with pattern explanations. A "challenge_forward" learner gets energetic, quick corrections with humor.
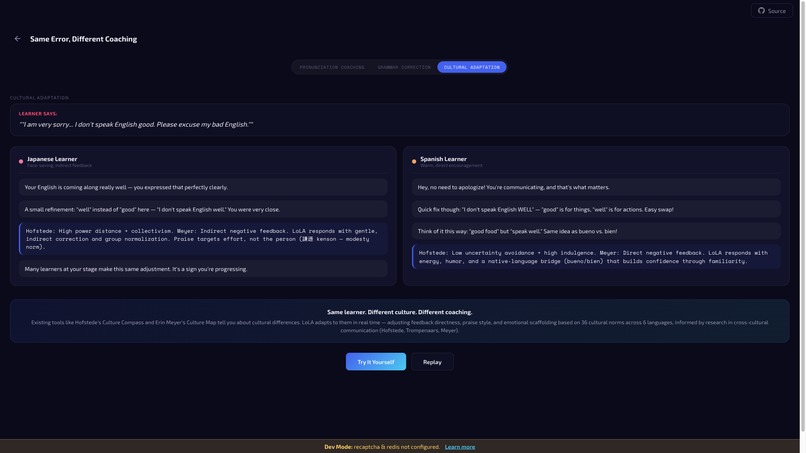
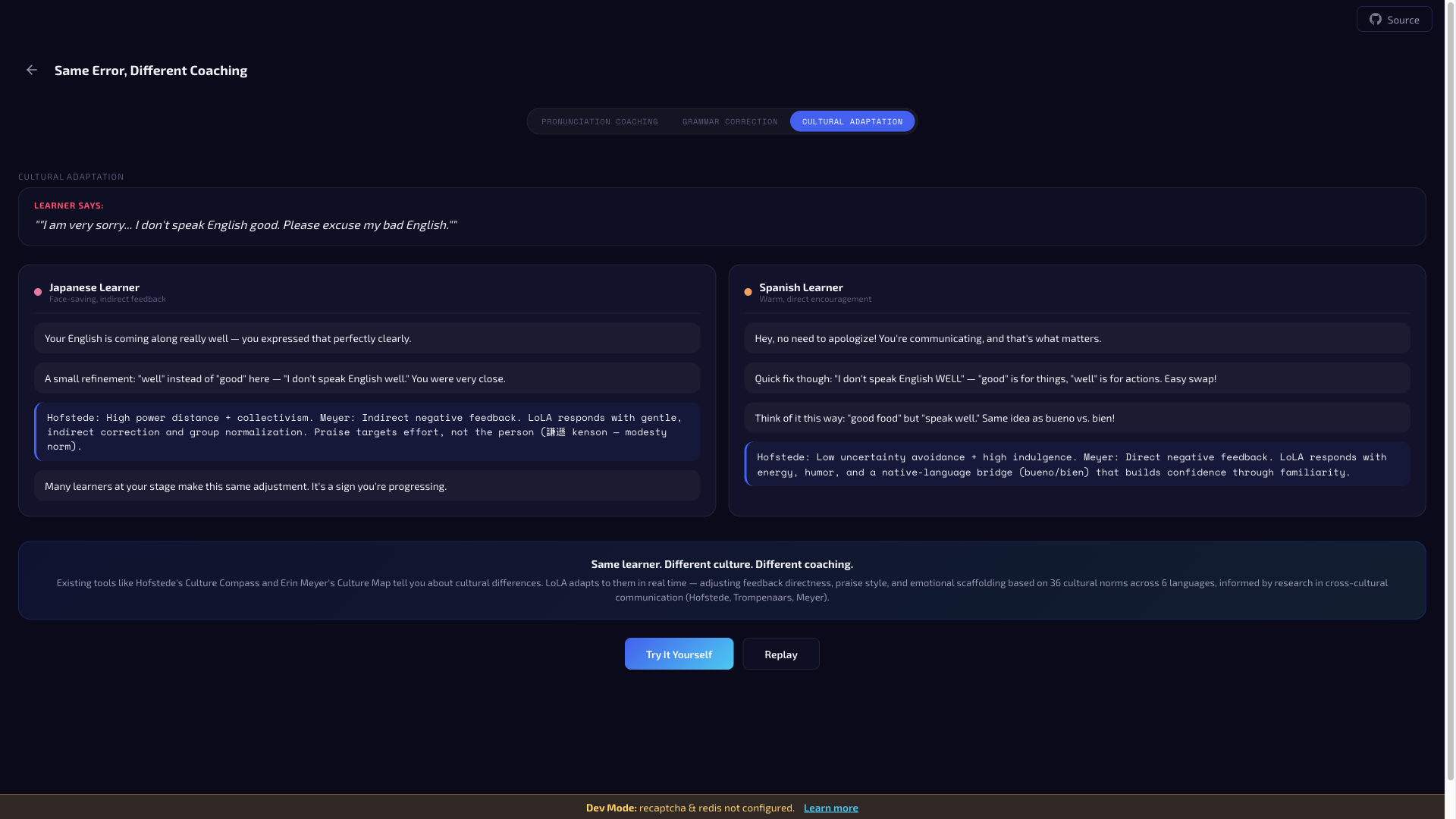
The result is a unique system instruction for every session. Two learners can make the identical pronunciation error and receive visibly different coaching — different tone, different explanation strategy, different emotional scaffolding.
Split-Screen Demonstration
To make this difference visceral rather than theoretical, LoLA includes a split-screen demo mode. The same microphone input is sent simultaneously through two WebSocket connections to two independent Gemini Live API sessions, each running with a different coaching profile. Judges and users can watch in real-time as two coaches respond to the same utterance with visibly different approaches — one might explain the grammar rule in detail while the other gives a quick correction and moves on with encouragement.
Vision-Aware Coaching
Learners can show their camera to the coach — a notebook with handwritten English, a restaurant menu, a textbook page, or a street sign. The coach reads it, identifies errors or learning opportunities, and creates a coaching moment from the visual content, all while maintaining the adaptive coaching style matched to that learner's profile.
Bilingual L1 Bridging
Unlike monolingual AI tutors, LoLA coaches bilingually. A Japanese speaker learning English hears the coach use Japanese to explain grammar concepts, exactly like a real bilingual coach. Analytical learners get structured L1 grammar explanations. Explorers get casual conversational bridges. L1 bridging works in both directions — English speakers learning Japanese receive the same adaptive bilingual coaching in reverse.
Mid-Session Personality Switching
Using Gemini's sendClientContent(), LoLA injects context updates mid-session without disconnecting. When learner frustration is detected, the coaching approach shifts toward greater emotional scaffolding in real-time — a capability unique to the Gemini Live API.
Avatar Expressions and Waveform Visualization
Each coaching personality has a distinct avatar with 8 expression states. Expressions crossfade based on keyword detection in Gemini's output transcription. A real-time waveform visualizer driven by AnalyserNode provides visual feedback during conversation.
