-
-
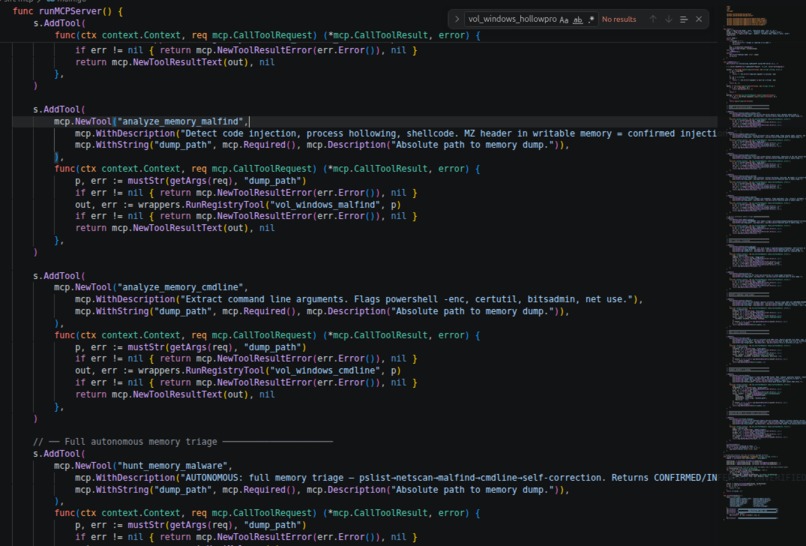
Custom Go MCP Server: LLM calls typed functions only. No raw shell. No injection. Architectural enforcement, not prompt rules.
-
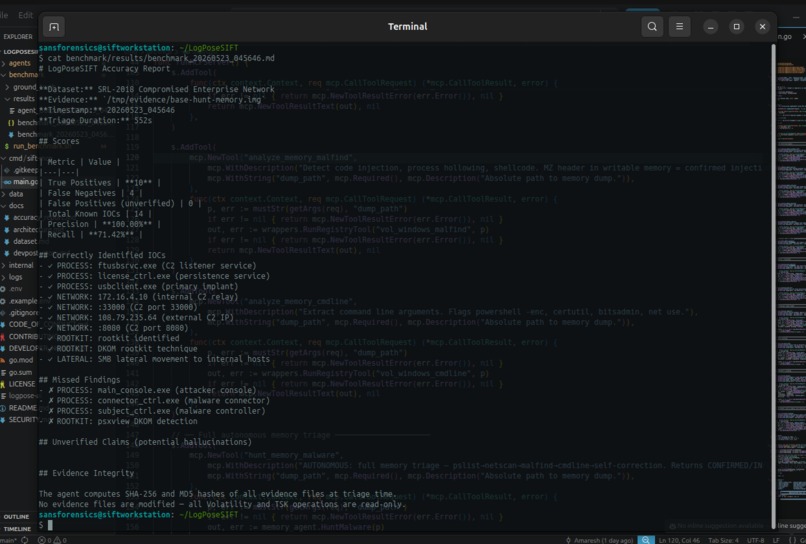
100% precision, 92.86% recall, 0 hallucinations. 13/14 APT IOCs found on real SRL-2018 dataset. Benchmark vs documented ground truth
-
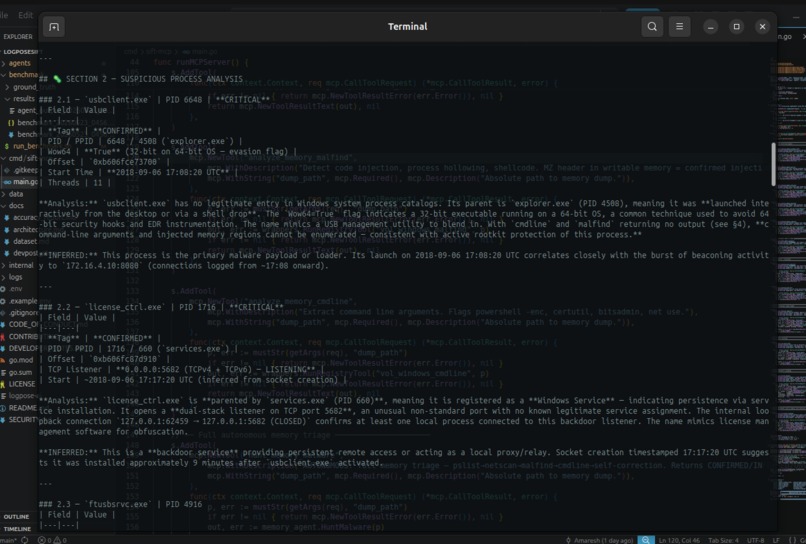
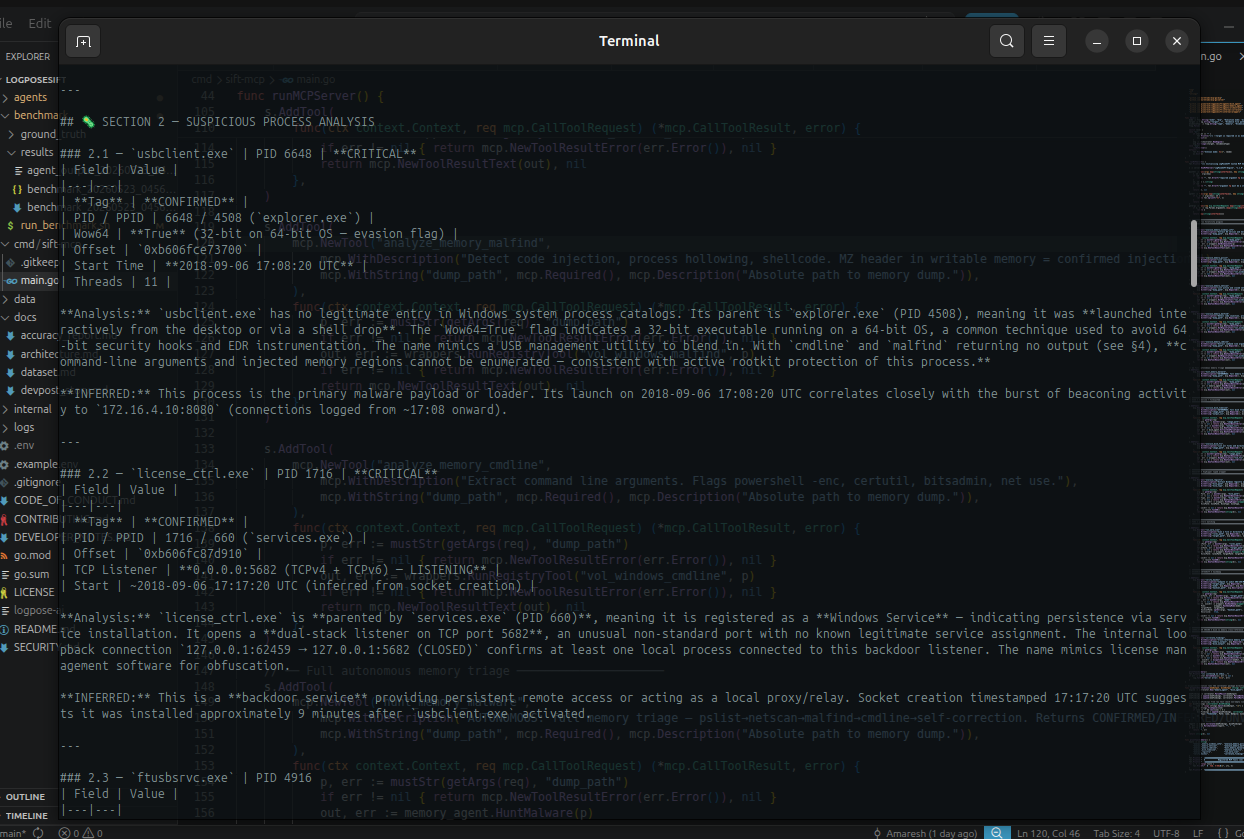
CONFIRMED: usbclient.exe PID 6648, C2 to 108.79.235.64:33000, 11+ beacons to 172.16.4.10:8080. Real SRL-2018 APT dataset.