How we built it
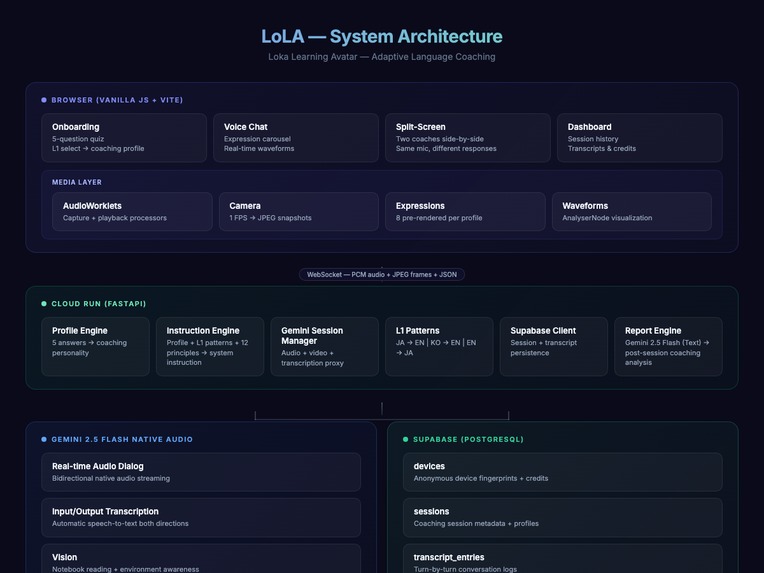
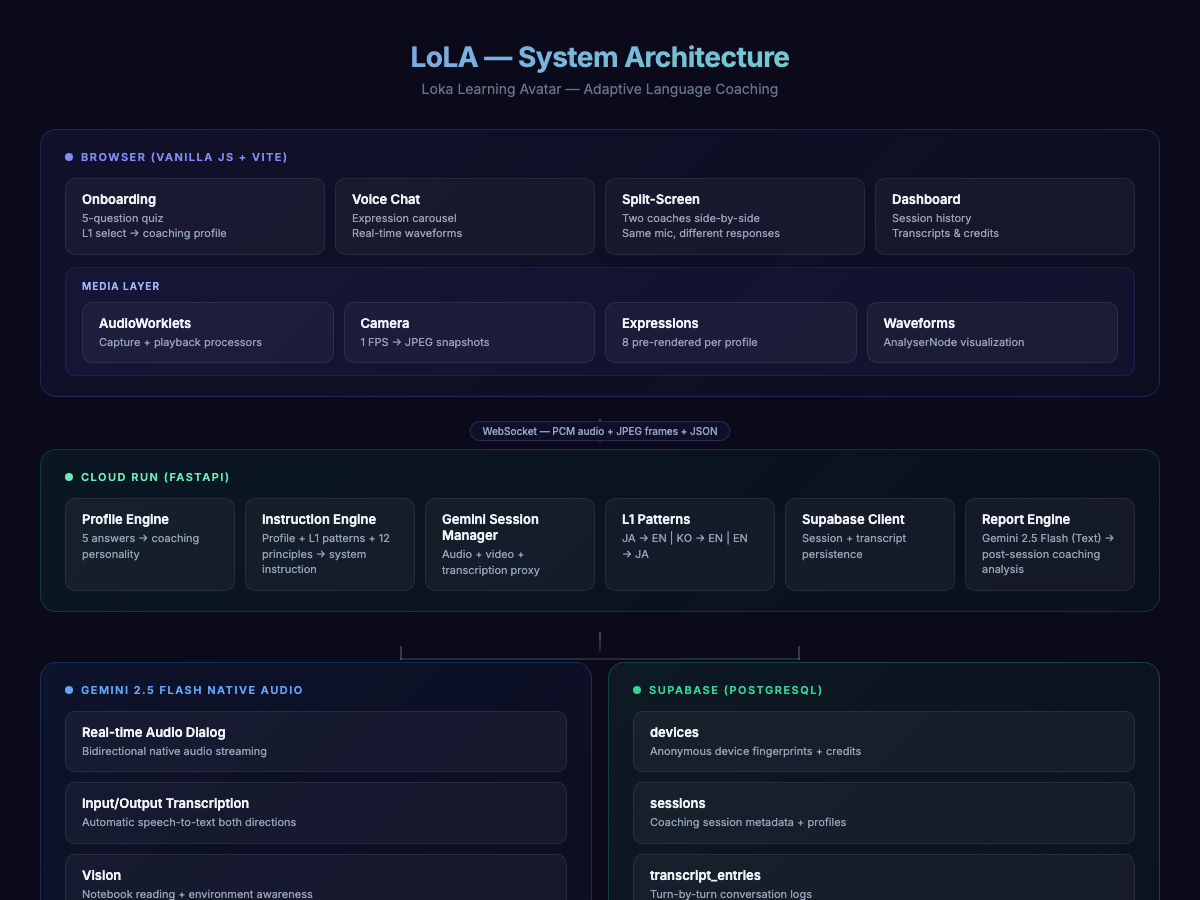
Voice Pipeline: Browser mic → capture.worklet.js (AudioWorklet) → PCM 16-bit mono 16kHz → WebSocket → FastAPI → Gemini 2.5 Flash Native Audio via google-genai SDK Live API. Gemini audio streams back through the same WebSocket → playback.worklet.js → gain control → AnalyserNode → speakers.