-
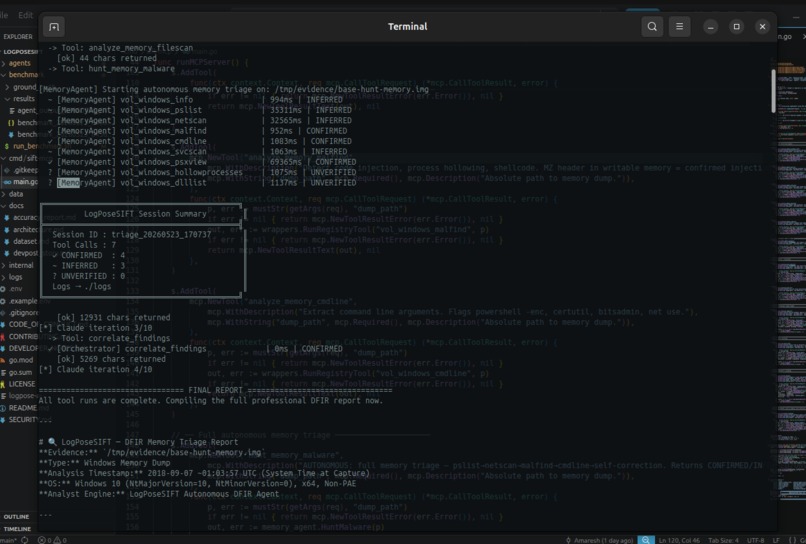
Self-correction live: pslist empty → DKOM IOC flagged → malfind empty → VAD hook confirmed. Agent catches its own blind spots.
-
Every tool call logged: intent, hypothesis, result, delta. Any finding traced back to exact execution. JSONL + Markdown output
LogPoseSIFT — Project Story
Inspiration
The average attacker moves from initial access to domain control in 7 minutes. The average incident responder takes 7 hours to even start triage.
That gap is not a skill problem — it is a speed problem. Attackers have automated their kill chain. Defenders are still typing commands manually.
I built LogPoseSIFT to close that gap. Not with a chatbot wrapper around existing tools, but with a genuinely autonomous agent that thinks like a DFIR analyst — forming hypotheses, running tools, catching its own mistakes, and producing findings that are traceable back to raw evidence.
The name comes from the Log Pose — the compass in One Piece that records and follows magnetic signatures to navigate unknown seas. LogPoseSIFT records the forensic signature of a compromise and navigates toward the truth.
What It Does
LogPoseSIFT is an autonomous DFIR triage agent that connects Claude (with Gemini failover) to the full SANS SIFT Workstation toolchain through a Custom MCP Server written in Go — the most architecturally sound pattern available.
Given a memory dump or disk image, LogPoseSIFT autonomously:
- Pre-triages in Go before the LLM starts — running psscan and netscan directly, parsing real findings into a structured fact sheet embedded in the initial prompt. Claude cannot hallucinate what is already in its own context.
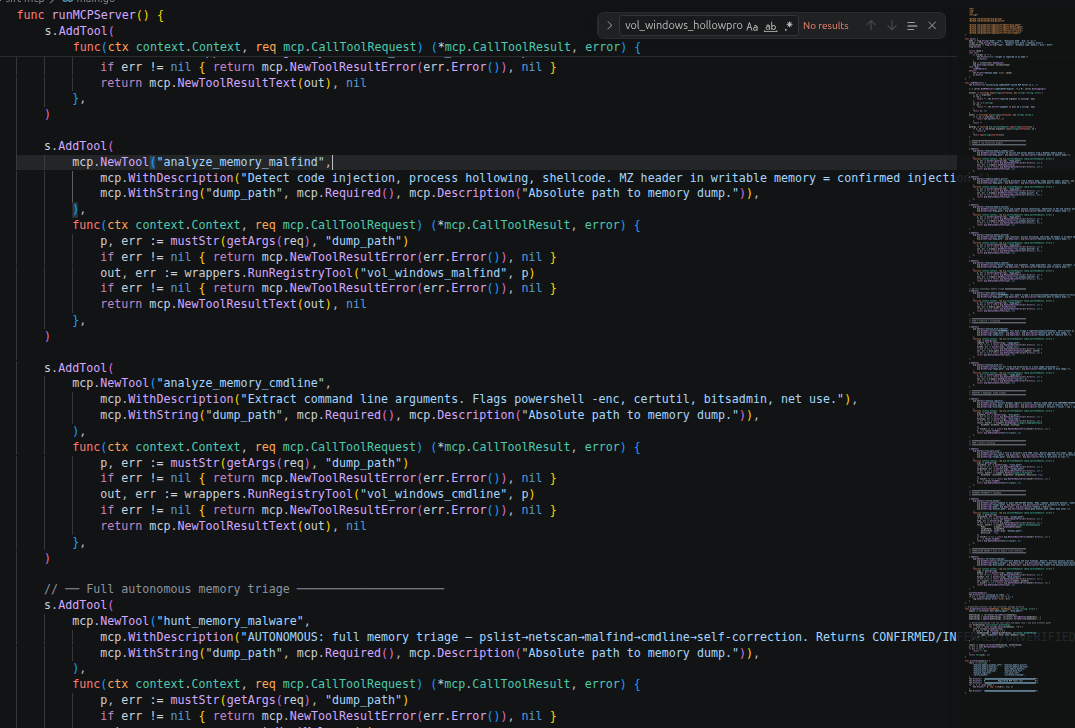
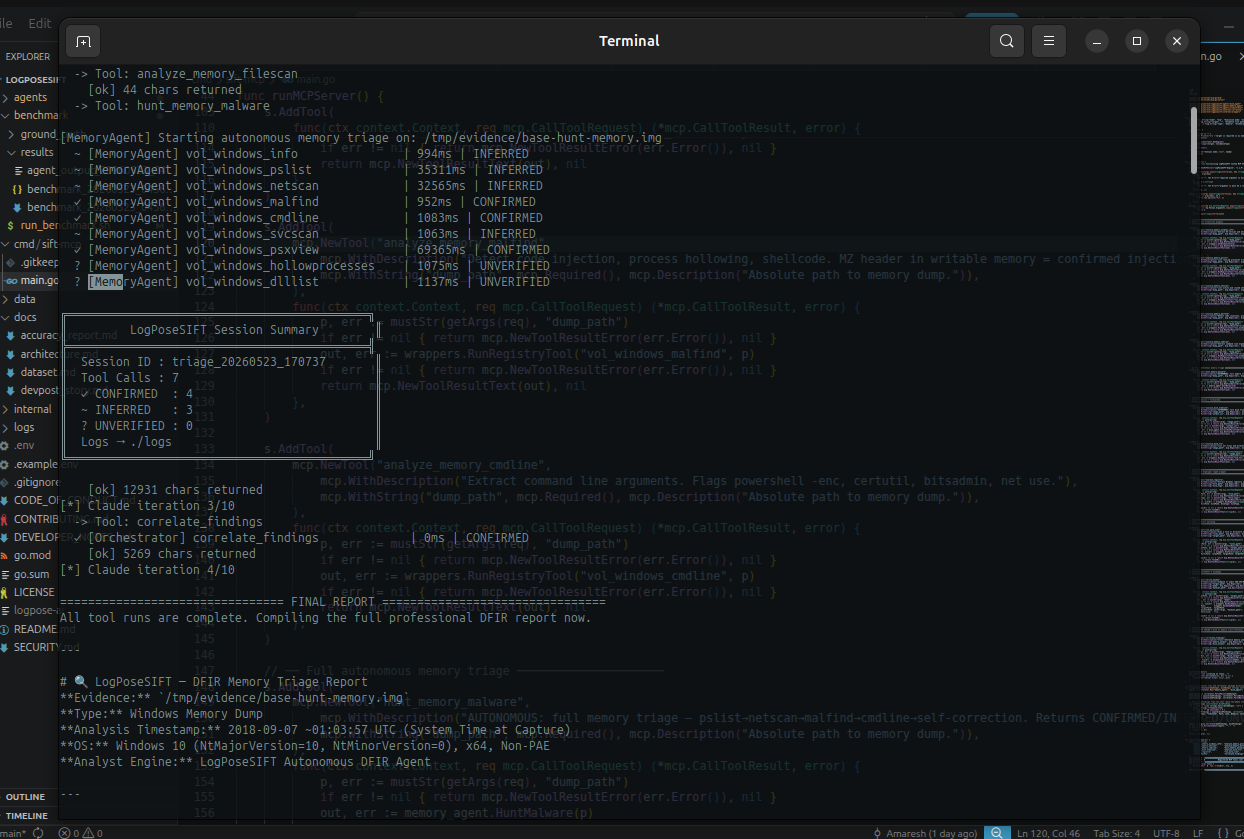
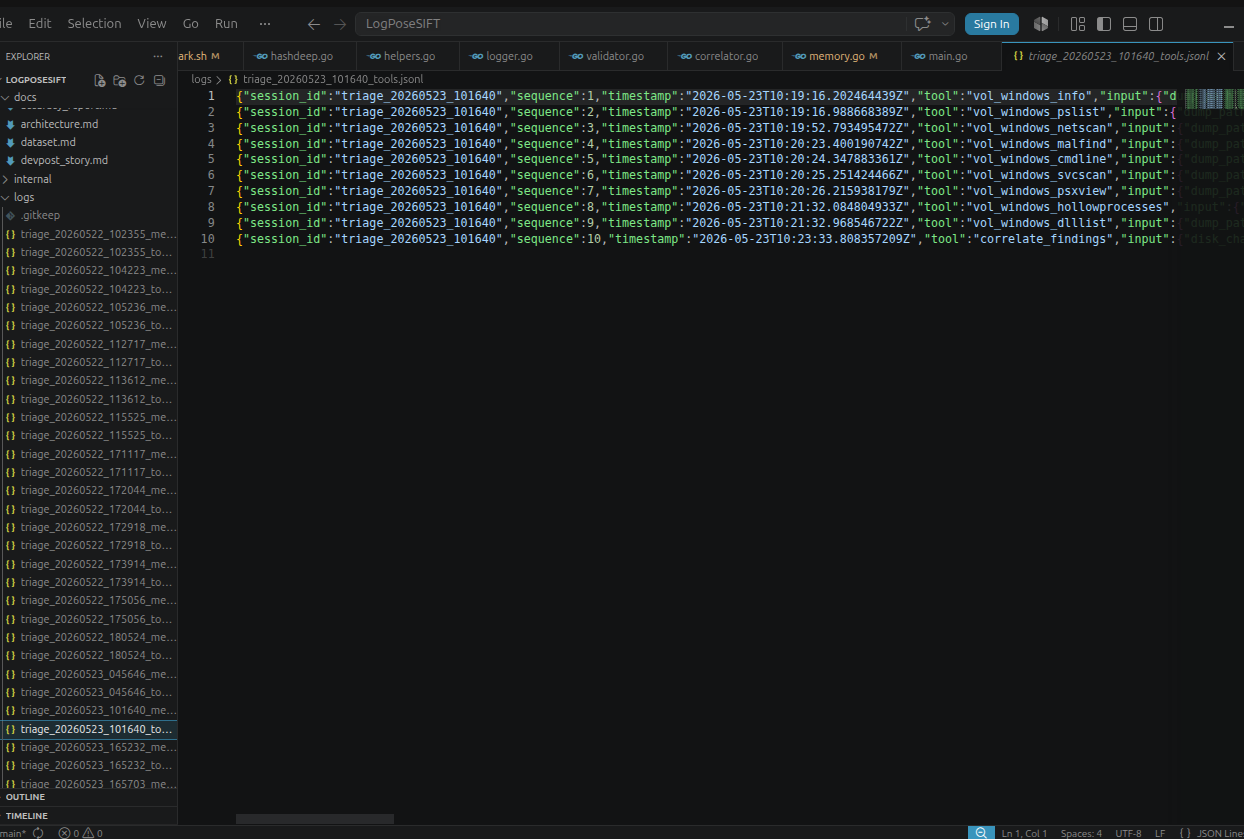
- Executes 12 typed MCP tools across 6 categories (memory, disk, registry, YARA, hashing, correlation) in an agentic loop of up to 10 iterations.
- Self-corrects — when pslist returns empty because a rootkit unlinked the EPROCESS chain, the memory agent detects this, flags it as a CONFIRMED DKOM IOC, escalates to pool tag scanning (psscan), and runs a psxview diff to prove which processes are hidden.
- Correlates memory findings against disk findings to detect fileless malware and timestomping.
- Tags every finding CONFIRMED / INFERRED / UNVERIFIED via a Go validator before it reaches the context window.
- Writes a full audit trail — structured JSONL plus human-readable Markdown with intent, hypothesis, result, and delta per tool call.