Backend: Python 3.10 / FastAPI handles REST endpoints (session creation, profile generation, onboarding) and the WebSocket proxy to Gemini. gemini_live.py manages Live API sessions — setup config, audio streaming, input/output transcription, vision frame injection. Deployed on Google Cloud Run with multi-stage Dockerfile, deploy.sh one-command deployment, and cloudbuild.yaml CI/CD.
Frontend: Vanilla JavaScript with Web Components (Custom Elements) — no frameworks. Vite for dev/bundling. CSS custom properties from a centralized design system (glassmorphism, dark-first palette).
Coaching Engine: profile_engine.py maps 5 answers to a structured profile. instruction_engine.py combines the profile + L1 pattern data + 12 weighted principles into a unique system instruction. principles.py stores all 12 principles as structured data with per-dimension weight matrices, not hardcoded prompt text.
Avatar Pipeline: FLUX Schnell generates anchor portraits. FLUX Kontext Pro generates 8 expression variants per personality while maintaining identity consistency. Both via Together AI API.
Base: Forked from Google's Immergo language learning demo (Apache 2.0, official hackathon resource) by Zack Akil.
Challenges we ran into
TalkingHead needsUpdate Flag: Five lip sync implementation attempts failed before discovering that TalkingHead's morph target update requires BOTH mt.newvalue = X AND mt.needsUpdate = true — without the boolean flag, updates are silently skipped (line 1591: if (!o.needsUpdate) continue;). Pivoted to expression crossfade with waveform visualization, which proved more visually distinctive.
Gemini Native Audio Unsupported Features: enable_affective_dialog and proactivity are not supported on native audio models — including them causes silent failures. The session starts normally but responses become unreliable. No documentation warned about this; discovered through systematic config field elimination.
Temperature Sensitivity: Default temperature 1.0 caused the model to inconsistently ignore system instructions, with coaching personality drifting mid-session. Dropping to 0.7 produced dramatically more reliable instruction following.
AudioWorklet Pipeline Complexity: Real-time PCM streaming required careful buffer management across four boundaries: AudioWorklet capture, WebSocket binary frames, Gemini Live API chunks, and AudioWorklet playback — each with different buffer size expectations and timing constraints.
Expression Detection from Transcription: Mapping output transcription to avatar facial expressions via keyword detection required iterative tuning. Natural language is ambiguous — built a keyword-weight system with surrounding context, but this remains an area for improvement.
Accomplishments that we're proud of
Split-screen demo that makes the difference visceral. Same microphone input, two coaches, two WebSocket connections, two Gemini sessions, two visibly different coaching responses. This is not a slide about personalization — it is personalization running live.
12-principle coaching framework grounded in peer-reviewed research. Every coaching principle traces to published academic work (Dweck on growth mindset, Sweller on cognitive load, Vygotsky on zone of proximal development, Bandler & Grinder on NLP meta-model questioning, Roediger on retrieval practice, and others). This is not prompt engineering intuition — it is neuroscience translated into weighted system instructions.
L1 bilingual bridging. The coach naturally uses Japanese or Korean to explain English concepts, matching how real bilingual coaches work. Most AI tutors are monolingual by design. LoLA's L1 bridging works in both directions — English speakers learning Japanese receive the same adaptive bilingual coaching.
5-question onboarding to unique coaching personality in under 30 seconds. No lengthy assessments, no placement tests, no account setup friction. Five taps and the learner is talking to a coach calibrated to their psychology.