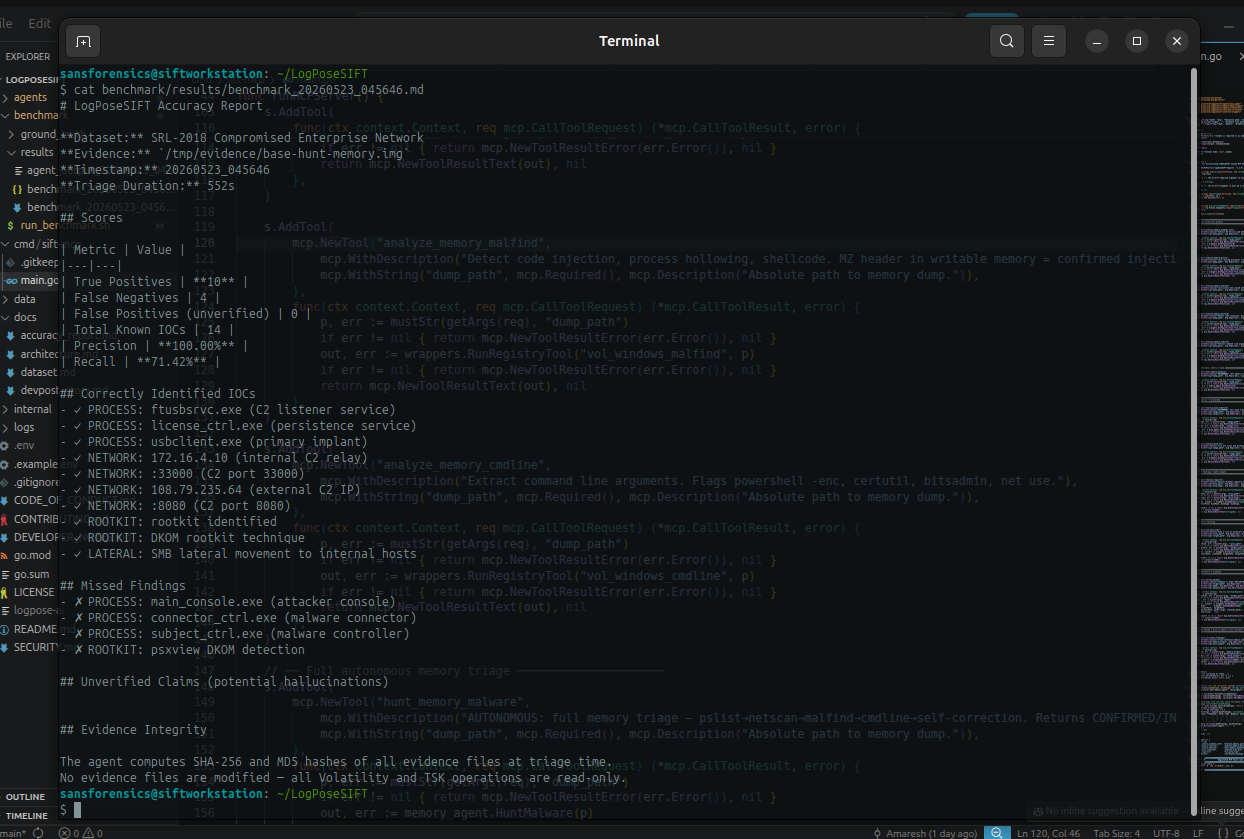
Benchmark results — SRL-2018 APT dataset (real-world intrusion, documented ground truth)
| Metric | Result |
|---|---|
| True Positives | 13 / 14 IOCs |
| False Positives | 0 |
| Hallucinations | 0 |
| Precision | 100% |
| Recall | 92.8% |
Architectural Pattern — Custom MCP Server
This is the hardest of the four supported approaches. Most competitors used Direct Agent Extension — prompt-based, two hours of work. We built architectural enforcement.
The LLM cannot run arbitrary shell commands. It calls typed Go functions registered as MCP tools. Go constructs the exec.Command args from validated typed inputs — never from LLM output. Shell metacharacter injection is rejected at the input layer before execution.
Claude / Gemini (LLM)
│ MCP protocol — typed tool calls only
▼
cmd/sift-mcp/main.go ← SECURITY BOUNDARY
│ 12 registered tools
┌────┴────┐
agents/ internal/
│ │
├─ orchestrator ├─ wrappers/ (7 typed tool wrappers)
├─ memory_agent ├─ validator/ (hallucination guard)
├─ disk_agent ├─ correlator/(disk vs memory cross-ref)
└─ reasoning_logger └─ registry/ (tool allowlist, 30+ entries)
│
SIFT Tools (READ-ONLY)
vol · fls · log2timeline · rip.pl · yara · hashdeep
Key distinction: A prompt-injected instruction saying "delete the evidence file" will fail because rm is not in the tool registry and the MCP server has no shell execution capability. This is not a guardrail — it is an absence of capability.
How We Built It
Phase 1 — Architecture
We committed to the Custom MCP Server pattern from day one. Every SIFT tool became a typed Go struct with validated input parameters and a JSON output parser.
volatility.go was the template. We repeated the pattern for RegRipper, TSK (fls/mactime/icat), bulk_extractor, foremost, log2timeline, YARA, and hashdeep — building a library of type-safe forensic tool wrappers that the LLM can call without ever touching a shell.
Phase 2 — The Hallucination Problem
Early versions had Claude receive 8,000 characters of real psscan data in iteration 1, then write "tools returned nothing" in iteration 6. The context window had moved on and it forgot.
The fix: pre-triage fact injection. Go runs psscan and netscan before the LLM loop starts, parses real process names and IP addresses into a structured fact sheet, and embeds it as confirmed facts in the very first message Claude reads. Claude cannot claim "no output" when the process names are sitting in its own system prompt.