Complete end-to-end pipeline. Onboarding, profile generation, weighted system instruction, real-time voice coaching, avatar expressions, vision input, mid-session context injection, and split-screen comparison — all working as one integrated experience.
Solo developer, ~2 weeks of evening/weekend work. One person (Ryan Ahamer) in Adelaide, Australia. Every line of code, design decision, avatar, and deployment script.
What we learned
Gemini Live API's native audio is remarkably capable for real-time conversation. Barge-in handling, natural turn-taking, voice quality, and latency all exceed expectations. It feels like a conversation partner, not a speech-to-text-to-LLM-to-TTS pipeline.
Native audio models have meaningful undocumented limitations. No affective dialog, no proactivity settings, different temperature sensitivity. Expect to discover constraints through experimentation rather than documentation.
Temperature 0.7 is dramatically better than 1.0 for agent behavior. This single parameter change was the difference between a reliable coaching personality and a model that drifted to generic behavior mid-session. Critical knowledge for personality-driven agents on Gemini.
sendClientContent()is a powerful and unique Gemini capability. Mid-session context injection enables personality switching, frustration response, and vision updates without reconnecting. The coaching engine can continuously adapt during a live conversation.AudioWorklet is complex but necessary. No shortcut exists for real-time audio streaming at coaching quality. Most online examples use the deprecated ScriptProcessorNode.
Adaptive coaching is a fundamentally different product category from AI tutoring. The insight that two learners with the same error need different coaching is a product insight, not an engineering one. The Gemini Live API is the first platform capable of delivering it at consumer scale with voice.
What's next for LoLA
Self-Marketing Pipeline — LoLA avatars generate their own social media content (short-form video, carousel posts, audio clips) and build organic audiences across platforms. Learners discover their coach through link-in-bio and convert to a freemium plan. The avatar is simultaneously the marketing channel and the product. No user acquisition cost.
Educator Creator Platform — Any language educator, accent coach, or subject matter expert can build, own, and monetize their own AI coaching avatar. The 12-principle framework auto-applies based on each learner's onboarding profile, so creators focus on personality, domain knowledge, and their unique teaching philosophy. Creators earn revenue from their avatar's coaching sessions.
Domain-Agnostic Expansion — Language coaching is the first vertical, but the architecture — vision input, adaptive personality, L1 bridging, real-time voice conversation — works for any procedural skill domain. Restaurant staff training (show the menu, practice taking orders), medical communication (practice patient conversations with culturally appropriate bedside manner), sports coaching (show form, get real-time feedback). The coaching engine is domain-agnostic by design.
Co-Active Learning Triangle — Educator, AI, and Learner form a three-sided relationship where all participants continuously improve the learning experience. The educator refines the coaching framework and contributes domain expertise. The AI adapts in real-time to each learner's psychology. Learner data flows back to both the educator and the AI. This triangle is the long-term architecture — every AI competitor offers only a single line between AI and learner.
Built With
gemini-live-api, google-genai-sdk, google-cloud-run, fastapi, python, javascript, web-components, vite, web-audio-api, flux-kontext, talkinghead
Third-Party Resources and Credits
This project is built on a fork of Google's Immergo language learning demo (open-source, Apache 2.0 license, listed as an official hackathon resource) by Zack Akil. The 3D avatar rendering uses the TalkingHead library (MIT license) by Mika Suominen (met4citizen) with the HeadAudio module for real-time lip-sync. Avatar models are created via Ready Player Me. The adaptive coaching engine, personality profiling system, 12-principle coaching framework, multilingual L1 interference patterns, bilingual coaching logic, vision-aware coaching rules, avatar mood mapping, split-screen demonstration view, and all system instruction generation logic are original work created during the contest period.
Built With
- cloud-build
- fastapi
- gemini-live-api
- google-cloud-run
- google-genai-sdk
- javascript
- python
- supabase
- vite
- web-components


Log in or sign up for Devpost to join the conversation.