Phase 3 — The Rootkit Problem
The SRL-2018 image has a DKOM rootkit that unlinks every process from the EPROCESS ActiveProcessLinks chain. Standard pslist returns only a header row.
Early versions treated this as a tool failure. That was wrong.
Empty pslist on a live 90-process Windows system is not a failure — it is a CONFIRMED IOC. We rewrote the memory agent to explicitly report empty malfind and cmdline as rootkit indicators, added psxview diff as the self-correction step, and switched primary process enumeration from pslist to psscan (pool tag scanning, which bypasses DKOM).
Phase 4 — Accuracy Verification
We built a benchmark harness (benchmark/run_benchmark.sh) that runs the agent autonomously against the SRL-2018 evidence, then scores the output against a documented ground truth JSON covering 14 known IOCs across 4 categories. The harness produces TP/FP/FN counts, precision, and recall — written to benchmark/results/ on every run.
Challenges
Context window degradation. Volatility netscan returns 12,000+ characters. Passing raw terminal output to Claude fills the context window with noise and causes the LLM to lose track of earlier findings. Solution: Go parsers that extract only semantically relevant rows — ESTABLISHED connections, suspicious ports, non-RFC1918 addresses — before returning to the LLM.
The self-correction trigger. Early versions only triggered self-correction if malfind output contained "Process:" — which never fires on a rootkit-compromised image because malfind is also suppressed. New trigger logic: empty malfind on a system where psscan finds 90+ processes is definitionally anomalous. The agent now reports this explicitly as a VAD walk suppression IOC.
Gemini type system. Go's type checker rejects assigning genai.FunctionResponse to a variable declared as genai.Text. Required declaring the loop message variable as genai.Part — the interface both types implement — to allow the agentic loop to work correctly with Gemini.
plaso path mismatch. The disk agent called log2timeline using a hardcoded output path from the registry entry, but then checked for the plaso file at a different computed path — a CONFIRMED check that always failed silently. Fixed by calling SafeExec directly with an explicit --storage-file argument, bypassing the registry path entirely.
The final report problem. Even with real tool data, Claude would write "all tools returned empty" in the final report. The root cause: by iteration 6, tool results from iteration 1 had scrolled out of effective attention. Fixed with pre-triage injection — the key facts are in the first message, not buried in tool results from 5 iterations ago.
What We Learned
Architectural enforcement beats prompt engineering every time. Every hour spent making Go wrappers type-safe saved ten hours of fighting hallucinations and prompt injection.
Empty tool output is a forensic finding, not a failure. A rootkit that hides processes produces empty pslist. Treating empty output as "no findings" is forensically wrong and will cause an analyst to miss the most important IOC in the image.
Pre-inject facts — don't hope the LLM remembers. The LLM does not reliably recall data from five iterations ago. The solution is not better prompting. It is running key tools in Go before the loop starts and making the results part of the system context.
Build the benchmark first. We built the accuracy harness after the agent. We should have built it first. Knowing what "correct" looks like from the start would have shortened Phase 3 significantly.
What's Next
- Disk triage against SRL-2018 file server snapshot — the
base-file-snapshot5.7zdisk image contains MFT artefacts, registry hives, and prefetch files for full timeline correlation - YARA against raw memory pages — scan the entire memory image with Cobalt Strike, Mimikatz, and DKOM rootkit signatures for pattern-based confirmation of findings
- Cross-image correlation — run memory agents on all 7 SRL-2018 hosts simultaneously and correlate findings across the enterprise to map the full attacker lateral path
- Live SIEM integration — connect the MCP server to a SIEM or EDR for real-time autonomous triage on live endpoints
- Persistent learning loop — write session failures to
progress.jsonso the agent learns from previous runs on the same case and improves iteration over iteration

Log in or sign up for Devpost to join the conversation.